本文要介绍的是由哈尔滨工业大学联合华为发表论文《DeepFM: A Factorization-Machine based Neural Network for CTR Prediction》中提出的DeepFM模型。其实根据名字可以看出来,此模型包含Deep和FM两个部分。其中Deep部分就是普通的深度神经网络,FM是因子分解机(Factorization Machine),用于来做特征交叉。
DeepFM实际上是将FM模型与Wide&Deep模型进行了整合。DeepFM对Wide&Deep模型的改进之处在于,它使用了FM来替换了原来的Wide部分,加强了浅层网络部分特征组合的能力。
为了更好地理解DeepFM模型,读者最好先了解一下FM模型和Wide&Deep模型。
介绍
在推荐系统中,学习隐藏在用户行为数据背后的复杂特征交互对最大化CTR任务起着重要的作用,而提高CTR的预估准确率能够直接为企业带来丰厚的利益。
很多在线广告系统是根据CTR*bid来对候选广告进行排名的,其中bid代表用户每次点击广告时系统能获得的收益。
学习用户点击行为背后的隐藏特征交互对CTR预估任务来说十分重要。作者通过对主流的app应用市场调查研究发现,用户常常在用餐时间下载外卖类app,这就是一种对”app类别“和“时间”这两种特征的二阶交互信息,这类的二阶交互信息可以用于CTR预估任务。
再比如,男性青少年偏爱射击类和角色扮演游戏,这些信息是3阶的。即包含了”性别“,”年龄“和”app类别“,这也有助于CTR预估任务。这些用户行为背后的特征交互是非常复杂的,这些特征包括了低阶和高阶的交互信息。
2016年谷歌提出的Wide & Deep模型对特征进行了低阶和高阶交互,整体上提高了模型性能。然而,Wide&Deep模型中的”Wide“部分仍然需要依赖手工特征提取。
DeepFM模型
为了能够同时进行低阶和高阶的特征融合,并且以端到端的方式训练,论文作者提出了DeepFM模型,模型结构图如下:
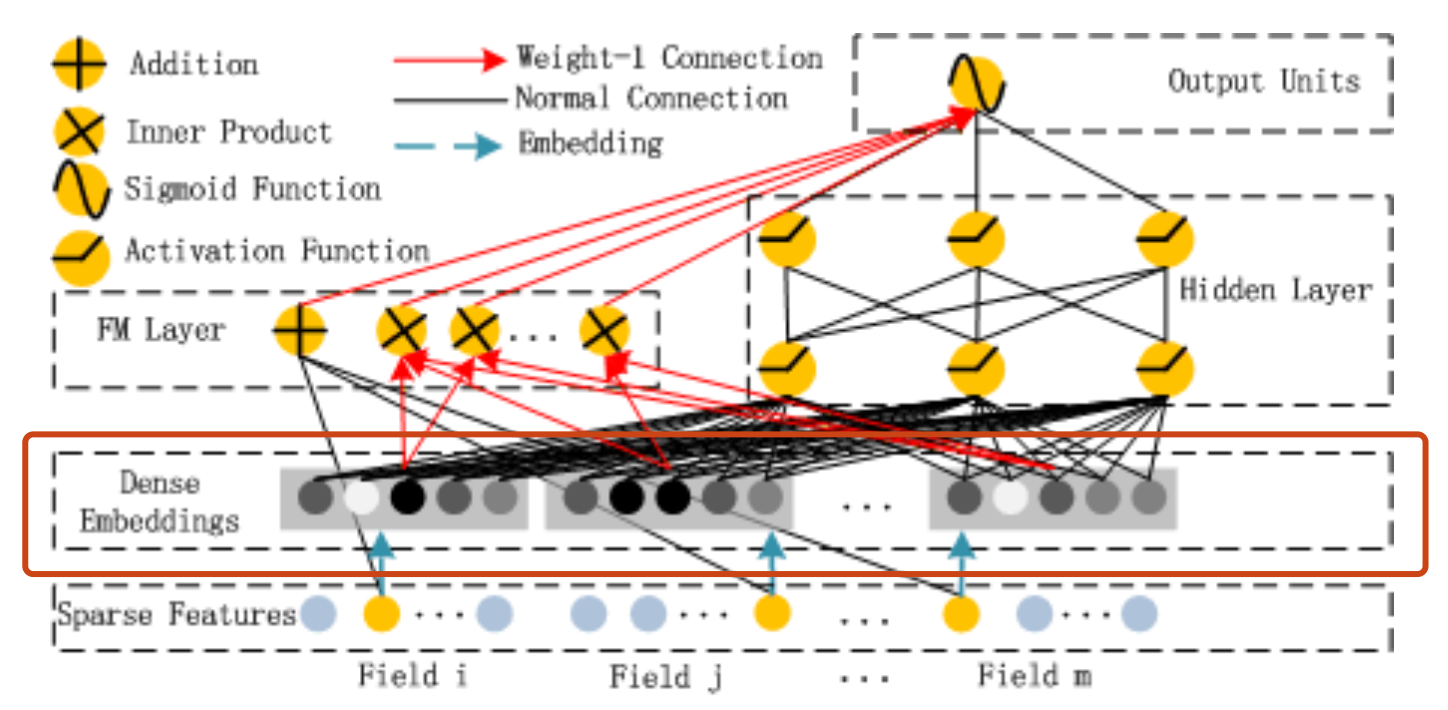
DeepFM模型
DeepFM模型实际上延续了Wide&Deep双模型组合的结构。它使用FM去替换了Wide&Deep中的Wide部分,加强了浅层网络部分特征组合的能力。上图中,左侧的FM部分与右侧的Deep神经网络部分共享同样的Embedding层。左侧的FM部分对不同的特征域的Embedding进行了两两交叉,也就是将Embedding向量当做原FM中的特征隐向量。最后将FM的输出与Deep部分的输出一同输入到最后的输出层,参与最后的目标拟合。
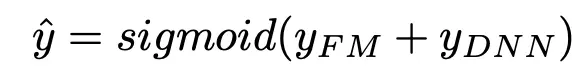
下面依次从FM和Deep两个部分来详细描述DeepFM模型。
FM部分
FM部分的结构图如下:

FM部分结构图

Deep部分
Deep部分就更简单了,就是一个前向深度网络,它用来学习更高阶的特征交互。Deep部分如下:

Deep部分结构图
这里的DNN与图像或者音频领域使用的DNN不同,这些领域的输出数据通常都是连续且稠密的。而CTR预估任务中的数据通常是极度稀疏,超高维的,并且是类别数据和连续数据混合的,因此需要从网络结构上进行改变。因此在输入数据和Hidden Layer中间有一个Dense EMbeddings层,它的主要作用就是将稀疏高维的数据压缩成稠密的实数向量。
输入层到Embedding层的子网络结构如下图所示:

Embedding层结构
这里需要指出这个网络结构的两个有趣的特性:
- 尽管输入向量长度可能不同,但是他们的Embedding大小都是相同的。
- FM中的隐向量现在直接变成了DeepFM模型中的网络权重参数,它们被用来将输入数据压缩成embedding向量。
FFN模型使用的是一个预训练好的FM用来做网络参数初始化,而DeepFM是相当于直接把FM集成到了模型内部,跟着模型一起训练优化。这样就消除了FM的预训练过程,整个网络就可以使用端到端的方式来进行训练了。我们可以将Embedding层的输出表示为:


特别值得注意的是,FM部分和Deep部分是共享同样的特征embedding表示的,这样做带来了两个好处:
- 它可以同时从原始特征中学习低阶和高阶的特征组合
- 无需对输入进行额外的特征工程,而在Wide&Deep中是需要的
DeepFM与其他神经网络对比
作者将DeepFM与FNN、PNN、Wide&Deep等进行了对比,分别分析了各自的优缺点,总结出了下表:

模型对比
可以看到DeepFM模型是唯一一个不需要预训练和特征工程,且可以同时捕获低阶和高阶特征交互的模型。
完整源码&技术交流
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
文章中的完整源码、资料、数据、技术交流提升, 均可加知识星球交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:mlc2060,备注:来自 获取推荐资料
方式②、微信搜索公众号:机器学习社区,后台回复:推荐资料
代码实践
模型部分:
import torch
import numpy as np
import torch.nn as nn
import torch.utils.data as Data
from torch.utils.data import DataLoader
import torch.optim as optim
import torch.nn.functional as F
from sklearn.metrics import log_loss, roc_auc_score
from collections import OrderedDict, namedtuple, defaultdict
from BaseModel.basemodel import BaseModel
class DeepFM(BaseModel):
