文章目录
- 前言
- 架构
- SpringCloud服务构建
- 后台搭建
- Python服务调用
- Python算法服务
- app
- 总结
前言
趁着五一有时间,先把大三下个学期的期末作业做了,把微信小程序和Java开发的一起做了。顺便把机器学习的也一起做了。所以的话,我们完整项目的技术体系主要有 微信小程序开发,Java Web开发(因为我喜欢把admin后台管理和用户端服务分开,所有我选择SpringCloud做一个切分,实际上就是两个服务+网关),然后是基于Pytorch的NLP对话机器人,那么关于对话机器人的话,这个没办法,只能继续用先前GPT2的那个,没办法,有几个效果不错的,但是嘛,跑不动,当然也可以直接那啥,但是吧有一定的风险,能跑就行了,架子搭起来,上面都好说。
同样的,文章分为上下两篇,后端与前端部分,其实也没办法,一天没写完,中间准备会议录屏去了。中间还遇到了Python的一个bug,查了小半天的issue。
整个项目的设计非常简单,也没有做什么复杂的东西,dome而已,没必要那么复杂,也不见得那些老师可以看懂,没必要把自己搞得那么累,能花500搞定绝不花1000精力搞定。
所以,整个项目是很简单的,不过涉及到的东西不少,所以问题在你对于上面提到的技术熟不熟悉。
架构
ok,这里我们可以先看到我们整个项目的基本架构。由于这里没有涉及到部署,所以这里的话,我就不画那些花里胡哨的东西了。
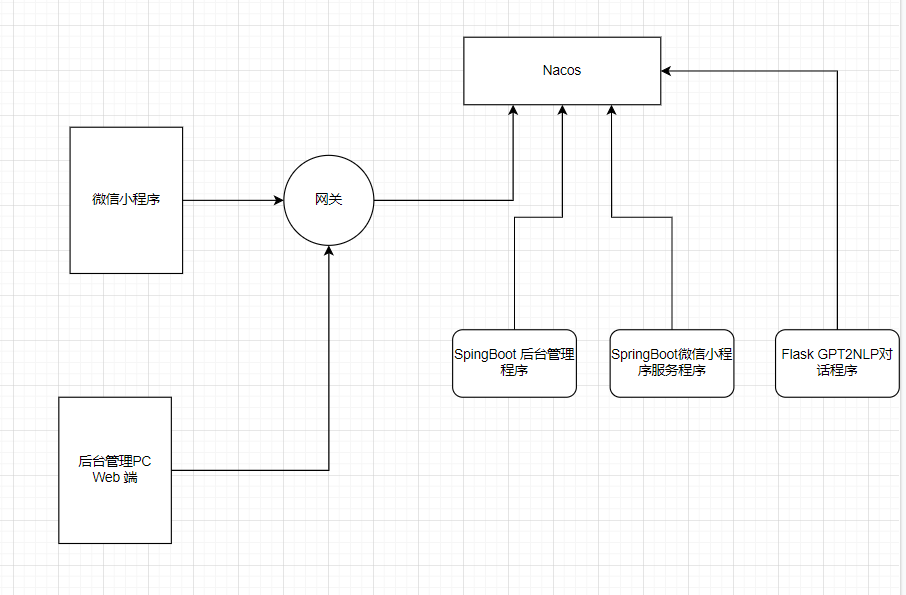
那么这里的网关的话,其实就是这个SpringCloud当中的GateWay,然后我们的flask算法服务都是注册到nacos,进行服务发现注册调用的。通过网关我们开放了对外的访问接口,但是直接通过网关不能直接访问到flask程序,这个程序是通过SpringBoot进行远程调用,远程调用的地址是通过Nacos获取的,换一句话来说,我们的算法服务是属于内网服务,不暴露。
那么在nacos的视角是这样的:
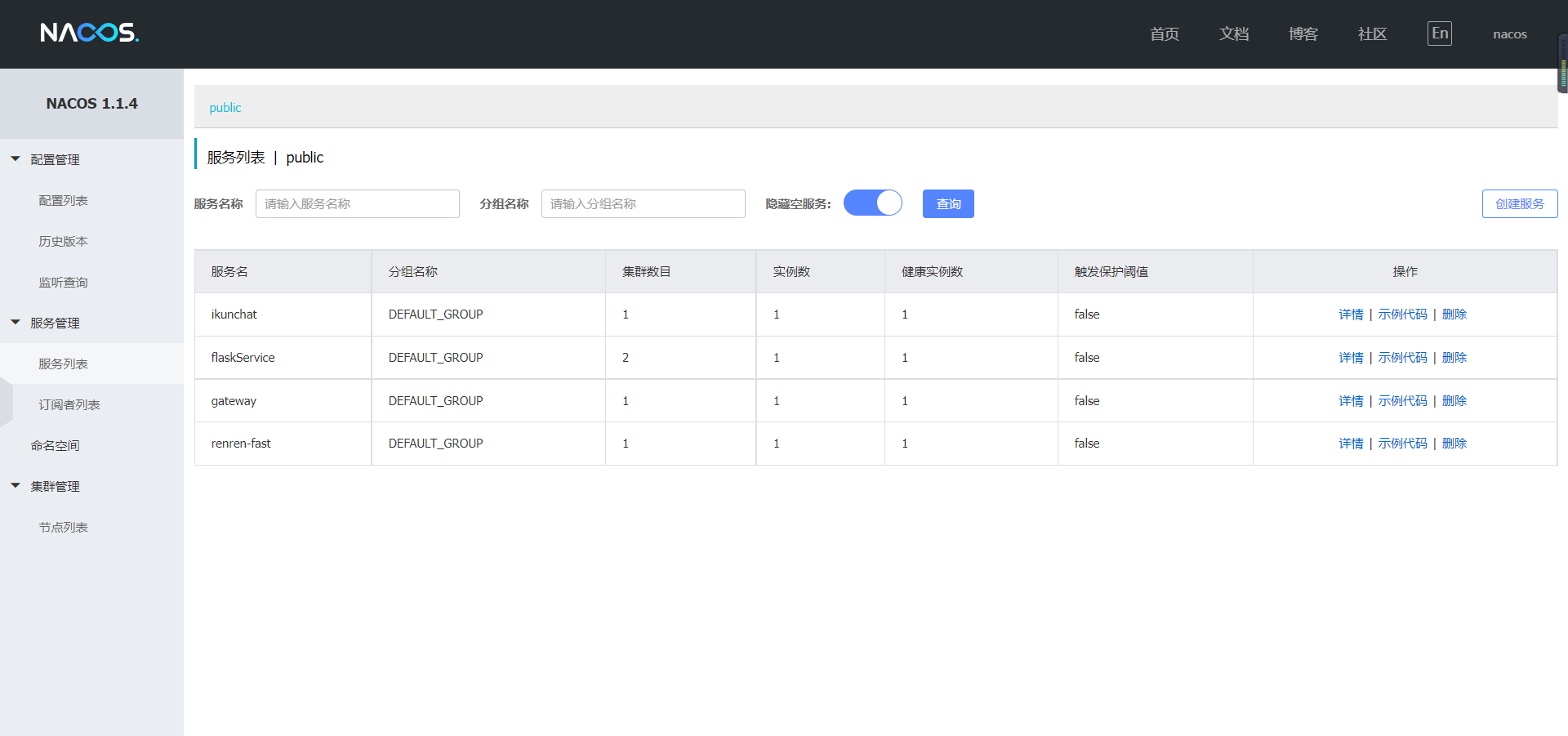
SpringCloud服务构建
ok,废话不多说,我们先来看看这个SpringCloud服务是如何构建的。
其实这里的话,我们先是偷了个懒,没错直接把先前开发WhiteHole准备好的模板工程拿了过来。这个模板工程是基于人人开源做的。当然我们在这个基础上做了改动,使得可以更加符合我的需求。
后台搭建
ok,对SpringCloud的服务的话,我们其实就两个,一个是后台管理,还有一个是正经微信小程序的服务端。Python不提供直接的服务,都是通过Java程序调用的。
那么关于这个后台的搭建的话,可以看到我以前的这两篇博文:
https://huterox.blog.csdn.net/article/details/126847925
