知识图谱生成
在之前章节中,我们尝试过让 ChatGPT 对一段文本做实体识别和词性分析,结果很不错。但如果是需要长期留存下来,后续在不同场景下快速查询分析,最好还是要把数据存入到专门的图数据库中,才能方便随时读取。本节,我们试试让 ChatGPT 直接把从文本中抽取到的知识图谱数据,存入最流行的图数据库 Neo4J 中。
这次我们换一个场景,不提供文本,试试看 ChatGPT 本身已有的知识储备量如何。
请你生成一部分红楼梦中的知识图谱,并转换成 neo4j 格式的数据插入语句。

结果超乎意料之外,ChatGPT 竟然表示自己虽然有红楼梦的知识,但无法生成 neo4j 的插入语句!
这回需要我们排查一下 prompt 问题了,就像我们排查代码一样。让我们先验证一下 ChatGPT 说自己懂红楼梦这句话是否真实:
请你以三元组的形式生成红楼梦中的知识图谱。

我们看到输出的结果,顺着内容越往后,准确度逐渐开始下降,"胡说"的成分开始变大。所以,为了更好的利用 ChatGPT 的文本生成能力,我们还是需要给出一些更明确的内容,效果更加。比如同样还是红楼梦,我们明确提供全书开头宝黛初见一章的一段文本,要求总结这段内容变为知识图谱试试:
抽取下面这段文本中的知识图谱。切记格式为(头实体、关系、尾实体)
黛玉方进入房时,只见两个人搀着一位鬓发如银的老母迎上来,黛玉便知是她外祖母。方欲拜见时,早被她外祖母一把搂入怀中,“心肝儿肉”叫着大哭起来。当下地下侍立之人,无不掩面涕泣,黛玉也哭个不住。一时众人慢慢的解劝住了,黛玉方拜见了外祖母。——此即冷子兴所云之史太君也,贾赦、贾政之母。 当下贾母一一指与黛玉:“这是你大舅母;这是你二舅母;这是你先珠大哥的媳妇珠大嫂子。”黛玉一一拜见过。贾母又说:“请姑娘们来。今日远客才来,可以不必上学去了。”众人答应了一声,便去了两个。 不一时,只见三个奶嬷嬷并五六个丫鬟,簇拥着三个姊妹来了。 第一个肌肤微丰,合中身材,腮凝新荔,鼻腻鹅脂,温柔沉默,观之可亲。 