def __init__(self, config, feat_sizes, sparse_feature_columns, dense_feature_columns):
super(DeepFM, self).__init__(config)
self.feat_sizes = feat_sizes
self.device = config['device']
self.sparse_feature_columns = sparse_feature_columns
self.dense_feature_columns = dense_feature_columns
self.embedding_size = config['ebedding_size']
self.l2_reg_linear = config['l2_reg_linear']
# self.feature_index 建立feature到列名到输入数据X的相对位置的映射
self.feature_index = self.build_input_features(self.feat_sizes)
self.bias = nn.Parameter(torch.zeros((1,)))
# self.weight
self.weight = nn.Parameter(torch.Tensor(len(self.dense_feature_columns), 1)).to(self.device)
torch.nn.init.normal_(self.weight, mean=0, std=0.0001)
# FM的Linear部分,即对每一个特征乘上一个权重系数,由于有稠密和稀疏特征,因此这里分为了两部分。
self.embedding_dict1 = self.create_embedding_matrix(self.sparse_feature_columns, feat_sizes, 1, device=self.device)
self.embedding_dict2 = self.create_embedding_matrix(self.sparse_feature_columns, feat_sizes, self.embedding_size, device=self.device)
# Deep
self.dropout = nn.Dropout(self._config['dnn_dropout'])
self.dnn_input_size = self.embedding_size * len(self.sparse_feature_columns) + len(self.dense_feature_columns)
hidden_units = [self.dnn_input_size] + self._config['dnn_hidden_units']
self.linears = nn.ModuleList(
[nn.Linear(hidden_units[i], hidden_units[i + 1]) for i in range(len(hidden_units) - 1)])
self.relus = nn.ModuleList(
[nn.ReLU() for i in range(len(hidden_units) - 1)])
for name, tensor in self.linears.named_parameters():
if 'weight' in name:
nn.init.normal_(tensor, mean=0, std=config['init_std'])
self.dnn_linear = nn.Linear(
self._config['dnn_hidden_units'][-1], 1, bias=False).to(self.device)
self.to(self.device)
def forward(self, X):
'''
FM liner
'''
sparse_embedding_list1 = [self.embedding_dict1[feat](
X[:, self.feature_index[feat][0]:self.feature_index[feat][1]].long())
for feat in self.sparse_feature_columns]
dense_value_list2 = [X[:, self.feature_index[feat][0]:self.feature_index[feat][1]]
for feat in self.dense_feature_columns]
linear_sparse_logit = torch.sum(torch.cat(sparse_embedding_list1, dim=-1), dim=-1, keepdim=False)
linear_dense_logit = torch.cat(dense_value_list2, dim=-1).matmul(self.weight)
logit = linear_sparse_logit + linear_dense_logit
sparse_embedding_list = [self.embedding_dict2[feat](
X[:, self.feature_index[feat][0]:self.feature_index[feat][1]].long())
for feat in self.sparse_feature_columns]
'''
FM second
'''
fm_input = torch.cat(sparse_embedding_list, dim=1) # shape: (batch_size,field_size,embedding_size)
square_of_sum = torch.pow(torch.sum(fm_input, dim=1, keepdim=True), 2) # shape: (batch_size,1,embedding_size)
