目录
一、为什么选用SmartEngine
二、各类流程引擎框架简单对比
1、流程设计器推荐
2、什么是BPMN
流程定义解释说明
三、SmartEngine之Custom实操
1、引入依赖
2、典型的初始化代码如下
3、节点如何流转以及流程实例存储问题
4、定义Delegation
关键类
一、为什么选用SmartEngine
阿里目前新开源了一套流程引擎框架,相比于flowable等传统流程引擎框架,SmartEngine更加轻便,它支持两种模式,其中的Custom模式,并不强依赖数据库,经典场景如请求密集型的互联网业务,这种业务对高并发和存储成本比较敏感,流程实例的状态可由一个简短的json文本来存储,意味着所有的流程更新,都会体现在这一个json字符串里。结合公司业务场景需要,以及未来考量,Custom模式完全符合当下场景。
二、各类流程引擎框架简单对比
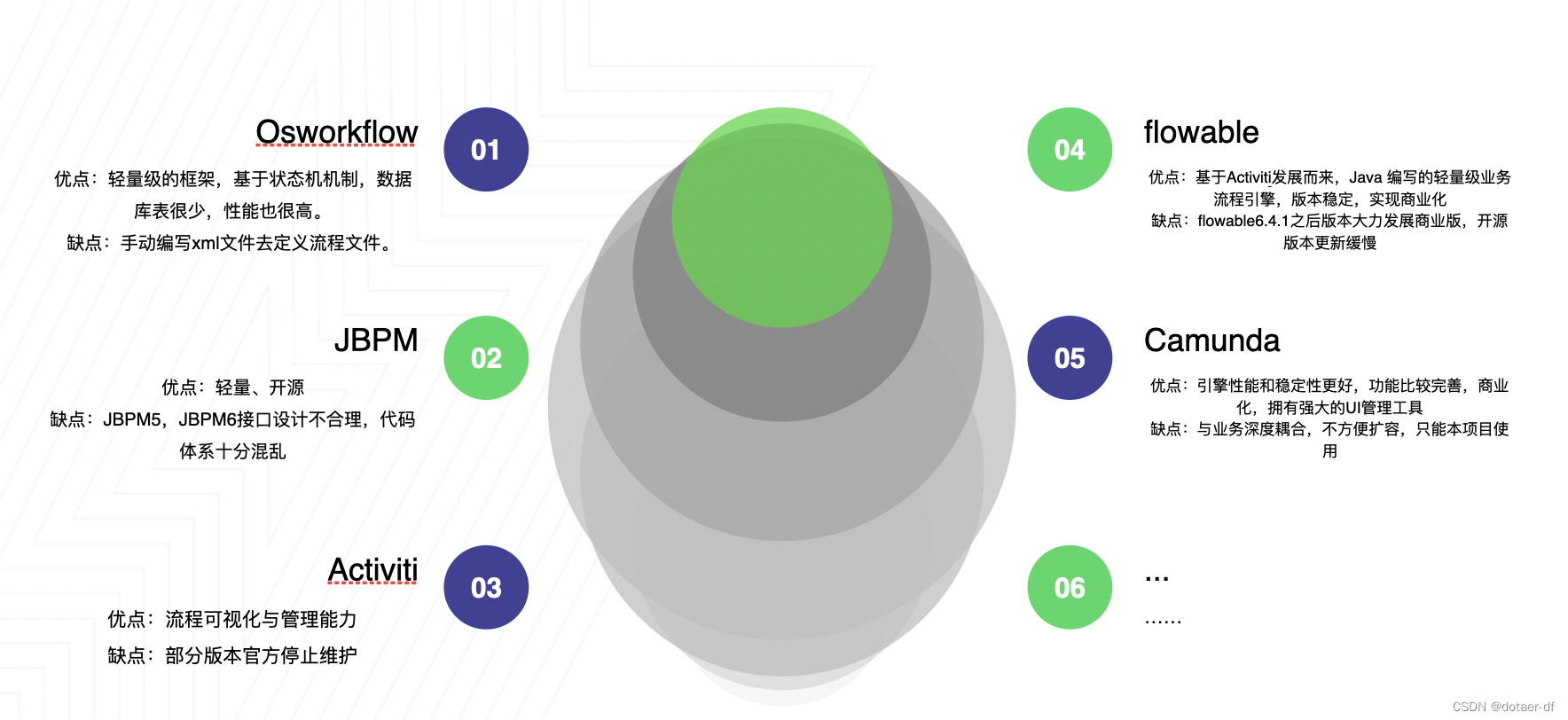
市场上比较有名的开源流程引擎有osworkflow、jbpm、activiti、flowable、camunda。其中:Jbpm4、Activiti、Flowable、camunda四个框架同宗同源,祖先都是Jbpm4,开发者只要用过其中一个框架,基本上就会用其它三个。流程可视化作为低代码开发平台的特征之一,它的核心是流程引擎和流程设计器。
1、流程设计器推荐
SmartEngine推荐使用Camunda这个开源版本设计器。相关bpmn流程图可以直接用Camunda Modeler 绘制,绘制完成后导出xml文件,然后在SmartEngine中无缝使用,不用额外手工修改
Camunda下载地址
所以需要大家对Camunda有一个基本的了解
2、什么是BPMN
BPMN全称Business Process Model And Notation,是一套符合国际标准的业务流程建模符号。基本上,BPMN规范定义流程该怎么做,哪些结构可以与其他进行连接等等。不符合BPMN的流程引擎使用效果将大打折扣。也就是说所有流程引擎都要遵循BPMN这一标准,好比所有浏览器都要遵循HTTP协议
BPMN片段实例
<?xml version="1.0" encoding="UTF-8"?>
<definitions xmlns:smart="http://smartengine.org/schema/process" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL" targetNamespace="Examples">
<process id="exclusiveTest" version="1.0.0">
<startEvent id="theStart">
</startEvent>
<sequenceFlow id="flow1" sourceRef="theStart" targetRef="submitTask"/>
<userTask id="submitTask" name="SubmitTask">
</userTask>
<sequenceFlow id="flowFromSubmitTask" sourceRef="submitTask" targetRef="auditTask"/>
<userTask id="auditTask" name="AuditTask">
</userTask>
<sequenceFlow id="flowFromAuditTask" sourceRef="auditTask" targetRef="exclusiveGw1"/>
<exclusiveGateway id="exclusiveGw1" name="Exclusive Gateway 1"/>
<sequenceFlow id="flow2" sourceRef="exclusiveGw1"
targetRef="executeTask">
<conditionExpression xsi:type="mvel">approve == 'agree'
</conditionExpression>
</sequenceFlow>
<sequenceFlow id="flow3" sourceRef="exclusiveGw1"
targetRef="advancedAuditTask">
<conditionExpression xsi:type="mvel">approve == 'upgrade'
</conditionExpression>
</sequenceFlow>
<serviceTask id="executeTask" name="ExecuteTask"
smart:class="com.alibaba.simplest.bpm.util.AuditProcessServiceTaskDelegation">
</serviceTask>
