HBASE整理
一、HBASE由来
思考: HDFS主要适用于什么场景呢? 具有高的吞吐量 适合于批量数据的处理操作
思考: 如果想在HDFS上, 直接读取HDFS上某一个文件中某一行数据, 请问是否可以办到呢?
或者说, 我们想直接修改HDFS上某一个文件中某一行数据,请问是否可以办到呢?
HDFS并不支持对文件中数据进行随机的读写操作, 仅支持追加的方式来写入数据
假设, 现在有一个场景: 数据量比较大, 需要对数据进行存储, 而且后续需要对数据进行随机读写的操作, 请问如何做呢?
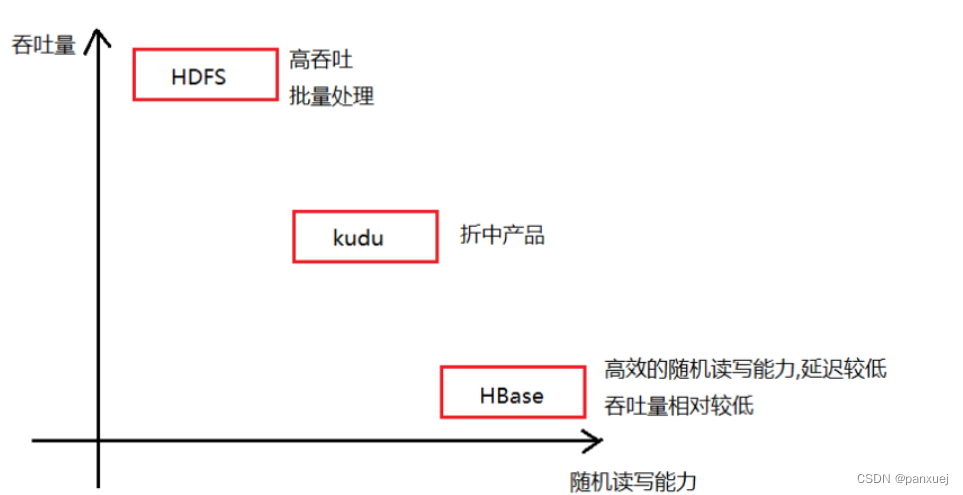
此时HDFS并不合适了, 此时需要有一款软件能够帮助存储海量的数据, 并且支持高效的随机读写的特性, 此时HBase就是在这样的背景下产生了
HBase是采用java语言编写的一款 apache 开源的基于HDFS的nosql型数据库,不支持 SQL, 不支持事务, 不支持Join操作,没有表关系
既然是基于HDFS的, 那么也就意味HBase的数据最终是存在HDFS上, 在启动HBase集群之前, 必须要先启动HDFS
HBase仅支持三种数据读取方案:
1- 基于 rowkey(行键|主键)读取
2- 基于 rowkey的range范围读取
3- 扫描全表数据
不支持事务, 仅支持单行事务
主要存储结构化数据以及半结构化的数据
HBase中数据存储都是以字节的形式来存储的
hbase易于扩展的
HBase的表具有三大特征:
1- 大: 在一个表中可以存储上十亿行的数据, 可以拥有上百万个列
2- 面向列: 是基于列族进行管理操作, 基于列族进行列式存储方案
3- 稀疏性: 在HBase中, 对于NULL值的数据, 不占用任何的磁盘空间的, 对效率也没有任何的影响, 所以表可以设计的非常稀疏
HBase的应用场景:
1- 数据量比较庞大的
2- 数据需要具备随机读写特性
3- 数据具有稀疏性特性
当以后工作中, 如果发现数据具备了以上二个及以上的特性的时候, 就可以尝试使用HBase来解决了
二、hbase和其他软件的区别
2.1 hbase和RDBMS的区别
HBase: 具有表, 存在rowkey, 分布式存储, 不支持SQL,不支持Join, 没有表关系, 不支持事务(仅支持单行事务)
MySQL(RDBMS): 具有表, 存在主键, 单机存储,支持SQL,支持Join, 存在表关系, 支持事务
2.2 hbase 和 HDFS的区别
HBase: 基于hadoop, 和 HDFS是一种强依赖关系, HBase的吞吐量不是特别高, 支持高效的随机读写特性
HDFS: 具有高的吞吐量, 适合于批量数据处理, 主要应用离线OLAP, 不支持随机读写
HBase是基于HDFS, 但是HDFS并不支持随机读写特性, 但是HBase却支持高效的随机读写特性, 两者貌似出现了一定的矛盾关系, 也就意味着HBase中必然做了一些特殊的处理工作
2.3 hbase和hive的区别
HBase: 基于HADOOP 是一个存储数据的nosql型数据库, 延迟性比较低, 适合于接入在线业务(实时业务)
HIVE: 基于HADOOP 是一个数据仓库的工具, 延迟性较高, 适用于离线的数据处理分析操作
HBase和hive都是基于hadoop的不同的软件, 两者之间可以共同使用, 可以使用hive集成HBase, 这样hive就可以读取hbase中数据, 从而实现统计分析操作
三、HBASE安装
3.1解压
[pxj@pxj62 /opt/app]$tar -zxvf hbase-2.1.0.tar.gz -C ../app/
3.2设置软连接
[pxj@pxj62 /opt/app]$ln -s hbase-2.1.0 hbase
3.3修改HBase配置文件
3.31hbase-env.sh
<configuration>
<!-- HBase数据在HDFS中的存放的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://pxj62:8020/hbase</value>
</property>
<!-- Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- ZooKeeper的地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>pxj62,pxj63,pxj64</value>
</property>
<!-- ZooKeeper快照的存储位置 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/app/zookeeper/zkdatas</value>
</property>
<!-- V2.1版本,在分布式情况下, 设置为false -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
3.32hbase-env.sh
# 第28行
export JAVA_HOME=/export/server/jdk1.8.0_241/
# 第 125行
export HBASE_MANAGES_ZK=false
3.33 配置环境变量
[pxj@pxj62 /home/pxj]$vim .bashrc
export HBASE_HOME=/opt/app/hbase
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZOOKEEPER_HOME}/bin:${KAFKA_HOME}/bin:${KE_HOME}/bin:${HBASE_HOME}/bin:$PATH
[pxj@pxj62 /home/pxj]$source .bashrc
3.34复制jar包
[pxj@pxj62 /opt/app/hbase/lib/client-facing-thirdparty]$cp htrace-core-3.1.0-incubating.jar /opt/app/hbase/lib/
3.35 修改regionservers文件
[pxj@pxj62 /opt/app/hbase/conf]$vim regionservers
pxj62
pxj63
pxj64
3.36分发文件
[pxj@pxj62 /opt/app]$xsync hbase-2.1.0/
3.37启动HBASE
启动Hadoop
start-all.sh
启动zk
[pxj@pxj62 /home/pxj]$start-hbase.sh
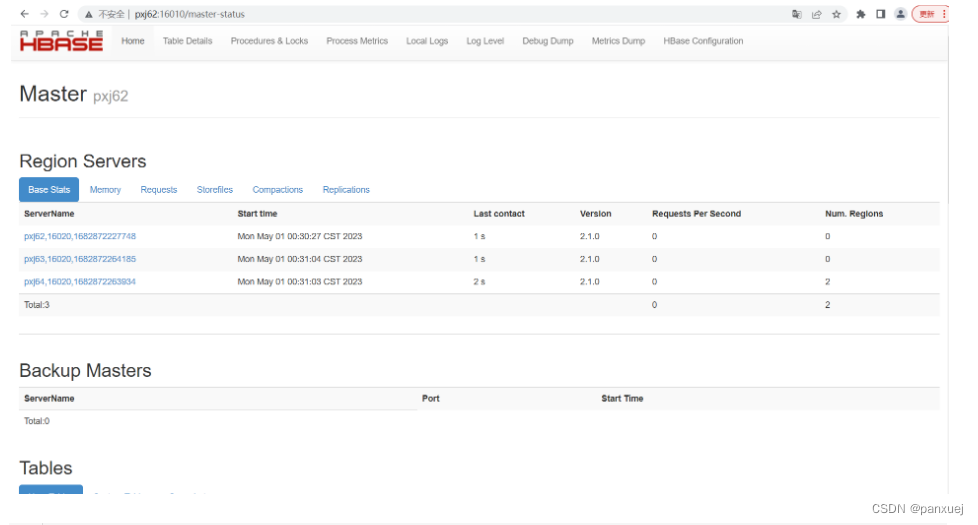
3.38验证是否成功
http://pxj62:16010/master-status
[pxj@pxj62 /home/pxj]$hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/app/hadoop-3.1.4/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/app/hbase-2.1.0/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
Version 2.1.0, re1673bb0bbfea21d6e5dba73e013b09b8b49b89b, Tue Jul 10 17:26:48 CST 2018
Took 0.0029 seconds
hbase(main):001:0> status
1 active master, 0 backup masters, 3 servers, 0 dead, 0.6667 average load
Took 1.7279 seconds
hbase(main):002:0>
四、HBASE模型
4.1rowkey : 行键
rowkey : 行键 , 理解为mysql中主键 , 只不过叫法不同而已
1) 在hbase中, rowkey的长度最长为64KB,但是在实际使用中, 一般长度在 0~100个字节, 常常的范围集中在 10~30区间
2) 在hbase中, 表中数据都是按照rowkey来进行排序, 不关心插入的顺序. 排序规则为 字典序的升序排列
请将以下内容, 按照字典序的升序排序:
1 2 10 245 3 58 11 41 269 3478 154
排序结果为:
1 10 11 154 2 245 269 3 3478 41 58
字典序规则:
先看第一位, 如果一致看第二位, 以此类推, 没有第二位的要比有第二位要小,其他位置也是一样的
3) 查询数据的方式, 主要有三种:
基于rowkey的查询
基于rowkey范围查询
扫描全表数据
4) rowkey也是具备唯一性和非空性
4.2.column family: 列族(列簇)
1) 在一个表中, 是可以有多个列族的, 但是一般建议列族越少越好, 能用一个解决, 坚决不使用多个