sum_of_square = torch.sum(torch.pow(fm_input, 2), dim=1, keepdim=True) # shape: (batch_size,1,embedding_size)
cross_term = square_of_sum - sum_of_square
cross_term = 0.5 * torch.sum(cross_term, dim=2, keepdim=False) # shape: (batch_size,1)
logit += cross_term
'''
DNN
'''
# sparse_embedding_list、 dense_value_list2
dnn_sparse_input = torch.cat(sparse_embedding_list, dim=1)
batch_size = dnn_sparse_input.shape[0]
# print(dnn_sparse_input.shape)
dnn_sparse_input=dnn_sparse_input.reshape(batch_size,-1)
# dnn_sparse_input shape: [ batch_size, len(sparse_feat)*embedding_size ]
dnn_dense_input = torch.cat(dense_value_list2, dim=-1)
# print(dnn_sparse_input.shape)
# dnn_dense_input shape: [ batch_size, len(dense_feat) ]
dnn_total_input = torch.cat([dnn_sparse_input, dnn_dense_input], dim=-1)
deep_input = dnn_total_input
for i in range(len(self.linears)):
fc = self.linears[i](deep_input)
fc = self.relus[i](fc)
fc = self.dropout(fc)
deep_input = fc
dnn_output = self.dnn_linear(deep_input)
logit += dnn_output
'''
output: sigmoid(DNN + FM)
'''
y_pred = torch.sigmoid(logit+self.bias)
return y_pred
def fit(self, train_input, y_label, val_input, y_val, batch_size=5000, epochs=15, verbose=5):
x = [train_input[feature] for feature in self.feature_index]
for i in range(len(x)):
if len(x[i].shape) == 1:
x[i] = np.expand_dims(x[i], axis=1) # 扩展成2维,以便后续cat
# 构造torch 数据加载器
train_tensor_data = Data.TensorDataset(torch.from_numpy(np.concatenate(x, axis=-1)), torch.from_numpy(y_label))
train_loader = DataLoader(dataset=train_tensor_data,shuffle=True ,batch_size=batch_size)
print(self.device, end="\n")
model = self.train()
loss_func = F.binary_cross_entropy
# loss_func = F.binary_cross_entropy_with_logits
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay = 0.0)
# optimizer = optim.Adagrad(model.parameters(),lr=0.01)
# 显示 一次epoch需要几个step
sample_num = len(train_tensor_data)
steps_per_epoch = (sample_num - 1) // batch_size + 1
print("Train on {0} samples, {1} steps per epoch".format(
len(train_tensor_data), steps_per_epoch))
for epoch in range(epochs):
loss_epoch = 0
total_loss_epoch = 0.0
train_result = {}
pred_ans = []
true_ans = []
with torch.autograd.set_detect_anomaly(True):
for index, (x_train, y_train) in enumerate(train_loader):
x = x_train.to(self.device).float()
y = y_train.to(self.device).float()
y_pred = model(x).squeeze()
optimizer.zero_grad()
loss = loss_func(y_pred, y.squeeze(),reduction='mean')
#L2 norm
loss = loss + self.l2_reg_linear * self.get_L2_Norm()
loss.backward(retain_graph=True)
optimizer.step()
