本文要介绍的AutoRec模型是由澳大利亚国立大学在2015年提出的,它将自编码器(AutoEncoder)的思想与协同过滤(Collaborative Filter)的思想结合起来,提出了一种单隐层的简单神经网络推荐模型。
可以说这个模型的提出,拉开了使用深度学习解决推荐系统问题的序幕,为复杂深度学习网络的构建提供了思路。
原论文只有2页,非常简洁明了,比较适合作为深度学习推荐系统的入门模型来学习,原文地址在这里
前言
本文会介绍AutoRec模型的基本原理,包括网络模型、损失函数、推荐过程、实验结果等,并且会给出基于PyTorch的代码。
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
文章中的完整源码、资料、数据、技术交流提升, 均可加知识星球交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:mlc2060,备注:来自 获取推荐资料
方式②、微信搜索公众号:机器学习社区,后台回复:推荐资料
AutoRec模型介绍
AutoRec模型跟MLP(多层感知器)类似,是一个标准的3层(包含输入层)神经网络,只不过它结合其结合了自编码器(AutoEncoder)和协同过滤(Collaborative Filtering)的思想。
其实再确切一点说,AutoRec模型就是一个标准的自编码器结构,它的基本原理是利用协同过滤中的共现矩阵,完成物品向量或者用户向量的自编码。再利用自编码结果得到用户对所有物品的评分,结果通过排序之后就可以用于物品推荐。
这里先简要地介绍一下自编码器:
自编码器是一种无监督的数据维度压缩和数据特征表达方法,它是神经网络的一种,经过训练后能尝试将输入复制到输出。自编码器由编码器和解码器组成,结构如下:
 自编码器结构
自编码器结构


下面是AutoRec的整体模型框图:
损失函数
AutoRec模型的损失函数中考虑到了对参数的限制,因此加入了L2正则来防止过拟合,损失函数变化为:
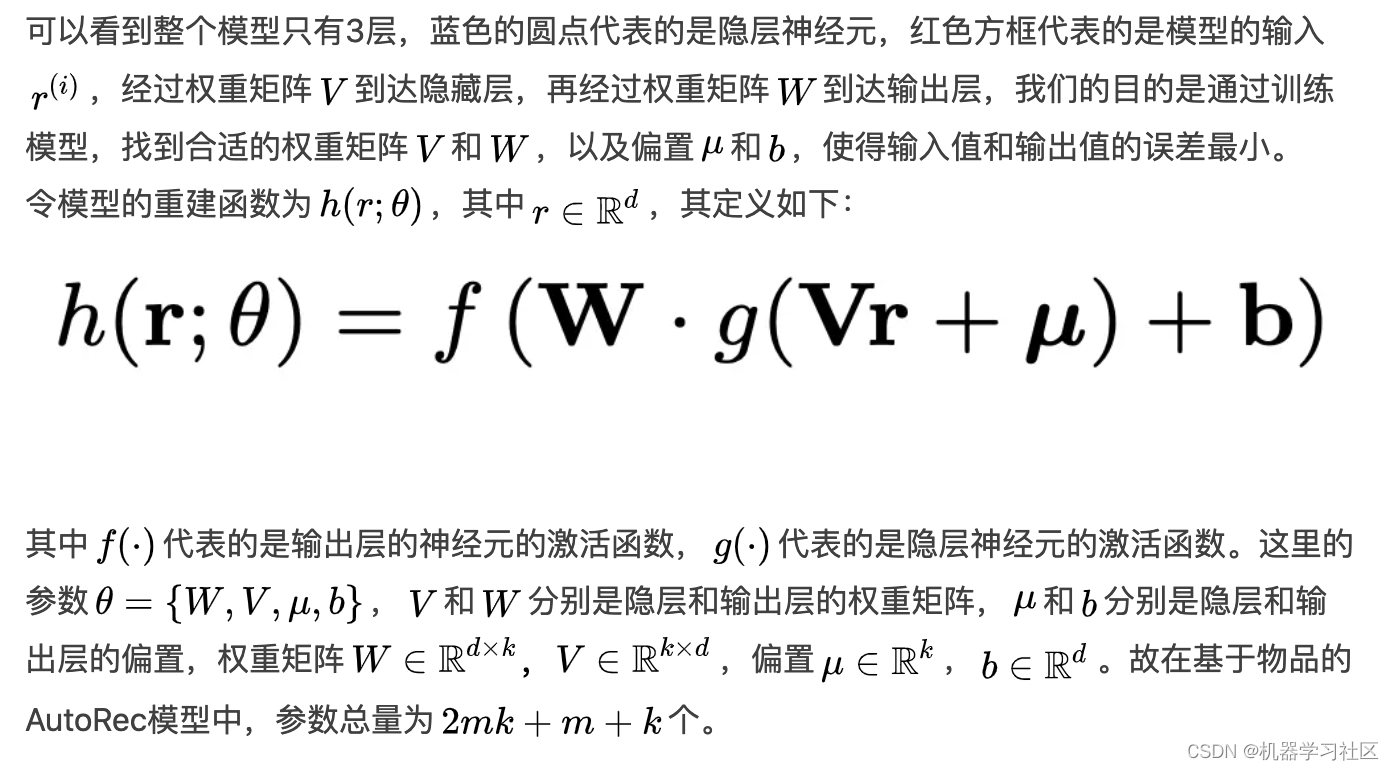
基于AutoRec的推荐过程
假如我们现在已经训练好了模型,那基于物品的AutoRec模型的推荐过程是怎样的呢?其实非常简单,只需要2步:
- 依次输入物品,得到模型输出的预测评分向量。
- 遍历所有物品预测评分向量的推荐列表。
上述流程是针对基于物品的AutoRec模型,也就是Item-AutoRec,其实只要把AutoRec模型的输入变成用户向量,那么模型其实就变成了基于用户的AutoRec模型,即User-AutoRec。这两者的推荐流程有点不同,在后面的代码实践中,我将两种推荐方式都写下来了,读者可以参考代码。
实验对比
作者分别在MovieLens 1M和10M、以及Netflix数据上进行了对比实验,评测指标为RMSE,即均方根误差。分别与U-RBM、I-RBM、BiasedMF、LLORMA算法进行了对比。结果如下:
作者还做了消融实验,验证选择不同的激活函数对最终实验结果的影响。 除此之外,还评测了不同隐层神经元数量对实验结果的影响, 可以看到随着隐层神经元数量的增加,RMSE稳步下降。
代码实践
代码基于PyTorch编写,主要包含数据预处理和加载文件dataloader.py,网络模型定义network.py,训练器trainer.py,以及测试文件autorec_test.py。
数据预处理部分比较简单,测试的数据为MovieLens 1M数据集,主要定义了共现矩阵,并且将数据集划分为训练集和测试集。
完整代码如下:
import torch
import numpy as np
import torch.utils.data as Data
def dataProcess(filename, num_users, num_items, train_ratio):
fp = open(filename, 'r')
lines = fp.readlines()
num_total_ratings = len(lines)
user_train_set = set()
user_test_set = set()
item_train_set = set()
item_test_set = set()
train_r = np.zeros((num_users, num_items))
test_r = np.zeros((num_users, num_items))
train_mask_r = np.zeros((num_users, num_items))
test_mask_r = np.zeros((num_users, num_items))
random_perm_idx = np.random.permutation(num_total_ratings)
train_idx = random_perm_idx[0:int(num_total_ratings * train_ratio)]
test_idx = random_perm_idx[int(num_total_ratings * train_ratio):]
''' Train '''
for itr in train_idx:
line = lines[itr]
user, item, rating, _ = line.split("::")