<sequenceFlow id="flow5" sourceRef="executeTask" targetRef="theEnd"/>
<userTask id="advancedAuditTask" name="AdvancedAuditTask">
</userTask>
<sequenceFlow id="flowFromAdvancedAuditTask" sourceRef="advancedAuditTask"
targetRef="exclusiveGw2"/>
<exclusiveGateway id="exclusiveGw2" name="Exclusive Gateway 2"/>
<sequenceFlow id="flow9" sourceRef="exclusiveGw2"
targetRef="executeTask">
<conditionExpression type="mvel">approve == 'agree'
</conditionExpression>
</sequenceFlow>
<sequenceFlow id="flow10" sourceRef="exclusiveGw2"
targetRef="theEnd">
<conditionExpression type="mvel">approve == 'deny'
</conditionExpression>
</sequenceFlow>
<endEvent id="theEnd"/>
</process>
</definitions>流程定义解释说明
process,表示一个流程。id="exclusiveTest" version="1.0.0",分别表示流程定义的id和版本。这两个字段唯一区分一个流程定义。startEvent,表示流程开始节点。只允许有一个开始节点。endEvent,表示流程结束节点。可以有多个结束节点。sequenceFlow,表示环节流转关系。sourceRef="theStart" targetRef="submitTask"分别表示起始节点和目标节点。该节点有个子节点,<conditionExpression type="mvel">approve == 'agree' </conditionExpression>,这个片段很重要,用来描述流程流转的条件.approve == 'upgrade'使用的是MVEL表达式语法. 另外,还值得注意的是,在驱动流程运转时,需要传入正确的参数。 比如说,在后面介绍的api中,通常会需要在Map中传递业务请求参数。 那么需要将map中的key 和 Mvel的运算因子关联起来。 以这个例子来说,request.put("approve", "agree");里面的approve 和approve == 'agree'命名要一致。exclusiveGateway,表示互斥网关。该节点非常重要。用来区分流程节点的不同转向。 互斥网关在引擎执行conditionExpression后,有且只能选择一条匹配的sequenceFlow 继续执行。serviceTask,服务任务,用来表示执行一个服务,所以他会有引擎默认的扩展:smart:class="com.alibaba.smart.framework.example.AuditProcessServiceTaskDelegation". Client Developer使用时,需要自定义对应的业务实现类。在该节点执行时,它会自动执行服务调用,执行 smart:class 这个 delegation 。 该节点不暂停,会自动往下一个流转。receiveTask,接收任务。在引擎遇到此类型的节点时,引擎执行会自动暂停,等待外部调用signal方法。 当调用signal方法时,会驱动流程当前节点离开。 在离开该节点时,引擎会自动执行 smart:class 这个 delegation。 在一般业务场景中,我们通常使用receiveTask来表示等需要等待外部回调的节点。userTask,表示用户任务节点,仅用于DataBase模式。该节点需要人工参与处理,并且通常需要在待办列表中展示。 在Custom 模式下,建议使用receiveTask来代替。parallelGateway,这个节点并未在上述流程定义中体现,这里详细说一下。parallelGateway首先必须成对出现,分别承担fork 和join 职责。 其次,在join时需要实现分布式锁接口:LockStrategy。第三,fork 默认是顺序遍历多个sequeceFlow,但是你如果需要使用并发fork功能的话,则需要实现该接口:ExecutorService。
大致了解一下标签的定义即可,最终这些片段都可以通过Camunda,定义好流程直接转化成xml文件
三、SmartEngine之Custom实操
无论是使用Custom 还是DataBase 模式,以下均是必须了解的知识。
- 第一步,要选择正确的SmartEngine 版本,将其添加到pom依赖中。
- 第二步,要实现
