深入理解SeaTunnel:易用、高性能、支持实时流式和离线批处理的海量数据集成平台
- 一、认识SeaTunnel
- 二、SeaTunnel 系统架构、工作流程与特性
- 三、SeaTunnel工作架构
- 四、部署SeaTunnel
- 1.安装Java
- 2.下载SeaTunnel
- 3.安装连接器
- 五、快速启动作业
- 1.添加作业配置文件以定义
- 2.运行 SeaTunnel
- 六、SeaTunnel集成flink
- 1.部署和配置Flink
- 2.添加作业配置文件以定义
- 3.运行SeaTunnel
- 七、SeaTunnel集成Spark
- 1.部署和配置Spark
- 2.添加作业配置文件以定义
- 3.运行SeaTunnel
- 八、运行命令
一、认识SeaTunnel
- SeaTunnel 是一个非常易用、高性能、支持实时流式和离线批处理的海量数据集成平台,架构于 Apache Spark 和 Apache Flink 之上,支持海量数据的实时同步与转换。
SeaTunnel专注于数据集成和数据同步,主要解决数据集成领域的常见问题:
- 数据源多样:常用的数据源有数百种,版本不兼容。随着新技术的出现,出现了更多的数据源。用户很难找到能够全面快速支持这些数据源的工具。
- 复杂同步场景:数据同步需要支持离线-全量同步、离线-增量同步、CDC、实时同步、全库同步等多种同步场景。
- 资源需求高:现有的数据集成和数据同步工具往往需要大量的计算资源或JDBC连接资源来完成海量小表的实时同步。这在一定程度上加重了企业的负担。
- 缺乏质量和监控:数据集成和同步过程经常会丢失或重复数据。同步过程缺乏监控,无法直观了解任务过程中数据的真实情况。
- 技术栈复杂:企业使用的技术组件各不相同,用户需要针对不同的组件开发相应的同步程序来完成数据集成。
- 管理维护困难:受限于不同的底层技术组件(Flink/Spark),离线同步和实时同步往往是分开开发和管理的,增加了管理和维护的难度。
二、SeaTunnel 系统架构、工作流程与特性
SeaTunnel 系统架构图:
- Input/Source[数据源输入] -> Filter/Transform[数据处理] -> Output/Sink[结果输出]

上图为 SeaTunnel 的整个工作流程,数据处理流水线由多个过滤器构成,以满足多种数据处理需求。如果用户习惯了 SQL,也可以直接使用 SQL 构建数据处理管道,更加简单高效。目前,SeaTunnel 支持的过滤器列表也在扩展中。
SeaTunnel的特点:
- 丰富且可扩展的Connector:SeaTunnel提供了不依赖于特定执行引擎的Connector API。基于此API开发的连接器(Source、Transform、Sink)可以运行在很多不同的引擎上,比如目前支持的SeaTunnel Engine、Flink、Spark。
- Connector插件:插件式的设计让用户可以很方便的开发自己的Connector,并集成到SeaTunnel项目中。目前,SeaTunnel 已支持 100 多个 Connector,而且数量还在激增。
- 批流融合:基于SeaTunnel Connector API开发的Connector,完美兼容离线同步、实时同步、全量同步、增量同步等场景。大大降低了管理数据集成任务的难度。
- 支持分布式快照算法,保证数据一致性。
- 多引擎支持:SeaTunnel默认使用SeaTunnel Engine进行数据同步。同时,SeaTunnel也支持使用Flink或Spark作为Connector的执行引擎,以适配企业现有的技术组件。SeaTunnel 支持多个版本的 Spark 和 Flink。
- JDBC多路复用,数据库日志多表解析:SeaTunnel支持多表或全库同步,解决了JDBC连接过多的问题;支持多表或全库日志读取和解析,解决了CDC多表同步场景需要重复读取和解析日志的问题。
- 高吞吐低延迟:SeaTunnel支持并行读写,提供高吞吐低延迟稳定可靠的数据同步能力。
- 完善的实时监控:SeaTunnel支持数据同步过程中每一步的详细监控信息,让用户轻松了解同步任务读写的数据量、数据大小、QPS等信息。
- 支持两种作业开发方式:编码和画布设计:提供了作业的可视化管理、调度、运行和监控能力。
三、SeaTunnel工作架构
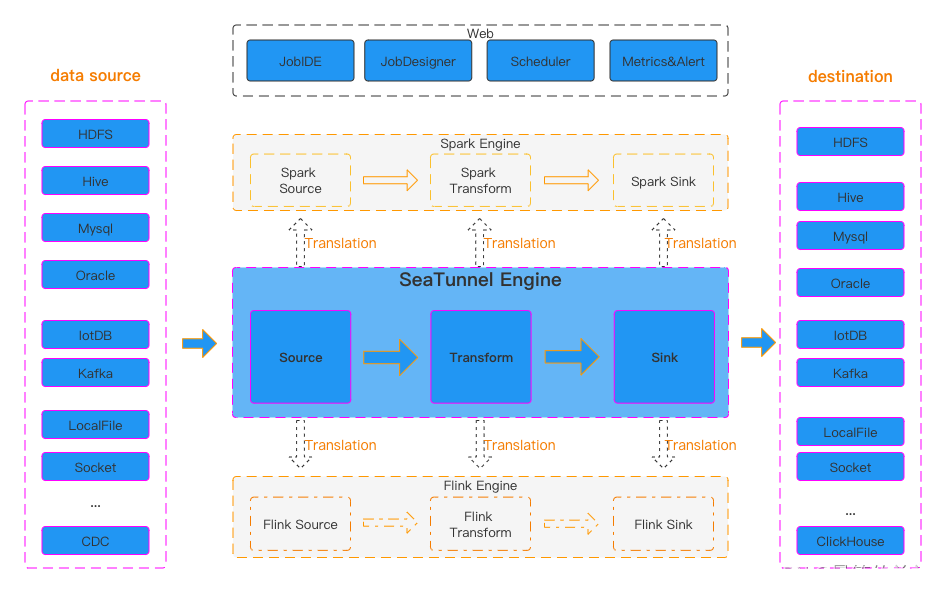
SeaTunnel的运行过程如上图所示。
- 用户配置作业信息,选择执行引擎提交作业。
- Source Connector负责并行读取数据并将数据发送给下游Transform或直接发送给Sink,Sink将数据写入目的地。值得注意的是,无论是Source还是Transform和Sink,都可以很方便的自行开发扩展。
- SeaTunnel 是一个 EL(T) 数据集成平台。因此,在SeaTunnel中,Transform只能用于对数据进行一些简单的转换,例如将某列的数据转换为大写或小写,更改列名,或者将一列拆分为多列。
- SeaTunnel 使用的默认引擎是SeaTunnel Engine。如果您选择使用Flink或Spark引擎,SeaTunnel会将Connector打包成Flink或Spark程序提交给Flink或Spark运行。
- Source Connectors SeaTunnel 支持从各种关系数据库、图形数据库、NoSQL 数据库、文档数据库和内存数据库中读取数据。HDFS等各种分布式文件系统。S3、OSS等多种云存储。同时我们也支持很多常见的SaaS服务的数据读取。
- 转换连接器如果源和接收器之间的架构不同,您可以使用转换连接器更改从源读取的架构,使其与接收器架构相同。
- Sink Connector SeaTunnel 支持向各种关系数据库、图数据库、NoSQL 数据库、文档数据库和内存数据库写入数据。HDFS等各种分布式文件系统。S3、OSS等多种云存储。同时我们也支持向很多常见的SaaS服务写入数据。
四、部署SeaTunnel
1.安装Java
- 安装Java8以上版本
2.下载SeaTunnel
export version="2.3.1"
wget "https://archive.apache.org/dist/incubator/seatunnel/${version}/apache-seatunnel-incubating-${version}-bin.tar.gz"
tar -xzvf "apache-seatunnel-incubating-${version}-bin.tar.gz"
