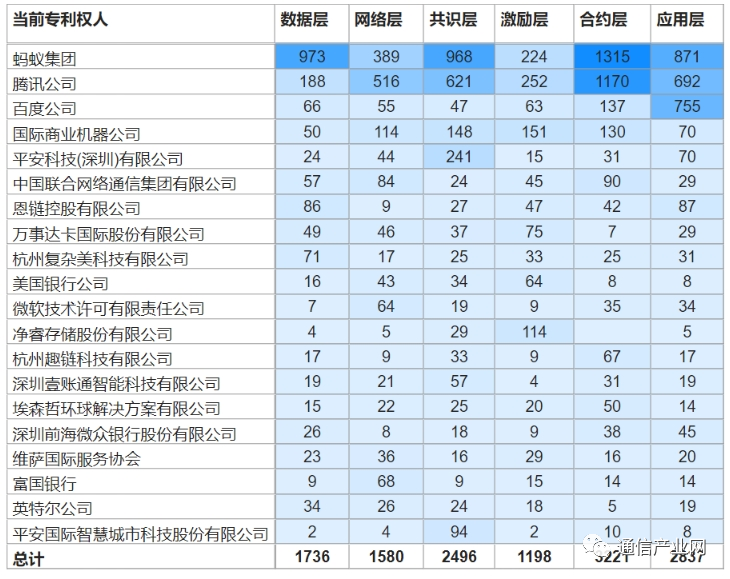
俄罗斯Yandex开发的ClickHouse是一款性能黑马的OLAP数据库,其对SIMD的灵活运用给其带来了难以置信的性能。本文我们聊聊它如何对过滤操作进行SIMD优化。
基本思想
1、有一个数组data,即ColumnVector::data,存放数据
2、使用uint8类型,即1个字节类型的filter数组:ICloumn::Filter。他的大小是data数组大小,里面存放布尔值,标记data数组里面哪些数据满足过滤条件,应该筛选出来
3、最终生成一个新的数组res,根据filter数组,对data数组进行筛选,满足条件的拷贝到res数组中。标量逻辑的简单伪码:
let res = []
for (let i = 0; i < data.size(); i ++) {
if (filter[i] != 0) {
res.append(data[i])
}
}Clickhouse如何实现的呢?
4、上面代码耗时因素在于循环次数非常多,等于data数组的大小
5、如果可以降低循环次数,同时保证单次循环耗时变化不大,总体执行效率更高。要满足上面条件,需要在同一个指令周期做更多运算,SIMD指令可以做这样的运算。
6、SIMD指令目前最大支持512位数据,而filter本身一个值为8位,单词循环处理数据量为512 / 8 = 64个
7、每次取出来64个filter数组项(64字节),将其组成一个64位无符号整数值mask,这样每个filter数组项占用一个比特位
8、有两种特殊情况:1)mask 64位比特位都是1,本次循环中,64个data项都应该拷贝到res中。2)mask 64位比特位都是0,可以直接跳过循环。当然,这两种特殊情况经常出现在业务常见中
9、第三中情况是有一部分满足条件,此时是否需要循环64次?有没有进一步的优化方法?看看clickhouse咋处理
10、有多少项需要拷贝到新数组,取决于mask中比特位为1的个数,通过__builtin_clzll内置函数得到入参(64位)二进制表示形式中开头0的个数,从而得到最高比特位为1的索引,继而知道哪项数据需要拷贝。
11、最高1比特位的数据项拷贝后,需要将它置成0,这里有2个比较高效的方法blsr函数:一个是_blsr_u64指令,另一个是mask & (mask-1)
12、循环设置最高1的比特位,直到mask中所有比特位都为0
ColumnVector<T>::filter函数
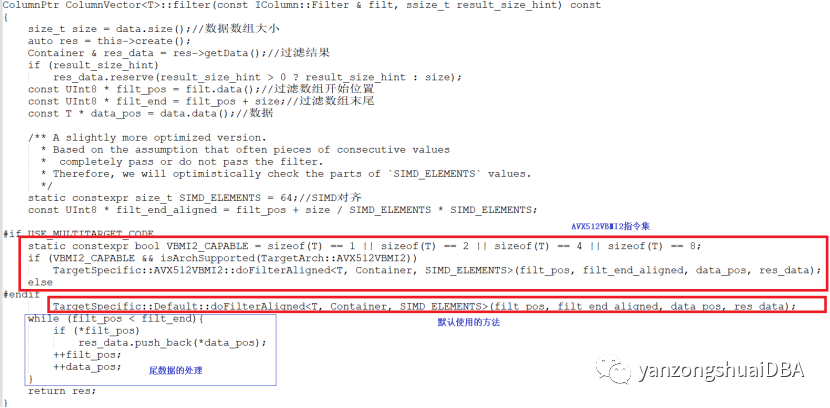
过滤函数主要是filter函数。其实分为3部分,AVX512VBMI2指令集、默认的操作和尾部数据处理。其中尾部数据处理是指处理数据不够64个时,剩余的部分处理方式,这种方式无法使用SIMD,沿用标量处理方式。
先看下默认操作方式:doFilterAligned即:模板函数

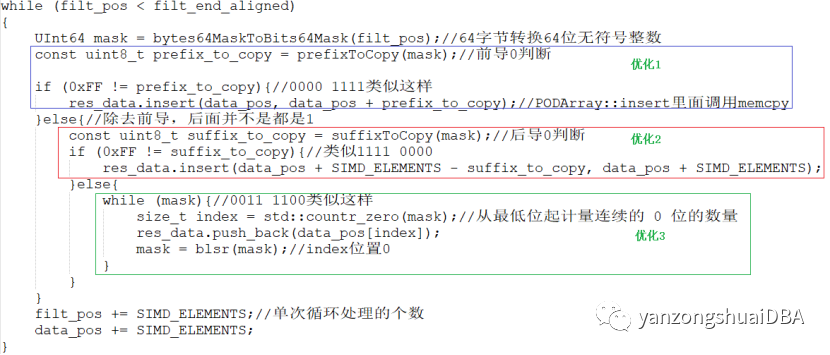
这部分其实是对有一部分值满足条件场景的优化,主要有3个方面:
1)前导0个数,即data数组data[0]--data[i]都满足条件,需要拷贝到结果中
2)后导0个数,即data数组data[i]--data[63]都满足条件,需要拷贝到结果中
3)其他场景,比如0011 1100的场景,即两边都有不满足条件的,那就需要特殊处理了:计算出最低位起0的个数index,然后将data_pos[index]拷贝到结果中,即该数组满足条件,最后将index位置为0。
前缀和后缀拷贝的判断:
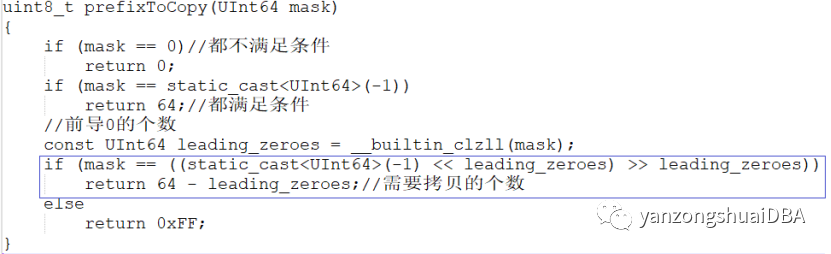
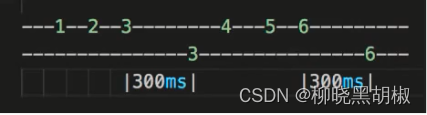
蓝色框表示的意义:其实是去除前导0后,剩余的都是1,即mask值。也就是从0的索引开始,到64 - leading_zeroes都需要拷贝到结果中。蓝框计算效果,以2个字节大小为例,前导5个0:

后导0的处理:其实可以调用__buitlin_ctzll函数
uint8_t suffixToCopy(UInt64 mask)
{
const auto prefix_to_copy = prefixToCopy(~mask);//mask值取反
return prefix_to_copy >= 64 ? prefix_to_copy : 64 - prefix_to_copy;//需要拷贝个数
}效果如下图所示:

64字节值转换成64位掩码值的计算函数Bytes64MaskToBits64Mask实现也很有讲究:
/// Transform 64-byte mask to 64-bit mask
inline UInt64 bytes64MaskToBits64Mask(const UInt8 * bytes64)
{
#if defined(__AVX512F__) && defined(__AVX512BW__)
const __m512i vbytes = _mm512_loadu_si512(reinterpret_cast<const void *>(bytes64));
UInt64 res = _mm512_testn_epi8_mask(vbytes, vbytes);
#elif defined(__AVX__) && defined(__AVX2__)
const __m256i zero32 = _mm256_setzero_si256();
UInt64 res =
(static_cast<UInt64>(_mm256_movemask_epi8(_mm256_cmpeq_epi8(
_mm256_loadu_si256(reinterpret_cast<const __m256i *>(bytes64)), zero32))) & 0xffffffff)
| (static_cast<UInt64>(_mm256_movemask_epi8(_mm256_cmpeq_epi8(
_mm256_loadu_si256(reinterpret_cast<const __m256i *>(bytes64+32)), zero32))) << 32);
#elif defined(__SSE2__)
const __m128i zero16 = _mm_setzero_si128();
UInt64 res =
(static_cast<UInt64>(_mm_movemask_epi8(_mm_cmpeq_epi8(
_mm_loadu_si128(reinterpret_cast<const __m128i *>(bytes64)), zero16))) & 0xffff)
| ((static_cast<UInt64>(_mm_movemask_epi8(_mm_cmpeq_epi8(
_mm_loadu_si128(reinterpret_cast<const __m128i *>(bytes64 + 16)), zero16))) << 16) & 0xffff0000)
| ((static_cast<UInt64>(_mm_movemask_epi8(_mm_cmpeq_epi8(
_mm_loadu_si128(reinterpret_cast<const __m128i *>(bytes64 + 32)), zero16))) << 32) & 0xffff00000000)
| ((static_cast<UInt64>(_mm_movemask_epi8(_mm_cmpeq_epi8(
_mm_loadu_si128(reinterpret_cast<const __m128i *>(bytes64 + 48)), zero16))) << 48) & 0xffff000000000000);
#elif defined(__aarch64__) && defined(__ARM_NEON)