user_idx = int(user) - 1
item_idx = int(item) - 1
train_r[user_idx][item_idx] = int(rating)
train_mask_r[user_idx][item_idx] = 1
user_train_set.add(user_idx)
item_train_set.add(item_idx)
''' Test '''
for itr in test_idx:
line = lines[itr]
user, item, rating, _ = line.split("::")
user_idx = int(user) - 1
item_idx = int(item) - 1
test_r[user_idx][item_idx] = int(rating)
test_mask_r[user_idx][item_idx] = 1
user_test_set.add(user_idx)
item_test_set.add(item_idx)
return train_r, train_mask_r, test_r, test_mask_r, user_train_set, item_train_set, user_test_set, item_test_set
def Construct_DataLoader(train_r, train_mask_r, batchsize):
torch_dataset = Data.TensorDataset(torch.from_numpy(train_r), torch.from_numpy(train_mask_r))
return Data.DataLoader(dataset=torch_dataset, batch_size=batchsize, shuffle=True)
网络模型部分代码比较简单,基本就是两个全连接层外加一个Sigmoid激活函数就搞定。因为需要加上关于权重矩阵的正则化,所以这里的损失函数并没有使用torch自带的,而是根据论文描述自己定义的。
同时实现了根据用户对所有物品评分向量的推荐方法,和根据所有用户对物品的评分向量的物品推荐方法,并且加上了在测试集上的评估方法。
代码如下:
import torch
import numpy as np
import torch.nn as nn
class AutoRec(nn.Module):
"""
基于物品的AutoRec模型
"""
def __init__(self, config):
super(AutoRec, self).__init__()
self._num_items = config['num_items']
self._hidden_units = config['hidden_units']
self._lambda_value = config['lambda']
self._config = config
self._encoder = nn.Sequential(
nn.Linear(self._num_items, self._hidden_units),
nn.Sigmoid()
)
self._decoder = nn.Sequential(
nn.Linear(self._hidden_units, self._num_items)
)
def forward(self, input):
return self._decoder(self._encoder(input))
def loss(self, res, input, mask, optimizer):
cost = 0
temp = 0
cost += ((res - input) * mask).pow(2).sum()
rmse = cost
for i in optimizer.param_groups:
for j in i['params']:
if j.data.dim() == 2:
temp += torch.t(j.data).pow(2).sum()
cost += temp * self._config['lambda'] * 0.5
return cost, rmse
def recommend_user(self, r_u, N):
"""
:param r_u: 单个用户对所有物品的评分向量
:param N: 推荐的商品个数
"""
predict = self.forward(torch.from_numpy(r_u).float())
predict = predict.detach().numpy()
indexs = np.argsort(-predict)[:N]
return indexs
def recommend_item(self, user, test_r, N):
"""
:param r_u: 所有用户对物品i的评分向量
:param N: 推荐的商品个数
"""
recommends = np.array([])
for i in range(test_r.shape[1]):
predict = self.forward(test_r[:, i])
recommends.append(predict[user])