3.安装连接器
从2.2.0-beta开始,二进制包默认不提供connector依赖,所以第一次使用时,我们需要执行如下命令安装connector:(当然你也可以手动下载connector从https://repo.maven.apache.org/maven2/org/apache/seatunnel/下载,然后手动移动到connectors/seatunnel目录)。
sh bin/install-plugin.sh 2.3.1
如果需要指定connector的版本,以2.3.0-beta为例,我们需要执行
sh bin/install-plugin.sh 2.3.1
通常你不需要所有的连接器插件,所以你可以通过配置指定你需要的插件config/plugin_config,比如你只需要connector-console插件,那么你可以修改plugin_config为
--connectors-v2--
connector-console
--end--
如果你想让示例应用程序正常工作,你需要添加以下插件
--connectors-v2--
connector-fake
connector-console
--end--
您可以在${SEATUNNEL_HOME}/connectors/plugins-mapping.properties下找到所有支持的连接器和相应的 plugin_config 配置名称。
提示:
如果想通过手动下载connector的方式安装connector插件,需要特别注意以下几点
connectors目录包含以下子目录,如果不存在,需要手动创建
seatunnel
如果想手动安装V2 connector插件,只需要下载自己需要的V2 connector插件,放到seatunnel目录下即可
五、快速启动作业
1.添加作业配置文件以定义
编辑config/v2.batch.config.template,决定了seatunnel启动后数据输入、处理、输出的方式和逻辑。下面是一个配置文件的例子,和上面提到的例子应用是一样的。
env {
execution.parallelism = 1
job.mode = "BATCH"
}
source {
FakeSource {
result_table_name = "fake"
row.num = 16
schema = {
fields {
name = "string"
age = "int"
}
}
}
}
sink {
Console {}
}
2.运行 SeaTunnel
可以通过以下命令启动应用程序
cd "apache-seatunnel-incubating-${version}"
./bin/seatunnel.sh --config ./config/v2.batch.config.template -e local
查看输出:运行命令时,您可以在控制台中看到它的输出。您可以认为这是命令运行成功与否的标志。
SeaTunnel 控制台会打印一些日志如下:
2022-12-19 11:01:45,417 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - output rowType: name<STRING>, age<INT>
2022-12-19 11:01:46,489 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=1: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: CpiOd, 8520946
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=2: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: eQqTs, 1256802974
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=3: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: UsRgO, 2053193072
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=4: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: jDQJj, 1993016602
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=5: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: rqdKp, 1392682764
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=6: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: wCoWN, 986999925
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=7: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: qomTU, 72775247
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=8: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: jcqXR, 1074529204
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=9: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: AkWIO, 1961723427
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=10: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: hBoib, 929089763
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=11: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: GSvzm, 827085798
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=12: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: NNAYI, 94307133
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=13: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: EexFl, 1823689599
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=14: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: CBXUb, 869582787
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=15: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: Wbxtm, 1469371353
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=16: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: mIJDt, 995616438
六、SeaTunnel集成flink
1.部署和配置Flink
下载Flink,Flink版本要求>=1.12.0
配置 SeaTunnel:更改设置config/seatunnel-env.sh,它基于您的引擎在部署时安装的路径。更改FLINK_HOME为 Flink 部署目录。
2.添加作业配置文件以定义
编辑config/v2.streaming.conf.template,决定了seatunnel启动后数据输入、处理、输出的方式和逻辑。下面是一个配置文件的例子,和上面提到的例子应用是一样的。
env {
execution.parallelism = 1
job.mode = "BATCH"
}
source {
FakeSource {
result_table_name = "fake"
row.num = 16
schema = {
fields {
name = "string"
age = "int"
}
}
}
}
sink {
Console {}
}
3.运行SeaTunnel
flink1.12.x和flink1.14.x
cd "apache-seatunnel-incubating-${version}"
./bin/start-seatunnel-flink-13-connector-v2.sh --config ./config/v2.streaming.conf.template
flink1.15.x和flink1.16.x
cd "apache-seatunnel-incubating-${version}"
./bin/start-seatunnel-flink-15-connector-v2.sh --config ./config/v2.streaming.conf.template
查看输出:运行命令时,您可以在控制台中看到它的输出。您可以认为这是命令运行成功与否的标志。
SeaTunnel 控制台会打印一些日志如下:
2022-12-19 11:01:45,417 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - output rowType: name<STRING>, age<INT>
2022-12-19 11:01:46,489 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=1: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: CpiOd, 8520946
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=2: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: eQqTs, 1256802974
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=3: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: UsRgO, 2053193072
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=4: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: jDQJj, 1993016602
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=5: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: rqdKp, 1392682764
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=6: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: wCoWN, 986999925
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=7: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: qomTU, 72775247
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=8: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: jcqXR, 1074529204
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=9: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: AkWIO, 1961723427
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=10: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: hBoib, 929089763
2022-12-19 11:01:46,490 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=11: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: GSvzm, 827085798
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=12: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: NNAYI, 94307133
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=13: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: EexFl, 1823689599
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=14: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: CBXUb, 869582787
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=15: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: Wbxtm, 1469371353
2022-12-19 11:01:46,491 INFO org.apache.seatunnel.connectors.seatunnel.console.sink.ConsoleSinkWriter - subtaskIndex=0 rowIndex=16: SeaTunnelRow#tableId=-1 SeaTunnelRow#kind=INSERT: mIJDt, 995616438
七、SeaTunnel集成Spark
1.部署和配置Spark
下载Spark(要求版本>=2.4.0)
配置 SeaTunnel:更改设置config/seatunnel-env.sh,它基于您的引擎在部署时安装的路径。更改SPARK_HOME为 Spark 部署目录。
2.添加作业配置文件以定义
编辑config/seatunnel.streaming.conf.template,决定了seatunnel启动后数据输入、处理、输出的方式和逻辑。下面是一个配置文件的例子,和上面提到的例子应用是一样的。
env {
execution.parallelism = 1
job.mode = "BATCH"
}
source {
FakeSource {
result_table_name = "fake"
row.num = 16
schema = {
fields {
name = "string"
age = "int"
}
}
}
}
sink {
Console {}
}
3.运行SeaTunnel
可以通过以下命令启动应用程序
Spark2.4.x
cd "apache-seatunnel-incubating-${version}"
./bin/start-seatunnel-spark-2-connector-v2.sh \
--master local[4] \
--deploy-mode client \
--config ./config/seatunnel.streaming.conf.template
spark3.xx
cd "apache-seatunnel-incubating-${version}"
./bin/start-seatunnel-spark-3-connector-v2.sh \
--master local[4] \
--deploy-mode client \
--config ./config/seatunnel.streaming.conf.template
查看输出:运行命令时,您可以在控制台中看到它的输出。您可以认为这是命令运行成功与否的标志。
SeaTunnel 控制台会打印一些日志如下:
fields : name, age
types : STRING, INT
row=1 : elWaB, 1984352560
row=2 : uAtnp, 762961563
row=3 : TQEIB, 2042675010
row=4 : DcFjo, 593971283
row=5 : SenEb, 2099913608
row=6 : DHjkg, 1928005856
row=7 : eScCM, 526029657
row=8 : sgOeE, 600878991
row=9 : gwdvw, 1951126920
row=10 : nSiKE, 488708928
row=11 : xubpl, 1420202810
row=12 : rHZqb, 331185742
row=13 : rciGD, 1112878259
row=14 : qLhdI, 1457046294
row=15 : ZTkRx, 1240668386
row=16 : SGZCr, 94186144
八、运行命令
Spark2:
bin/start-seatunnel-spark-2-connector-v2.sh --config config/v2.batch.config.template -m local -e client
Spark3:
bin/start-seatunnel-spark-3-connector-v2.sh --config config/v2.batch.config.template -m local -e client
Flink13和Flink14:
bin/start-seatunnel-flink-13-connector-v2.sh --config config/v2.batch.config.template
Flink15和Flink16:
bin/start-seatunnel-flink-15-connector-v2.sh --config config/v2.batch.config.template




![[MAUI]模仿iOS多任务切换卡片滑动的交互实现](https://img-blog.csdnimg.cn/6fca7de1f85646dc894e72f43390f317.gif)