目录
头文件-源代码
头文件重复包含
问题
解决方案
程序生成过程
预处理Preprocessi
编译Compilation
汇编Assembly
链接Linking
编译期-运行期
编译期确定
运行期确定
编译期错误
运行期错误
类和对象
宏
宏的其他用法
inline内联
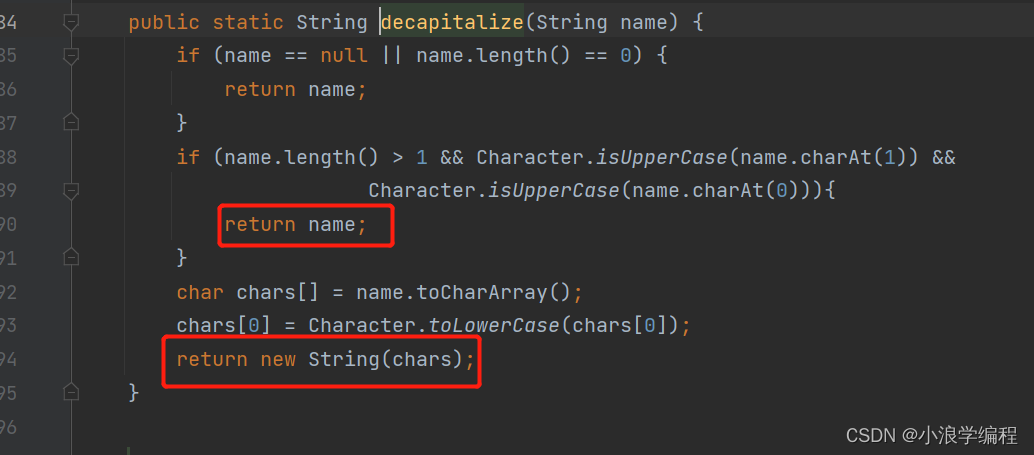
头文件-源代码
头文件(.h)和源文件(.cpp)两者的区别:
- 默认情况下,头文件不参与编译,而每个源文件自上而下独立编译。
- 通常我们将声明的变量、类型、函数、宏、结构体和类的定义等放于头文件(.h文件),将变量的定义初始化、函数的定义实现放于源文件中,这样方便于我们去管理、规划,更重要的是避免了重定义的问题。

正常变量的声明与定义
//test.h
extern int b; //变量的声明//test.cpp
int b = 1;注意:变量不要在头文件中直接定义
正常函数的声明与定义
//test.h
void fun(int ); //声明//test.cpp
void fun(int a) {
cout << __FUNCTION__ << endl;
}类中的成员函数在对应的源文件中定义时,一定要加上类名作用域。
//test.h
class CTest{
public:
void fun();
};//test.cpp
void CTest::fun(){
cout << __FUNCTION__ << endl;
}类中普通成员属性和const成员属性在构造函数中的初始化参数列表进行初始化定义,而静态成员属性要在源文件中单独定义。
//test.h
class CTest {
public:
int m_a;
static int m_b;
const int m_c;
CTest(); //只声明
~CTest();
};//test.cpp
int CTest::m_b = 5;
//类成员函数在类外定义,需要在函数名前加上类名作用域
CTest::CTest():m_a(4) ,m_c(6){
cout << __FUNCTION__ << endl;
}
CTest::~CTest() {
cout << __FUNCTION__ << endl;
}常函数的声明与定义(保留const关键字)
//test.h
void funConst() const;
//test.cpp
//关键字需要保留
void CTest::funConst(/* const CTest* const this */) const {
cout << __FUNCTION__ << endl;
}静态成员函数的声明与定义(去掉static关键字)
//test.h
static void funStatic();//test.cpp
void CTest::funStatic() { //去掉static 关键字
cout << __FUNCTION__ << endl;
}虚函数的声明与定义(去掉virtual关键字)
//test.h
virtual void funVirtual();//test.cpp
//去掉 virtual关键字
void CTest::funVirtual() {
cout << __FUNCTION__ << endl;
}纯虚函数(不需要实现)
//test.h
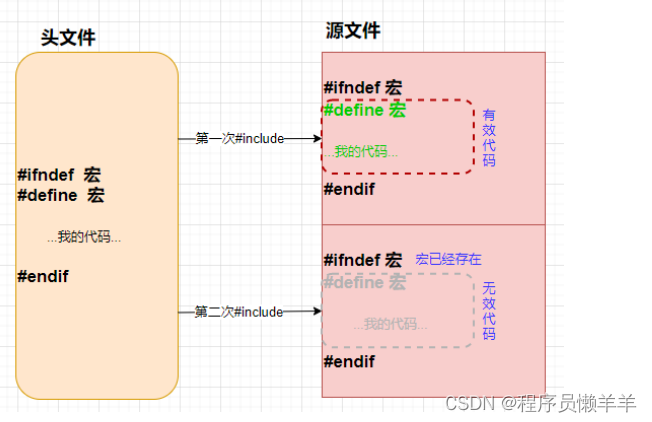