https://huterox.blog.csdn.net/article/details/126977137
这边的话,我就不复述了,完成之后是这样的:
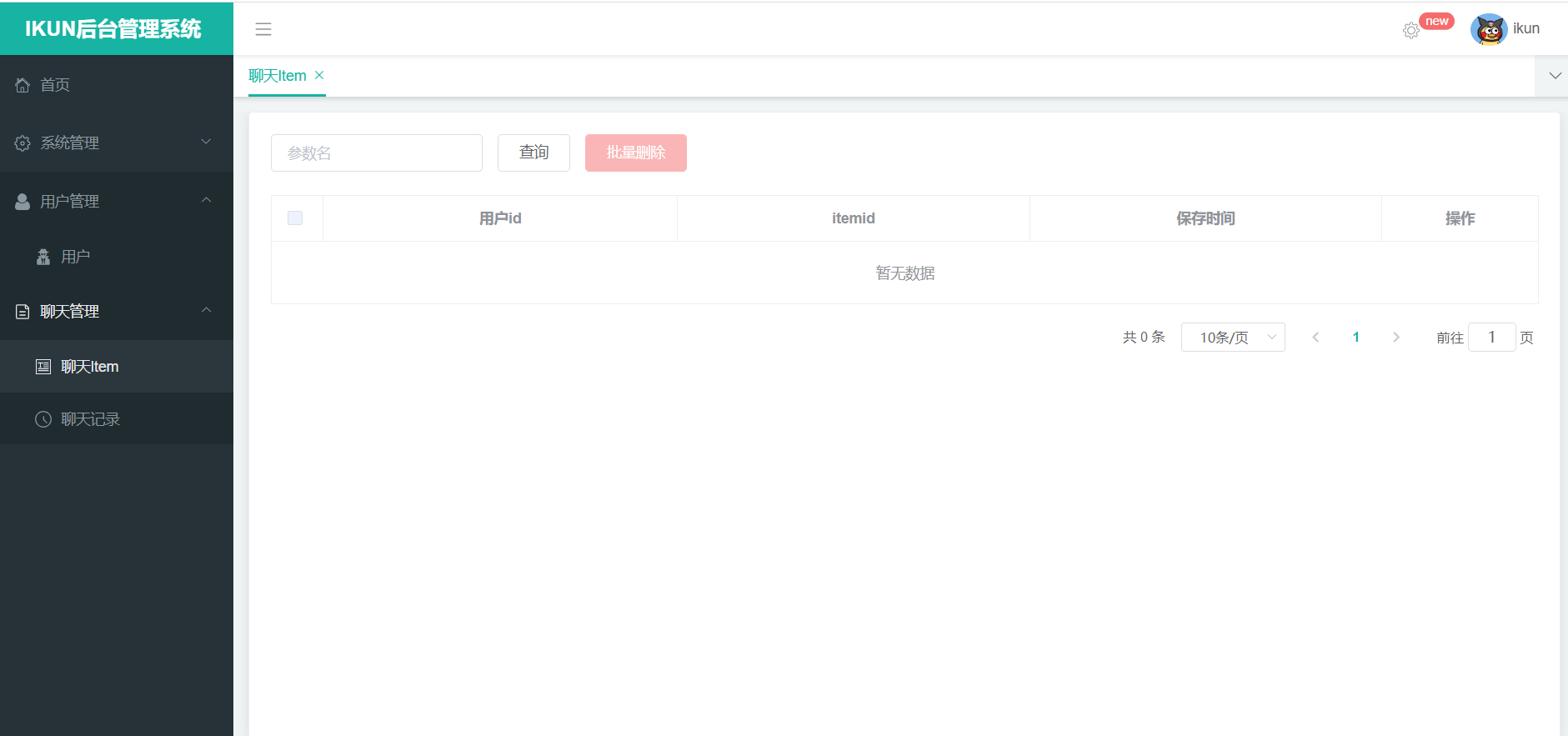
Python服务调用
之后是,调用我们的Python服务,其实也就是我们的算法,我们要的效果是这样的:
我们访问的是SpringBoot程序
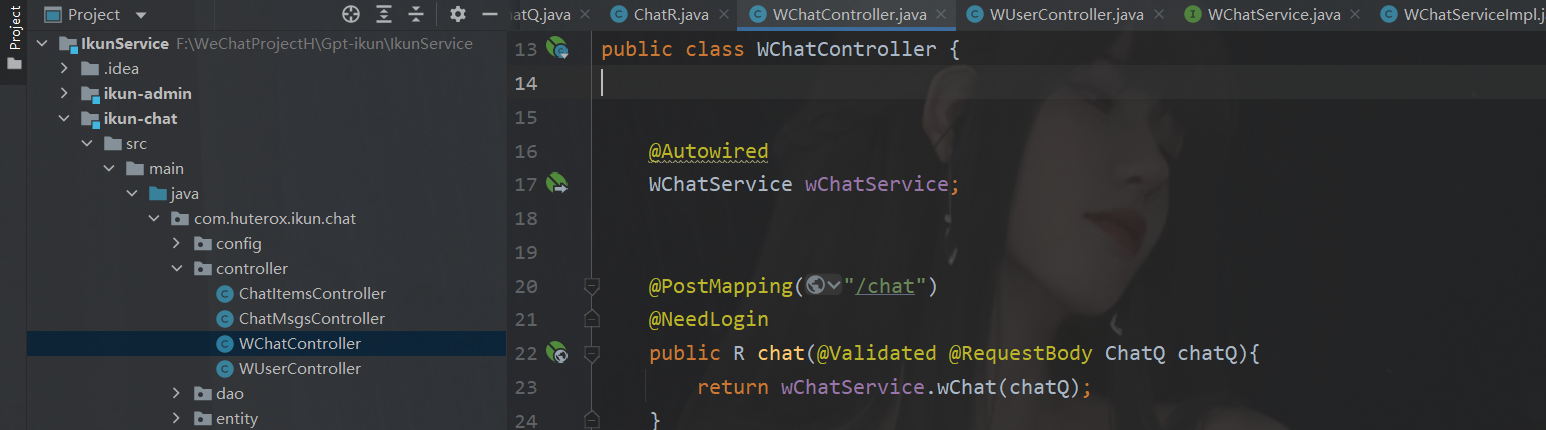
然后它调用到Flask程序,然后给到我们的前端
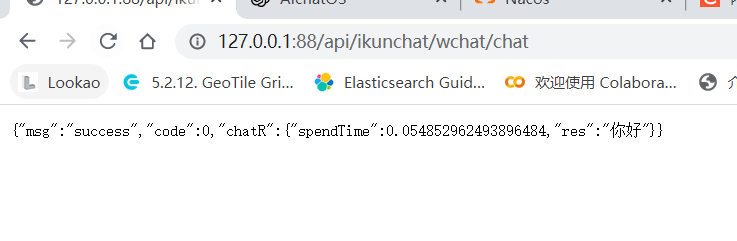
那么这里的实现的话,很简单,就是拿到nacos然后就好了。
package com.huterox.ikun.chat.service.impl;
import com.alibaba.nacos.api.naming.pojo.Instance;
import com.huterox.common.utils.R;
import com.huterox.ikun.chat.entity.Q.ChatQ;
import com.huterox.ikun.chat.entity.R.ChatR;
import com.huterox.ikun.chat.service.WChatService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.discovery.DiscoveryClient;
import org.springframework.core.ParameterizedTypeReference;
import org.springframework.http.*;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import java.util.List;
import java.util.Map;
@Service
public class WChatServiceImpl implements WChatService {
private final RestTemplate restTemplate;
private final DiscoveryClient discoveryClient;
@Autowired
public WChatServiceImpl(RestTemplate restTemplate, DiscoveryClient discoveryClient) {
this.restTemplate = restTemplate;
this.discoveryClient = discoveryClient;
}
@Override
public R wChat(ChatQ chatQ) {
