前言
小亭子正在努力的学习编程,接下来将开启javaEE的学习~~
分享的文章都是学习的笔记和感悟,如有不妥之处希望大佬们批评指正~~
同时如果本文对你有帮助的话,烦请点赞关注支持一波, 感激不尽~~
目录
数据库基础知识
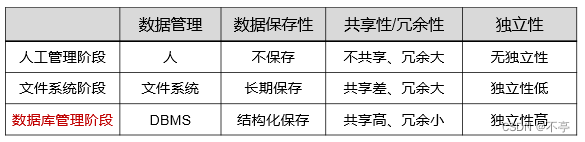
数据,数据库,数据库管理系统,数据库系统
数据库的发展阶段
数据库系统的结构
数据模型
一、概念模型
逻辑结构
关系模型
关系代数
数据库的分类
配置初始化文件
常用的dos代码
注意:
SQL分类
表设计
一对一
一对多
多对多
常用数据类型
数值类型
字符串类型
日期类型
数据库的操作
显示当前数据库
语法:
创建数据库
语法:
说明:
示例:
使用数据库
语法:
删除数据库
语法:
说明:
示例:
表的操作
使用数据库
查看表结构
创建表
删除表
表的增删改查(CRUD)
CRUD
新增数据
语法:
示例:
单行数据 +全列插入
多行数据+指定列插入
查询数据
全列查询
指定列查询
查询字段为表达式
设置别名
去重查询
排序查询
where条件查询
分页查询
聚合函数查询
GROUP BY子句
HAVING 子句
联合查询
修改数据
语法
示例
删除数据
语法
示例
数据库约束
索引
事务
数据库基础知识
数据,数据库,数据库管理系统,数据库系统

数据库的发展阶段
数据库系统的结构
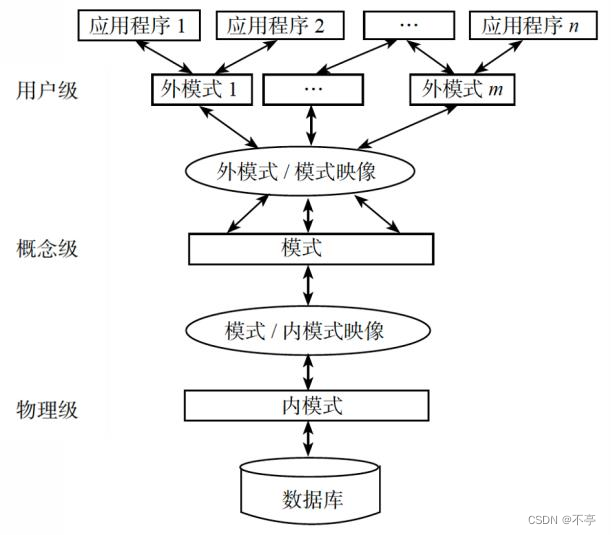
三级结构

数据库系统的二级映像
1.外模式/模式映像:保证逻辑独立性
2.模式/内模式映像:保证物理独立性
数据模型
一、概念模型
1.相关术语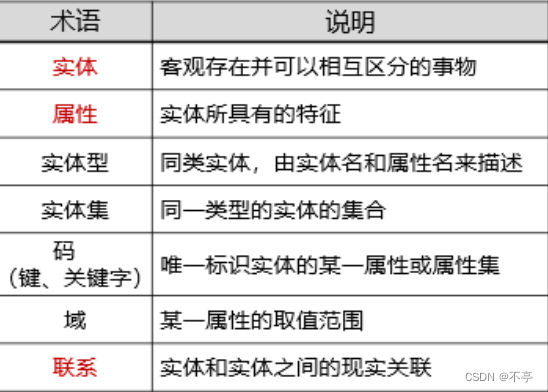
2.实体型之间的联系
1.一对一联系(1:1)
两个方向都是 1:1
例:班级和班主任
2.一对多联系(1:n)
一个方向是 1:1,另一个方向是 1:n
例:学生和班主任
3.多对多联系(m:n)
两个方向都是 1:n
例:学生和课程
3.E-R 图
矩形表示实体;椭圆表示属性;菱形表示联系;无向边;联系类型
例:①班级和班主任;②学生和班主任;③学生和课程

逻辑结构
1.结构
树型结构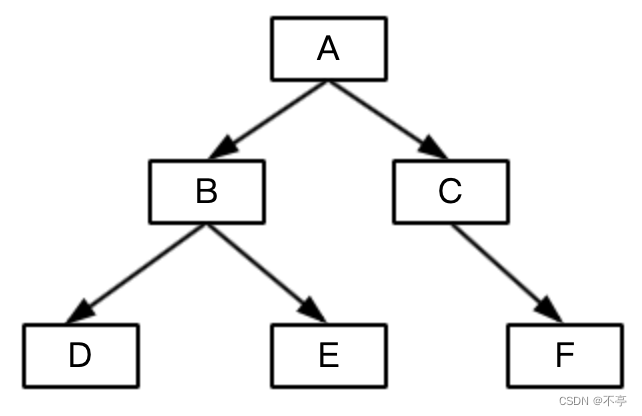
2.特点
(1)一个模型有且只有一个节点没有双亲节点,这个节点称为根节点
(2)根节点以外的其他节点有且只有一个双亲节点
(3)父子节点之间的联系是一对多联系(1∶ n)
网型结构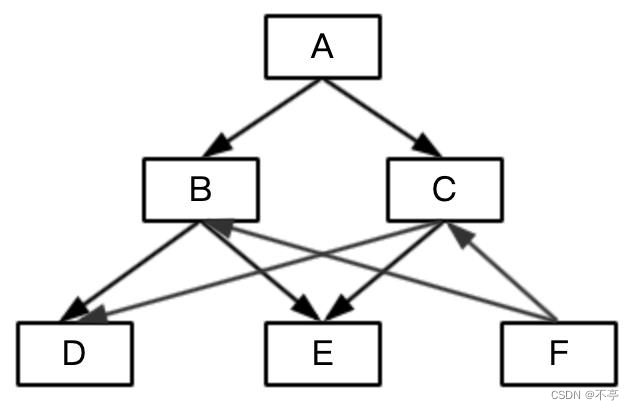
2.特点
(1)允许一个以上的节点没有双亲节点
(2)允许一个节点有多个双亲节点
(3)节点之间存在多种联系(m:n)
关系模型
(一)基本概念
1.关系:二维表
2.属性:列、字段;元数
3.域:值域
4.元组:行、记录
5.分量:属性值
如,(01001,赵乾,女,讲师,计算机, 6000)中“01001”为一个分量
6.关系模式:二维表结构
如, T(TNo, TN, Sex, Prof, Dept, Sal)

(二)关系的性质
1.每一列是同质的
2.不同列有不同的名字
3.列的顺序可以任意交换
4.行的顺序可任意交换
5.不允许出现完全一样的行
6.不允许出现合并单元格
(三)关系模型的完整性约束
有 3 类:实体完整性、参照完整性、用户定义完整性
(一)关系的码
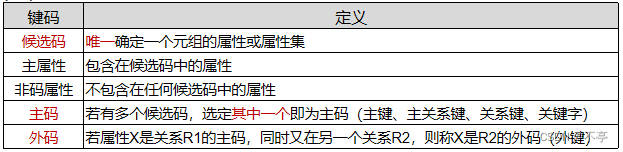
(二)实体完整性
原则:①有主码(不空)②不同元组的主码不重复
(三)参照完整性
原则: R2 表的外键 X 的取值,参照 R1 表的主键值
(四)用户自定义完整性
原则:事先定义值域
关系代数
一) 传统的集合运算
1.并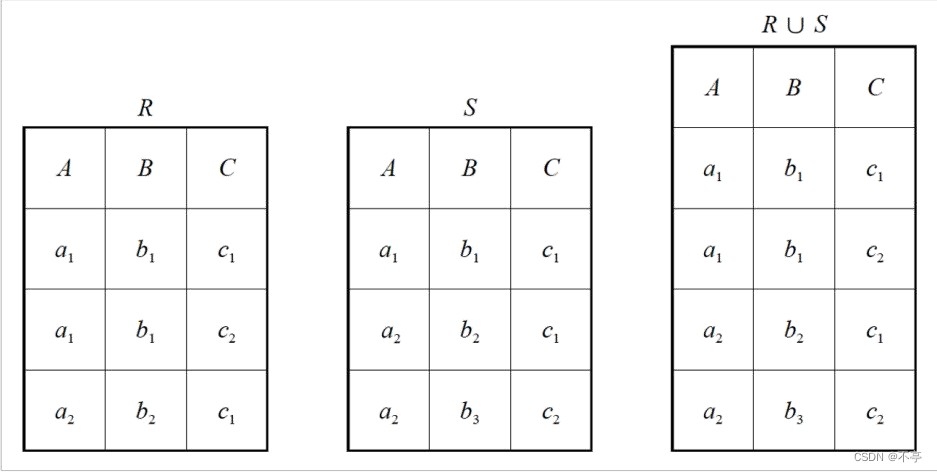
2 .差

3.交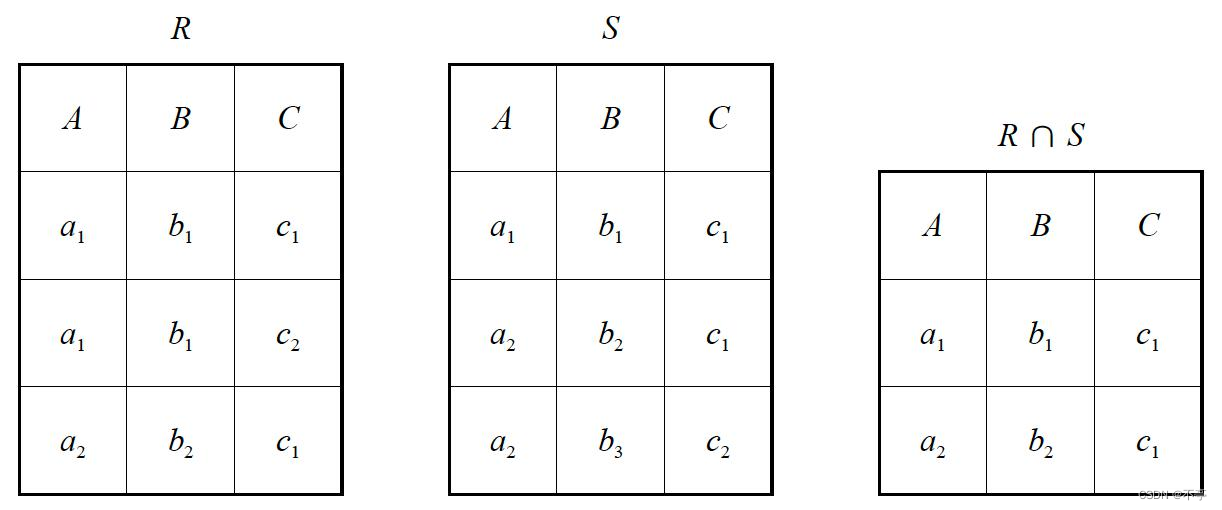
4.广义笛卡尔积

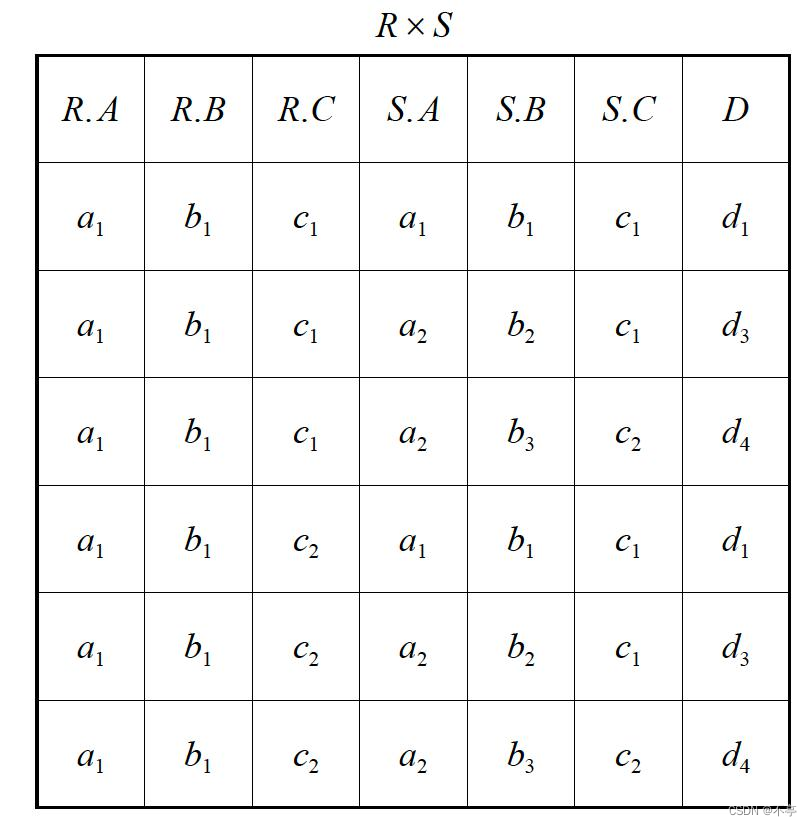
二) 专门的代数运算

1.选择 【根据条件得到行】
选择条件:性别 女
结果:

2.投影 【 根据条件得到列】
投影条件:姓名,系别
投影结果:
3.连接
连接运算是二目运算, 它从两个关系的广义笛卡儿积中选取满足连接条件的
元组, 组成新的关系。
( 1) 等值连接
规则: ①结果(字段-两个关系的字段和) (记录-等值属性值相等, 拼左右)
( 2) 自然连接
规则: ①两表有相同的属性②结果( 字段-相同属性列只保留一列) ( 记录-
相同属性做等值连接)
4.除
具体算法可以看这篇http://t.csdn.cn/D4vj3
数据库的分类
数据库分为关系型数据库和非关系型数据库
| 关系型数据库 | 非关系型数据库 | |
