一、ShardingJDBC的核心流程
ShardingJDBC的核心流程主要分成六个步骤,分别是:SQL解析->SQL优化->SQL路由->SQL改写->SQL执行->结果归并,流程图如下:
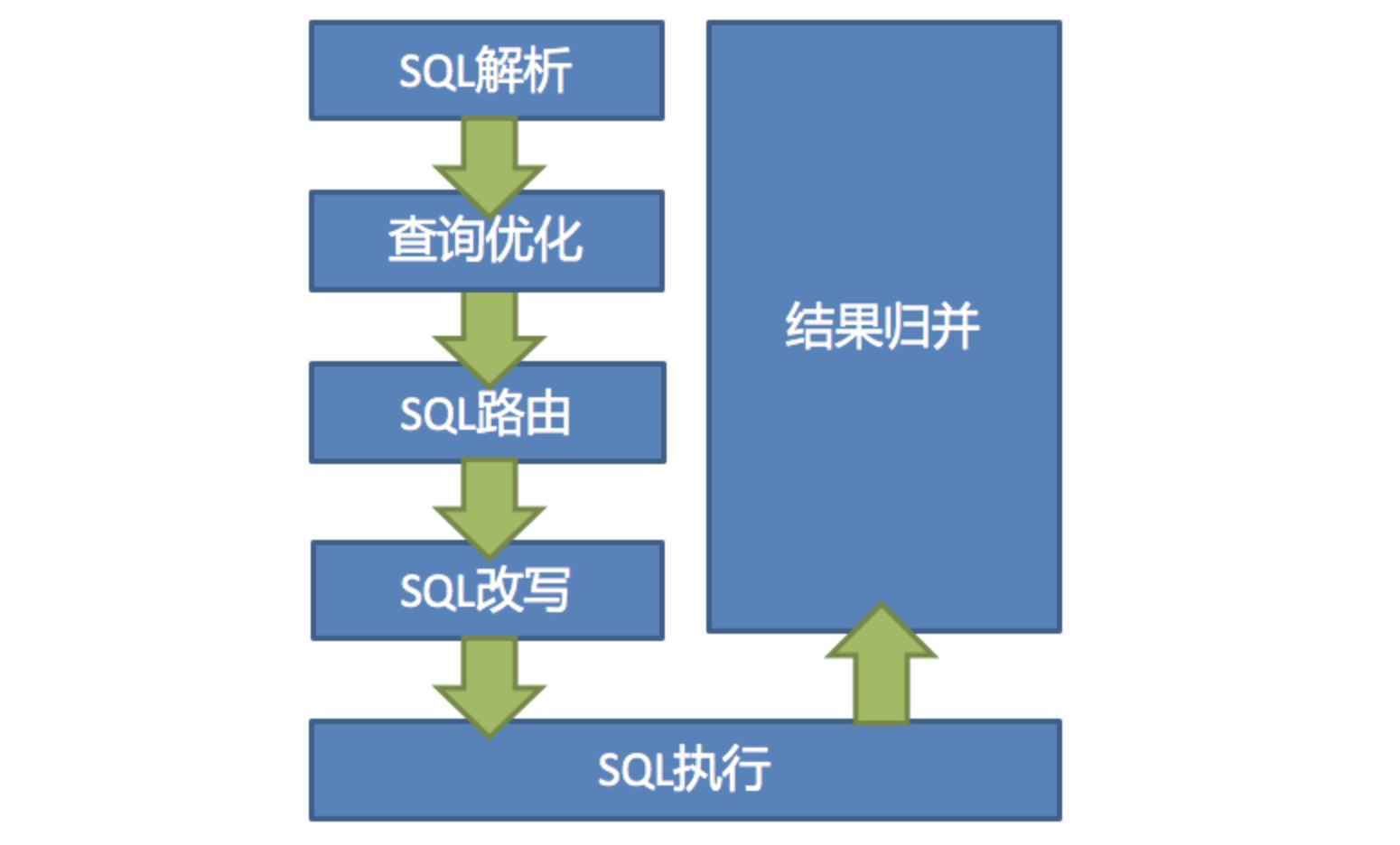
分为词法解析和语法解析。 先通过词法解析器将SQL拆分为一个个不可再分的单词。再使用语法解析器对SQL进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
SQL解析由ShardingJDBC的解析引擎负责处理
合并和优化分片条件,如OR等。
根据解析上下文匹配数据库和表的分片策略,并生成路由路径。 对于携带分片键的SQL,根据分片键的不同可以划分为单片路由(分片键的操作符是等号)、多片路由(分片键的操作符是IN)和范围路由(分片键的操作符是BETWEEN)。 不携带分片键的SQL则采用广播路由。
将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为正确性改写和优化改写。
SQL改写的主要场景有:
1、真实表名的改写:如查询逻辑表的SQL为:select * from user where user_id = 1000,需要改写成真实表的SQL:select * from user_0 where user_id = 1000
2、分页参数的改写:如两个真实表中分表存储数据为1、2、3、4;5、6、7、8;此时需要执行select * from user order by user_id limit 2,2 时,如果不改写的话,那么分别在两个真实表中取到的结果就是3、4和7、8,然后在合并结果之后得到的结果就是7和8,很显然数据是不对的,因为实际情况下取第二页的两条数据应该是3和4才对。所以需要将SQL改写成select * from user order by user_id limit 0,4。也就是说会取出前两页所有的数据,然后再内存中再进行排序取第二页的数据。(limit偏移量值越大,效率越低)
不过如果SQL仅仅路由到一个节点,那么此时就不需要进行分页参数的改写,避免从偏移量0开始扫描数据。
3、批量拆分:当进行批量操作时,比如IN操作,假设两个表根据user_id的奇偶数来分片,执行SQL为select * from user where user_id in (1,2,3,4).如果不进行拆分,就会让这个SQL再两个表中都执行,很显然筛选的数据就多了,性能就差了,虽然对于结果没有影响。
另外如果是批量插入操作时,就必须进行拆分,否则就会导致多个表中存在相同的数据了。
SQL执行通过执行引擎来处理,ShardingJDBC采用一套自动化的执行引擎,负责将路由和改写完成之后的真实SQL安全且高效发送到底层数据源执行。 它不是简单地将SQL通过JDBC直接发送至数据源执行;也并非直接将执行请求放入线程池去并发执行。它更关注平衡数据源连接创建以及内存占用所产生的消耗,以及最大限度地合理利用并发等问题。 执行引擎的目标是自动化的平衡资源控制与执行效率。
4.5.1、连接模式
