1.简介
作用:将结构化数据映射为一张表,并提供类sql功能
本质:将HQL转化成MapReduce程序
(1)Hive处理的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce
(3)执行程序运行在Yarn上
ps. HDFS 不支持随机写,只支持追加写,所以在 Hive 中不能 update 和delete,能 select 和 insert
与数据库对比: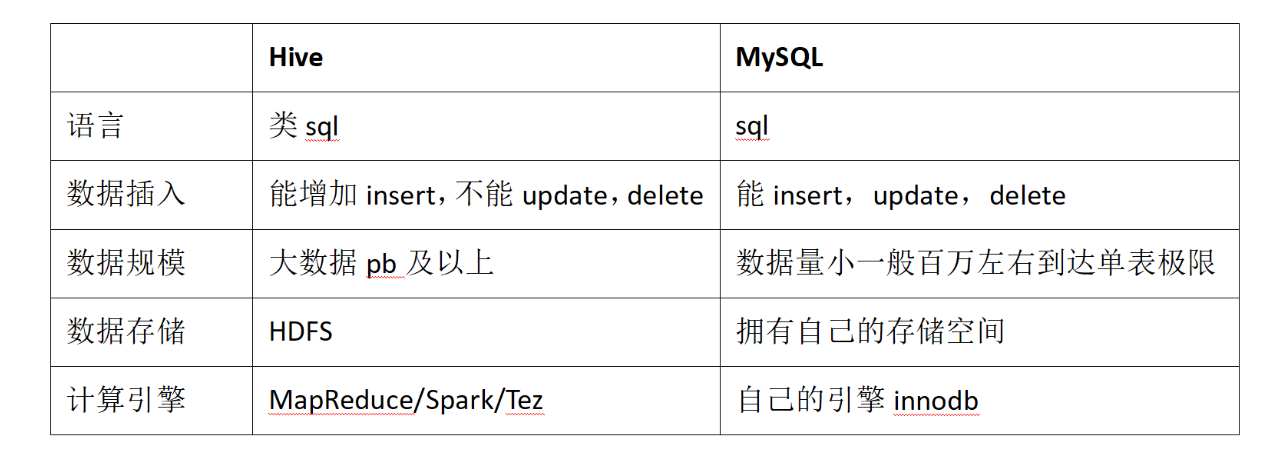
2.启动mysql
// 启动mysql
sudo systemctl start mysqld
// 登录mysql
mysql -uroot -p
// 退出mysql
exit3.启动hive
3..1 前提准备:
// 先启动hadoop集群
my_hadoop start
hive的底层是基于hadoop的
3.2 1 直接启动hive
[atguigu@hadoop101 ~]$ hivehive> exit;
ps.开启方式简单,但是查询数据输出不规整
3.2.2 通过jdbc启动hive
[atguigu@hadoop102 hive]$
bin/beeline -u jdbc:hive2://hadoop101:10000 -n atguigujdbc:hive2://hadoop101:10000> !quitps.开启方式复杂,但是返回的数据很规整
3.3.3 通过脚本启动hive
[atguigu@hadoop101 bin]$ hiveservices.sh start | stop | restart| status
ps.配置脚本的过程比较麻烦,还是了解一下即可
4.数据类型
4.1 基本数据类型
| Hive | mysql | JAVA | length | 示例 |
|---|---|---|---|---|
| TINYINT | TINYINT | byte | 1byte有符号整数 | 2 |
| SMALINT | SMALINT | short | 2byte有符号整数 | 20 |
| INT | INT | int | 4byte有符号整数 | 20 |
| BIGINT | BIGINT | long | 8byte有符号整数 | 20 |
| BOOLEAN | 无 | boolean | 布尔类型,true或者false | TRUE FALSE |
| FLOAT | FLOAT | float | 单精度浮点数 | 3.14159 |
| DOUBLE | DOUBLE | double | 双精度浮点数 | 3.14159 |
| STRING | VARCHAR | string | 字符系列。可以指定字符集。可以使用单引号或者双引号。 | ‘now is the time’“ |
| TIMESTAMP | TIMESTAMP | 时间类型 | '2013-01-31 00:13:00.345’ | |
| BINARY | BINARY | 字节数组 | 1010 |
ps.红标为常用的数据类型;
ps.对于Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串.
4.2 集合数据类型
| 数据类型 | 示例 | 描述 |
|---|---|---|
| STRUCT | 例如,如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第1个元素可以通过字段.first来引用。 | 例如:struct<street:string, city:string> |
| MAP | 例如,如果某个列的数据类型是MAP,其中键->值对是’first’->’John’和’last’->’Doe’,那么可以通过字段名[‘last’]获取最后一个元素 | 例如map<string, int> |
| ARRAY | 例如,数组值为[‘John’, ‘Doe’],那么第2个元素可以通过
| 例如array<string> |
例子:
1.hive下方有一个datas目录,在其中vim test.txt:
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijingps.每一行的数据都包含了四种类型,分别是string,array,map,struct
2. 在hive上创建表
create table test(
name string,
friends array<string>,
children map<string, int>,
address struct<street:string, city:string>
)3.数据分割(按照数据决定)
row format delimited fields terminated by ',' // 让每个字段按逗号分开
collection items terminated by '_' // 集合(MAP STRUCT和ARRAY)的分隔符
map keys terminated by ':' // MAP中的key与value的分隔符
lines terminated by '\n'; // 行分隔符(可以判断出是两行)4.导入文本数据到测试表
load data local inpath '/opt/module/hive/datas/test.txt' into table test;5.访问数据
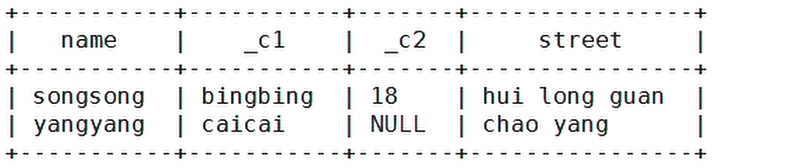
hive (default)> select name,friends[1],children['xiao song'],address.city
from test where name="songsong";
查询结果:
4.3 类型转换
1.规则:
(1)隐式转换
任何整数类型都可以隐式地转换为一个范围更广的类型。
如TINYINT可以转换成INT,INT可以转换成BIGINT。
所有整数类型、FLOAT和.STRING类型的数字.都可以隐式地转换成DOUBLE。
TINYINT、SMALLINT、INT都可以转换为FLOAT。
BOOLEAN类型不可以转换为任何其它的类型。
(2)强制转换
使用CAST操作。例如CAST(‘1’ as int)将把字符串’1’ 转换成整数1
2.示例
hive (default)> select '1' + 2, cast('1' as int) + 2;
_c0 _c1
3.0 3