| 使用SQL | 是 | 不强制要求,一般不基于SQL实现 |
| 事务支持 | 支持 | 不支持 |
| 复杂操作 | 支持 | 不支持 |
| 海量读写操作 | 效率低 | 效率高 |
| 基本结构 | 基于表和列,结构固定 | 灵活性比较高 |
| 使用场景 | 业务方面的OLTP系统 | 用于数据的缓存、或基于统计分析的OLAP系统 |
配置初始化文件
1. 在MySQL根目录下创建初始化文件my.ini,即D:\Tools\mysql-5.7.27-winx64\my.ini。内容
如下:
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
#设置3306端口
port=3306
# 设置mysql的安装目录
basedir=D:/Tools/mysql-5.7.27-winx64
# 设置mysql数据库的数据的存放目录
datadir=D:/Tools/mysql-5.7.27-winx64/data
# 允许最大连接数
max_connections=200
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=innodb2. 将以上 basedir 和 datadir 后的内容替换成自己的路径。
3. 注意:需要保存为ANSI编码。方法一:使用记事本打开,保存/另
法二:使用Notpad++打开,点击编码->转为ANSI编码->保存。
常用的dos代码
--连接服务器
mysql -u root -p
要求输入密码,没有设置密码则直接回车
进入MySQL命令行以后,可以看到 mysql>
-- 使用mysql数据库
use mysql;
-- 更新用户表的root账户,设置为任意ip都可以访问,密码修改为123456
update user set host="%",authentication_string=password('root') where
user="root";
-- 刷新权限
flush privileges;
--退出quit;
注意:
- 注释的写法 在前面加 --
- sql语句不区分大小写,写大写和小写都行
SQL分类
DDL数据定义语言,用来维护存储数据的结构
代表指令: create, drop, alter
DML数据操纵语言,用来对数据进行操作
代表指令: insert,delete,update
DML中又单独分了一个DQL,数据查询语言,代表指令: select
DCL数据控制语言,主要负责权限管理和事务
代表指令: grant,revoke,commit
表设计
一对一
一对多

多对多

常用数据类型
数值类型
分为整型和浮点型
| 数据类型 | 大小 | 说明 | 对应java类型 |
| BIT[ (M) ] | M指定位数,默认为1 | 二进制数,M范围从1到64, 存储数值范围从0到2^M-1 | 常用Boolean对应BIT,此时默认是1位,即只能存0和1 |
| TINYINT | 1字节 | Byte | |
| SMALLINT | 2字节 | Short | |
| INT | 4字节 | Integer | |
| BIGINT | 8字节 | Long | |
| FLOAT(M, D) | 4字节 | 单精度,M指定长度,D指定小数位数。会发生精度丢失 | Float |
| DOUBLE(M,D) | 8字节 | Double | |
| DECIMAL(M,D) | M/D最大值+2 | 双精度,M指定长度,D表示小数点位数。精确数值 | BigDecimal |
| NUMERIC(M,D) | M/D最大值+2 | 和DECIMAL一样 | BigDecimal |
补充:
- 数值类型可以指定为无符号(unsigned),表示不取负数
- 1字节(bytes)= 8bit。
- 对于整型类型的范围:
1. 有符号范围:-2^(类型字节数*8-1)到2^(类型字节数*8-1)-1,如int是4字节,是-2^31到2^31-1
2. 无符号范围:0到2^(类型字节数*8)-1,如int就是2^32-1
尽量不使用unsigned,对于int类型可能存放不下的数据,int unsigned同样可能存放不下,与其如此,还不如设计时,将int类型提升为bigint类型
字符串类型
| 数据类型 | 大小 | 说明 | 对应java类型 |
| VARCHAR (SIZE) | 0-65,535字节 | 可变长度字符串 | String |
| TEXT | 0-65,535字节 | 长文本数据 | String |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 | String |