String serviceName = "flaskService";
ServiceInstance instance = discoveryClient.getInstances(serviceName).stream()
.findFirst()
.orElseThrow(() -> new RuntimeException("no available instances"));
String url = String.format("http://%s:%d/message", instance.getHost(), instance.getPort());
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
HttpEntity<ChatQ> entity = new HttpEntity<>(chatQ, headers);
ResponseEntity<Map<String, Object>> response = restTemplate.exchange(url, HttpMethod.POST, entity, new ParameterizedTypeReference<Map<String, Object>>() {});
Map<String, Object> body = response.getBody();
ChatR chatR = new ChatR ();
chatR.setRes((String) body.get("res"));
chatR.setSpendTime((Double) body.get("spend_time"));
return R.ok().put("chatR",chatR);
}
}
Python算法服务
之后,是我们的算法服务构建。
首先我们的算法还是先前的这个项目的基础上改动的:
https://gitee.com/Huterox/gpt-play
那么改动的地方的话,就两个地方:app.py,和controller.py
首先是controller:
import torch
import os
import argparse
from datetime import datetime
import logging
from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
from transformers import BertTokenizer
import torch.nn.functional as F
from flask_caching import Cache
PAD = '[PAD]'
pad_id = 0
def set_interact_args():
"""
Sets up the training arguments.
"""