InstanceAccessor接口。 这个接口主要便于SmartEngine和Spring等IOC框架集成,获取各种微服务的bean。 SmartEngine 会根据流程定义中的smart:class属性值,在结合InstanceAccessor的实现类,去调用Delegation。值得一提的是,smart:class的属性值可以使className 或者 beanName,只要在逻辑上和InstanceAccessor的实现类保持一致即可。 - 第三步,完成SmartEngine初始化。在初始化时,一般要加载流程定义到应用中。 集群情况下,要注意流程定义的一致性(如果纯静态记载则无此类问题)。 在初始化时,可以根据需要定义Bean的加载优先级。
1、引入依赖
<dependency>
<groupId>com.alibaba.smart.framework</groupId>
<artifactId>smart-engine-extension-storage-custom</artifactId>
<version>3.0.0</version>
</dependency>2、典型的初始化代码如下
package com.ibuscloud.order.core.service.flow;
import com.alibaba.smart.framework.engine.SmartEngine;
import com.alibaba.smart.framework.engine.configuration.InstanceAccessor;
import com.alibaba.smart.framework.engine.configuration.ProcessEngineConfiguration;
import com.alibaba.smart.framework.engine.configuration.impl.DefaultProcessEngineConfiguration;
import com.alibaba.smart.framework.engine.configuration.impl.DefaultSmartEngine;
import com.alibaba.smart.framework.engine.exception.EngineException;
import com.alibaba.smart.framework.engine.service.command.RepositoryCommandService;
import com.alibaba.smart.framework.engine.util.IOUtil;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.annotation.Order;
import org.springframework.core.io.Resource;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import java.io.InputStream;
import static org.springframework.core.Ordered.LOWEST_PRECEDENCE;
/**
* @Author dotaer
* @Date 2023/4/30
*/
@Order(LOWEST_PRECEDENCE)
@Configuration
@ConditionalOnClass(SmartEngine.class)
public class SmartEngineAutoConfiguration implements ApplicationContextAware {
private ApplicationContext applicationContext;
@Bean
@ConditionalOnMissingBean
public SmartEngine constructSmartEngine() {
ProcessEngineConfiguration processEngineConfiguration = new DefaultProcessEngineConfiguration();
// 实现InstanceAccessor接口
processEngineConfiguration.setInstanceAccessor(new CustomInstanceAccessService());
SmartEngine smartEngine = new DefaultSmartEngine();
smartEngine.init(processEngineConfiguration);
// 加载流程定义
deployProcessDefinition(smartEngine);
return smartEngine;
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