indexs = np.argsot(-recommends)[:N]
return recommends[indexs]
def evaluate(self, test_r, test_mask_r, user_test_set, user_train_set, item_test_set, item_train_set):
test_r_tensor = torch.from_numpy(test_r).type(torch.FloatTensor)
test_mask_r_tensor = torch.from_numpy(test_mask_r).type(torch.FloatTensor)
res = self.forward(test_r_tensor)
unseen_user_test_list = list(user_test_set - user_train_set)
unseen_item_test_list = list(item_test_set - item_train_set)
for user in unseen_user_test_list:
for item in unseen_item_test_list:
if test_mask_r[user, item] == 1:
res[user, item] = 3
mse = ((res - test_r_tensor) * test_mask_r_tensor).pow(2).sum()
RMSE = mse.detach().cpu().numpy() / (test_mask_r == 1).sum()
RMSE = np.sqrt(RMSE)
print('test RMSE : ', RMSE)
def saveModel(self):
torch.save(self.state_dict(), self._config['model_name'])
def loadModel(self, map_location):
state_dict = torch.load(self._config['model_name'], map_location=map_location)
self.load_state_dict(state_dict, strict=False)
测试代码主要是包含了模型训练,随机挑选了3个用户并推荐5个商品,以及在测试集上评估RMSE指标等。
代码如下:
import torch
from AutoRec.trainer import Trainer
from AutoRec.network import AutoRec
from AutoRec.dataloader import dataProcess
autorec_config = \
{
'train_ratio': 0.9,
'num_epoch': 200,
'batch_size': 100,
'optimizer': 'adam',
'adam_lr': 1e-3,
'l2_regularization':1e-4,
'num_users': 6040,
'num_items': 3952,
'hidden_units': 500,
'lambda': 1,
'device_id': 2,
'use_cuda': False,
'data_file': '../Data/ml-1m/ratings.dat',
'model_name': '../Models/AutoRec.model'
}
if __name__ == "__main__":
train_r, train_mask_r, test_r, test_mask_r, \
user_train_set, item_train_set, user_test_set, item_test_set = \
dataProcess(autorec_config['data_file'], autorec_config['num_users'], autorec_config['num_items'], autorec_config['train_ratio'])
autorec = AutoRec(config=autorec_config)
autorec.loadModel(map_location=torch.device('cpu'))
print("用户1推荐列表: ",autorec.recommend_user(test_r[0], 5))
print("用户2推荐列表: ",autorec.recommend_user(test_r[9], 5))
print("用户3推荐列表: ",autorec.recommend_user(test_r[23], 5))
autorec.evaluate(test_r, test_mask_r, user_test_set=user_test_set, user_train_set=user_train_set, \
item_test_set=item_test_set, item_train_set=item_train_set)
总结
AutoRec模型是深度学习方法用于推荐系统中的开山之作,它仅仅使用了一个单隐层的自编码器来泛化用户和物品评分,使模型具有一定的泛化和表达能力。但是由于模型过于简单,也让它在实际使用中显得表征能力不足。