| BLOB | 0-65,535字节 | 二进制形式的长文本数据 | byte[] |
说明:varchar 可变长度是指 假设 设置了1000个字符的大小,实际占用了100个,那么就只开辟100个空间。不可变长度就是设置了1000,空间占用就是1000,没用上的就空着但是还是占用了。
日期类型
| 数据类型 | 大 小 | 说明 | 对应java类型 |
| DATETIME | 8 字 节 | 范围从1000到9999年,不会进行时区的 检索及转换。 | java.util.Date、 java.sql.Timestamp |
| TIMESTAMP | 4 字 节 | 范围从1970到2038年,自动检索当前时 区并进行转换。 | java.util.Date、 java.sql.Timestamp |
补充:时间戳默认1970年1月1日,(时间纪元)有兴趣的自行百度。
数据库的操作
显示当前数据库
语法:
show databases
创建数据库
语法:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,
create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name
说明:
- 大写的表示关键字
- [] 是可选项
- CHARACTER SET: 指定数据库采用的字符集
- COLLATE: 指定数据库字符集的校验规则
示例:
1.创建名为db_test1 的数据库
CREATE DATABASE db_test1
2.如果系统没有 db_test2 的数据库,则创建一个名叫 db_test2 的数据库,如果有则不创建
CREATE DATABASE IF NOT EXISTS db_test2
3.如果系统没有 db_test 的数据库,则创建一个使用utf8mb4字符集的 db_test 数据库,如果有则不创建
CREATE DATABASE IF NOT EXISTS db_test CHARACTER SET utf8mb4;
使用数据库
语法:
use 数据库名
删除数据库
语法:
DROP DATABASE [IF EXISTS] db_name
说明:
数据库删除以后,内部看不到对应的数据库,里边的表和数据全部被删除
示例:
drop database if exists db_test1
drop database if exists db_test2
表的操作
-- 显示
show databases;
-- 创建
create database xxx;
-- 使用
use xxx;
-- 删除
drop database xxx;
使用数据库
操作表之前需要先使用该数据库
user 数据库名
查看表结构
desc 表名
示例+说明

创建表
语法
CREATE TABLE table_name (
field1 datatype,
field2 datatype,
field3 datatype
);
示例
create table stu_test (
id int,
name varchar(20) comment '姓名',
password varchar(50) comment '密码',
age int,
sex varchar(1),
birthday timestamp,
amout decimal(13,2),
resume text
);
删除表
语法
DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name] ...
示例
-- 删除 stu_test 表
drop table stu_test;
-- 如果存在 stu_test 表,则删除 stu_test 表
drop table if exists stu_test;
表的增删改查(CRUD)
CRUD
CRUD 即增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)四个单词的首字母缩写
新增数据
语法:
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...
value_list: value, [, value] ...
示例:
-- 创建一张学生表
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT,
sn INT comment '学号',
name VARCHAR(20) comment '姓名',
qq_mail VARCHAR(20) comment 'QQ邮箱'
);
单行数据 +全列插入
-- 插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