首先从数据库连接上来分析,当一个SQL条件中包含了多个库多个表中的数据时,如果每个真实SQL都占用一个连接的话,很容易就导致数据库连接数不够用了,会严重影响其他SQL的执行。但是如果一个SQL解析了很多的真实SQL,如果都采用一个连接来处理的话,就无法达到并行的效果,比如一个SQL拆分成了10个真实SQL,一个连接串行处理的话就会导致一个线程串行执行10次数据库查询操作,很显然效率又会大大的降低。
所以ShardingJDBC提供了两种数据库连接模式供用户选择,分别是内存限制模式和连接数限制模式
内存限制模式是每个真实SQL都分配一个连接去执行实现SQL的并行执行,达到效率的最大化
连接数限制模式是每个库只会分配一个连接,分库的情况下会分配多个连接,分表的情况下只会分配一个连接串行执行
对于这两种模式ShardingJDBC还提供了自动化执行引擎来动态的选择使用哪种模式,根据不同的SQL特点选择最优的模式来执行。
不过用户可以通过配置maxConnectionSizePerQuery来设置一次查询操作最多可以分配多少个连接来限制连接数
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并。
ShardingSphere支持的结果归并从功能上分为遍历、排序、分组、分页和聚合5种类型,它们是组合而非互斥的关系。 从结构划分,可分为流式归并、内存归并和装饰者归并。流式归并和内存归并是互斥的,装饰者归并可以在流式归并和内存归并之上做进一步的处理。
由于从数据库中返回的结果集是逐条返回的,并不需要将所有的数据一次性加载至内存中,因此,在进行结果归并时,沿用数据库返回结果集的方式进行归并,能够极大减少内存的消耗,是归并方式的优先选择。
流式归并是指每一次从结果集中获取到的数据,都能够通过逐条获取的方式返回正确的单条数据,它与数据库原生的返回结果集的方式最为契合。遍历、排序以及流式分组都属于流式归并的一种。
内存归并则是需要将结果集的所有数据都遍历并存储在内存中,再通过统一的分组、排序以及聚合等计算之后,再将其封装成为逐条访问的数据结果集返回。
装饰者归并是对所有的结果集归并进行统一的功能增强,目前装饰者归并有分页归并和聚合归并这2种类型。
ShardingSphere对于分页查询进行了2个方面的优化。
首先,采用流式处理 + 归并排序的方式来避免内存的过量占用。由于SQL改写不可避免的占用了额外的带宽,但并不会导致内存暴涨。 与直觉不同,大多数人认为ShardingSphere会将1,000,010 * 2记录全部加载至内存,进而占用大量内存而导致内存溢出。 但由于每个结果集的记录是有序的,因此ShardingSphere每次比较仅获取各个分片的当前结果集记录,驻留在内存中的记录仅为当前路由到的分片的结果集的当前游标指向而已。 对于本身即有序的待排序对象,归并排序的时间复杂度仅为O(n),性能损耗很小。
其次,ShardingSphere对仅落至单分片的查询进行进一步优化。 落至单分片查询的请求并不需要改写SQL也可以保证记录的正确性,因此在此种情况下,ShardingSphere并未进行SQL改写,从而达到节省带宽的目的。
二、商户商家订单的分片实现
用户下单,生成一个订单,把用户id【商户用商户ID】作为路由key,对user_id取hash值然后对表的数量进行取模,得到对应需要路由的表,然后写入数据。

引入和 参考:
基于ShardingJDBC的分库分表_shardingjdbc分库分表join查询_毕业即失业吗的博客-CSDN博客
分库分表后路由策略设计 - 掘金