private class CustomInstanceAccessService implements InstanceAccessor {
@Override
public Object access(String name) {
return applicationContext.getBean(name);
}
}
private void deployProcessDefinition(SmartEngine smartEngine) {
RepositoryCommandService repositoryCommandService = smartEngine
.getRepositoryCommandService();
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
try {
Resource[] resources = resolver.getResources("classpath*:/smart-engine/*.xml");
for (Resource resource : resources) {
InputStream inputStream = resource.getInputStream();
repositoryCommandService.deploy(inputStream);
IOUtil.closeQuietly(inputStream);
}
} catch (Exception e) {
throw new EngineException(e);
}
}
}
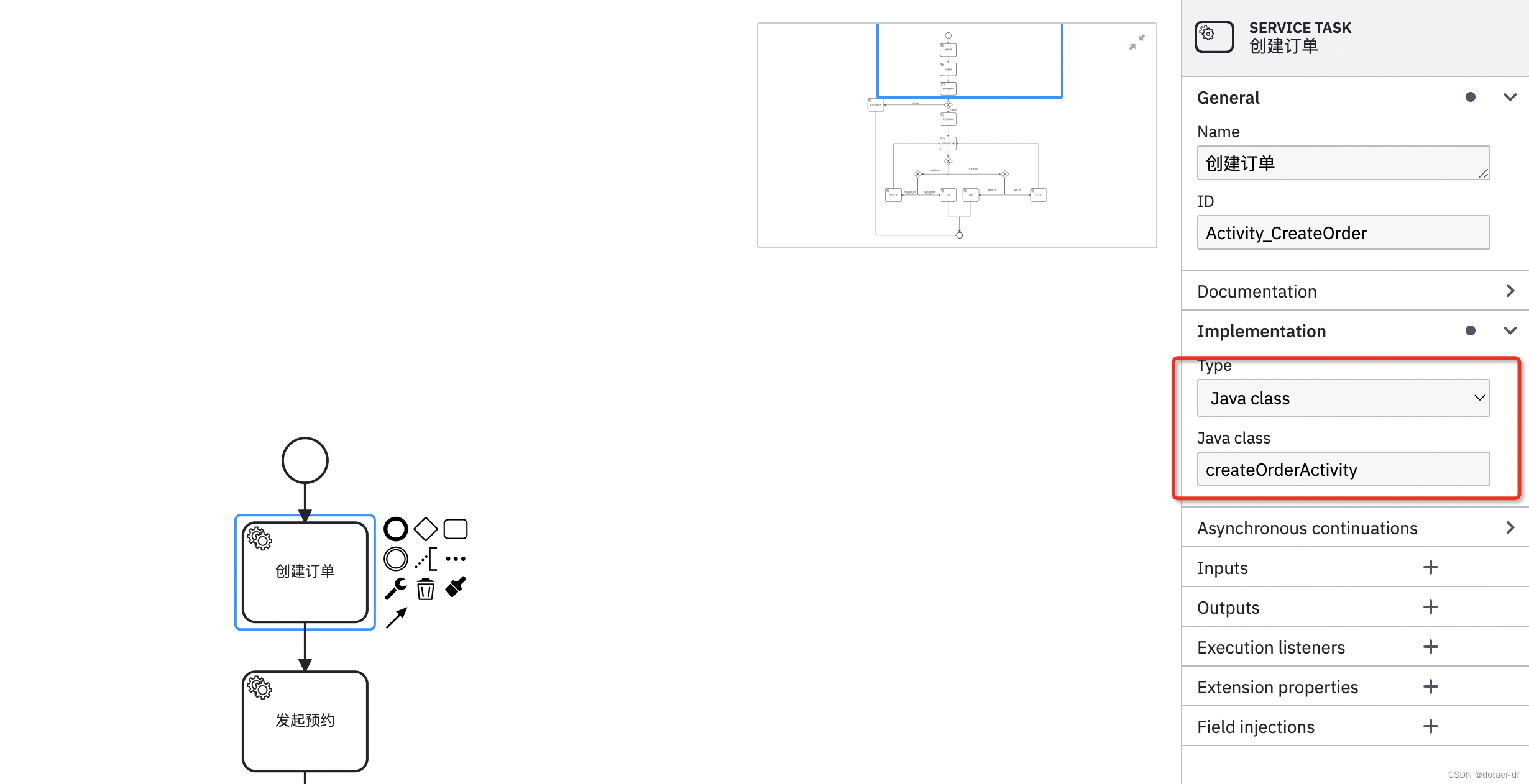
其中实现InstanceAccessor接口是为了让SmartEngine能在Spring容器中找到对应的流程节点bean。比如说通过Camunda有这样一个创建订单的节点,其bean的名称为createOrderActivity,你就可以定义一个类为CreateOrderActivity并实现JavaDelegation接口,那么SmartEngine 会根据流程定义中的smart:class属性值也就是对应的bean的名称createOrderActivity,在结合InstanceAccessor的实现类,去调用Delegation也就是这个bean,执行成功后,会自动的流转到下一个节点serviceTask节点(对应Camunda就是左上角为小齿轮的节点),遇到receiveTask(对应Camunda就是左上角为白色信封的节点)就会暂停。
3、节点如何流转以及流程实例存储问题
Custom 模式支持持久化流程实例数据和不持久化流程实例数据。 通常针对服务编排场景,是不需要持久化流程实例相关信息的;但是如果需要暂停后并恢复继续执行的也就是如果遇到receiveTask这样的节点,则需要考虑持久化流程实例到存储介质里。
在如下这个代码片段中,需要重点关注如下事项:
- Custom 模式必须在 try,finally块中使用
PersisterSession.create()和PersisterSession.destroySession()。 SmartEngine 内部执行时,会依赖该Session,从该session获取流程实例数据。 mockCreateOrder方法的内容:模拟启动流程实例。然后将流程实例序列化一个字符串后,存储到你持久化介质中。signal:模拟驱动业务流程。该过程和启动流程实例类似,都是将signal返回的流程实例序列化后更新到持久化介质中,然后在需要使用的时候,再取出来。BusinessProcess这个类由开发者自行决定,仅是个示例,服务编排场景忽略这种代码即可。
@Autowired
private SmartEngine smartEngine;
public ProcessInstance mockCreateOrder(Order order) {
// 1、流程上下文需要的参数
Map<String, Object> request = new HashMap<>();
request.put("order", order);
try {
PersisterSession.create();
ProcessCommandService processCommandService = smartEngine.getProcessCommandService();
// 其中processDefinitionId和processDefinitionVersion对应bpmn中的 process标签的id和versionTag
// 调用start则流程流转开始
ProcessInstance processInstance = processCommandService.start(processDefinitionId, processDefinitionVersion, request);