2) 在hbase中, 都是基于列族的管理和存储的 (是一个列式的存储方案)
3) 一个列族下, 可以有多个列名 . 可以达到上百万个
4) 在创建表的时候, 必须制定表名 和 列族名
4.3.column qualifier: 列名(列限定符号)
1) 一个列名必然是属于某一个列族的, 在一个列族下是可以有多个列名的
2) 列名不需要在创建表的时候指定, 在插入数据的时候, 动态指定即可
4.4.timeStamp : 时间戳
每一个单元格背后都是具有时间戳的概念的, 默认情况下, 时间戳为插入数据的时间, 当然也可以自定义
4.5.versions: 版本号
1) 在hbase中, 对于每一个单元格, 都是可以记录其历史变更行为的, 通过设置version版本数量, 表示需要记录多少个历史版本, 默认值为 1
2) 当设置版本数量为多个的时候, 默认展示的离当前时间最近的版本的数据
4.6.cell : 单元格
如何确定一个唯一的单元格呢? rowkey + 列族 + 列名 + 值
五、hbase的相关操作_shell命令
5.1hbase的基本shell操作
在三个节点任意一个节点的任意一个目录下, 执行:
hbase shell
[pxj@pxj62 /opt/app/zookeeper]$hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/app/hadoop-3.1.4/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/app/hbase-2.1.0/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
Version 2.1.0, re1673bb0bbfea21d6e5dba73e013b09b8b49b89b, Tue Jul 10 17:26:48 CST 2018
Took 0.0029 seconds
5.2.查看整个集群的状态信息
hbase(main):001:0> status
1 active master, 0 backup masters, 3 servers, 0 dead, 0.6667 average load
Took 0.5121 seconds
5.3.如何查看帮助文档信息
hbase(main):002:0> help
HBase Shell, version 2.1.0, re1673bb0bbfea21d6e5dba73e013b09b8b49b89b, Tue Jul 10 17:26:48 CST 2018
Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command.
Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group.
COMMAND GROUPS:
Group name: general
Commands: processlist, status, table_help, version, whoami
Group name: ddl
Commands: alter, alter_async, alter_status, clone_table_schema, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, list_regions, locate_region, show_filters
Group name: namespace
Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables
Group name: dml
Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve
Group name: tools
Commands: assign, balance_switch, balancer, balancer_enabled, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch, cleaner_chore_enabled, cleaner_chore_run, cleaner_chore_switch, clear_block_cache, clear_compaction_queues, clear_deadservers, close_region, compact, compact_rs, compaction_state, flush, is_in_maintenance_mode, list_deadservers, major_compact, merge_region, move, normalize, normalizer_enabled, normalizer_switch, split, splitormerge_enabled, splitormerge_switch, stop_master, stop_regionserver, trace, unassign, wal_roll, zk_dump
Group name: replication
Commands: add_peer, append_peer_namespaces, append_peer_tableCFs, disable_peer, disable_table_replication, enable_peer, enable_table_replication, get_peer_config, list_peer_configs, list_peers, list_replicated_tables, remove_peer, remove_peer_namespaces, remove_peer_tableCFs, set_peer_bandwidth, set_peer_exclude_namespaces, set_peer_exclude_tableCFs, set_peer_namespaces, set_peer_replicate_all, set_peer_serial, set_peer_tableCFs, show_peer_tableCFs, update_peer_config
Group name: snapshots
Commands: clone_snapshot, delete_all_snapshot, delete_snapshot, delete_table_snapshots, list_snapshots, list_table_snapshots, restore_snapshot, snapshot
Group name: configuration
Commands: update_all_config, update_config
Group name: quotas
Commands: list_quota_snapshots, list_quota_table_sizes, list_quotas, list_snapshot_sizes, set_quota
Group name: security
Commands: grant, list_security_capabilities, revoke, user_permission
Group name: procedures
Commands: abort_procedure, list_locks, list_procedures
Group name: visibility labels
Commands: add_labels, clear_auths, get_auths, list_labels, set_auths, set_visibility
Group name: rsgroup
Commands: add_rsgroup, balance_rsgroup, get_rsgroup, get_server_rsgroup, get_table_rsgroup, list_rsgroups, move_namespaces_rsgroup, move_servers_namespaces_rsgroup, move_servers_rsgroup, move_servers_tables_rsgroup, move_tables_rsgroup, remove_rsgroup, remove_servers_rsgroup
SHELL USAGE:
Quote all names in HBase Shell such as table and column names. Commas delimit
command parameters. Type <RETURN> after entering a command to run it.