virtual void fun() = 0;头文件重复包含
问题
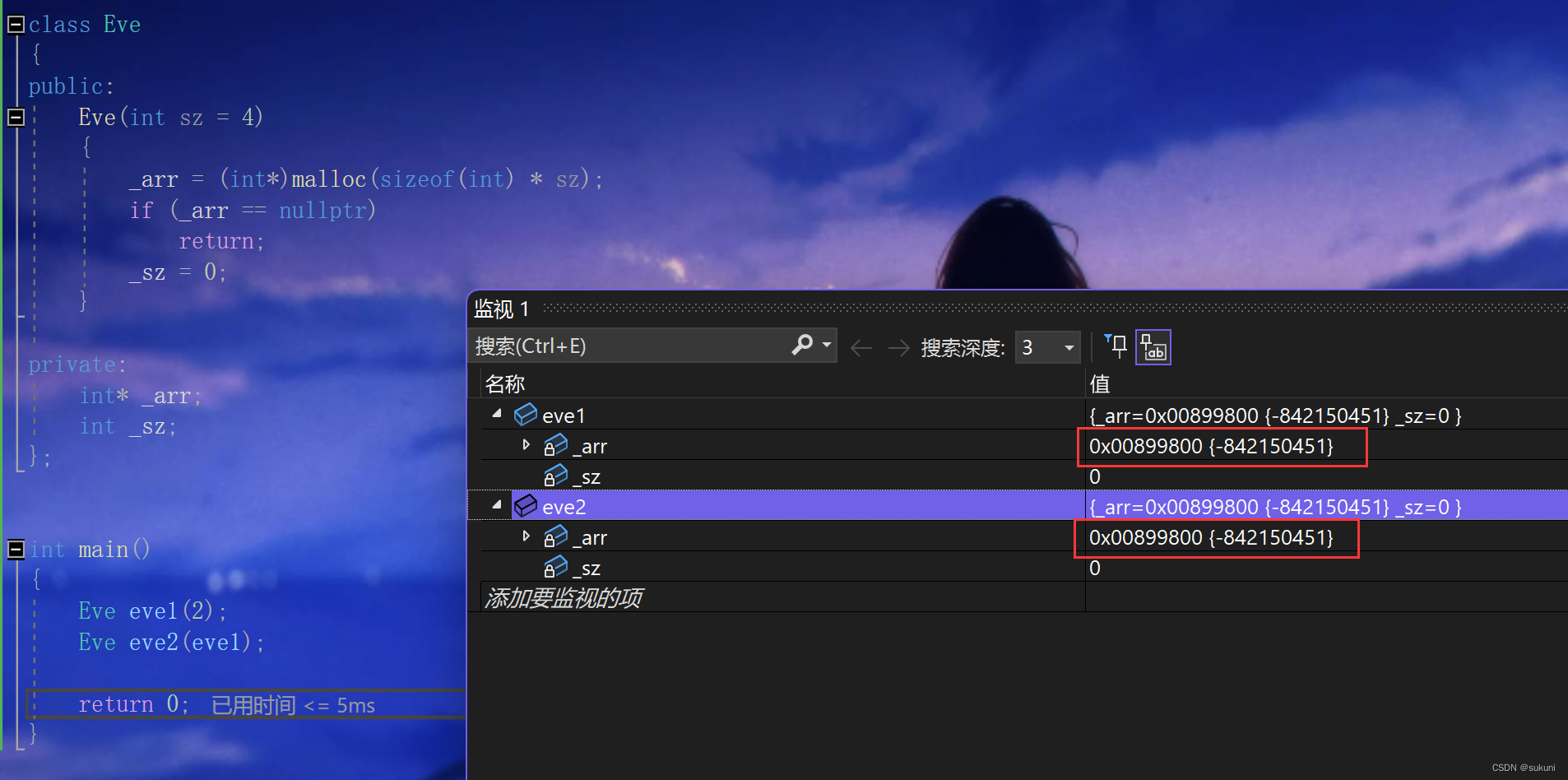
如果在一个头文件中创建一个类,然后另外两个头文件又都用到了这个头文件,在源文件中使用了另外两个头文件,那么第一个头文件中的类就会被创建两次,会出现重定义的错误。
//AA.h
class AA {
public:
int m_a = 0;
};//BB.h
#include"AA.h"
class BB {
public:
AA m_aa;
};//CC.h
#include"AA.h"
class CC {
public:
AA m_aa;
};在源文件中使用BB和CC两个头文件打开后就是这样:
class AA {
public:
int m_a = 0;
};
class BB {
public:
AA m_aa;
};
class AA {
public:
int m_a = 0;
};
class CC {
public:
AA m_aa;
};那么这种现象就称为头文件重复包含
解决方案
解决头文件重复包含问题有两种方法:
- #pragma once : 告诉编译器,当前的头文件在其他的源文件中只包含一次
- 宏逻辑判断(#ifndef #define #endif)
对比:
- #pragma once直接告诉编译器这个文件在源文件中只包含一次,相对来说效率比较高。
- 基于宏逻辑判断,在大量头文件时,编译速度降低,耗时增加。而且需要考虑宏重名的问题,一般情况下宏的名字与当前文件名对应,但时并不能保证一定不重名,如果不同路径下存在相同的文件,也可能会重复。
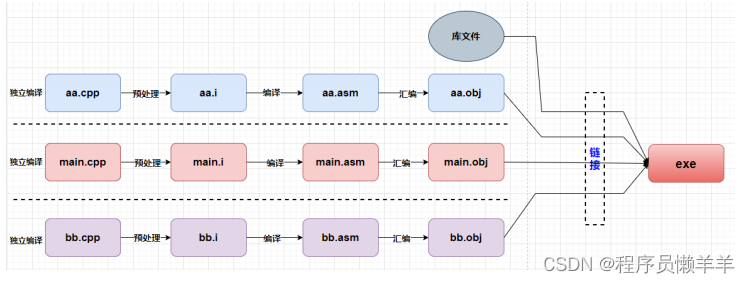
程序生成过程
预处理Preprocessi
将原文件(.cpp)初步处理,生成预处理文件(.i):
- 解析#include头文件展开替换。
- 宏定义指令:#define宏的替换,#undef等。
- 预处理指令:解析#if、#ifndef、#ifdef、#else、#elif、#endif等。
- 删除所有注释。
编译Compilation
将预处理后的文件(.i)进行一系列词法分析、语法分析、语义分析及优化,产生相应的汇编代码文件(.asm)。
汇编Assembly
将编译后的汇编代码文件(.asm)汇编指令逐条翻译成目标机器指令,并生成可重定位目标程序的.obj文件,该文件为二进制文件,字节编码是机器指令。
链接Linking
通过链接器将多个目标文件(.obj)和库文件链接在一起生成一个完整的可执行程序。
编译期-运行期
编译期:是指把源程序交给编译器编译、生成的过程,最终得到可执行文件。
运行期:是指将可执行文件交给操作系统执行、直到程序退出,把在磁盘中的程序二进制代码放到内存中执行起来,执行的目的是为了实现程序的功能。
编译期确定
#ifdef __cplusplus
#define A 1
#else
#define A 2
#endif
int a = A; //编译期确定
cout << a << endl; //1运行期确定
int b = 0;
cin >> b;
if (b) {
b = 10;
}
else {
b = 20;
}
int c = b; //运行期确定
cout << c << endl;编译期错误
int len = 10;
