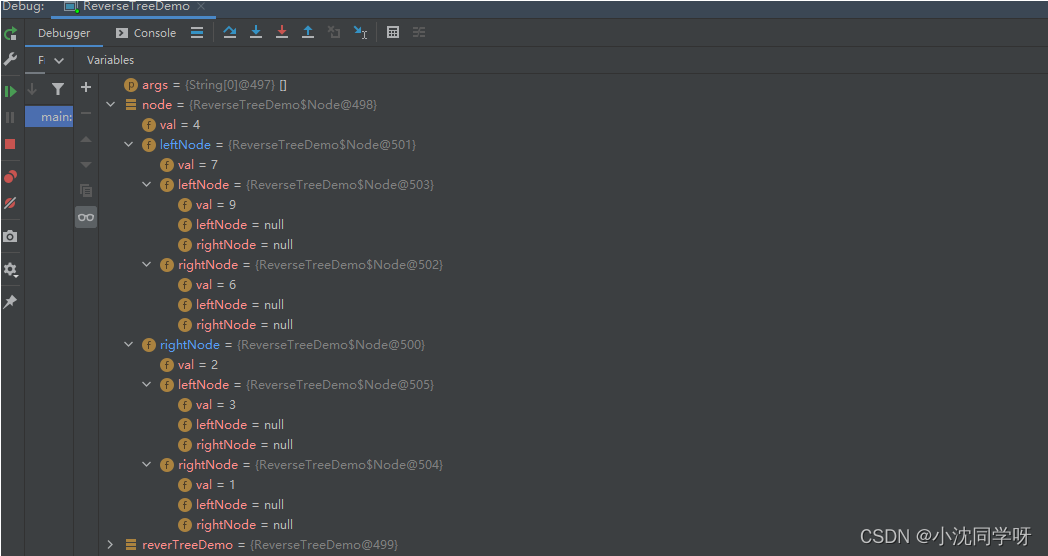
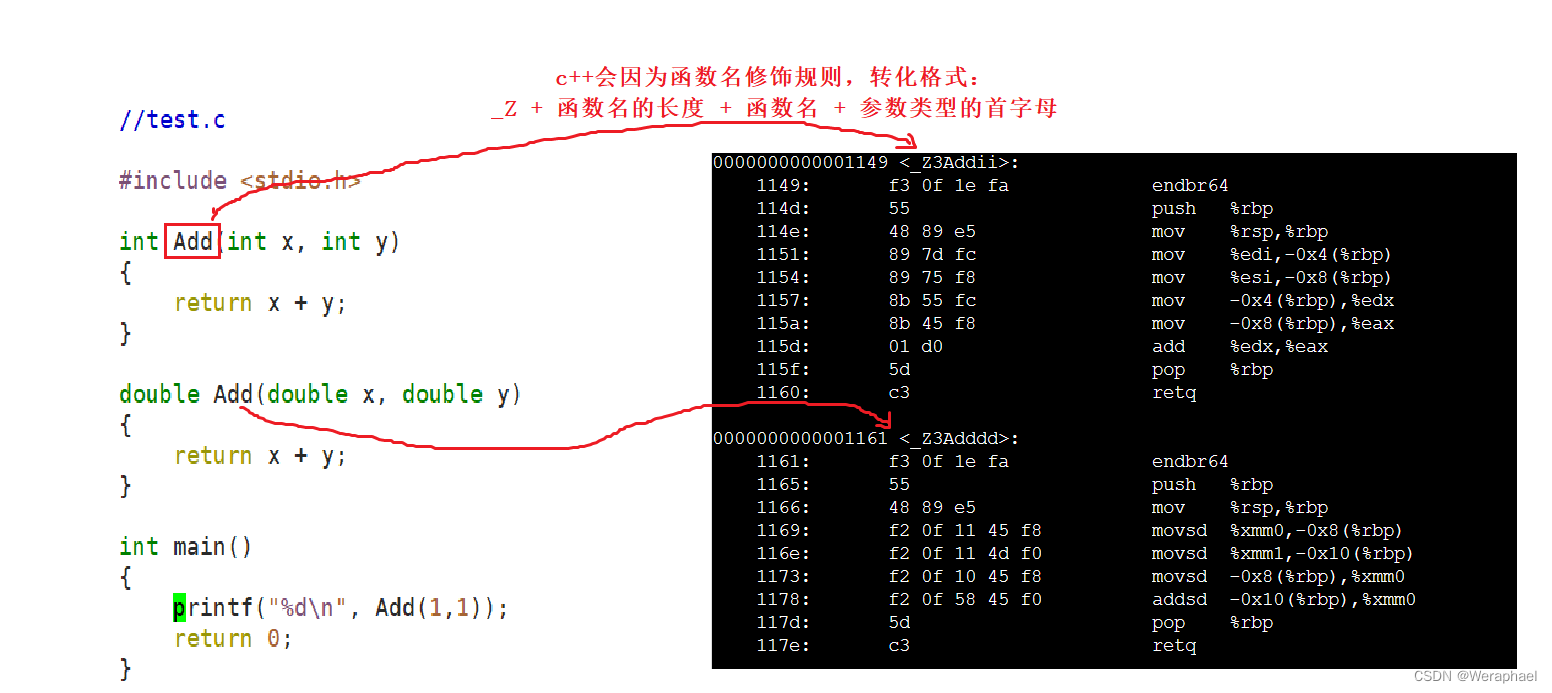
行人重识别:短时
- 类内差异增大,类间差异减小
应用——行人跟踪
- 单摄像头单目标
- 单摄像头多目标
- 多摄像头多目标
行人重识别系统
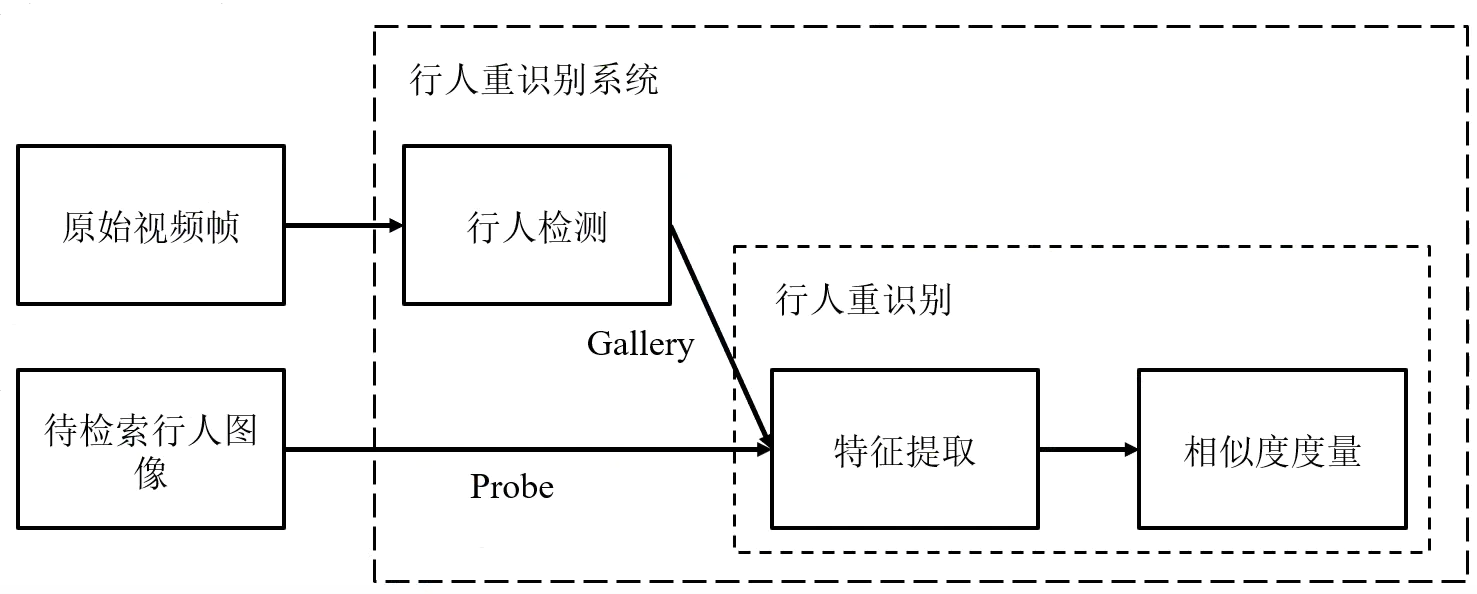
-
特征提取
学习能够应对在不同摄像头下行人变化的特征
-
度量学习
将学习到的特征映射到新的空间使相同的人更近,不同的人更远
-
图像检索
根据图片特征之间的距离进行排序,返回检索结果
评价模式
-
single query vs multi query
Single query是指probe中每个人的图像为一张(N=1),而multi query是指probe中每个人的图像为N>1张图像,然后融合N张图片的特征(最大池化或者平均池化)作为最终特征。同样的Rank-k下,一般N越大,得到的识别率越高。
特征
全局特征
每一张图片的全局信息进行一个特征抽取,全局特征没有任何的空间信息。
- 噪声区域会对全局特征造成极大的干扰
- 姿态的不对齐也会使全局特征无法匹配
局部特征
对图像的某一个区域进行特征提取,最后将多个局部特征融合起来作为最终特征
水平切块 ★★★
-
将图像进行水平方向的等分,每一个水平切块通过水平池化提取一个特征
-
Gate Siamese 和 AlignedReID 通过设计规则融合所有的局部特征计算距离
-
PCB,ICNN,SCPNet 对每一个局部特征计算一个 ReID 损失,直接将局部特征拼接起来
-
联合局部特征和全局特征往往能够得到更好的结果
Gate Siamese
- 每一块经过 CNN 网络得到特征,局部特征按顺序输入到 LSTM 网络,自动表达为图像最终的特征
- 利用对比损失训练网络