parser = argparse.ArgumentParser()
parser.add_argument('--device', default='0', type=str, required=False, help='生成设备')
# parser.add_argument('--temperature', default=1, type=float, required=False, help='生成的temperature')
# parser.add_argument('--topk', default=8, type=int, required=False, help='洛水K个我只饮一瓢')
# parser.add_argument('--topp', default=0.9, type=float, required=False, help='最高积累概率') #0
parser.add_argument('--model_config', default='../GPT2/config/model_config_dialogue_small.json', type=str, required=False,
help='模型参数')
parser.add_argument('--log_path', default='../GPT2/generatorlog/generator.log', type=str, required=False, help='interact日志存放位置')
parser.add_argument('--voca_path', default='../GPT2/vocabulary/vocab_small.txt', type=str, required=False, help='选择词库')
# parser.add_argument('--dialogue_model_path', default=r'../GPT2/model/norm_model/poertymodel', type=str, required=False, help='模型路径') #dialogue_model_path/
parser.add_argument('--save_samples_path', default="../GPT2/sample/", type=str, required=False, help="保存聊天记录的文件路径")
parser.add_argument('--repetition_penalty', default=1.0, type=float, required=False,
help="重复惩罚参数,若生成的对话重复性较高,可适当提高该参数")
parser.add_argument('--seed', type=int, default=None, help='设置种子用于生成随机数,以使得训练的结果是确定的')