Dictionaries of configuration used in the creation and alteration of tables are
Ruby Hashes. They look like this:
{'key1' => 'value1', 'key2' => 'value2', ...}
and are opened and closed with curley-braces. Key/values are delimited by the
'=>' character combination. Usually keys are predefined constants such as
NAME, VERSIONS, COMPRESSION, etc. Constants do not need to be quoted. Type
'Object.constants' to see a (messy) list of all constants in the environment.
If you are using binary keys or values and need to enter them in the shell, use
double-quote'd hexadecimal representation. For example:
hbase> get 't1', "key\x03\x3f\xcd"
hbase> get 't1', "key\003\023\011"
hbase> put 't1', "test\xef\xff", 'f1:', "\x01\x33\x40"
The HBase shell is the (J)Ruby IRB with the above HBase-specific commands added.
For more on the HBase Shell, see http://hbase.apache.org/book.html
hbase(main):003:0> help 'scan'
Scan a table; pass table name and optionally a dictionary of scanner
specifications. Scanner specifications may include one or more of:
TIMERANGE, FILTER, LIMIT, STARTROW, STOPROW, ROWPREFIXFILTER, TIMESTAMP,
MAXLENGTH or COLUMNS, CACHE or RAW, VERSIONS, ALL_METRICS or METRICS
If no columns are specified, all columns will be scanned.
To scan all members of a column family, leave the qualifier empty as in
'col_family'.
The filter can be specified in two ways:
1. Using a filterString - more information on this is available in the
Filter Language document attached to the HBASE-4176 JIRA
2. Using the entire package name of the filter.
If you wish to see metrics regarding the execution of the scan, the
ALL_METRICS boolean should be set to true. Alternatively, if you would
prefer to see only a subset of the metrics, the METRICS array can be
defined to include the names of only the metrics you care about.
Some examples:
hbase> scan 'hbase:meta'
hbase> scan 'hbase:meta', {COLUMNS => 'info:regioninfo'}
hbase> scan 'ns1:t1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'}
hbase> scan 't1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'}
hbase> scan 't1', {COLUMNS => 'c1', TIMERANGE => [1303668804000, 1303668904000]}
hbase> scan 't1', {REVERSED => true}
hbase> scan 't1', {ALL_METRICS => true}
hbase> scan 't1', {METRICS => ['RPC_RETRIES', 'ROWS_FILTERED']}
hbase> scan 't1', {ROWPREFIXFILTER => 'row2', FILTER => "
(QualifierFilter (>=, 'binary:xyz')) AND (TimestampsFilter ( 123, 456))"}
hbase> scan 't1', {FILTER =>
org.apache.hadoop.hbase.filter.ColumnPaginationFilter.new(1, 0)}
hbase> scan 't1', {CONSISTENCY => 'TIMELINE'}
For setting the Operation Attributes
hbase> scan 't1', { COLUMNS => ['c1', 'c2'], ATTRIBUTES => {'mykey' => 'myvalue'}}
hbase> scan 't1', { COLUMNS => ['c1', 'c2'], AUTHORIZATIONS => ['PRIVATE','SECRET']}
For experts, there is an additional option -- CACHE_BLOCKS -- which
switches block caching for the scanner on (true) or off (false). By
default it is enabled. Examples:
hbase> scan 't1', {COLUMNS => ['c1', 'c2'], CACHE_BLOCKS => false}
Also for experts, there is an advanced option -- RAW -- which instructs the
scanner to return all cells (including delete markers and uncollected deleted
cells). This option cannot be combined with requesting specific COLUMNS.
Disabled by default. Example:
hbase> scan 't1', {RAW => true, VERSIONS => 10}
Besides the default 'toStringBinary' format, 'scan' supports custom formatting
by column. A user can define a FORMATTER by adding it to the column name in
the scan specification. The FORMATTER can be stipulated:
1. either as a org.apache.hadoop.hbase.util.Bytes method name (e.g, toInt, toString)
2. or as a custom class followed by method name: e.g. 'c(MyFormatterClass).format'.
Example formatting cf:qualifier1 and cf:qualifier2 both as Integers:
hbase> scan 't1', {COLUMNS => ['cf:qualifier1:toInt',
'cf:qualifier2:c(org.apache.hadoop.hbase.util.Bytes).toInt'] }
Note that you can specify a FORMATTER by column only (cf:qualifier). You can set a
formatter for all columns (including, all key parts) using the "FORMATTER"
and "FORMATTER_CLASS" options. The default "FORMATTER_CLASS" is
"org.apache.hadoop.hbase.util.Bytes".
hbase> scan 't1', {FORMATTER => 'toString'}
hbase> scan 't1', {FORMATTER_CLASS => 'org.apache.hadoop.hbase.util.Bytes', FORMATTER => 'toString'}
Scan can also be used directly from a table, by first getting a reference to a
table, like such:
hbase> t = get_table 't'
hbase> t.scan
Note in the above situation, you can still provide all the filtering, columns,
options, etc as described above.
4.5.如何查看当前hbase中有那些表呢?
hbase(main):005:0> list
TABLE
0 row(s)
Took 0.0522 seconds
=> []
4.6.如何创建一张表
格式:
create '表名','列族1','列族2' ....
或者
create '表名',{NAME=>'列族1'},{NAME=>'列族2'} ....
hbase(main):006:0> create 'test01','f1','f2'
Created table test01
Took 0.8959 seconds
=> Hbase::Table - test01
hbase(main):007:0> list
TABLE
test01
1 row(s)
Took 0.0266 seconds
=> ["test01"]
hbase(main):008:0> create 'test02',{NAME=>'f1'},{NAME=>'f2'}
Created table test02
Took 0.7848 seconds
=> Hbase::Table - test02
4.7.如何向表中插入数据
hbase(main):009:0> put 'test01','rk0001','f1:name','zhangsan'
Took 0.2737 seconds
hbase(main):010:0> put 'test01','rk0001','f1:age','20'
Took 0.0141 seconds
hbase(main):011:0> put 'test01','rk0001','f1:birthday','2020-10-10'
Took 0.0077 seconds
hbase(main):012:0> put 'test01','rk0001','f2:sex','nan'
Took 0.0136 seconds
hbase(main):013:0> put 'test01','rk0001','f2:address','beijing'
Took 0.0127 seconds
hbase(main):014:0> scan 'test01'
ROW COLUMN+CELL
rk0001 column=f1:age, timestamp=1682920000246, value=20
rk0001 column=f1:birthday, timestamp=1682920029538, value=2020-10-10
rk0001 column=f1:name, timestamp=1682919262141, value=zhangsan
rk0001 column=f2:address, timestamp=1682920573062, value=beijing
rk0001 column=f2:sex, timestamp=1682920550965, value=nan
1 row(s)
Took 0.0353 seconds
4.8.如何修改数据呢?