AlignedReID
-
主要解决姿态不对齐的问题
-
骨架网络为 ResNet50
动态对齐 (DMLI)
- 假如输入图像为256×128,输出的特征图尺寸为 8×4×2048
- 利用水平池化得到 8 个局部特征,并计算一个 8×8 的距离方阵
- 对齐局部信息不能有跳连(从上到下)
- 利用 shortest path 来找到最优的动态连接
PCB
- 输入图像 384×128,分成 6 块
- 利用 ResNet50 提取特征,最后 24×8 的 feature map
- 每一行提取一个局部特征,连接一个 ReID loss
- 使用的时候把 6 个局部特征 concatenate 起来
ICNN
ICNN≈PCB + global branch with triplet loss
SCPNet
利用 spatial part 特征连监督 channel group 特征,将 local feature 传给 global feature
姿态信息 ★★★
- 利用一个姿态估计模型得到行人的(14个)关键姿态点
- 根据姿态点得到具有语义信息的 part 区域
- 对于每个 part 区域提取局部特征
- 联合局部特征和全局特征往往能够得到更好的结果
- 姿态点估计模型:Hourglass、OpenPose、CPM、AlphaPose
- Part:通过一定规则手工设置一些矩形框区域
- Attention:网络自动学习出的比较重要的任意形状区域
PIE
- CRM 提取姿态点
- 分成几个part,进行仿射变换对齐
- 融合原图和仿射图的特征
- 采用 ID 损失训练网络
Spindle Net
- FFN 网络提取特征,FFN 网络层次性地融合特征
PDC
- 利用姿态点信息分割为六个part
- 改进 STN 网络为 PTN 网络,学习仿射变换参数得到 modified part image