# parser.add_argument('--max_len', type=int, default=128, help='每个utterance的最大长度,超过指定长度则进行截断')
# parser.add_argument('--max_history_len', type=int, default=5, help="聊天的history的最大长度")
parser.add_argument('--no_cuda', action='store_true', help='不使用GPU进行预测')
return parser.parse_args()
def create_logger(args):
"""
将日志输出到日志文件和控制台
"""
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
formatter = logging.Formatter(
'%(asctime)s - %(levelname)s - %(message)s')
# 创建一个handler,用于写入日志文件
file_handler = logging.FileHandler(
filename=args.log_path)
file_handler.setFormatter(formatter)
file_handler.setLevel(logging.INFO)
logger.addHandler(file_handler)
# 创建一个handler,用于将日志输出到控制台
console = logging.StreamHandler()
console.setLevel(logging.DEBUG)
console.setFormatter(formatter)
logger.addHandler(console)
return logger
def top_k_top_p_filtering(logits, top_k=0, top_p=0.0, filter_value=-float('Inf')):
""" Filter a distribution of logits using top-k and/or nucleus (top-p) filtering
Args:
logits: logits distribution shape (vocabulary size)
top_k > 0: keep only top k tokens with highest probability (top-k filtering).
top_p > 0.0: keep the top tokens with cumulative probability >= top_p (nucleus filtering).
