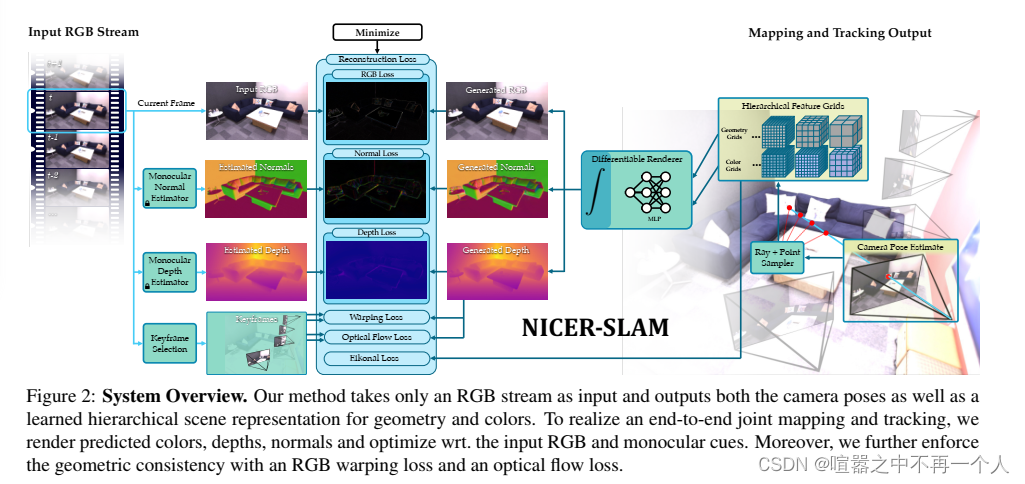
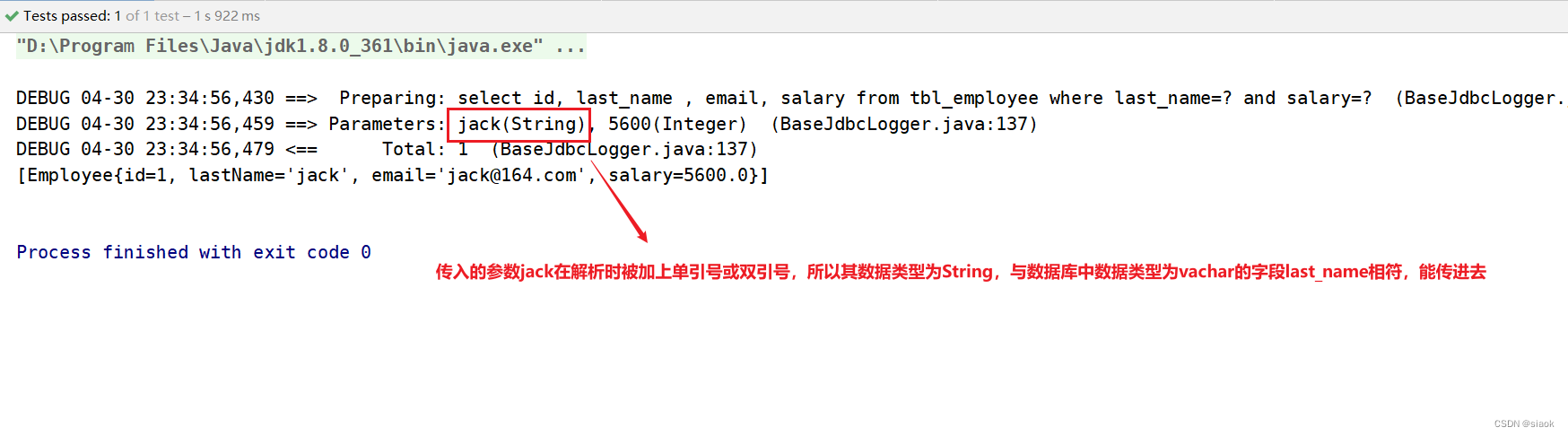
问题描述
如下是一个Java Bean类,这是我的sql2java工具根据数据库表自动生成的对应表记录的Java类。

与之对应的数据库表定义如下:
CREATE TABLE IF NOT EXISTS dc_device_channel (
`device_id` int NOT NULL COMMENT 'X@NAME:设备ID@X',
`sid` int NOT NULL DEFAULT 0 COMMENT 'X@NAME:物理屏幕ID@x',
`area` varchar(32) NOT NULL COMMENT 'X@NAME:显示区域ID@x',
`rect` varchar(64) DEFAULT NULL COMMENT 'X@NAME:显示区域坐标@x,对应EamPlayer的defineChannel语法TYPE@net.facelib.eam.interpreter.Rectangle@EPYT',
`channel` varchar(32) NOT NULL COMMENT 'X@NAME:频道ID@x,显示区域对应的频道',
`run_tasks` text DEFAULT NULL COMMENT 'X@NAME:播放任务@X描述,设备实际播放的任务描述,由设备端写入,对应EamPlayer的definePlanTask语法',
PRIMARY KEY(`device_id`,`sid`,`area`),
FOREIGN KEY (device_id) REFERENCES dc_device(id) ON DELETE CASCADE,
INDEX (channel)
)COMMENT 'X@NAME:设备显示区域频道记录@X' DEFAULT CHARSET=utf8;
这是一个基本标准的Java Bean,每个数据库字段对应的Java成员都有getter/setter方法。不论是jackson,还是fastjson将序列化为JSON字符串时都没有任何问题。
但是仔细看上面的截图可以发现,在setter方法中会修改initialzied,modified字段,(这是两个额外字段,以bit形式记录该字段是否被修改过)。尤其这个modified字段用于在调用JDBC方法保存记录时,决定是否保存该字段。
也就是说每次调用setter方法都会影响modified,initialized字段的值。
那么可以想见当不做任何特别设置,对JSON字段串进行反序列化时,得到的initialzied,modified字段的值是不确定的。取决于这两个字段被反序列化时的顺序,如果它们被在放在最后反序列化,那它们的值是正确的,否则它们的值与原始输入值肯定是不一致的。
另外如果输入的JSON字符串中字段名是snake-case的数据库字段名(如run_tasks),反序列化时应该能自动识别为camel-case的Java字段名(如runTasks)。这是JSON工具默认反序列化做不到的。
所以为了解决这些问题,只能为它们自定义反序列化实现。
fastjson 反序列化
fastjson反序列化器实现很简单,实现的时候没有遇到太多麻烦,
基本的逻辑就是继承com.alibaba.fastjson.parser.deserializer.JavaBeanDeserializer重写deserialze(DefaultJSONParser parser, Type type, Object fieldName)方法,先将输入内容反序列化为JSONObject(也就是Map<String, Object>), 然后识别snake-case的数据库字段名转为camel-case的JavaBean字段名。然后调用JavaBeanDeserializer.createInstance方法对JSONObject逐字段反序列化返回对应的Java Bean对象,并最后调用setter方法赋值modified,initialized字段在确保它们的值与原始输入值一致。