修改数据的操作 与 添加数据的操作是一致的, 只需要保证rowkey一样 就是修改数据
hbase(main):015:0> put 'test01','rk0001','f2:address','guangzhou'
Took 0.0094 seconds
hbase(main):016:0> scan 'test01'
ROW COLUMN+CELL
rk0001 column=f1:age, timestamp=1682920000246, value=20
rk0001 column=f1:birthday, timestamp=1682920029538, value=2020-10-10
rk0001 column=f1:name, timestamp=1682919262141, value=zhangsan
rk0001 column=f2:address, timestamp=1682921131272, value=guangzhou
rk0001 column=f2:sex, timestamp=1682920550965, value=nan
1 row(s)
Took 0.0161 seconds
hbase(main):017:0>
4.9如何删除数据的操作:
格式:
delete '表名','rowkey名称','列族:列名'
deleteall '表名','rowkey名称','列族:列名'
truncate '表名' 清空表
说明:
1) delete操作, 仅支持删除某一个列下的数据, 仅会删除当前这个版本, 恢复上一个版本
2) deleteall操作, 在删除某一个列数据的时候, 直接将其所有的历史版本全部都删除
3) deleteall操作, 在不指定列族和列名, 仅指定rowkey的时候, 删除整行
说明:
deleteall操作在hbase2.x以上的版本提供的
注意:
truncate操作 一般不使用, 因为此操作在重新建表的时候, 会与原来的表不一致. 比如一些设置参数信息,执行truncate全部都还原了
4.10如何删除表
格式:
describe '表名'
desc 'tablename'
格式:
drop '表名'
注意: 在删除hbase表之前, 必须要先禁用表
禁用表: disable '表名'
启动表: enable '表名'
判断表是否启用: is_enabled '表名'
判断表是否禁用: is_disabled '表名'
4.11如何查看表的结构
hbase(main):017:0> desc 'test01'
Table test01 is ENABLED
test01
COLUMN FAMILIES DESCRIPTION
{NAME => 'f1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOC
K_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_B
LOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'f2', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOC
K_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_B
LOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
2 row(s)
Took 0.0938 seconds
hbase(main):018:0> describe 'test01'
Table test01 is ENABLED
test01
COLUMN FAMILIES DESCRIPTION
{NAME => 'f1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOC
K_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_B
LOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'f2', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOC
K_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_B
LOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
2 row(s)
Took 0.0346 seconds
4.12如何查看表中有多少条数据:
count '表名'
hbase(main):019:0> count 'test01'
1 row(s)
Took 0.0936 seconds
=> 1
4.13如何通过扫描的方式查询数据, 以及根据范围查询数据
准备工作: 插入一部分数据
put 'test01','rk0001','f1:name','zhangsan'
put 'test01','rk0001','f1:age','20'
put 'test01','rk0001','f1:birthday','2020-10-10'
put 'test01','rk0001','f2:sex','nan'
put 'test01','rk0001','f2:address','beijing'
put 'test01','rk0002','f1:name','lisi'
put 'test01','rk0002','f1:age','25'
put 'test01','rk0002','f1:birthday','2005-10-10'
put 'test01','rk0002','f2:sex','nv'
put 'test01','rk0002','f2:address','shanghai'
put 'test01','rk0003','f1:name','王五'
put 'test01','rk0003','f1:age','28'
put 'test01','rk0003','f1:birthday','1993-10-25'
put 'test01','rk0003','f2:sex','nan'
put 'test01','rk0003','f2:address','tianjin'
put 'test01','0001','f1:name','zhaoliu'
put 'test01','0001','f1:age','25'
put 'test01','0001','f1:birthday','1995-05-05'
put 'test01','0001','f2:sex','nan'
put 'test01','0001','f2:address','guangzhou'
格式:
scan '表名' , {COLUMNS=>['列族' | '列族:列名' ....], STARTROW=>'起始rowkey值' ,ENDROW=>'结束rowkey值', FORMATTER=>'toString',LIMIT=>N}
注意
此处 [] 是格式要求, 必须存在了
范围检索是包头不包尾
hbase(main):020:0> put 'test01','rk0001','f1:name','zhangsan'
Took 0.0116 seconds
hbase(main):021:0> put 'test01','rk0001','f1:age','20'
Took 0.0070 seconds
hbase(main):022:0> put 'test01','rk0001','f1:birthday','2020-10-10'
Took 0.0111 seconds
hbase(main):023:0> put 'test01','rk0001','f2:sex','nan'
Took 0.0250 seconds
hbase(main):024:0> put 'test01','rk0001','f2:address','beijing'
Took 0.0089 seconds
hbase(main):025:0> put 'test01','rk0002','f1:name','lisi'
01','rk0003','f1:age','28'
put 'test01','rk0003','f1:birthday','1993-10-25'
put 'test01','rk0003','f2:sex','nan'
put 'test01','rk0003','f2:address','tianjin'
put 'test01','0001','f1:name','zhaoliu'
put 'test01','0001','f1:age','25'
put 'test01','0001','f1:birthday','1995-05-05'
put 'test01','0001','f2:sex','nan'
put 'test01','0001','f2:address','guangzhou'Took 0.0061 seconds
hbase(main):026:0> put 'test01','rk0002','f1:age','25'
Took 0.0128 seconds
hbase(main):027:0> put 'test01','rk0002','f1:birthday','2005-10-10'
Took 0.0095 seconds
hbase(main):028:0> put 'test01','rk0002','f2:sex','nv'
Took 0.0067 seconds
hbase(main):029:0> put 'test01','rk0002','f2:address','shanghai'
Took 0.0128 seconds
hbase(main):030:0> put 'test01','rk0003','f1:name','王五'
Took 0.0048 seconds
hbase(main):031:0> put 'test01','rk0003','f1:age','28'
Took 0.0076 seconds
hbase(main):032:0> put 'test01','rk0003','f1:birthday','1993-10-25'
Took 0.0054 seconds
hbase(main):033:0> put 'test01','rk0003','f2:sex','nan'
Took 0.0067 seconds
hbase(main):034:0> put 'test01','rk0003','f2:address','tianjin'
Took 0.0045 seconds
hbase(main):035:0> put 'test01','0001','f1:name','zhaoliu'
Took 0.0056 seconds
hbase(main):036:0> put 'test01','0001','f1:age','25'
Took 0.0064 seconds
hbase(main):037:0> put 'test01','0001','f1:birthday','1995-05-05'
Took 0.0058 seconds
hbase(main):038:0> put 'test01','0001','f2:sex','nan'
Took 0.0093 seconds
hbase(main):039:0> put 'test01','0001','f2:address','guangzhou'
Took 0.0066 seconds
hbase(main):040:0> count 'test01'
4 row(s)
Took 0.0202 seconds
=> 4
hbase(main):041:0>
查询
hbase(main):041:0> scan 'test01'
ROW COLUMN+CELL
0001 column=f1:age, timestamp=1682927992232, value=25
0001 column=f1:birthday, timestamp=1682927992253, value=1995-05-05
0001 column=f1:name, timestamp=1682927992216, value=zhaoliu
0001 column=f2:address, timestamp=1682927993912, value=guangzhou
0001 column=f2:sex, timestamp=1682927992273, value=nan
rk0001 column=f1:age, timestamp=1682927955560, value=20
rk0001 column=f1:birthday, timestamp=1682927955584, value=2020-10-10
rk0001 column=f1:name, timestamp=1682927955535, value=zhangsan
rk0001 column=f2:address, timestamp=1682927957076, value=beijing
rk0001 column=f2:sex, timestamp=1682927955609, value=nan
rk0002 column=f1:age, timestamp=1682927991975, value=25
rk0002 column=f1:birthday, timestamp=1682927992008, value=2005-10-10
rk0002 column=f1:name, timestamp=1682927991952, value=lisi
rk0002 column=f2:address, timestamp=1682927992080, value=shanghai
rk0002 column=f2:sex, timestamp=1682927992059, value=nv
rk0003 column=f1:age, timestamp=1682927992124, value=28