// 将流程实例介质更新到库中,方便后面取出
BusinessProcess businessProcess = new BusinessProcess();
// 唯一id
businessProcess.setUniqueId(order.getOrderNo());
businessProcess.setProcessInstance(InstanceSerializerFacade.serialize(processInstance));
myProcessInstacneService.updateProcessInstance(businessProcess);
return processInstance;
} catch (Exception e) {
log.error("初始化流程失败", e);
throw new RunTimeException("初始化流程失败");
} finally {
PersisterSession.destroySession();
}
}
public void signal(Long uniqueId, String activityId, Map<String, Object> map) {
try {
PersisterSession.create();
ExecutionQueryService executionQueryService = smartEngine.getExecutionQueryService();
ExecutionCommandService executionCommandService = smartEngine.getExecutionCommandService();
// 从存储介质中查询当前流程实例状态
BusinessProcess businessProcess = myProcessInstacneService.findById(uniqueId);
// 重新反序列化出来
ProcessInstance processInstance = InstanceSerializerFacade.deserializeAll(businessProcess.getSerializedProcessInstance());
PersisterSession.currentSession().setProcessInstance(processInstance);
// 判断当前节点是否应该是处在正确的节点上
List<ExecutionInstance> executionInstanceList = executionQueryService.findActiveExecutionList(processInstance.getInstanceId());
boolean found = false;
if (!CollectionUtils.isEmpty(executionInstanceList)) {
for (ExecutionInstance executionInstance : executionInstanceList) {
if (executionInstance.getProcessDefinitionActivityId().equals(activityId)) {
found = true;
// 执行signal方法进行 流转到下一个节点
ProcessInstance newProcessInstance = executionCommandService.signal(executionInstance.getInstanceId(), map);
// 同样的将流转后节点更新,方便后面取出
BusinessProcess businessProcess = new BusinessProcess();
// 唯一id
businessProcess.setUniqueId(uniqueId);
bizInstance.setProcessInstance(InstanceSerializerFacade.serialize(newProcessInstance));
myProcessInstacneService.updateProcessInstance(businessProcess);
}
}
if (!found) {
LOGGER.error("No active executionInstance found for businessInstanceId " + uniqueId + ",activityId " + activityId);
}
} else {
LOGGER.error("No active executionInstance found for businessInstanceId " + uniqueId + ",activityId " + activityId);
}
} finally {
PersisterSession.destroySession();