INSERT INTO student VALUES (100, 10000, '唐三藏', NULL);
INSERT INTO student VALUES (101, 10001, '孙悟空', '11111');
多行数据+指定列插入
-- 插入两条记录,value_list 数量必须和指定列数量及顺序一致
INSERT INTO student (id, sn, name) VALUES
(102, 20001, '曹孟德'),
(103, 20002, '孙仲谋');
查询数据
语法
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...
全列查询
--通常情况下 使用 * 进行全列查询
SELECT * FROM exam_result;
指定列查询
--指定列的顺序不需要按定义表的顺序来
SELECT id ,name FROM exam_result;
查询字段为表达式
-- 表达式不包含字段
SELECT id, name, 10 FROM exam_result;
-- 表达式包含一个字段
SELECT id, name, english + 10 FROM exam_result;
-- 表达式包含多个字段
SELECT id, name, chinese + math + english FROM exam_result;
设置别名
为查询结果中的列指定别名,表示返回的结果集中,以别名作为该列的名称
SELECT column [AS] alias_name [...] FROM table_name;
示例:
-- 结果集中,表头的列名=别名
SELECT id, name, chinese + math + english 总分 FROM exam_result;
去重查询
使用DISTINCT关键字对某列数据进行去重
示例:
SELECT DISTINCT math FROM exam_result;
排序查询
- ASC 为升序(从小到大)
- DESC 为降序(从大到小)
- 默认为 ASC
- null数据在排序中,视为最小的值
- 排序条件可以是表达式或者子查询
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];
示例:
-- 查询同学及总分,由高到低
SELECT name, chinese + english + math FROM exam_result
ORDER BY chinese + english + math DESC;
SELECT name, chinese + english + math total FROM exam_result
ORDER BY total DESC;
总结
-- 全列查询
select * from 表
-- 指定列查询
select 字段1,字段2... from 表
-- 查询表达式字段
select 字段1+100,字段2+字段3 from 表
-- 别名
select 字段1 别名1, 字段2 别名2 from 表
-- 去重DISTINCT
select distinct 字段 from 表
-- 排序ORDER BY
select * from 表 order by 排序字段
-- 条件查询WHERE:
-- (1)比较运算符 (2)BETWEEN ... AND ... (3)IN (4)IS NULL (5)LIKE (6)AND (7)OR
(8)NOT
select * from 表 where 条件
where条件查询
比较运算符
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, ...) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字 符 |
逻辑运算符
| 运算符 | 说明 |
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
注意:
1. WHERE条件可以使用表达式,但不能使用别名。
2. AND的优先级高于OR,在同时使用时,需要使用小括号()包裹优先执行的部分
分页查询
用limit关键字
语法:
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
示例:
按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页
--第 1 页
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3
OFFSET 0;
-- 第 2 页
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3