rk0003 column=f1:birthday, timestamp=1682927992148, value=1993-10-25
rk0003 column=f1:name, timestamp=1682927992104, value=\xE7\x8E\x8B\xE4\xBA\x94
rk0003 column=f2:address, timestamp=1682927992197, value=tianjin
rk0003 column=f2:sex, timestamp=1682927992178, value=nan
4 row(s)
Took 0.0398 seconds
hbase(main):042:0>
Took 0.0398 seconds
hbase(main):042:0> scan 'test01',{FORMATTER=>'toString'}
ROW COLUMN+CELL
0001 column=f1:age, timestamp=1682927992232, value=25
0001 column=f1:birthday, timestamp=1682927992253, value=1995-05-05
0001 column=f1:name, timestamp=1682927992216, value=zhaoliu
0001 column=f2:address, timestamp=1682927993912, value=guangzhou
0001 column=f2:sex, timestamp=1682927992273, value=nan
rk0001 column=f1:age, timestamp=1682927955560, value=20
rk0001 column=f1:birthday, timestamp=1682927955584, value=2020-10-10
rk0001 column=f1:name, timestamp=1682927955535, value=zhangsan
rk0001 column=f2:address, timestamp=1682927957076, value=beijing
rk0001 column=f2:sex, timestamp=1682927955609, value=nan
rk0002 column=f1:age, timestamp=1682927991975, value=25
rk0002 column=f1:birthday, timestamp=1682927992008, value=2005-10-10
rk0002 column=f1:name, timestamp=1682927991952, value=lisi
rk0002 column=f2:address, timestamp=1682927992080, value=shanghai
rk0002 column=f2:sex, timestamp=1682927992059, value=nv
rk0003 column=f1:age, timestamp=1682927992124, value=28
rk0003 column=f1:birthday, timestamp=1682927992148, value=1993-10-25
rk0003 column=f1:name, timestamp=1682927992104, value=王五
rk0003 column=f2:address, timestamp=1682927992197, value=tianjin
rk0003 column=f2:sex, timestamp=1682927992178, value=nan
4 row(s)
Took 0.0356 seconds
hbase(main):043:0> scan 'test01',{FORMATTER=>'toString',LIMIT=>2}
ROW COLUMN+CELL
0001 column=f1:age, timestamp=1682927992232, value=25
0001 column=f1:birthday, timestamp=1682927992253, value=1995-05-05
0001 column=f1:name, timestamp=1682927992216, value=zhaoliu
0001 column=f2:address, timestamp=1682927993912, value=guangzhou
0001 column=f2:sex, timestamp=1682927992273, value=nan
rk0001 column=f1:age, timestamp=1682927955560, value=20
rk0001 column=f1:birthday, timestamp=1682927955584, value=2020-10-10
rk0001 column=f1:name, timestamp=1682927955535, value=zhangsan
rk0001 column=f2:address, timestamp=1682927957076, value=beijing
rk0001 column=f2:sex, timestamp=1682927955609, value=nan
2 row(s)
Took 0.0436 seconds
hbase(main):044:0> scan 'test01',{COLUMN=>'f1'}
ROW COLUMN+CELL
0001 column=f1:age, timestamp=1682927992232, value=25
0001 column=f1:birthday, timestamp=1682927992253, value=1995-05-05
0001 column=f1:name, timestamp=1682927992216, value=zhaoliu
rk0001 column=f1:age, timestamp=1682927955560, value=20
rk0001 column=f1:birthday, timestamp=1682927955584, value=2020-10-10
rk0001 column=f1:name, timestamp=1682927955535, value=zhangsan
rk0002 column=f1:age, timestamp=1682927991975, value=25
rk0002 column=f1:birthday, timestamp=1682927992008, value=2005-10-10
rk0002 column=f1:name, timestamp=1682927991952, value=lisi
rk0003 column=f1:age, timestamp=1682927992124, value=28
rk0003 column=f1:birthday, timestamp=1682927992148, value=1993-10-25
rk0003 column=f1:name, timestamp=1682927992104, value=\xE7\x8E\x8B\xE4\xBA\x94
4 row(s)
Took 0.0157 seconds
hbase(main):045:0> scan 'test01',{COLUMN=>['f1','f2:address']}
ROW COLUMN+CELL
0001 column=f1:age, timestamp=1682927992232, value=25
0001 column=f1:birthday, timestamp=1682927992253, value=1995-05-05
0001 column=f1:name, timestamp=1682927992216, value=zhaoliu
0001 column=f2:address, timestamp=1682927993912, value=guangzhou
rk0001 column=f1:age, timestamp=1682927955560, value=20
rk0001 column=f1:birthday, timestamp=1682927955584, value=2020-10-10
rk0001 column=f1:name, timestamp=1682927955535, value=zhangsan
rk0001 column=f2:address, timestamp=1682927957076, value=beijing
rk0002 column=f1:age, timestamp=1682927991975, value=25
rk0002 column=f1:birthday, timestamp=1682927992008, value=2005-10-10
rk0002 column=f1:name, timestamp=1682927991952, value=lisi
rk0002 column=f2:address, timestamp=1682927992080, value=shanghai
rk0003 column=f1:age, timestamp=1682927992124, value=28
rk0003 column=f1:birthday, timestamp=1682927992148, value=1993-10-25
rk0003 column=f1:name, timestamp=1682927992104, value=\xE7\x8E\x8B\xE4\xBA\x94
rk0003 column=f2:address, timestamp=1682927992197, value=tianjin
4 row(s)
Took 0.0353 seconds
hbase(main):046:0>
hbase(main):046:0> scan 'test01',{STARTROW=>'rk0001',ENDROW=>'rk0003'}
ROW COLUMN+CELL
rk0001 column=f1:age, timestamp=1682927955560, value=20
rk0001 column=f1:birthday, timestamp=1682927955584, value=2020-10-10
rk0001 column=f1:name, timestamp=1682927955535, value=zhangsan
rk0001 column=f2:address, timestamp=1682927957076, value=beijing
rk0001 column=f2:sex, timestamp=1682927955609, value=nan
rk0002 column=f1:age, timestamp=1682927991975, value=25
rk0002 column=f1:birthday, timestamp=1682927992008, value=2005-10-10
rk0002 column=f1:name, timestamp=1682927991952, value=lisi
rk0002 column=f2:address, timestamp=1682927992080, value=shanghai
rk0002 column=f2:sex, timestamp=1682927992059, value=nv
2 row(s)
Took 0.0163 seconds
六、hbase的高级shell命令
whoami: 查看当前登录用户
hbase(main):002:0> whoami
pxj (auth:SIMPLE)
groups: pxj
Took 0.0098 seconds
exists查看表是否存在
hbase(main):003:0> exists 'test01'
Table test01 does exist
Took 0.5810 seconds
=> true
alter: 用来执行修改表的操作
增加列族:
alter '表名' ,NAME=>'新的列族'
删除列族:
alter '表名','delete'=>'旧的列族'
hbase的filter过滤器相关的操作 :
作用:补充hbase的查询方式
格式:
scan '表名',{FILTER=>"过滤器(比较运算符,'比较器表达式')"}
在hbase中常用的过滤器:
rowkey过滤器:
RowFilter: 实现根据某一个rowkey过滤数据
PrefixFilter: rowkey前缀过滤器
列族过滤器:
FamilyFilter: 列族过滤器
列名过滤器:
QualifierFilter : 列名过滤器, 显示对应列的数据
列值过滤器:
ValueFilter: 列值过滤器, 找到符合条件的列值
SingleColumnValueFilter: 在指定列族和列名下, 查询符合对应列值数据 的整行数据
SingleColumnValueExcludeFilter : 在指定列族和列名下, 查询符合对应列值数据 的整行数据 结果不包含过滤字段
其他过滤器:
PageFilter : 用于分页过滤器
比较运算符: > < >= <= != =
比较器:
BinaryComparator: 用于进行完整的匹配操作
BinaryPrefixComparator : 匹配指定的前缀数据
NullComparator : 空值匹配操作
SubstringComparator: 模糊匹配
比较器表达式:
BinaryComparator binary:值
BinaryPrefixComparator binaryprefix:值
NullComparator null
SubstringComparator substring:值
参考地址:
http://hbase.apache.org/2.2/devapidocs/index.html
从这个地址下, 找到对应过滤器, 查看其构造, 根据构造编写filter过滤器即可
需求一: 找到在列名中包含 字母 e 列名有哪些