代码如下:
public class FastjsonDeserializer extends JavaBeanDeserializer implements Constant {
public FastjsonDeserializer(ParserConfig config, Class<? extends BaseBean> beanClass) {
super(config, checkNotNull(beanClass,"beanClass is null"));
}
public FastjsonDeserializer(Class<? extends BaseBean> beanClass) {
this(ParserConfig.global, beanClass);
}
@SuppressWarnings("unchecked")
@Override
public <T> T deserialze(DefaultJSONParser parser, Type type, Object fieldName) {
/** deserialze to JSONObject */
JSONObject json = (JSONObject)super.deserialze(parser, JSONObject.class, fieldName);
// replace key to camel-case if snake-case
for(String key:Lists.newArrayList(json.keySet()) ) {
if(isSnakecase(key)) {
String camelcase = toCamelcase(key);
if(!json.containsKey(camelcase)) {
json.put(camelcase, json.get(key));
json.remove(key);
}
}
}
/** convert Map to target type based BaseBean */
try {
BaseBean bean = (BaseBean) createInstance(json, parser.getConfig());
bean.setNew(firstNonNull(json.getBoolean(FIELD_NEW), true));
Integer modified = json.getInteger(FIELD_MODIFIED);
Integer initialized = json.getInteger(FIELD_INITIALIZED);
if(null != initialized){
bean.setInitialized(initialized);
}
if(null != modified){
bean.setModified(modified);
}
return (T) bean;
} catch (Exception e) {
throw new JSONException(e.getMessage(), e);
}
}
}
有了这个类,实现一个为上面DeviceChannelBean定制的fastjson反序列化类就很简单:
public static class DeviceChannelBeanFastjsonDeserializer extends FastjsonDeserializer{
public DeviceChannelBeanFastjsonDeserializer() {
super(DeviceChannelBean.class);
}
}
然后我们就可以如下使用@JSONType注解将反序列化器定义在类上:
@JSONType(deserializer=DeviceChannelBeanFastjsonDeserializer.class)
public final class DeviceChannelBean extends BaseRow
implements Serializable,Constant
{
......