OFFSET 3;
-- 第 3 页,如果结果不足 3 个,不会有影响
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3
OFFSET 6;
示例:
--统计数学成绩总分
ELECT SUM(math) FROM exam_result;
-- 不及格 < 60 的总分,没有结果,返回 NULL
SELECT SUM(math) FROM exam_result WHERE math < 60;
聚合函数查询
聚合函数
常见的统计总数、计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
GROUP BY子句
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:
使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中
select column1, sum(column2), .. from table group by column1,column3;
示例:
准备测试的素材
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
role varchar(20) not null,
salary numeric(11,2)
);
insert into emp(name, role, salary) values
('马云','服务员', 1000.20),
('马化腾','游戏陪玩', 2000.99),
('孙悟空','游戏角色', 999.11),
('猪无能','游戏角色', 333.5),
('沙和尚','游戏角色', 700.33),
('隔壁老王','董事长', 12000.66);查询示例
查询每个角色的最高工资、最低工资和平均工资
select role,max(salary),min(salary),avg(salary) from emp group by role;
HAVING 子句
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用
HAVING
示例:
显示平均工资低于1500的角色和它的平均工资
select role,max(salary),min(salary),avg(salary) from emp group by role
having avg(salary)<1500;
联合查询
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积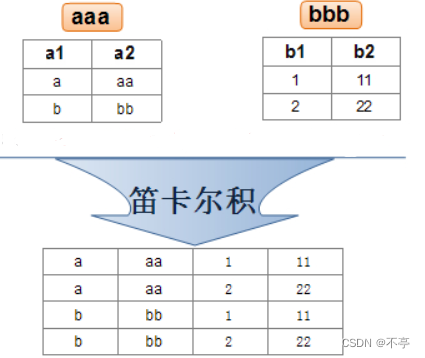
准备的测试数据
insert into classes(name, `desc`) values
('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'),
('中文系2019级3班','学习了中国传统文学'),
('自动化2019级5班','学习了机械自动化');
insert into student(sn, name, qq_mail, classes_id) values
('09982','黑旋风李逵','xuanfeng@qq.com',1),
('00835','菩提老祖',null,1),
('00391','白素贞',null,1),
('00031','许仙','xuxian@qq.com',1),
('00054','不想毕业',null,1),
('51234','好好说话','say@qq.com',2),
('83223','tellme',null,2),
('09527','老外学中文','foreigner@qq.com',2);
insert into course(name) values
('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文');
insert into score(score, student_id, course_id) values
-- 黑旋风李逵
(70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
-- 菩提老祖
(60, 2, 1),(59.5, 2, 5),
-- 白素贞
(33, 3, 1),(68, 3, 3),(99, 3, 5),
-- 许仙
(67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
-- 不想毕业
(81, 5, 1),(37, 5, 5),-- 好好说话
(56, 6, 2),(43, 6, 4),(79, 6, 6),