hbase(main):004:0> scan 'test01',{FILTER=>"QualifierFilter(=,'substring:e')"}
ROW COLUMN+CELL
0001 column=f1:age, timestamp=1682927992232, value=25
0001 column=f1:name, timestamp=1682927992216, value=zhaoliu
0001 column=f2:address, timestamp=1682927993912, value=guangzhou
0001 column=f2:sex, timestamp=1682927992273, value=nan
rk0001 column=f1:age, timestamp=1682927955560, value=20
rk0001 column=f1:name, timestamp=1682927955535, value=zhangsan
rk0001 column=f2:address, timestamp=1682927957076, value=beijing
rk0001 column=f2:sex, timestamp=1682927955609, value=nan
rk0002 column=f1:age, timestamp=1682927991975, value=25
rk0002 column=f1:name, timestamp=1682927991952, value=lisi
rk0002 column=f2:address, timestamp=1682927992080, value=shanghai
rk0002 column=f2:sex, timestamp=1682927992059, value=nv
rk0003 column=f1:age, timestamp=1682927992124, value=28
rk0003 column=f1:name, timestamp=1682927992104, value=\xE7\x8E\x8B\xE4\xBA\x94
rk0003 column=f2:address, timestamp=1682927992197, value=tianjin
rk0003 column=f2:sex, timestamp=1682927992178, value=nan
4 row(s)
Took 0.1787 seconds
需求二: 查看rowkey以rk开头的数据
hbase(main):005:0> scan 'test01',{FILTER=>"PrefixFilter('rk')"}
ROW COLUMN+CELL
rk0001 column=f1:age, timestamp=1682927955560, value=20
rk0001 column=f1:birthday, timestamp=1682927955584, value=2020-10-10
rk0001 column=f1:name, timestamp=1682927955535, value=zhangsan
rk0001 column=f2:address, timestamp=1682927957076, value=beijing
rk0001 column=f2:sex, timestamp=1682927955609, value=nan
rk0002 column=f1:age, timestamp=1682927991975, value=25
rk0002 column=f1:birthday, timestamp=1682927992008, value=2005-10-10
rk0002 column=f1:name, timestamp=1682927991952, value=lisi
rk0002 column=f2:address, timestamp=1682927992080, value=shanghai
rk0002 column=f2:sex, timestamp=1682927992059, value=nv
rk0003 column=f1:age, timestamp=1682927992124, value=28
rk0003 column=f1:birthday, timestamp=1682927992148, value=1993-10-25
rk0003 column=f1:name, timestamp=1682927992104, value=\xE7\x8E\x8B\xE4\xBA\x94
rk0003 column=f2:address, timestamp=1682927992197, value=tianjin
rk0003 column=f2:sex, timestamp=1682927992178, value=nan
3 row(s)
Took 0.0328 seconds
hbase(main):006:0> scan 'test01',{FILTER=>"RowFilter(=,'binaryprefix:rk')"}
ROW COLUMN+CELL
rk0001 column=f1:age, timestamp=1682927955560, value=20
rk0001 column=f1:birthday, timestamp=1682927955584, value=2020-10-10
rk0001 column=f1:name, timestamp=1682927955535, value=zhangsan
rk0001 column=f2:address, timestamp=1682927957076, value=beijing
rk0001 column=f2:sex, timestamp=1682927955609, value=nan
rk0002 column=f1:age, timestamp=1682927991975, value=25
rk0002 column=f1:birthday, timestamp=1682927992008, value=2005-10-10
rk0002 column=f1:name, timestamp=1682927991952, value=lisi
rk0002 column=f2:address, timestamp=1682927992080, value=shanghai
rk0002 column=f2:sex, timestamp=1682927992059, value=nv
rk0003 column=f1:age, timestamp=1682927992124, value=28
rk0003 column=f1:birthday, timestamp=1682927992148, value=1993-10-25
rk0003 column=f1:name, timestamp=1682927992104, value=\xE7\x8E\x8B\xE4\xBA\x94
rk0003 column=f2:address, timestamp=1682927992197, value=tianjin
rk0003 column=f2:sex, timestamp=1682927992178, value=nan
3 row(s)
Took 0.0502 seconds
需求三: 查询 年龄大于等于25岁的数据
hbase(main):007:0> scan 'test01',{FILTER=>"SingleColumnValueFilter('f1','age',>=,'binary:25')"}
ROW COLUMN+CELL
0001 column=f1:age, timestamp=1682927992232, value=25
0001 column=f1:birthday, timestamp=1682927992253, value=1995-05-05
0001 column=f1:name, timestamp=1682927992216, value=zhaoliu
0001 column=f2:address, timestamp=1682927993912, value=guangzhou
0001 column=f2:sex, timestamp=1682927992273, value=nan
rk0002 column=f1:age, timestamp=1682927991975, value=25
rk0002 column=f1:birthday, timestamp=1682927992008, value=2005-10-10
rk0002 column=f1:name, timestamp=1682927991952, value=lisi
rk0002 column=f2:address, timestamp=1682927992080, value=shanghai
rk0002 column=f2:sex, timestamp=1682927992059, value=nv
rk0003 column=f1:age, timestamp=1682927992124, value=28
rk0003 column=f1:birthday, timestamp=1682927992148, value=1993-10-25
rk0003 column=f1:name, timestamp=1682927992104, value=\xE7\x8E\x8B\xE4\xBA\x94
rk0003 column=f2:address, timestamp=1682927992197, value=tianjin
rk0003 column=f2:sex, timestamp=1682927992178, value=nan
3 row(s)
Took 0.0422 seconds
hbase(main):008:0> scan 'test01',{FILTER=>"SingleColumnValueExcludeFilter('f1','age',>=,'binary:25')"}
ROW COLUMN+CELL
0001 column=f1:birthday, timestamp=1682927992253, value=1995-05-05
0001 column=f1:name, timestamp=1682927992216, value=zhaoliu
0001 column=f2:address, timestamp=1682927993912, value=guangzhou
0001 column=f2:sex, timestamp=1682927992273, value=nan
rk0002 column=f1:birthday, timestamp=1682927992008, value=2005-10-10
rk0002 column=f1:name, timestamp=1682927991952, value=lisi
rk0002 column=f2:address, timestamp=1682927992080, value=shanghai
rk0002 column=f2:sex, timestamp=1682927992059, value=nv
rk0003 column=f1:birthday, timestamp=1682927992148, value=1993-10-25
rk0003 column=f1:name, timestamp=1682927992104, value=\xE7\x8E\x8B\xE4\xBA\x94
rk0003 column=f2:address, timestamp=1682927992197, value=tianjin
rk0003 column=f2:sex, timestamp=1682927992178, value=nan
3 row(s)
Took 0.0273 seconds
七、Java操作API
准备工作:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.ccj.pxj</groupId>
<artifactId>Hbase_Ky</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<repositories><!--代码库-->
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases><enabled>true</enabled></releases>
<snapshots>
<enabled>false</enabled>
<updatePolicy>never</updatePolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version></dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
<scope>compile</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<target>1.8</target>
<source>1.8</source>
</configuration>
</plugin>
</plugins>
</build>
</project>
7.1创建表
@Test
public void test01() throws Exception{
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","pxj62:2181,pxj63:2181,pxj64:2181");
Connection hbaseConn = ConnectionFactory.createConnection(conf);
// 2) 根据连接对象, 获取相关的管理对象: admin(执行对表进行操作) table(执行对表数据的操作)tabl
Admin admin = hbaseConn.getAdmin();
// 3) 执行相关的操作
// 3.1) 判断表是否存在呢?