}
这样不论在什么环境 DeviceChannelBean 都可以被faskjson正确反序列化了
jackson反序列化实现(一)
这是我最开始设计的jackson反序列化实现,
基本的逻辑就是继承com.fasterxml.jackson.databind.deser.std.StdDeserializer重写deserialize(JsonParser jp, DeserializationContext ctxt)方法,先将输入内容反序列化为JsonNode ,然后调用ObjectMapper.treeToValue方法将JsonNode 转为指定类的对象,并在最后调用setter方法赋值modified,initialized字段确保它们的值与原始输入值一致。
注意这个实现中没有考虑
snake-case的问题。
public class JacksonDeserializer<B extends BaseBean> extends StdDeserializer<B>implements Constant {
private static final long serialVersionUID = 7410414787512241455L;
protected JacksonDeserializer(Class<B> beanClass) {
super(beanClass);
}
@SuppressWarnings("unchecked")
@Override
public B deserialize(JsonParser jp, DeserializationContext ctxt) throws IOException, JsonProcessingException {
ObjectMapper mapper = (ObjectMapper) jp.getCodec();
JsonNode node = mapper.readTree(jp);
B bean = (B) mapper.treeToValue(node,_valueClass);
bean.setNew(firstNonNull(getBoolean(node,FIELD_NEW), true));
Integer modified = getInteger(node,FIELD_MODIFIED);
Integer initialized = getInteger(node,FIELD_INITIALIZED);
if(null != initialized){
bean.setInitialized(initialized);
}
if(null != modified){
bean.setModified(modified);
}
return bean;
}
private Boolean getBoolean(JsonNode node,String name) {
JsonNode vnode = node.get(name);
if(null != vnode && !vnode.isNull()) {
return vnode.asBoolean();
}
return null;
}
private Integer getInteger(JsonNode node,String name) {
JsonNode vnode = node.get(name);
if(null != vnode && !vnode.isNull()) {
return vnode.asInt();
}
return null;
}
}
设计很简单,一切看起来都很美好,
但是这个反序列化器是不能正常工作的,用于反序列化时就会报错:StackOverflowError,很严重的堆栈溢出错误。
为啥呢?
问题出在ObjectMapper.treeToValue方法,仔细研究ObjectMapper的源码发现,treeToValue方法是调用readValue(JsonParser p, Class<T> valueType),而readValue方法最终是调用 _findRootDeserializer(DeserializationContext ctxt,JavaType valueType)来根据treeToValue方法提供的valueType参数(目标类型)获取反序列化实例。那么它返回的还是当前JacksonDeserializer实例,也就是自己。所以就造成了无限递归。所以这里我们不能简单的调用treeToValue(TreeNode n, Class<T> valueType)方法来完成字段反序列化。必须在deserialize(JsonParser jp, DeserializationContext ctxt)实现Java Bean的字段解析。才能避免递归调用问题。
jackson反序列化实现(二)
下面的代码是我实现的第二版的jackson反序列化器。它以com.fasterxml.jackson.databind.deser.BeanDeserializer为基类,BeanDeserializer是Jackson默认的Java Bean反序列化实现。
在下面的deserialize(JsonParser jp, DeserializationContext ctxt)方法中参照BeanDeserializer.vanillaDeserialize方法实现字段解析,在字段解析过程中自动识别snake-case的数据库字段名转为camel-case的JavaBean字段名(参见findProperty方法),并在最后调用setter方法赋值modified,initialized字段确保它们的值与原始输入值一致。
public class JacksonDeserializer extends BeanDeserializer implements Constant {
private static final long serialVersionUID = 7410414787512241455L;
public JacksonDeserializer(Class<? extends BaseBean> beanClass) {
super(createBeanDeserializer(beanClass));
}
@Override
public BaseBean deserialize(JsonParser jp, DeserializationContext ctxt) throws IOException, JsonProcessingException {
// see also BeanDeserializer.vanillaDeserialize
BaseBean bean = (BaseBean) _valueInstantiator.createUsingDefault(ctxt);
Boolean _new = null;
Integer initialized = null,modified = null;
for(String propName = jp.nextFieldName();propName != null;propName = jp.nextFieldName()) {
jp.nextToken();
SettableBeanProperty prop = findProperty(this,propName);
if (prop != null) { // normal case
try {
switch(propName) {
case FIELD_NEW:
_new = (Boolean) prop.deserialize(jp,ctxt);
break;
case FIELD_INITIALIZED:
initialized = (Integer) prop.deserialize(jp,ctxt);
break;
case FIELD_MODIFIED:
modified = (Integer) prop.deserialize(jp,ctxt);
break;
default:
prop.deserializeAndSet(jp, ctxt, bean);
}
} catch (Exception e) {
wrapAndThrow(e, bean, propName, ctxt);
}
continue;
}
handleUnknownVanilla(jp, ctxt, bean, propName);
}
if(null != _new) {
bean.setNew(_new);
}
if(null != initialized){
bean.setInitialized(initialized);
}
if(null != modified){
bean.setModified(modified);
}
return bean;
}
private SettableBeanProperty findProperty(BeanDeserializer beanDeserializer,String propName) {
SettableBeanProperty prop = beanDeserializer.findProperty(propName);
if(null == prop && isSnakecase(propName)) {
prop = beanDeserializer.findProperty(toCamelcase(propName));
}
return prop;
}
/**
* 创建{@code beanClass}对应的{@link BeanDeserializerBase}实例用于父类构造方法的参数,
* 将{@code beanClass}的序列化参数注入到当前实例中
* @param beanClass
*/
private static BeanDeserializerBase createBeanDeserializer(Class<?> beanClass){
try {
ObjectMapper mapper = new ObjectMapper();
DefaultDeserializationContext defctx = (DefaultDeserializationContext) mapper.getDeserializationContext();
DefaultDeserializationContext ctxt = defctx.createInstance(mapper.getDeserializationConfig(), null,null);
JavaType type = ctxt.constructType(beanClass);
BasicBeanDescription beanDesc = (BasicBeanDescription)ctxt.getConfig().introspect(type);
BeanDeserializerFactory factory = (BeanDeserializerFactory) ctxt.getFactory();
BeanDeserializer beanDeserializer = (BeanDeserializer) factory.buildBeanDeserializer(ctxt, type, beanDesc);
beanDeserializer.resolve(ctxt);
return beanDeserializer;
} catch (IOException e) {
throw new ExceptionInInitializerError(e);
}
}
}
有了这个jackson反序列化实现类,实现一个为上面DeviceChannelBean定制的jackson反序列化类就很简单:
public static class DeviceChannelBeanJacksonDeserializer extends JacksonDeserializer{
private static final long serialVersionUID = 359505789687575302L;
public DeviceChannelBeanJacksonDeserializer() {
super(DeviceChannelBean.class);
}
}
然后我们就可以如下使用@JsonDeserialize注解将反序列化器定义在类上:
@JsonDeserialize(using=DeviceChannelBeanJacksonDeserializer.class)
public final class DeviceChannelBean extends BaseRow
implements Serializable,Constant
{
......
}
这样不论在什么环境 DeviceChannelBean 都可以被jackson正确反序列化了
createBeanDeserializer
这里最难实现并不是deserialize(JsonParser jp, DeserializationContext ctxt)中的逐字段反序列化。而是构造方法。BeanDeserializer最简单的构造方法的参数也是一个BeanDeserializerBase实例,这个实例包含了一个JavaBean类所有的反序列化配置,没有以Class<?>为参数的构造方法,jackson源码中也没有找到直接的方法或简单示例根据一个Java Bean类型创建一个BeanDeserializer实例。
所以我参照com.fasterxml.jackson.databind.deser.DeserializerCache.(DeserializationContext ctxt,DeserializerFactory factory, JavaType type)和com.fasterxml.jackson.databind.deser.DeserializerFactory.createBeanDeserializer(DeserializationContext ctxt, JavaType type, BeanDescription beanDesc)方法结合实际测试,设计了上面的静态方法createBeanDeserializer(Class<?> beanClass)实现从一个Java Bean类型创建一个BeanDeserializerBase实例。用于为JavaBeanDeserializer构造方法提供参数。
完整代码
以上FastjsonDeserializer,JacksonDeserializer的完整代码参见我的码云仓库:
https://gitee.com/l0km/sql2java/blob/master/sql2java-base/src/main/java/gu/sql2java/json/FastjsonDeserializer.java
https://gitee.com/l0km/sql2java/blob/master/sql2java-base/src/main/java/gu/sql2java/json/JacksonDeserializer.java