-- tellme
(80, 7, 2),(92, 7, 6);
内连接
语法
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
示例
查询所有同学的总成绩,及同学的个人信息
-- 成绩表对学生表是多对1关系,查询总成绩是根据成绩表的同学id来进行分组的
SELECT
stu.sn,
stu.NAME,
stu.qq_mail,
sum( sco.score )
FROM
student stu
JOIN score sco ON stu.id = sco.student_id
GROUP BY
sco.student_id;
外连接
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接
语法
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
示例
查询所有同学的成绩,及同学的个人信息,如果该同学没有成绩,也需要显示
- “老外学中文”同学 没有考试成绩,也显示出来了
select * from student stu left join score sco on stu.id=sco.student_id;
-- 对应的右外连接为:
select * from score sco right join student stu on stu.id=sco.student_id;
-- 学生表、成绩表、课程表3张表关联查询
SELECT
stu.id,
stu.sn,
stu.NAME,
stu.qq_mail,
sco.score,
sco.course_id,
cou.NAME
FROM
student stu
LEFT JOIN score sco ON stu.id = sco.student_id
LEFT JOIN course cou ON sco.course_id = cou.id
ORDER BY
stu.id;
自连接
自连接是指在同一张表连接自身进行查询。
示例:
显示所有“计算机原理”成绩比“Java”成绩高的成绩信息
SELECT
stu.*,
s1.score Java,
s2.score 计算机原理
FROM
score s1
JOIN score s2 ON s1.student_id = s2.student_id
JOIN student stu ON s1.student_id = stu.id
JOIN course c1 ON s1.course_id = c1.id
JOIN course c2 ON s2.course_id = c2.id
AND s1.score < s2.score
AND c1.NAME = 'Java'
AND c2.NAME = '计算机原理';拆分上述语句得到一下的分布执行的语句
--先查询“计算机原理”和“Java”课程的id
select id,name from course where name='Java' or name='计算机原理';
-- 再查询成绩表中,“计算机原理”成绩比“Java”成绩 好的信息
SELECT
s1.*
FROM
score s1,
score s2
WHERE
s1.student_id = s2.student_idAND s1.score < s2.score
AND s1.course_id = 1
AND s2.course_id = 3;
-- 也可以使用join on 语句来进行自连接查询
SELECT
s1.*
FROM
score s1
JOIN score s2 ON s1.student_id = s2.student_id
AND s1.score < s2.score
AND s1.course_id = 1
AND s2.course_id = 3;
子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
单行子查询:返回一行记录的子查询
-- 单行子查询
select ... from 表1 where 字段1 = (select ... from ...);
示例
查询与“不想毕业” 同学的同班同学
select * from student where classes_id=(select classes_id from student where
name='不想毕业');
多行子查询:返回多行记录的子查询
-- [NOT] IN
select ... from 表1 where 字段1 in (select ... from ...);
-- [NOT] EXISTS
select ... from 表1 where exists (select ... from ... where 条件);