}
}其中序列化的的流程实例文本长这样:v1|4333,processDefinitionId:1.0.0,null,null,running|5033,null,WaitPayCallBackActivity,5133,true,|。 这个字符串的顺序依次是:序列化协议版本号,分隔符,流程实例,流程定义 id 和 version,父流程实例 id,父流程实例的执行实例 id,流程状态,分割符,(注释:后面是环节信息,可以有多个,用|分开),环节实例 id,环节实例 blockId(可忽略),执行实例 id,执行实例状态,分隔符
注意点:
- 节点之间流转所需要的上下文参数可放在 Map<String, Object> request = new HashMap<>();中,包括互斥网关所需要用到的条件,都需要从这个上下文中获取,调用start初始化或者调用signal携带进去即可。
- 所有ServiceTask节点会自动流转到下一节点,无须调用signal方法,直到遇到ReceiveTask这样的节点才会暂停,而ReceiveTask节点需调用signal方法才会流转到下一节点
- 所有流程节点流转每流转一次,需将新的流程实例存储到实例介质中,根据系统情况,选择合适的存储介质,以防丢失。
4、定义Delegation
@Component
@Slf4j
public class CreateOrderActivity implements JavaDelegation {
@Autowired
private OrderService orderService;
@Override
public void execute(ExecutionContext executionContext) {
Map<String, Object> request = executionContext.getRequest();
if (request != null && request.containsKey("order")) {
Order order = (Order) request.get("order");
maasOrderCoreService.createOrder(maasOrder);
log.info("create order {}", maasOrder);
} else {
log.error("Invalid request, no order", new IllegalArgumentException());
}
}
}这样调用processCommandService.start过后就会根据bpmn里面smart:class属性值找到这个bean进行执行,执行过后,自动的流转到下一个节点,直到遇到ReceiveTask等这样的节点才会暂停。大家可以根据自身业务去实现对应的JavaDelegation即可。
补充:
重要领域对象
- 部署实例:
DeploymentInstance,描述这个流程定义是谁发布的,当前处于什么状态。 - 流程定义:
ProcessDefinition, 描述一个流程有几个环节,之间的流转关系是什么样子的。 - 流程实例:
ProcessInstance,可以简单理解为我们常见的一个工单。 - 活动实例:
ActivityInstance,主要是描述流程实例(工单)的流转轨迹。 - 执行实例:
ExecutionInstance,主要根据该实例的状态,来判断当前流程处在哪个节点上。 - 任务实例:
TaskInstance,用来表示人工任务处理的.可以理解为一个需要人工参与处理的环节。 - 任务处理:
TaskAssigneeInstance,用来表示当前任务共有几个处理者。通常在代办列表中用到此实体。 - 变量实例:
VariableInstance,用来存储流程实例上下文。
关键类
ExecutionContext:getExecutionInstance()方法可以通过这个对象获得当前环节的id;getBaseElement()方法可以通过这个对象获得当前环节的id的流程定义配置;getRequest()方法可以获得业务请求参数;getResponse()方法设置返回值;getProcessDefinition()方法可以获得完成的流程定义;
参考链接:
SmartEngine UserGuide Chinese Version (中文版) · alibaba/SmartEngine Wiki · GitHub
![[大家的项目] 获取主机IP地址](https://img-blog.csdnimg.cn/img_convert/1dc783e0aba42b17b4dd105ea846d967.png)





![[java]云HIS运维运营分系统功能实现(springboot框架)](https://img-blog.csdnimg.cn/58586826632646e29303a6c1253334a7.png)