- 融合全局特征和局部特征
- 计算三个 ReID 损失
- 浅层网络共享,高层网络独立
GLAD
- 分为头,上身,下身三个 part
- 融合全局特征和三个 part 的特征
PABP
- 利用 ReID 网络提取 feature map A
- 利用 openpose 提取 feature map P
- A 和 R 每个对应像素位置的向量进行外积,并向量化
- 会激活对应位置的外观特征
分割信息 ★★
- 图像语义分割是一种极精细的像素级别 part 信息
- 图像分割分为粗粒度的行人前景分割和细粒度的肢体语义分割
- 分割结果通常作为图像预处理的 Mask 或者 feature map 中的 attention 相乘
- 目前基于分割的方法没有取得特别广泛的应用
前背景提取
SPReID
网格特征 ★
- 网格特征是比较细粒度的物理区域特征
- 早期工作将网格特征扩展为part特征计算两幅图像的特征图差
- 近期利用网格特征解决 partial ReID 工作
- 总体而言网格特征并不常用
IDLA
- 骨干网络为 Siamese 网络计算
- 两幅图 5x5 网格特征差值
- 交换"主客"分别计算 K 和 K’
- 计算二分类验证损失
PersonNet
DSR
- 将一副图像的所有网格特征作为一个特征集合
- 对两个特征集合进行稀疏重建得到集合距离
序列重识别

- 姿态变化丰富
- 遮挡现象普遍
- 总有几帧质量好,也有几帧质量差
- 需要考虑如何融合各帧的信息
单帧 → 序列
- 对每一帧图像都提取一个ReID特征
- 直接通过平均池化或者最大池化来得到最终的ReID特征
- 比较简单,性能依赖于单帧 ReID 的性能
CNN+LSTM
- 类似于动作识别,利用 CNN 提取特征,然后利用 LSTM 提取时序特征
难点
- 如何对多帧特征进行特征融合?