-- 临时表:form子句中的子查询
select ... from 表1, (select ... from ...) as tmp where 条件
示例
案例:查询“语文”或“英文”课程的成绩信息
. [NOT] IN关键字
--使用INselect * from score where course_id in (select id from course where
name='语文' or name='英文');
-- 使用 NOT IN
select * from score where course_id not in (select id from course where
name!='语文' and name!='英文');
可以使用多列包含:
-- 插入重复的分数:score, student_id, course_id列重复
insert into score(score, student_id, course_id) values
-- 黑旋风李逵
(70.5, 1, 1),(98.5, 1, 3),
-- 菩提老祖
(60, 2, 1);
-- 查询重复的分数
SELECT
*
FROM
score
WHERE
( score, student_id, course_id ) IN ( SELECT score, student_id,
course_id FROM score GROUP BY score, student_id, course_id HAVING
count( 0 ) > 1 );
[NOT] EXISTS关键字-- 使用 EXISTS
select * from score sco where exists (select sco.id from course cou
where (name='语文' or name='英文') and cou.id = sco.course_id);
-- 使用 NOT EXISTS
select * from score sco where not exists (select sco.id from course cou
where (name!='语文' and name!='英文') and cou.id = sco.course_id);
在from子句中使用子查询:子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用。
查询所有比“中文系2019级3班”平均分高的成绩信息
-- 获取“中文系2019级3班”的平均分,将其看作临时表
SELECT
avg( sco.score ) score
FROM
score sco
JOIN student stu ON sco.student_id = stu.id
JOIN classes cls ON stu.classes_id = cls.id
WHERE
cls.NAME = '中文系2019级3班';
查询成绩表中,比以上临时表平均分高的成绩
SELECT
*
FROM
score sco,
(
SELECT
avg( sco.score ) score
FROM
score sco
JOIN student stu ON sco.student_id = stu.id
JOIN classes cls ON stu.classes_id = cls.id
WHERE
cls.NAME = '中文系2019级3班'
) tmp
WHERE
sco.score > tmp.score;
合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用
-- UNION:去除重复数据(操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。)
select ... from ... where 条件
union
select ... from ... where 条件
-- UNION ALL:不去重(该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行)
select ... from ... where 条件
union all
select ... from ... where 条件
-- 使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致
示例
UNION
和UNION ALL时,前后查询的结果集中,字段需要一致
案例:查询id小于3,或者名字为“英文”的课程:
select * from course where id<3
union
select * from course where name='英文';
-- 或者使用or来实现