const uint8x16_t bitmask = {0x01, 0x02, 0x4, 0x8, 0x10, 0x20, 0x40, 0x80, 0x01, 0x02, 0x4, 0x8, 0x10, 0x20, 0x40, 0x80};
const auto * src = reinterpret_cast<const unsigned char *>(bytes64);
const uint8x16_t p0 = vceqzq_u8(vld1q_u8(src));
const uint8x16_t p1 = vceqzq_u8(vld1q_u8(src + 16));
const uint8x16_t p2 = vceqzq_u8(vld1q_u8(src + 32));
const uint8x16_t p3 = vceqzq_u8(vld1q_u8(src + 48));
uint8x16_t t0 = vandq_u8(p0, bitmask);
uint8x16_t t1 = vandq_u8(p1, bitmask);
uint8x16_t t2 = vandq_u8(p2, bitmask);
uint8x16_t t3 = vandq_u8(p3, bitmask);
uint8x16_t sum0 = vpaddq_u8(t0, t1);
uint8x16_t sum1 = vpaddq_u8(t2, t3);
sum0 = vpaddq_u8(sum0, sum1);
sum0 = vpaddq_u8(sum0, sum0);
UInt64 res = vgetq_lane_u64(vreinterpretq_u64_u8(sum0), 0);
#else
UInt64 res = 0;
for (size_t i = 0; i < 64; ++i)
res |= static_cast<UInt64>(0 == bytes64[i]) << i;
#endif
return ~res;
}我们看到,按照优先级尽可能利用位数多的指令集进行计算,同时在所有指令集都不可用及未64字节对齐(align)的部分进行了保底处理。其利用了以下指令集:
AVX512F / AVX512BW
AVX/AVX2
SSE2
其中,_mm512_testn_epi8_mask函数功能:计算a和b两个入参值按8位整数逐位与(AND),产生中间8位值,如果中间值为0,则在结果掩码k中设置相应位:
FOR j := 0 to 63
i := j*8
k[j] := ((a[i+7:i] AND b[i+7:i]) == 0) ? 1 : 0
ENDFOR
所以,bytes64MaskToBits64Mask最终计算出的值需要取反。另外,其他指令集,比如AVX下,_mm256_cmpeq_epi8比较32位是否等于0,等于0表示不满足条件,当然等于零时该函数返回0xFF,所以同样最终结果需要取反。
另外一种操作方式:doFilterAligned即:模板函数

主要是通过_mm512_mask_compressstoreu_epi8类似函数分别对1、2、4、8字节长度类型针对掩码进行数据拷贝,这里不再赘述。
参考
https://zhuanlan.zhihu.com/p/454657709
https://blog.csdn.net/u010002184/article/details/113977586
https://blog.51cto.com/u_15103025/2643507
https://zhuanlan.zhihu.com/p/449154820
https://www.zhihu.com/question/450069375/answer/1813516193
https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html