// 返回true 表示存在 返回false 表示不存在
boolean flag = admin.tableExists(TableName.valueOf("WATER_BILL"));
if(!flag){
// 说明表不存在, 需要构建表
//3.2 创建表
//3.2.1 创建表的构建器对象
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(TableName.valueOf("WATER_BILL"));
//3.2.2 在构建器对象中, 设置表的列族信息
ColumnFamilyDescriptor familyDescriptor = ColumnFamilyDescriptorBuilder.newBuilder("C1".getBytes()).build();
tableDescriptorBuilder.setColumnFamily(familyDescriptor);
// 3.2.3得到表结构对象
TableDescriptor tableDescriptor = tableDescriptorBuilder.build();
admin.createTable(tableDescriptor);
}
// 处理结果集(只要查询才有结果集)
// 释放资源
admin.close();
hbaseConn.close();
}
7.2 添加数据
@Test
public void test02() throws Exception{
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","pxj62:2181,pxj63:2181,pxj64:2181");
Connection hbaseConn = ConnectionFactory.createConnection(conf);
// 2- 根据连接对象, 获取相关的管理对象: admin table
Table table = hbaseConn.getTable(TableName.valueOf("WATER_BILL"));
// 3.执行相关操作:添加数据
Put put = new Put("4944191".getBytes());
put.addColumn("C1".getBytes(),"NAME".getBytes(),"登卫红".getBytes());
put.addColumn("C1".getBytes(),"ADDRESS".getBytes(),"贵州省铜仁市德江县7单元267室".getBytes());
put.addColumn("C1".getBytes(),"SEX".getBytes(),"男".getBytes());
table.put(put);
// 4- 处理结果集(只有查询存在)
// 5- 释放资源
table.close();
hbaseConn.close();
}
7.3抽取公共方法
private Connection hbaseConn;
private Admin admin;
private Table table;
@Before
public void before() throws Exception{
// 1- 根据hbase的连接工厂对象创建hbase的连接对象
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","pxj62:2181,pxj63:2181,pxj64:2181");
hbaseConn = ConnectionFactory.createConnection(conf);
// 2- 根据连接对象, 获取相关的管理对象: admin table
admin = hbaseConn.getAdmin();
table = hbaseConn.getTable(TableName.valueOf("WATER_BILL"));
}
7.4查询一条数据
@Test
public void test03() throws Exception {
// 3- 执行相关的操作
Get get = new Get("4944191".getBytes());
Result result = table.get(get);
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
byte[] rowKeyBytes = CellUtil.cloneRow(cell);
byte[] familyBytes = CellUtil.cloneFamily(cell);
byte[] columnNameBtyes = CellUtil.cloneQualifier(cell);
byte[] valueBytes = CellUtil.cloneValue(cell);
String rowKey = Bytes.toString(rowKeyBytes);
String family = Bytes.toString(familyBytes);
String columnName = Bytes.toString(columnNameBtyes);
String value = Bytes.toString(valueBytes);
System.out.println("rowkey为:"+rowKey +", 列族为:"+family +"; 列名为:"+columnName+"; 列值为:"+value);
}
}
7.5删除数据
// 需求五:删除数据操作,rowkey为4944191的数据删除
@Test
public void test05() throws Exception{
Delete delete = new Delete("4944191".getBytes());
table.delete(delete);
}
hbase(main):004:0> scan 'WATER_BILL'
ROW COLUMN+CELL
0 row(s)
Took 0.0183 seconds
7.6删除表操作
@Test
public void test06() throws Exception{
//3. 执行相关的操作
//3.1: 如果表没有被禁用, 先禁用表
if( admin.isTableEnabled(TableName.valueOf("WATER_BILL")) ){
admin.disableTable(TableName.valueOf("WATER_BILL"));
}
//3.2: 执行删除
admin.deleteTable(TableName.valueOf("WATER_BILL"));
//4. 处理结果集
}
=> ["test01", "test02"]
hbase(main):006:0> scan 'WATER_BILL'
ROW COLUMN+CELL
org.apache.hadoop.hbase.TableNotFoundException: WATER_BILL
at org.apache.hadoop.hbase.client.ConnectionImplementation.getTableState(ConnectionImplementation.java:1954)
at org.apache.hadoop.hbase.client.ConnectionImplementation.isTableDisabled(ConnectionImplementation.java:583)
at org.apache.hadoop.hbase.client.ConnectionImplementation.relocateRegion(ConnectionImplementation.java:713)
at org.apache.hadoop.hbase.client.RpcRetryingCallerWithReadReplicas.getRegionLocations(RpcRetryingCallerWithReadReplicas.java:328)
at org.apache.hadoop.hbase.client.ScannerCallable.prepare(ScannerCallable.java:139)
at org.apache.hadoop.hbase.client.ScannerCallableWithReplicas$RetryingRPC.prepare(ScannerCallableWithReplicas.java:399)
at org.apache.hadoop.hbase.client.RpcRetryingCallerImpl.callWithRetries(RpcRetryingCallerImpl.java:105)
at org.apache.hadoop.hbase.client.ResultBoundedCompletionService$QueueingFuture.run(ResultBoundedCompletionService.java:80)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
ERROR: Unknown table WATER_BILL!
For usage try 'help "scan"'
Took 1.0289 seconds
7.7导入数据的操作
如何导入数据
hbase org.apache.hadoop.hbase.mapreduce.Import 表名 HDFS数据文件路径
执行相关操作
1) 需要先将资料中10w抄表数据上传到HDFS中:
hdfs dfs -mkdir -p /hbase/water_bill/input
将数据上传到此目录下
hdfs dfs -put part-m-00000_10w /hbase/water_bill/input
2) 执行导入操作:
hbase org.apache.hadoop.hbase.mapreduce.Import WATER_BILL /hbase/water_bill/input/part-m-00000_10w
[pxj@pxj63 /opt/sofe]$rz -E
rz waiting to receive.