total_loss_epoch = total_loss_epoch + loss.item()
y_pred = y_pred.cpu().data.numpy() # .squeeze()
pred_ans.append(y_pred)
true_ans.append(y.squeeze().cpu().data.numpy())
if (epoch % verbose == 0):
print('epoch %d train loss is %.4f train AUC is %.4f' %
(epoch,total_loss_epoch / steps_per_epoch,roc_auc_score(np.concatenate(true_ans), np.concatenate(pred_ans))))
self.val_auc_logloss(val_input, y_val, batch_size=50000)
print(" ")
def predict(self, test_input, batch_size=256, use_double=False):
"""
:param x: The input data, as a Numpy array (or list of Numpy arrays if the model has multiple inputs).
:param batch_size: Integer. If unspecified, it will default to 256.
:return: Numpy array(s) of predictions.
"""
model = self.eval()
x = [test_input[feature] for feature in self.feature_index]
for i in range(len(x)):
if len(x[i].shape) == 1:
x[i] = np.expand_dims(x[i], axis=1) # 扩展成2维,以便后续cat
tensor_data = Data.TensorDataset(torch.from_numpy(np.concatenate(x, axis=-1)))
test_loader = DataLoader(dataset=tensor_data, shuffle=False, batch_size=batch_size)
pred_ans = []
with torch.no_grad():
for index, x_test in enumerate(test_loader):
x = x_test[0].to(self.device).float()
# y = y_test.to(self.device).float()
y_pred = model(x).cpu().data.numpy() # .squeeze()
pred_ans.append(y_pred)
if use_double:
return np.concatenate(pred_ans).astype("float64")
else:
return np.concatenate(pred_ans)
def val_auc_logloss(self, val_input, y_val, batch_size=256, use_double=False):
pred_ans = self.predict(val_input, batch_size)
print("test LogLoss is %.4f test AUC is %.4f"%(log_loss(y_val, pred_ans), roc_auc_score(y_val, pred_ans)) )
def get_L2_Norm(self ):
loss = torch.zeros((1,), device=self.device)
loss = loss + torch.norm(self.weight)
for t in self.embedding_dict1.parameters():
loss = loss+ torch.norm(t)
for t in self.embedding_dict2.parameters():
loss = loss+ torch.norm(t)
return loss
def build_input_features(self, feat_sizes):
# Return OrderedDict: {feature_name:(start, start+dimension)}
features = OrderedDict()
start = 0
for feat in feat_sizes:
feat_name = feat
if feat_name in features:
continue
features[feat_name] = (start, start + 1)
start += 1
return features
def create_embedding_matrix(self ,sparse_feature_columns, feat_sizes, embedding_size,init_std=0.0001, device='cpu'):
embedding_dict = nn.ModuleDict(
{feat: nn.Embedding(feat_sizes[feat], embedding_size, sparse=False)
for feat in sparse_feature_columns}
)
for tensor in embedding_dict.values():
nn.init.normal_(tensor.weight, mean=0, std=init_std)
return embedding_dict.to(device)
使用了一个很小的criteo数据集进行训练和测试,模型很快过拟合了,不过因为只是demo,也没有继续调整。