Nucleus filtering is described in Holtzman et al. (http://arxiv.org/abs/1904.09751)
From: https://gist.github.com/thomwolf/1a5a29f6962089e871b94cbd09daf317
"""
assert logits.dim() == 1 # batch size 1 for now - could be updated for more but the code would be less clear
top_k = min(top_k, logits.size(-1)) # Safety check
if top_k > 0:
# Remove all tokens with a probability less than the last token of the top-k
# torch.topk()返回最后一维最大的top_k个元素,返回值为二维(values,indices)
# ...表示其他维度由计算机自行推断
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None] #增加了一个维度。newaxis效果和None是一样的,None是别名
logits[indices_to_remove] = filter_value # 对于topk之外的其他元素的logits值设为负无穷
if top_p > 0.0:
sorted_logits, sorted_indices = torch.sort(logits, descending=True) # 对logits进行递减排序
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
# Remove tokens with cumulative probability above the threshold
sorted_indices_to_remove = cumulative_probs > top_p
# Shift the indices to the right to keep also the first token above the threshold
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = 0
indices_to_remove = sorted_indices[sorted_indices_to_remove]
logits[indices_to_remove] = filter_value
return logits
def load_model(model_path):
args = set_interact_args()
args.cuda = torch.cuda.is_available() and not args.no_cuda
device = 'cuda' if args.cuda else 'cpu'
logger = create_logger(args)
# 当用户使用GPU,并且GPU可用时
logger.info('using device:{}'.format(device))
os.environ["CUDA_VISIBLE_DEVICES"] = args.device
model = GPT2LMHeadModel.from_pretrained(model_path)
model.to(device)
model.eval()
return model,device,args
def GPTgetSentence(input_target,
temperature=1,
topK = 10,
topP = 0.9,
max_len = 128,
history = None,
max_history_len=5,
max_history = 100,
chat=False,
model_path = None,
):
"""
:param input_target:
:param temperature:
:param topK:
:param topP:
:param max_len:
:param history:
:param max_history_len: 参考历史聊天记录
:param max_history: 历史记录长度
:param chat: 是否为聊天模式
:return:
"""
assert history!=None and max_history>max_history_len,"history不为空,max_history必须大于max_history_len"
from .app import chat_model
if(chat_model.get("model")):
model, device, args = chat_model.get("model")
else:
model, device, args = load_model(model_path)
chat_model['model'] = (model, device, args)
tokenizer = BertTokenizer(vocab_file=args.voca_path)
if args.save_samples_path:
if not os.path.exists(args.save_samples_path):
os.makedirs(args.save_samples_path)
samples_file = open(args.save_samples_path + '/samples.txt', 'a', encoding='utf8')
samples_file.write("聊天记录{}:\n".format(datetime.now()))
# 存储聊天记录,每个utterance以token的id的形式进行存储
text = input_target
if args.save_samples_path:
samples_file.write("user:{}\n".format(text))
if(chat):
if(max_history<len(history)):
history = []
history.append(tokenizer.encode(text))
input_ids = [tokenizer.cls_token_id] # 每个input以[CLS]为开头
if(chat):
for history_id, history_utr in enumerate(history[-max_history_len:]):
input_ids.extend(history_utr)
input_ids.append(tokenizer.sep_token_id)
curr_input_tensor = torch.tensor(input_ids).long().to(device)
generated = []
# 最多生成max_len个token
for _ in range(max_len):
outputs = model(input_ids=curr_input_tensor)
next_token_logits = outputs[0][-1, :]
# 对于已生成的结果generated中的每个token添加一个重复惩罚项,降低其生成概率
for id in set(generated):