- 如何对每帧图像进行质量判断?
- 如何提取序列图像的运动特征?
- 如何解决序列帧数不统一问题?
- 如何提高序列 ReID 的运算效率?
学术尝试
AMOC
- 帧与帧之间存在着运动(步态)特征,也有利于 ReID 任务
- 包含空间子网络和运动子网络
- 空间子网络提取单帧图像的内容特征
- 运动子网络提取相邻两帧的运动特征
- 融合内容特征与运动特征作为该帧的最终特征
- 利用 RNN 网络融合所有帧的特征信息
- 利用对比损失判断两个序列是否属于同一个行人ID
DFGP
- 采用传统的 LOMO 特征提取序列每一帧图像的行人特征
- 利用 PCN 网络提取每一帧特征,之后平均池化得到序列特征,找到最稳定帧 MSVP
- 对 MSVP 提取 LOMO 特征,并与序列q计算特征距离,按照距离进行 softmin 归一化,得到每帧权重
- 特征×权重之后进行最大池化
- 融合池化后的序列特征和最稳定帧的特征作为最终特征
RQEN
- 遮挡是序列重识别中非常普遍的一个问题,会造成特征分布不均匀
-
对每帧行人提取14个关键姿态点,并分为3个语义 part
-
当某个姿态点被遮挡之后,pose map 的响应值会非常低
- 全局分支提取全局特征
- 局部分支提取局部特征
- 姿态分支对图像进行质量(遮挡)判断
基于 GAN 的方法
痛点
- 数据不够用 → 生成图像
- 政府限制监控数据的采集
- 人工标注采集数据价格昂贵
- 缺乏一些极难的极端样本
- 数据有偏差 → 减小偏差
- 姿态与姿态之间存在偏差
- 相机与相机之间存在偏差
- 地域与地域之间存在偏差
组成
- 生成器:随机数 → 生成样本
- 判别器:判断生成样本是否真实
代表方法
GAN+LSRO
利用 GAN 网络随机生成行人图片,利用 LSRO 技术平滑 ID 标签,训练交叉熵损失
- 照片随机生成,ID 信息不可靠
CamStyle
利用 CycleGAN 来实现任意两个相机之间的风格转换
- 原始样本计算ID损失,生成样本利用平滑标签计算交叉熵损失
PTGAN
不同场景下采集的数据存在明显的偏差
- 利用 PSPNet 分割行人前景 mask
- 利用 CycleGAN 的思想进行图像风格转换
- 计算mask区域生成损失,保持行人前景尽可能不变
- 联合风格损失与生成损失
SPGAN
与 PTGAN 类似,利用 source domain 的数据生成 target domain,解决不同场景下采集的数据间的明显偏差
PNGAN
利用 GAN 来生成固定姿态样本
- 利用 GAN 生成目标姿态的样本
- 原图和生成图分别进入两个 ReID 网络
- 融合原图和生成图的特征作为最终特征,融合方式使用max池化
对比
| 算法 | GAN | CycleGAN | PTGAN | SPGAN | PNGAN |
|---|---|---|---|---|---|
| 基础 | GAN | CycleGAN | CycleGAN | CycleGAN | InfoGAN |
| 额外 | 标签平滑 | 标签平滑 | 前景分割 | 孪生网络 | 姿态估计 |
| 目标 | 数据增广 | 相机偏差 | 数据域偏差 | 数据域偏差 | 姿态偏差 |