Protobuf介绍
Protobuf(下文称为 PB)是一种常见的数据序列化方式,常常用于后台微服务之间传递数据
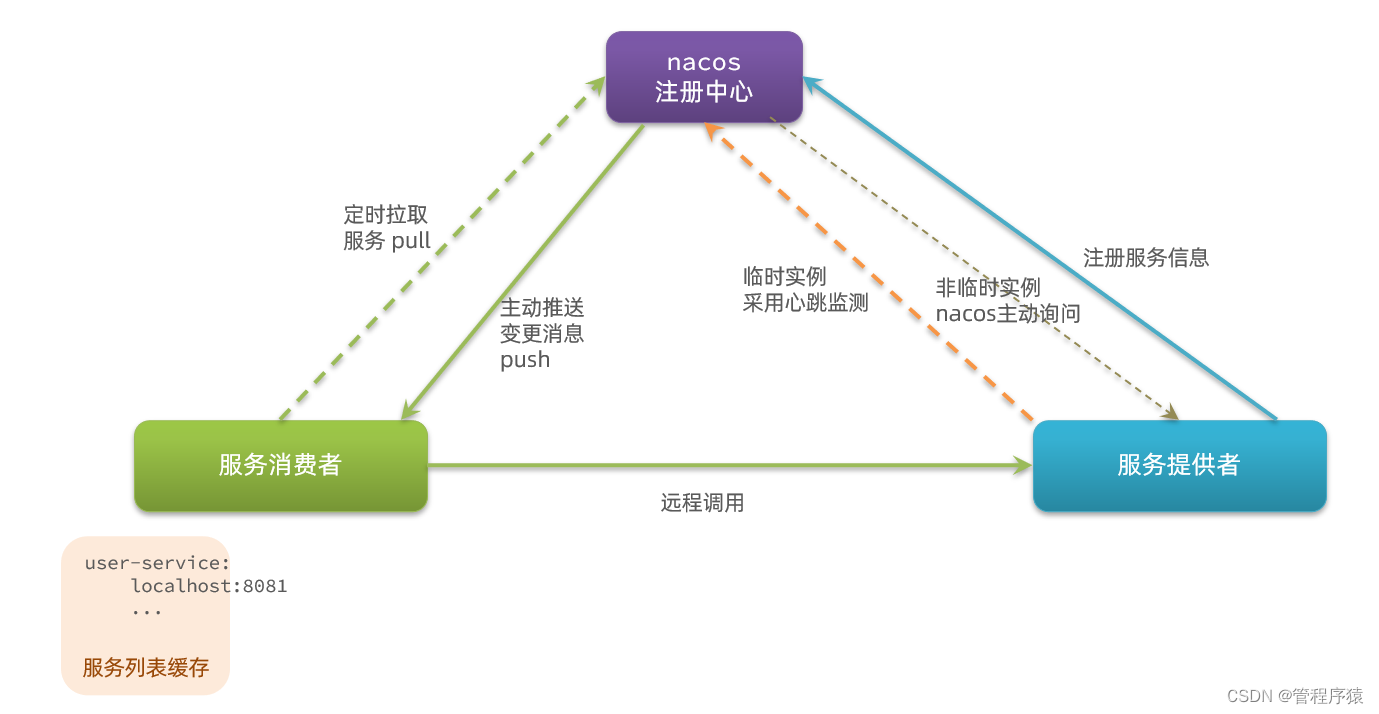
protobuf 的类图如下:
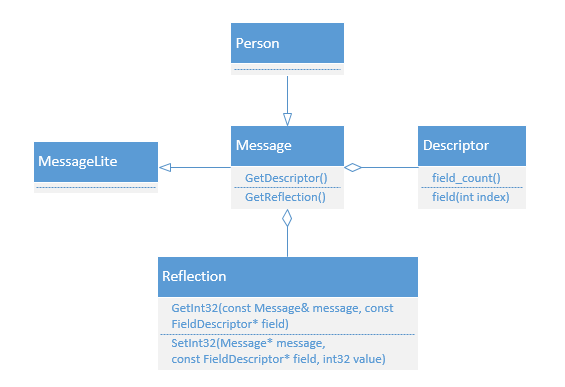
类 Descriptor 介绍
类 Descriptor 主要是对 Message 进行描述,包括 message 的名字、所有字段的描述、原始 proto 文件内容等
Descriptor 类和 Reflection 类都聚合于 Message,是弱依赖的关系。
| 类名 | 类描述 |
|---|---|
| Descriptor | 对 Message 进行描述,包括 message 的名字、所有字段的描述、原始 proto 文件内容等 |
| FieldDescriptor | 对 Message 中单个字段进行描述,包括字段名、字段属性、原始的 field 字段等 |
| Reflection | 提供了动态读和写 message 中单个字段能力 |
利用类比思维来理解Descriptor和ProtoBuf的关系
Descriptor->proto
字节码 ->Java类
Protobuf的优点
性能方面
- 序列化后,数据大小可缩小3倍
- 序列化速度快
- 传输速度快
使用方面
- 使用简单:
proto编译器自动进行序列化和反序列化- 维护成本低:多平台只需要维护一套对象协议文件,即
.proto文件- 可扩展性好:不必破坏旧的数据格式,就能对数据结构进行更新
- 加密性好:http传输内容抓包只能抓到字节数据
使用范围
- 跨平台、跨语言、可扩展性强
字段解释
// FileName: tutorial.person.proto
// 通常文件名建议命名格式为 包名.消息名.proto
// 表示正在使用proto2命令
syntax = "proto2";
//包声明,tutorial 也可以声明为二级类型。
//例如a.b,表示a类别下b子类别
package tutorial;
//编译器将生成一个名为person的类
//类的字段信息包括姓名name,编号id,邮箱email,
//以及电话号码phones
message Person {
required string name = 1; // (位置1)
required int32 id = 2;
optional string email = 3; // (位置2)
enum PhoneType { //电话类型枚举值
MOBILE = 0; //手机号
HOME = 1; //家庭联系电话
WORK = 2; //工作联系电话
}
//电话号码phone消息体
//组成包括号码number、电话类型 type
message PhoneNumber {
required string number = 1;
optional PhoneType type =
2 [default = HOME]; // (位置3)
}
repeated PhoneNumber phones = 4; // (位置4)
}
// 通讯录消息体,包括一个Person类的people
message AddressBook {
repeated Person people = 1;
}包声明
proto文件以package声明开头,这有助于防止不同项目之间命名冲突。在C++中,以package声明的文件内容生成的类将放在与包名匹配的namespace中,上面的.proto文件中所有的声明都属于tutorial。字段规则
required:消息体中必填字段,不设置会导致编解码异常。(例如位置1)optional: 消息体中可选字段,可通过default关键字设置默认值。(例如位置2)repeated: 消息体中可重复字段,重复的值的顺序会被保留(例如位置3)。其中,proto3默认使用packed方式存储,这样编码方式比较节省内存。标识号
标识号:在消息体的定义中,每个字段都必须要有一个唯一的标识号,标识号是[0,2^29-1]范围内的一个整数。以Person为例,name=1,id=2, email=3, phones=4 中的1-4就是标识号。数据定义
许多标准的简单数据类型都可以用作
message字段类型,包括bool,int32,float,double和string。还可以使用其他message类型作为字段类型在消息体中添加更多结构。在上面的示例中,Person包含PhoneNumber message, 而AddressBook包含Person message。甚至可以定义嵌套在其他message中的message类型。例如,上面的PhoneNumber定义在Person。