https://featurize.cn/notebooks/368cbc81-2b27-4036-98a1-d77589b1f0c4
nvidia深度学习加速库apex简单介绍
NVIDIA深度学习加速库Apex是一个用于PyTorch的开源混合精度训练工具包,旨在加速训练并减少内存使用。Apex提供了许多用于混合精度训练的工具,包括半精度浮点数(float16)支持、动态精度缩放、分布式训练等功能。
Apex中最为常用的功能是半精度浮点数支持。半精度浮点数通常用于加速深度学习训练,并且可以显著减少GPU内存的使用。Apex提供了一种简单的方法来实现半精度训练,只需要在模型定义和训练循环中添加几行代码即可。
除了半精度训练之外,Apex还提供了一些其他的功能,包括:
-
动态精度缩放:Apex提供了GradScaler类,可以自动缩放梯度以适应半精度浮点数的范围,并防止下溢或溢出。
-
分布式训练:Apex支持使用PyTorch内置的分布式训练工具进行分布式训练,并提供了一些用于分布式训练的工具和优化器。
-
深度学习优化器:Apex提供了一些用于深度学习优化器的工具和优化器,包括FusedAdam、FusedLAMB等。
-
其他工具:Apex还提供了一些其他有用的工具,例如AMP、SyncBatchNorm等。
总之,Apex是一个用于PyTorch的开源混合精度训练工具包,可以加速训练并减少内存使用。除了半精度训练之外,Apex还提供了一些其他有用的功能,例如动态精度缩放、分布式训练、深度学习优化器等。如果想要加速PyTorch训练并减少内存使用,可以考虑使用Apex。
如何使用Apex
PyTorch支持半精度训练,可以使用半精度浮点数(float16)来加速训练和降低模型的显存占用。下面是使用PyTorch进行半精度训练的步骤:
- 安装Apex库(可选):Apex是NVIDIA开源的混合精度训练库,可以帮助用户方便地使用PyTorch进行半精度训练。可以使用以下命令安装:
pip install apex
-
定义模型:定义PyTorch模型,可以使用nn.Module或者nn.Sequential等模块。
-
将模型转换为半精度模型:使用torch.cuda.amp中的GradScaler和autocast实现半精度训练。首先,需要将模型转换为半精度模型,可以使用以下代码实现:
from torch.cuda.amp import autocast, GradScaler
model = model.half()
-
定义优化器:定义优化器,可以使用torch.optim中的SGD、Adam等优化器。
-
定义GradScaler和amp autocast:定义GradScaler和autocast,可以使用以下代码实现:
scaler = GradScaler()
with autocast():
...
- 编写训练代码:在训练循环中,需要使用autocast()将输入转换为半精度浮点数,使用GradScaler()对梯度进行缩放,然后使用优化器进行更新。可以使用以下代码实现:
for input, target in dataloader:
input = input.to(device).half()
target = target.to(device)
with autocast():
output = model(input)
loss = criterion(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
- 测试模型:在测试模型时,需要将模型转换回浮点数模型,可以使用以下代码实现:
model.float()
总之,使用PyTorch进行半精度训练需要将模型转换为半精度模型,使用GradScaler和autocast对梯度进行缩放和输入输出进行转换,然后使用优化器进行更新。在测试模型时,需要将模型转换回浮点数模型。使用Apex库可以更方便地实现半精度训练。
如何使用GradScaler用于对梯度进行缩放,以适应半精度浮点数的范围,并防止下溢或溢出。autocast用于将输入转换为半精度浮点数,在前向传播和反向传播期间使用。这样可以加速计算并减少内存使用。
使用GradScaler和autocast进行混合精度训练,可以加速计算并减少内存使用。下面是使用GradScaler和autocast进行混合精度训练的步骤:
- 导入GradScaler和autocast:从torch.cuda.amp模块中导入GradScaler和autocast。
from torch.cuda.amp import GradScaler, autocast
- 定义GradScaler:定义GradScaler对象,用于缩放梯度。可以使用以下代码实现:
scaler = GradScaler()
- 在训练循环中使用autocast():在训练循环中使用autocast()将输入和模型转换为半精度浮点数。可以使用以下代码实现:
for inputs, labels in dataloader:
inputs, labels = inputs.to(device), labels.to(device)
with autocast():
outputs = model(inputs)
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
在上述代码中,使用autocast()将输入数据和模型转换为半精度浮点数,在前向传播和反向传播期间使用。然后,使用GradScaler对损失进行缩放,执行反向传播,并使用GradScaler更新优化器。最后,使用GradScaler的update()方法更新缩放因子。
总之,使用GradScaler和autocast进行混合精度训练可以加速计算并减少内存使用。在训练循环中,使用autocast()将输入和模型转换为半精度浮点数,使用GradScaler对损失进行缩放,执行反向传播,使用GradScaler更新优化器,并使用GradScaler的update()方法更新缩放因子。
pytoch最常用得开启混合精度的方法
在PyTorch中,开启混合精度训练可以使用torch.cuda.amp模块中的GradScaler和autocast来实现。GradScaler用于对梯度进行缩放以适应半精度浮点数的范围,并防止下溢或溢出。autocast用于将输入转换为半精度浮点数,以加速计算并减少内存使用。
最常用的开启混合精度的方法如下:
- 导入GradScaler和autocast:
from torch.cuda.amp import GradScaler, autocast
- 创建GradScaler对象:
scaler = GradScaler()
- 在训练循环中使用autocast()将输入和模型转换为半精度浮点数:
for inputs, labels in dataloader:
inputs, labels = inputs.to(device), labels.to(device)
with autocast():
outputs = model(inputs)
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
在上述代码中,使用autocast()将输入和模型转换为半精度浮点数,在前向传播和反向传播期间使用。然后,使用GradScaler对损失进行缩放,执行反向传播,并使用GradScaler更新优化器。最后,使用GradScaler的update()方法更新缩放因子。
- 在测试模型时,需要使用torch.cuda.amp.autocast()将输入转换为半精度浮点数:
with torch.no_grad():
with autocast():
outputs = model(inputs)
在上述代码中,使用torch.no_grad()禁用梯度计算,然后使用autocast()将输入转换为半精度浮点数。
总之,使用GradScaler和autocast可以在PyTorch中开启混合精度训练,从而加速计算并减少内存使用。在训练循环中,使用autocast()将输入和模型转换为半精度浮点数,使用GradScaler对损失进行缩放,执行反向传播,使用GradScaler更新优化器,并使用GradScaler的update()方法更新缩放因子。在测试模型时,需要使用torch.cuda.amp.autocast()将输入转换为半精度浮点数。
https://www.bilibili.com/video/BV1ZY411i7gZ/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f






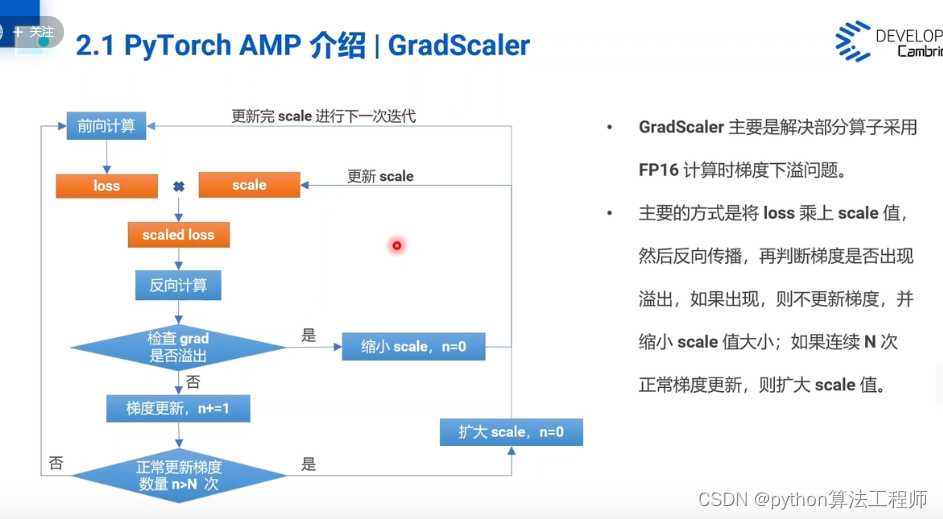






GradScaler接口内部实现过程是什么?
GradScaler是PyTorch中用于缩放梯度以适应半精度浮点数的范围,并防止下溢或溢出的工具。GradScaler的内部实现过程如下:
- 初始化缩放因子和上下文:
在GradScaler对象被创建时,会初始化缩放因子为1,并创建一个上下文(scale_ctx),用于存储当前的缩放因子和梯度缩放状态。
- 调用scale()方法进行梯度缩放:
在进行反向传播计算时,每次调用scale()方法时,GradScaler会将损失乘以当前的缩放因子,从而获得缩放后的损失。然后,GradScaler会将缩放后的梯度存储在上下文中,并返回缩放后的损失。
- 调用step()方法更新模型参数:
在调用优化器的step()方法更新模型参数之前,GradScaler会调用unscale_()方法将缩放后的梯度除以当前的缩放因子,从而得到真实的梯度。然后,GradScaler会调用优化器的step()方法更新模型参数。
- 调用update()方法更新缩放因子:
在每个训练迭代结束时,GradScaler会调用update()方法更新缩放因子。GradScaler会根据梯度的大小动态调整缩放因子,并将新的缩放因子存储在上下文中,以便下一次使用。
总之,GradScaler通过动态调整缩放因子来缩放梯度,以适应半精度浮点数的范围,并防止下溢或溢出。在进行反向传播计算时,GradScaler会将损失乘以当前的缩放因子,从而获得缩放后的损失。在更新模型参数之前,GradScaler会将缩放后的梯度除以当前的缩放因子,从而得到真实的梯度。在每个训练迭代结束时,GradScaler会根据梯度的大小动态调整缩放因子,并将新的缩放因子存储在上下文中,以便下一次使用。
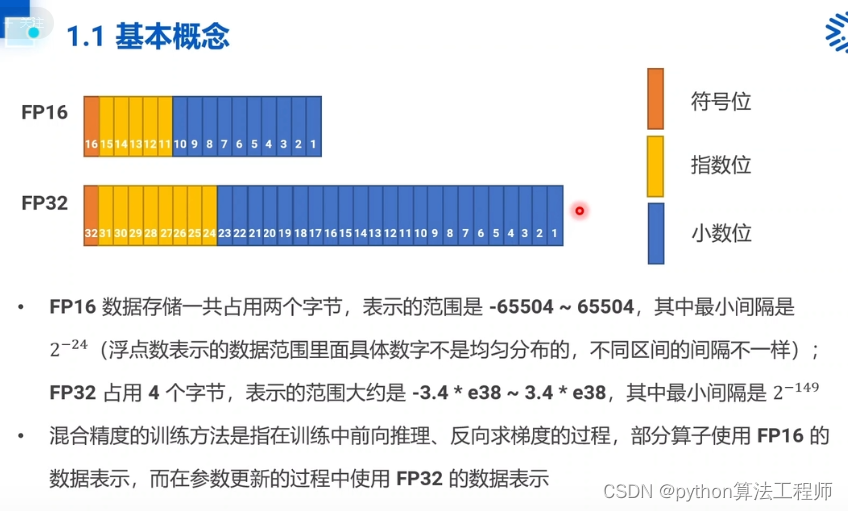
分别说明Loss缩放,中间结果FP32表示的具体含义
在混合精度训练中,使用半精度浮点数(float16)可以加速计算并减少内存使用,但是可能会出现梯度下溢或溢出的问题。为了解决这个问题,可以使用Loss缩放和中间结果FP32表示。
- Loss缩放:
当使用半精度浮点数进行训练时,梯度下溢或溢出的问题可能会导致训练失败。为了解决这个问题,可以使用Loss缩放。具体来说,就是将损失乘以一个缩放因子,然后在反向传播期间将梯度除以该缩放因子。这样可以防止梯度下溢或溢出,并保持梯度的大小适当。
- 中间结果FP32表示:
在混合精度训练中,使用半精度浮点数可以加速计算并减少内存使用,但是可能会导致精度损失。为了解决这个问题,可以使用中间结果FP32表示。具体来说,中间结果(例如,卷积层的输出)可以在计算过程中使用半精度浮点数,但是在计算损失之前,需要将这些中间结果转换为单精度浮点数(float32)。这样可以保持较高的精度,并避免精度损失。
总之,Loss缩放和中间结果FP32表示是用于解决混合精度训练中梯度下溢或溢出以及精度损失问题的两种技术。Loss缩放将损失乘以一个缩放因子,然后在反向传播期间将梯度除以该缩放因子,防止梯度下溢或溢出。中间结果FP32表示可以在计算过程中使用半精度浮点数,并在计算损失之前将这些中间结果转换为单精度浮点数,以保持较高的精度。这样可以加速计算并减少内存使用,同时保持较高的精度。
那些显卡支持混合精度?
目前,大多数NVIDIA的显卡都支持混合精度训练。具体而言,从Pascal架构开始,NVIDIA的显卡就开始支持混合精度训练。以下是一些常见的显卡型号和其支持的混合精度训练的情况:
-
NVIDIA Tesla V100:支持混合精度训练。
-
NVIDIA Tesla P100:支持混合精度训练。
-
NVIDIA Tesla T4:支持混合精度训练。
-
NVIDIA GeForce RTX 30系列(如RTX 3090、RTX 3080等):支持混合精度训练。
-
NVIDIA GeForce RTX 20系列(如RTX 2080 Ti、RTX 2080等):支持混合精度训练。
-
NVIDIA GeForce GTX 10系列(如GTX 1080 Ti、GTX 1080等):支持混合精度训练,但需要使用一些特殊的技巧和工具(如NVIDIA Apex)。
需要注意的是,混合精度训练需要使用支持FP16(即半精度浮点数)计算的硬件,因此并不是所有的显卡都能够支持混合精度训练。此外,不同的显卡在支持混合精度训练的方式和性能上也会有所不同。因此,在选择显卡时,需要根据自己的需求和预算来选择最合适的显卡。
总之,大多数NVIDIA的显卡都支持混合精度训练,但不同的显卡在支持混合精度训练的方式和性能上也会有所不同。在选择显卡时,需要根据自己的需求和预算来选择最合适的显卡。