int arr[len]; //编译期错误表达式的计算结果不是常数,编译期分配内存,因为必须要确定len的大小,但它是变量在编译期无法确定其具体值。
运行期错误
int len1 = 0;
cin >> len1;
int* p = new int[len1]; //运行期
//p[100] = 10; //数组越界:运行期错误程序崩溃:数组越界,在编译期是检查不出来的,在真正运行时可能会报错。
类和对象
类:编译期的概念,包括:类成员函数、静态属性,作用域 访问修饰符
对象:运行期的概念实例,引用,指针
class CFather {
public:
virtual void fun() {
cout << "CFather::fun" << endl;
}
};
class CSon :public CFather {
private: //编译期的限制
virtual void fun() {
cout << "CSon::fun" << endl;
}
}; CFather* pFa = new CSon;
pFa->fun(); //Cson::fun编译器在检查代码时,他认为pFa->fun()调用的是父类中public属性的函数,那自然是通过编译的。但是在运行期时由于多态的作用,结果调用的是子类的fun函数,即使子类的fun函数是private但由于访问修饰符是编译期的限制,所以在运行时无效,子列的fun函数自然也能调用。
宏
宏起到替换作用(预处理阶段),一般写法:
#define A 10一个标识符被宏定义后,在用到宏A的地方替换为10,再程序编译前预处理阶段进行替换,替换后才进行编译。
宏是可以传参数的,在宏名字后面加(PARAM),参数的作用也是一个替换。
#define N(PARAM) int a = PARAM;一般情况下,宏替换当前这一行的内容,替换多行可以使用\这个字符
作用:用来连接当前行和下一行。
注意:一般最后一行不加\,\后面不能有任何字符,包括空格、tab、注释等。
#define B\
for (int i = 0; i < A; i++){\
cout << i << " ";\
}使用宏替换需要注意,宏及参数并不会像函数参数一样自动计算,也不做表达式求解,它只是单纯的复制粘贴。
#define N 2+3
int a = N*2; //2+3*2可以加上()来解决
#define N (2+3)
int a = N*2; //(2+3)*2#undef宏:取消宏定义,限制宏的作用范围
#define AB 10
cout << AB << endl;
#undef AB //取消宏定义
int AB = 20;
cout << AB << endl;优点
- 使用宏可以替换在程序中经常使用的常量或表达式,在后期程序维护时,不用对整个程序进行修改,只需要维护、修改一份宏定义的内容即可。
- 宏在一定程度上可以代替简单的函数,这样就省去了调用函数的各种开销,提高程序的运行效率。
缺点
- 不方便调试。
- 没有类型安全的检查
- 对带参的宏而言,由于是直接替换,并不会检查参数是否合法,也并不会计算求解,存在一定的安全隐患。
宏的其他用法
我们先来创建三个重载函数用以测试
void fun(int a) {
cout << __FUNCSIG__ << " " << a << endl;
}
void fun(const char* p) {
cout << __FUNCSIG__ << " " << p << endl;
}