select * from course where id<3 or name='英文';union all
案例:查询id小于3,或者名字为“Java”的课程
-- 可以看到结果集中出现重复数据Java
select * from course where id<3
union all
select * from course where name='英文';
修改数据
语法
update 表 set 字段1=value1, 字段2=value2... where 条
示例
-- 将孙悟空同学的数学成绩变更为 80 分
UPDATE exam_result SET math = 80 WHERE name = '孙悟空';
-- 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
UPDATE exam_result SET math = 60, chinese = 70 WHERE name = '曹孟德';
-- 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
UPDATE exam_result SET math = math + 30 ORDER BY chinese + math + english LIMIT
3;
-- 将所有同学的语文成绩更新为原来的 2 倍
UPDATE exam_result SET chinese = chinese * 2;
删除数据
语法
delete from 表 where 条件
示例
-- 删除孙悟空同学的考试成绩
DELETE FROM exam_result WHERE name = '孙悟空';
-- 删除整张表数据
-- 准备测试表
DROP TABLE IF EXISTS for_delete;
CREATE TABLE for_delete (
id INT,
name VARCHAR(20)
);
-- 插入测试数据
INSERT INTO for_delete (name) VALUES ('A'), ('B'), ('C');
-- 删除整表数据
DELETE FROM for_delete;
数据库约束
- NOT NULL - 指示某列不能为空
- UNIQUE - 保证某列的每行必须有唯一,不重复的。
- DEFAULT - 规定没有给列赋值时的默认值。
- PRIMARY KEY - 主键约束,与 NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY - 外键约束,保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句。
索引
索引,相当于目录,它是一种特殊的文件包含着对数据表里所有记录的引用指针。可以帮助我们快速定位,检索数据。
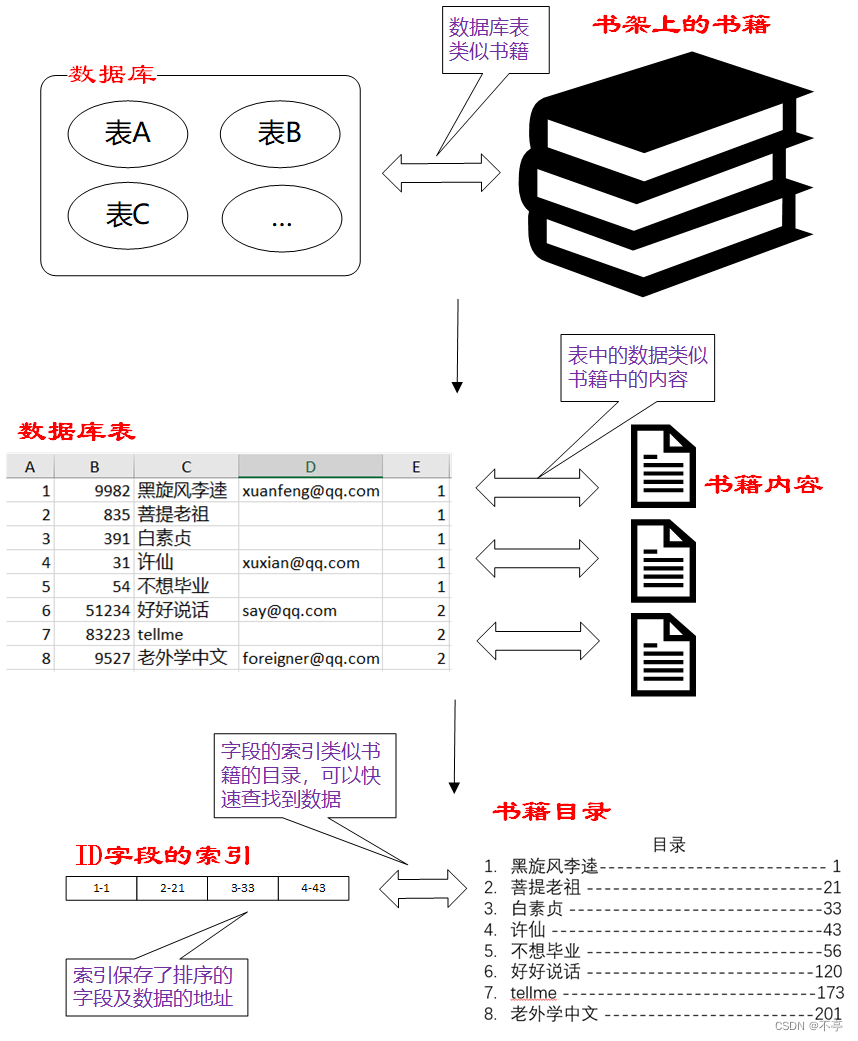
注意:创建索引会占用额外的磁盘空间,插入火绒修改操作效率不高,通常建议使用在需要大量进行查询的场合。
使用方法:
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。
查看索引
show index from 表名;
示例:
查看学生表已有的索引
show index from student;
创建索引
对于非主键、非唯一约束、非外键的字段,可以创建普通索引
create index 索引名 on 表名(字段名);
示例
创建班级表中,name字段的索引
create index idx_classes_name on classes(name);
删除索引
drop index 索引名 on 表名;
示例
删除班级表中name字段的索引
drop index idx_classes_name on classes;
事务
试想一下,当你妈妈给你打生活费的时候,她给你转账但是数据库挂掉了,那边显示转账成功了,金额减少了2000,但是你的账户并没有增加2000。这个时候是不是就很难受,那么这个问题该怎么解决呢?
那就让这里两个操作要么同时成功,要么同时失败。这就是事务的逻辑。
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。
使用
- (1)开启事务:start transaction;
- (2)执行多条SQL语句
- (3)回滚或提交:rollback/commit;
说明:rollback即是全部失败,commit即是全部成功。
示例:
start transaction;
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
commit;
【以上就是本文分享的全部内容,下一篇JDBC编程,敬请期待~~】