第二个削肩细腰,长挑身材,鸭蛋脸面,俊眼修眉,顾盼神飞,文彩精华,见之忘俗。 第三个身量未足,形容尚小。其钗环裙袄,三人皆是一样的妆饰。黛玉忙起身迎上来见礼,互相厮认过,大家归坐。丫鬟们斟上茶来。不过说些黛玉之母如何得病,如何请医服药,如何送死发丧。不免贾母又伤感起来,因说:“我这些儿女,所疼者独有你母亲,今日一旦先舍我去了,连面也不能一见,今见了你,我怎不伤心!”说着,搂了黛玉在怀,又呜咽起来。众人忙都宽慰解释,方略略止住。
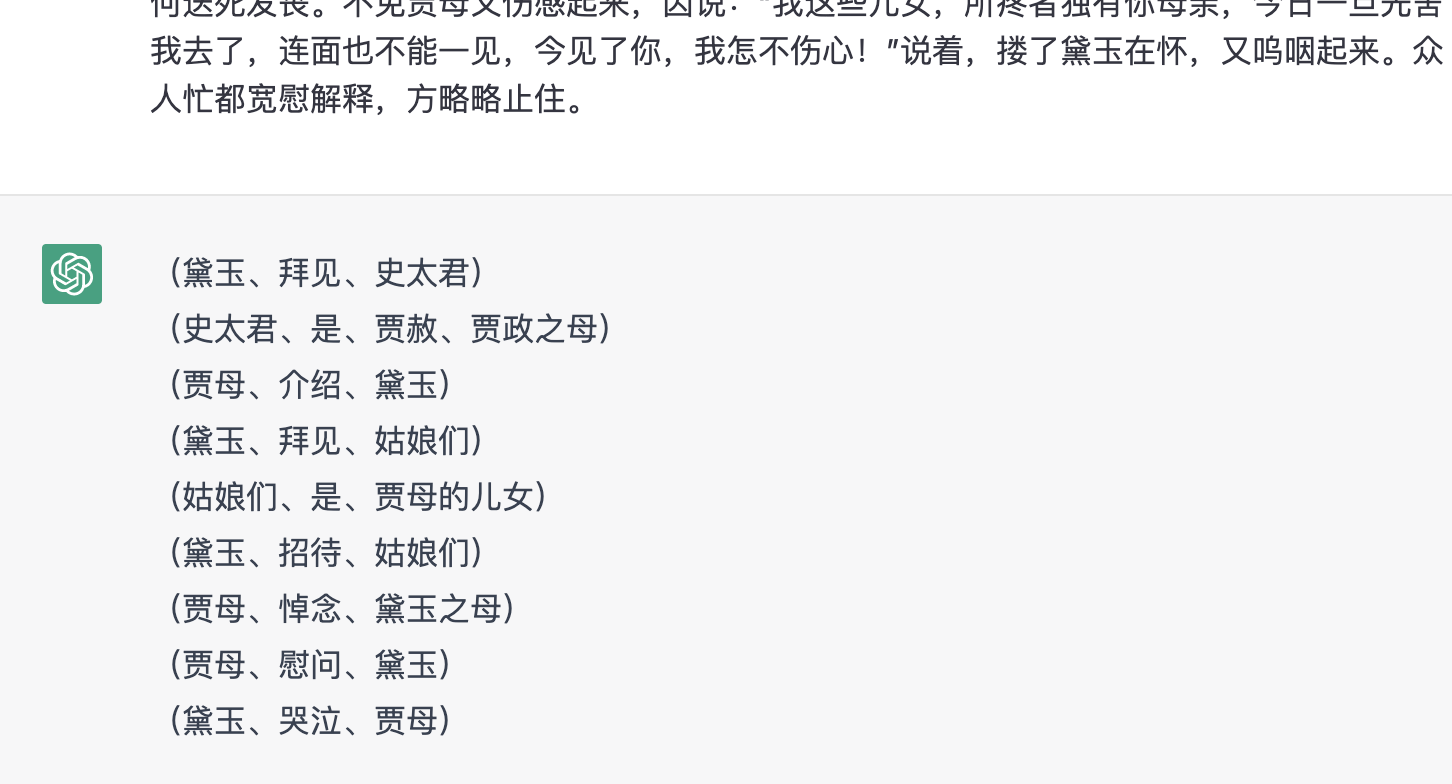
具体文本的总结能力还是比"记忆"要好的多。然后,让我们再继续排查 ChatGPT 生成 neo4j 语句的能力:
生成对应的 Neo4J 写入语句

也没问题。ChatGPT 两项能力都具备。那看来我们应该想办法优化最开头那句 prompt 了。之前我们曾经介绍过一些可以有效提高 ChatGPT 文本生成质量的咒语。从上面排查过程可以看到,分步运行都没有问题。那么 let's think step by step. 应该就适用于这个场景了。让我们在最开始失败的 prompt 后面加上这句:
请你生成一部分红楼梦中的知识图谱,并转换成 neo4j 格式的数据插入语句。let's think step by step.

慢慢思考过程较长,我们用 continue 提示 ChatGPT 继续完成:

我们可以发现,加上 let's think step by step 以后,不但可以直接生成 neo4j 的插入语句了,甚至连实体的属性输出的都更全面了,"贾宝玉"直接配上了年龄、状态、性格等一系列属性,真是太神奇了。











![Linux网络编程——网络基础[1]](https://img-blog.csdnimg.cn/img_convert/949c0312b6cf147693433566e0086d1c.png)