🤵♂️ 个人主页@老虎也淘气 个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注
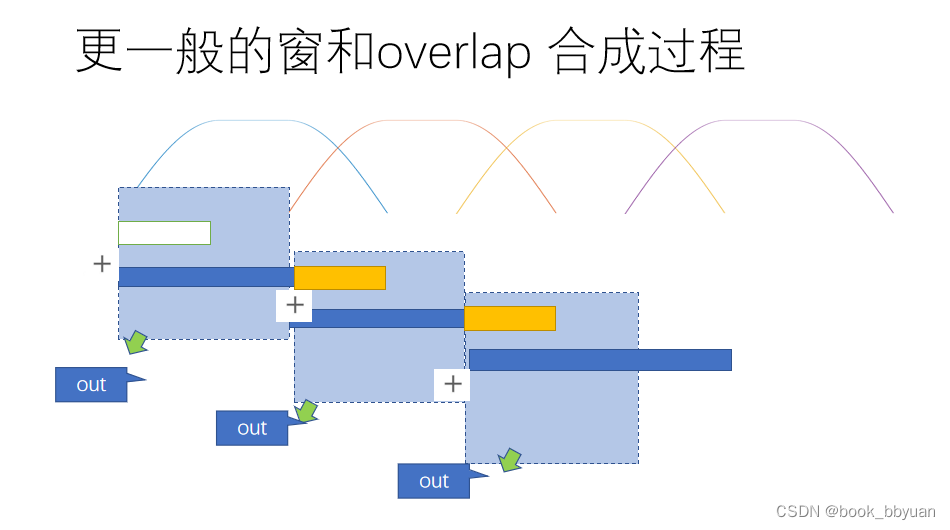
分享 10 个日常使用的脚本
- 1、测网速,选择最佳服务器
- 2、使用 google 搜索关键词
- 3、Web 机器人
- 4、获取图片的 exif 信息
- 5、OCR
- 6、将照片转换为卡通图片
- 7、清空 recycle.bin
- 8、pdf 转图片
- 9、Hex 转 RGB
- 10、检查网站是否下线
1、测网速,选择最佳服务器
这个脚本可以测试上传、下载速度,也提供了函数 get_best_server 来选择最佳服务器,在客户端和多服务器模式中非常实用。
脚本:
# pip install pyspeedtest
# pip install speedtest
# pip install speedtest-cli
#方法1
import speedtest
speedTest = speedtest.Speedtest()
print(speedTest.get_best_server())
#检查下载速度
print(speedTest.download())
#检查上传速度
print(speedTest.upload())
#方法2
import pyspeedtest
st = pyspeedtest.SpeedTest()
st.ping()
st.download()
st.upload()
2、使用 google 搜索关键词
有时候为了引导用户使用搜索引擎,我们可以直接将错误关键词用 google 搜索下,将结果显示在界面上,这样用户可以直接点击链接来查看搜索结果,很方便,不需要再复制关键词,打开浏览器搜素等一系列麻烦。
#pip install google
from googlesearch import search
query = "somenzz"
for url in search(query):
print(url)
print 的结果就是 google 搜索结果的 url 列表,类似的,百度和 bing 也应该有对应的库,你可以搜索以下。
3、Web 机器人
这个咱之前已经分享过了,selenium 和 playwright 都可以,我个人更喜欢 playwright
selenium 示例代码:
# pip install selenium
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
bot = webdriver.Chrome("chromedriver.exe")
bot.get('http://www.google.com')
search = bot.find_element_by_name('q')
search.send_keys("somenzz")
search.send_keys(Keys.RETURN)
time.sleep(5)
bot.quit()
playwright 示例代码:
#pip install playwright
#playwright install
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto("http://playwright.dev")
print(page.title())
browser.close()
4、获取图片的 exif 信息
有两种方法获取,一个是使用 pillow,一个是使用 exifread:
# Get Exif of Photo
# Method 1
# pip install pillow
import PIL.Image
import PIL.ExifTags
img = PIL.Image.open("Img.jpg")
exif_data =
{
PIL.ExifTags.TAGS[i]: j
for i, j in img._getexif().items()
if i in PIL.ExifTags.TAGS
}
print(exif_data)
# Method 2
# pip install ExifRead
import exifread
filename = open(path_name, 'rb')
tags = exifread.process_file(filename)
print(tags)
5、OCR
OCR 的全称是 Optical Character Recognition,即光学字符识别,通俗点讲就是文字识别,这里有个很简单的脚本,适用于 Windows,不过需要你在 GitHub 上下载 tesseract.exe[1]。
# pip install pytesseract
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
t=Image.open("img.png")
text = pytesseract.image_to_string(t, config='')
print(text)
6、将照片转换为卡通图片
# pip install opencv-python
import cv2
img = cv2.imread('img.jpg')
grayimg = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
grayimg = cv2.medianBlur(grayimg, 5)
edges = cv2.Laplacian(grayimg , cv2.CV_8U, ksize=5)
r,mask =cv2.threshold(edges,100,255,cv2.THRESH_BINARY_INV)
img2 = cv2.bitwise_and(img, img, mask=mask)
img2 = cv2.medianBlur(img2, 5)
cv2.imwrite("cartooned.jpg", mask)
7、清空 recycle.bin
recycle.bin 是系统回收站在每一个磁盘上的链接文件夹,用于保存磁盘上删除的文件或者文件夹信息,是系统重要的隐藏文件;默认情况下,会占用用户设置过的磁盘的容量,因此,用户清空回收站之后不会释放空间。
# pip install winshell
import winshell
try:
winshell.recycle_bin().empty(confirm=False, show_progress=False, sound=True)
print("Recycle bin 已本清空")
except:
print("Recycle bin 是空文件")
8、pdf 转图片
将 pdf 文件转成多个图片
import fitz
pdf = 'sample_pdf.pdf'
doc = fitz.open(pdf)
for page in doc:
pix = page.getPixmap(alpha=False)
pix.writePNG('page-%i.png' % page.number)
9、Hex 转 RGB
def Hex_to_Rgb(hex):
h = hex.lstrip('#')
return tuple(int(h[i:i+2], 16) for i in (0, 2, 4))
print(Hex_to_Rgb('#c96d9d')) # (201, 109, 157)
print(Hex_to_Rgb('#fa0515')) # (250, 5, 21)
10、检查网站是否下线
我们可以通过 http 的状态码判断一个网站的服务是否正常运行。
# pip install requests
# 方法 1
import urllib.request
from urllib.request import Request, urlopen
req = Request('https://somenzz.cn', headers={'User-Agent': 'Mozilla/5.0'})
webpage = urlopen(req).getcode()
print(webpage) # 200
# 方法 2
import requests
r = requests.get("https://somenzz.cn")
print(r.status_code) # 200






![[C]实现能在本地存储的简易通讯录](https://img-blog.csdnimg.cn/d2bf25fd4ccf45d7b6617edb9a98a740.png)