[pxj@pxj63 /opt/sofe]$ll
总用量 712392
-rw-r--r--. 1 pxj pxj 678001736 3月 21 22:53 mysql-5.7.40-linux-glibc2.12-x86_64.tar.gz
-rw-r--r--. 1 pxj pxj 51483241 4月 13 23:32 part-m-00000_10w
[pxj@pxj63 /opt/sofe]$hdfs dfs -mkdir -p /hbase/water_bill/input
hbase(main):007:0> count 'WATER_BILL'
Current count: 1000, row: 0100876
Current count: 2000, row: 0198911
Current count: 3000, row: 0297202
Current count: 4000, row: 0396260
Current count: 5000, row: 0496133
Current count: 6000, row: 0600497
Current count: 7000, row: 0703223
Current count: 8000, row: 0800139
Current count: 9000, row: 0894996
Current count: 10000, row: 0989166
Current count: 11000, row: 1083304
Current count: 12000, row: 1176972
Current count: 13000, row: 1282285
Current count: 14000, row: 1384119
Current count: 15000, row: 1486440
Current count: 16000, row: 1585872
Current count: 17000, row: 1683376
Current count: 18000, row: 1784217
Current count: 19000, row: 1883173
Current count: 20000, row: 1981216
Current count: 21000, row: 2080089
Current count: 22000, row: 2177073
Current count: 23000, row: 2281290
Current count: 24000, row: 2387611
Current count: 25000, row: 2485928
Current count: 26000, row: 2586855
Current count: 27000, row: 2692853
Current count: 28000, row: 2790279
Current count: 29000, row: 2891564
Current count: 30000, row: 2992772
Current count: 31000, row: 3092745
Current count: 32000, row: 3192473
Current count: 33000, row: 3292718
Current count: 34000, row: 3392517
Current count: 35000, row: 3492498
Current count: 36000, row: 3597604
Current count: 37000, row: 3699894
Current count: 38000, row: 3803168
Current count: 39000, row: 3907990
Current count: 40000, row: 4010517
Current count: 41000, row: 4110878
Current count: 42000, row: 4207162
Current count: 43000, row: 4306768
Current count: 44000, row: 4413198
Current count: 45000, row: 4512536
Current count: 46000, row: 4612263
Current count: 47000, row: 4713620
Current count: 48000, row: 4815897
Current count: 49000, row: 4916970
Current count: 50000, row: 5011658
Current count: 51000, row: 5118661
Current count: 52000, row: 5214746
Current count: 53000, row: 5312632
Current count: 54000, row: 5409128
Current count: 55000, row: 5502543
Current count: 56000, row: 5601945
Current count: 57000, row: 5707443
Current count: 58000, row: 5815118
Current count: 59000, row: 5913868
Current count: 60000, row: 6014358
Current count: 61000, row: 6111505
Current count: 62000, row: 6208207
Current count: 63000, row: 6309356
Current count: 64000, row: 6414059
Current count: 65000, row: 6516637
Current count: 66000, row: 6612872
Current count: 67000, row: 6718005
Current count: 68000, row: 6814867
Current count: 69000, row: 6919232
Current count: 70000, row: 7014585
Current count: 71000, row: 7115052
Current count: 72000, row: 7215747
Current count: 73000, row: 7316079
Current count: 74000, row: 7419978
Current count: 75000, row: 7524553
Current count: 76000, row: 7628323
Current count: 77000, row: 7729588
Current count: 78000, row: 7833969
Current count: 79000, row: 7935328
Current count: 80000, row: 8035829
Current count: 81000, row: 8133527
Current count: 82000, row: 8236834
Current count: 83000, row: 8341968
Current count: 84000, row: 8442569
Current count: 85000, row: 8542044
Current count: 86000, row: 8648227
Current count: 87000, row: 8746478
Current count: 88000, row: 8848619
Current count: 89000, row: 8948384
Current count: 90000, row: 9048613
Current count: 91000, row: 9151751
Current count: 92000, row: 9250679
Current count: 93000, row: 9349696
Current count: 94000, row: 9450573
Current count: 95000, row: 9550716
Current count: 96000, row: 9651741
Current count: 97000, row: 9747953
Current count: 98000, row: 9848779
Current count: 99000, row: 9951726
99505 row(s)
Took 8.1651 seconds
=> 99505
7.8案例
需求: 查询2020年 6月份所有用户的用水量:
日期字段: RECORD_DATE
用水量: NUM_USAGE
用户: NAME
/*
需求: 查询2020年 6月份所有用户的用水量:
日期字段: RECORD_DATE
用水量: NUM_USAGE
用户: NAME
*/
// SQL: select NAME,NUM_USAGE from WATER_BILL where RECORD_DATE between '2020-06-01' and '2020-06-30';
```java
@Test
public void test07()throws Exception{
// 3.执行相关的操作
Scan scan = new Scan();
// 3.1:设置过滤条件
SingleColumnValueFilter filter1 = new SingleColumnValueFilter(
"C1".getBytes(),
"RECORD_DATE".getBytes(),
CompareOperator.GREATER_OR_EQUAL,
new BinaryComparator("2020-06-01".getBytes())
);
SingleColumnValueFilter filter2 = new SingleColumnValueFilter(
"C1".getBytes(),
"RECORD_DATE".getBytes(),
CompareOperator.LESS_OR_EQUAL,
new BinaryComparator("2020-06-30".getBytes())
);
//3.1.2 构建 filter集合, 将镀铬filter合并在一起
FilterList filterList = new FilterList();
filterList.addFilter(filter1);
filterList.addFilter(filter2);
// 设置输出行数
scan.setLimit(10);
// 在查询的时候,限定返回那些列的数据
scan.addColumn("C1".getBytes(),"NAME".getBytes());
scan.addColumn("C1".getBytes(),"NUM_USAGE".getBytes());
scan.addColumn("C1".getBytes(),"RECORD_DATE".getBytes());
ResultScanner results = table.getScanner(scan); // 获取到多行数据
//4- 处理结果集
//4.1: 获取每一行的数据
for (Result result : results) {
// 4.2 将一行中每一个单元格获取
List<Cell> cells = result.listCells();
// 4.3 遍历每一个单元格: 一个单元格里面主要包含(rowkey信息, 列族信息, 列名信息, 列值信息)
for (Cell cell : cells) {
byte[] columnNameBtyes = CellUtil.cloneQualifier(cell);
String columnName = Bytes.toString(columnNameBtyes);
//if("NAME".equals(columnName) || "NUM_USAGE".equals(columnName) || "RECORD_DATE".equals(columnName)){
byte[] rowKeyBytes = CellUtil.cloneRow(cell);
byte[] familyBytes = CellUtil.cloneFamily(cell);
byte[] valueBytes = CellUtil.cloneValue(cell);
String rowKey = Bytes.toString(rowKeyBytes);
String family = Bytes.toString(familyBytes);
Object value ;
if("NUM_USAGE".equals(columnName)){
value = Bytes.toDouble(valueBytes);
}else{
value = Bytes.toString(valueBytes);
}
System.out.println("rowkey为:"+rowKey +", 列族为:"+family +"; 列名为:"+columnName+"; 列值为:"+value);
//}
}
System.out.println("---------------------------------------");
}
}
作者:潘陈(pxj)
日期:2023-05-03