void fun(char c) {
cout << __FUNCSIG__ << " " << c << endl;
}# 将宏参数转为字符串,相当于加了 双引号
#define D(PARAM) #PARAM
fun(D(123));
fun(D("abc"));![]()
#@ 将宏参数转为字符,相当于加了 单引号
#define E(PARAM) #@PARAM
fun(E(1));
![]()
## 拼接作用,常用于宏参数与其他内容的拼接
#define F(PARAM) int a##PARAM = 100;
F(1)
cout << a1 << endl;inline内联
内联函数是C++为了提高程序的运行速度做的一项改进,普通函数和内联函数主要区别不在于编写方式,而在于C++编译器如何将他们组合到程序中的。编译器将使用相应的函数代码替换到内联函数的调用处,所以程序无需跳转到另一个位置执行函数体代码,所以会比普通的函数稍快,代价是需要占用更多的内存,空间换时间的做法。
执行函数之前需要做一些准备工作i,要将实参、局部变量、返回地址以及若干寄存器都压入栈中,然后才能执行函数体中的代码,代码执行完毕后还要将之前压入栈中的数据都出栈。这个过程涉及到空间和时间的开销问题,如果函数体中的代码比较多,逻辑也比较复杂,那么执行函数体占用大部分时间,而函数调用、释放空间过程花费的时间占比很小可以忽略;如果函数体中的代码非常少,逻辑也非常简单,那么相比于函数体代码的执行时间,函数调用机制所花费的时间就不能忽略了。
int add(int a,int b){
return a+b;
}
int c = add(1,2);所以为了消除函数调用的时间开销,C++提供一种提高效率的方法:inline函数,上例中的add函数可以变为内联函数,如下,内联函数在编译时将函数调用处用函数体替换(类似于宏)。
inline int add(int a, int b) {
return a + b;
}
int c = add(1,2);注意:
- inline是一种空间换时间的做法,内联在一定程度上能提高函数的执行效率,这并不意味着所有函数都要成为内联函数,如果函数调用的开销时间远小于函数体代码执行的时间,那么效率提高的并不多,如果该函数被大量调用时,每一处调用都会复制一份函数体代码,那么将占用更多的内存,得不偿失。所以一般函数体代码比较长,函数体出现内循环(for、while),switch等不应为内联函数。
- 并非我们加上inline关键字,编译器就一定会把它当作内联函数进行替换。定义inline函数只是程序员对编译器提出的一个建议,而不是强制性的,编译器有自己的判断能力,他会根据具体的情况决定是否把它认为是内联函数。编译器不会把虚函数、递归函数视为内联函数。
- 类、结构中在的类内部声明并定义的函数默认为内联函数,如果类中只给出声明,在类外定义的函数,那么默认不是内联函数,除非我们手动加上inline关键字。
class CTest{
void fun1(){} //默认内联
void fun2(); //声明
};
void CTest::fun2(){} //默认不是内联函数CTest tst;
tst.fun1(); //内联替换
tst.fun2(); //未替换void fun1(){
int a =10;
}
void fun2(){
int b= 20;
}
int main(){
fun1();
fun2();
return 0;
}汇编文件如下: