大家好,我是csdn的博主:lqj_本人
这是我的个人博客主页:
lqj_本人的博客_CSDN博客-微信小程序,前端,python领域博主lqj_本人擅长微信小程序,前端,python,等方面的知识
https://blog.csdn.net/lbcyllqj?spm=1011.2415.3001.5343哔哩哔哩欢迎关注:小淼Develop
小淼Develop的个人空间-小淼Develop个人主页-哔哩哔哩视频
本篇文章主要讲述python的计算机视觉【YOLOV5目标检测模型】,本篇文章已经成功收录YOLOV5系列从入门到实战专栏中:
https://blog.csdn.net/lbcyllqj/category_12307626.html?spm=1001.2014.3001.5482
https://blog.csdn.net/lbcyllqj/category_12307626.html?spm=1001.2014.3001.5482
什么是YOLO
YOLO是目标检测模型。
目标检测是计算机视觉中比较简单的任务,用来在一张图篇中找到某些特定的物体,目标检测不仅要求我们识别这些物体的种类,同时要求我们标出这些物体的位置
显然,类别是离散数据,位置是连续数据。

上面的图片中,分别是计算机视觉的三类任务:分类,目标检测,实例分割。
很显然,整体上这三类任务从易到难,我们要讨论的目标检测位于中间。前面的分类任务是我们做目标检测的基础,至于像素级别的实例分割,太难了别想了。
YOLO在2016年被提出,发表在计算机视觉顶会CVPR(Computer Vision and Pattern Recognition)上。
YOLO的全称是you only look once,指只需要浏览一次就可以识别出图中的物体的类别和位置。
因为只需要看一次,YOLO被称为Region-free方法,相比于Region-based方法,YOLO不需要提前找到可能存在目标的Region。
也就是说,一个典型的Region-base方法的流程是这样的:先通过计算机图形学(或者深度学习)的方法,对图片进行分析,找出若干个可能存在物体的区域,将这些区域裁剪下来,放入一个图片分类器中,由分类器分类。
因为YOLO这样的Region-free方法只需要一次扫描,也被称为单阶段(1-stage)模型。Region-based方法方法也被称为两阶段(2-stage)方法。
YOLO之前的世界
YOLO之前的世界,额,其实是R-CNN什么的,也就是我们前面说的Region-based方法,但是感觉还是太高端了。我们从用脚都能想到的目标检测方法开始讲起。
如果我们现在有一个分类器:
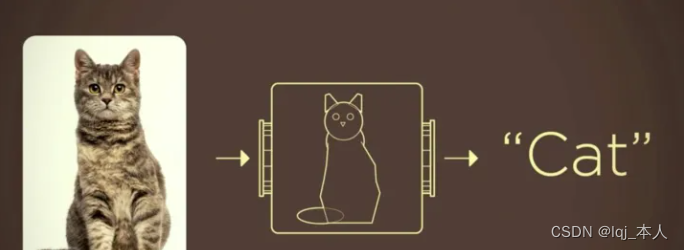
但是,我们不仅仅想处理这种一张图片中只有一个物体的图片,我们现在想处理有多个物体的图片。
那么该这样做:
首先有几点我们要实现想到:首先物体的位置是不确定的,你没办法保证物体一定在最中间;其次,物体的大小是不确定的,有的物体比较大,也有的物体比较小,注意,这里不是说大象一定更大,猫咪一定更小,毕竟还有近大远小嘛;然后,我们还没办法保证物体的种类,假设我们有一个可以识别100中物体的分类器,那么起码图片中出现了这100种物体我们都要识别出来。
比如说这样:

YOLO原理
目标检测是基于监督学习的,每张图片的监督信息是它所包含的N个物体,每个物体的信息有五个,分别是物体的中心位置(x,y)和它的高(h)和宽(w),最后是它的类别。
YOLO 的预测是基于整个图片的,并且它会一次性输出所有检测到的目标信息,包括类别和位置。
YOLO的第一步是分割图片,它将图片分割为 S² 个grid,每个grid的大小都是相等的:

YOLO的聪明之处在于,它只要求这个物体的中心落在这个框框之中。
这意味着,我们不用设计非常非常大的框,因为我们只需要让物体的中心在这个框中就可以了,而不是必须要让整个物体都在这个框中。
我们要让这个 S² 个框每个都预测出B个bounding box,这个bounding box有5个量,分别是物体的中心位置(x,y)和它的高(h)和宽(w),以及这次预测的置信度。
每个框框不仅只预测B个bounding box,它还要负责预测这个框框中的物体是什么类别的,这里的类别用one-hot编码表示。
注意,虽然一个框框有多个bounding boxes,但是只能识别出一个物体,因此每个框框需要预测物体的类别,而bounding box不需要。
也就是说,如果我们有 S² 个框框,每个框框的bounding boxes个数为B,分类器可以识别出C种不同的物体,那么所有整个ground truth的长度为:

bounding box显示:

图片被分成了49个框,每个框预测2个bounding box,因此上面的图中有98个bounding box。
可以看到这些BOX中有的边框比较粗,有的比较细,这是置信度不同的表现,置信度高的比较粗,置信度低的比较细。
在详细的介绍confidence之前,我们先来说一说关于bounding box的细节。
bounding box可以锁定物体的位置,这要求它输出四个关于位置的值,分别是x,y,h和w。我们在处理输入的图片的时候想让图片的大小任意,这一点对于卷积神经网络来说不算太难,但是,如果输出的位置坐标是一个任意的正实数,模型很可能在大小不同的物体上泛化能力有很大的差异。
这时候当然有一个常见的套路,就是对数据进行归一化,让连续数据的值位于0和1之间。
对于x和y而言,这相对比较容易,毕竟x和y是物体的中心位置,既然物体的中心位置在这个grid之中,那么只要让真实的x除以grid的宽度,让真实的y除以grid的高度就可以了。
但是h和w就不能这么做了,因为一个物体很可能远大于grid的大小,预测物体的高和宽很可能大于bounding box的高和宽,这样w除以bounding box的宽度,h除以bounding box的高度依旧不在0和1之间。
解决方法是让w除以整张图片的宽度,h除以整张图片的高度。
下面的例子是一个448*448的图片,有3*3的grid,展示了计算x,y,w,h的真实值(ground truth)的过程:
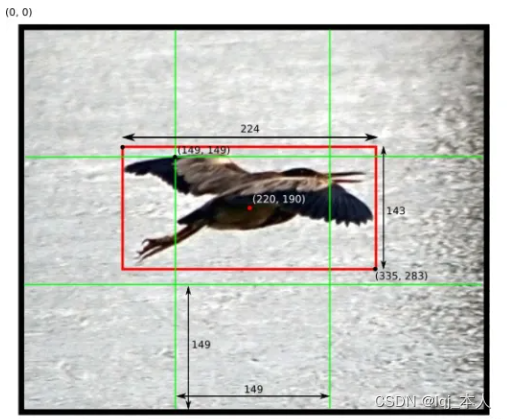

confidence的计算公式是:

这个IOU的全称是intersection over union,也就是交并比,它反应了两个框框的相似度。

存在一个不得不考虑的问题,如果物体很大,而框框又很小,一个物体被多个框框识别了怎么办?
这时用到一个叫做非极大值抑制Non-maximal suppression(NMS)的技术。
这个NMS还是基于交并比实现的。

B1,B2,B3,B4这四个框框可能都说狗狗在我的框里,但是最后的输出应该只有一个框,那怎么把其他框删除呢?
这里就用到了我们之前讲的confidence了,confidence预测有多大的把握这个物体在我的框里,我们在同样是检测狗狗的框里,也就是B1,B2,B3,B4中,选择confidence最大的,把其余的都删掉。
也就是只保留B1。
YOLOV5
YOLOV5目前的四个版本与版本对应的不同的性能如下图:
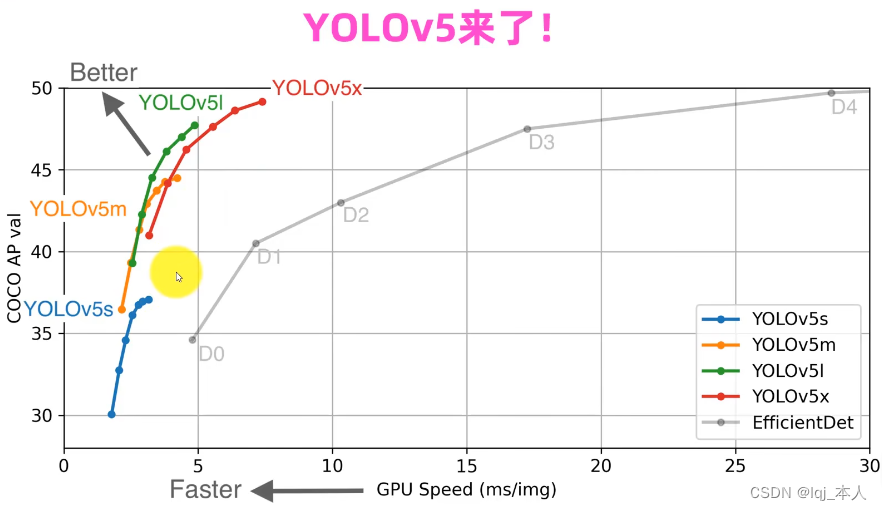
YOLOV4出现之后不久,YOLOv5横空出世。YOLOv5在YOLOv4算法的基础上做了进一步的改进,检测性能得到进一步的提升。虽然YOLOv5算法并没有与YOLOv4算法进行性能比较与分析,但是YOLOv5在COCO数据集上面的测试效果还是挺不错的。大家对YOLOv5算法的创新性半信半疑,有的人对其持肯定态度,有的人对其持否定态度。在我看来,YOLOv5检测算法中还是存在很多可以学习的地方,虽然这些改进思路看来比较简单或者创新点不足,但是它们确定可以提升检测算法的性能。其实工业界往往更喜欢使用这些方法,而不是利用一个超级复杂的算法来获得较高的检测精度。
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。

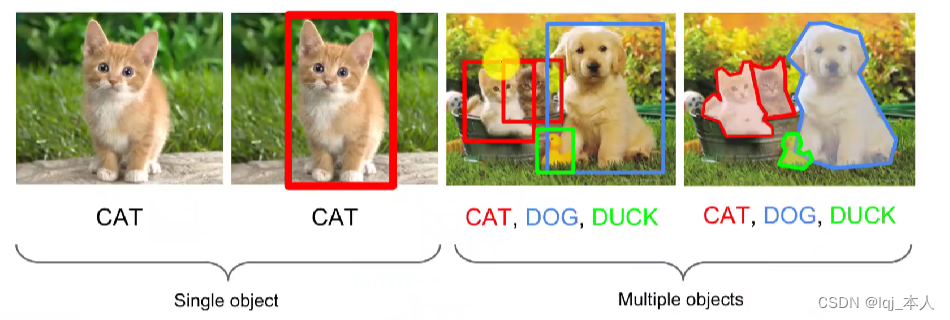
目标检测(Object Detection)=What,and where
定位Lcalization
位置(最小外界矩形,Bounding box)
识别Recognition what?
类别标签(Category label)
置信度得分(Confidence score)
定位和检测:
定位是找到检测图像中带有一个给定标签的单个目标。
检测时找到图像中带有给定标签的所有目标。
目标检测数据集
1.PASCAL VOC
2.MS COCO
PASCAL VOC:
PASCAL VOC挑战赛再2005年到2012年间展开。
PASCAL VOC 2007:9963张图片,24640个标注;PASCAL VOC2012:11530张图片,27450个标注,该数据集有20个分类:
Person:person
Animal:bird,cat,cow,dog,horse,sheep
Vehicle:aerop,bicy,boat,bus,car,motorbike,train
Indoor:botle,chair,dining table,potted plant,sofa,tv/monitor

链接:The PASCAL Visual Object Classes Challenge 2012 (VOC2012)
MS COCO
MS COCO的全称时Microsoft Common Objects in Context,起源于是微软于2014出资标注的Microsoft COCO数据集,与ImageNet竞赛一样,被视为是计算机视觉领域最受欢迎和最权威的比赛之一。
在ImageNet竞赛停办后,COCO竞赛就成为是当前目标识别、检测等领域的一个最权威、最重要的标杆,也是目前该领域在国际上唯一能汇集Google、微软、Facebook以及国内外众多顶尖院校的优秀创新企业共同参与的大赛。
COCO - Common Objects in Context
COCO数据集包含20万个图象:11.5万多张训练集图片,5千张验证集图像,2万多张检测集图像
80个类别中有超出50万个目标标注
平均每个图像的目标数为7.2