next_token_logits[id] /= args.repetition_penalty
next_token_logits = next_token_logits / temperature
# 对于[UNK]的概率设为无穷小,也就是说模型的预测结果不可能是[UNK]这个token
next_token_logits[tokenizer.convert_tokens_to_ids('[UNK]')] = -float('Inf')
filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=topK, top_p=topP)
# torch.multinomial表示从候选集合中无放回地进行抽取num_samples个元素,权重越高,抽到的几率越高,返回元素的下标
next_token = torch.multinomial(F.softmax(filtered_logits, dim=-1), num_samples=1)
if next_token == tokenizer.sep_token_id: # 遇到[SEP]则表明response生成结束
break
generated.append(next_token.item())
curr_input_tensor = torch.cat((curr_input_tensor, next_token), dim=0)
history.append(generated)
text = tokenizer.convert_ids_to_tokens(generated)
if args.save_samples_path:
samples_file.write("GPT:{}\n".format("".join(text)))
return "".join(text)
if __name__ == '__main__':
histroy = []
model_path = "../GPT2/model/norm_model/poertymodel"
print(GPTgetSentence("你好",1,10,0.9,128,histroy,5,100,False,model_path))
然后是我们的app服务。
app
这里的话,我先说一下有些坑在这个python当中,我们连接nacos使用的是这个:nacos-sdk-python。但是在我实际的使用当中,发现这个玩意会莫名其妙下线,但是服务是正常的。可能是版本还是什么问题,这个咱也不知道,也不敢说,最后查了查iusse,最后的话,写了个临时的方案,具体说明原因的话,我这里就不展开了。因为也不确定分析的对不对,猜测应该是这样的。
import queue
import sys
import os
import threading
curPath = os.path.abspath(os.path.dirname(__file__))
rootPath = os.path.split(curPath)[0]
sys.path.append(rootPath)
import requests
from Server.controller import GPTgetSentence
import time
from flask import Flask, request, jsonify
from nacos import NacosClient
"""
这里对原先的GPT2-play进行修改
"""
history_cache = {}
chat_model = {}
app = Flask(__name__)
# NacosClient.set_debugging()
client = NacosClient("127.0.0.1:8848", namespace="public")
app.config['JSON_AS_ASCII'] = False
q = queue.Queue()
lock = threading.Lock()
def init():
"""
懒得改了,激活一下就好了
:return:
"""
start = time.time()
chat_model_path = "../GPT2/model/norm_model/chatmodel"
result = GPTgetSentence("你好", 1.2, 10, 0.95, 256,
[], 24, 100, True, chat_model_path
)
end = time.time()
print("激活完成~,耗时:",end-start)
# 定义处理心跳消息的函数
def handle_heartbeat():
while True:
try:
requests.get('http://127.0.0.1:8100/heartbeat')
instance_info = q.get()
client.add_naming_instance(instance_info['serviceName'], instance_info['ip'], instance_info['port'])
except:
if(not q.empty()):
return
# 启动处理心跳消息的专用线程
# t = threading.Thread(target=handle_heartbeat)
# t.start()
@app.route('/heartbeat')
def heartbeat():
instance_info = {'serviceName': 'flaskService', 'ip': '127.0.0.1', 'port': 8100}
lock.acquire()
try:
q.put(instance_info)
time.sleep(2)
finally:
lock.release()
return 'OK'
@app.route('/message',methods=['POST'])
def ikun_chat():
user_input = request.json['msg']
user_id = request.json['uid']
history = history_cache.get(user_id,[])
chat_model_path = "../GPT2/model/norm_model/chatmodel",
start = time.time()
result = GPTgetSentence(user_input, 1.2, 10, 0.95, 256,
history, 24, 100, True, chat_model_path
)
end = time.time()
response = {
'res': result ,
'spend_time': end - start
}
return jsonify(response)
if __name__ == '__main__':
init()
# 注册 Flask 应用到 Nacos 中
client.add_naming_instance('flaskService', '127.0.0.1', 8100)
is_start = True
t = threading.Thread(target=handle_heartbeat)
t.start()
app.run(debug=False,port=8100)
总结
这个玩意,一个作孽可以当三个交,还是能玩玩的。