目录
0 如果你还不知道Libarchive是什么请一定要先看一下
1 简介
1.1 为什么实现Libarchive
1.2 到底都有谁在用呢?
1.3 Libarchive都有哪些功能
1.4 我们可以通过这些获取更多信息
1.5 如何贡献
2 Libarchive归档与压缩
3 Libarchive编译
4 Libarchive简单的入门
4.1 读取归档中的文件名
4.2 注册自己的函数
4.2.1 read / write / close callback
4.2.2 skip callback
4.2.3 seek callback
4.3 写入文件
4.4 在磁盘上构造对象
4.5 错误处理
现在网上好多好多Libarchive的源码包,可是却没有一个文章是去带你了解Libarchive的教程,所以这就导致很多人不知道Libarchive是一个什么东西,所以今天我们就来聊一下Libarchive到底是一个什么东西以及说是带你入门一下Libarchive,让你以后看到Libarchive会有一个基础的认识以及说是有一个自我学习的能力。
总览:Libarchive 是一个可以创建和读取多种不同流式归档格式的程序库,包含了最流行的 tar 格式变体、一些 cpio 格式,以及所有的 BSD 和 GNU ar 变体。bsdtar 是一个使用 libarchive 的 tar 实现。
0 如果你还不知道Libarchive是什么请一定要先看一下
我们今天所说的Libarchive是一个开源的C库,用于在各种格式的归档文件中读取和写入数据。它支持多种常见的存档格式,如tar、zip、7zip以及ISO映像等。libarchive还提供了对压缩、加密和数字签名等操作的支持,使用户可以在不同的存档格式之间进行转换和处理。由于其高度可移植性和灵活性,libarchive被广泛用于许多应用程序中,例如压缩工具、备份软件、虚拟化系统等。
1 简介
1.1 为什么实现Libarchive
大约在 2001 年的某个时间,邮件列表中出现了一些关于 FreeBSD 打包工具的辩论,辩论主要涉及两个相关的问题:
- 对打包工具来说什么是 正确 (right) 的格式?
- 为什么 FreeBSD 的打包工具比其他发行版的打包工具慢?
在仔细研究之后,Kientzle 认为 tar/gzip 和 tar/bzip2 依然是很好的格式,性能问题纯粹是实现的原因。

因此,Kientzle 开启了一个从 pkg_add 开始重写打包工具的项目,关键是这个项目是一个了解 tar/gzip 和 tar/bzip2 的库。他最终在 2003 年时完成了 libtarfile,并意识到许多核心的基础设施都要简单通用地处理其他格式,因此这个库被重命名为 libarchive。一次在 Kientzle 构建 libarchive 时,他意识到他早期测试套件更接近于一个 GNU tar 的完全 BSD 许可的替代品,即 bsdtar。FreeBSD 项目采用了 bsdtar 和 libarchive,并允许他继续在 FreeBSD 源码树中开发。大约在 2007 年,libarchive 被移植到其他平台,并将主要开发工作转移到了独立的仓库,刚开始在 GoogleCode,之后转到了 GitHub 直到今天。

1.2 到底都有谁在用呢?
-
操作系统
- freeBSD
- 2004 年 11 月发布的 FreeBSD 5.3 中首次包含 libarchive
- FreeBSD 6 起将 bsdtar 设置为默认的 tar 工具
- FreeBSD 8 起将 bsdcpio 设置为默认的 cpio 工具
- FreeBSD 8 起将 Kai Wang 的
ar和 Dag-Erling Smørgrav 的unzip标准化
- NetBSD
- 从 NetBSD 5.0 开始 libarchive 就是其一部分
- NetBSD 9.0 开始使用 bsdtar 和 bsdcpio 作为默认的系统工具
- MacOS
- 2009 的起 libarchive 就作为 MacOS 的一部分
- bsdtar 和 bsdcpio 也是 MacOS 的默认系统工具
- Windows
- Windows 10 insider build 17063 开始,libarchive 和 bsdtar 作为系统默认工具被提供
- freeBSD
-
包管理器
- Arch Linux 的 Pacman
- Void Linux 的 XBPS
- CRUX Linux 的 pkgutils
- Gentoo 和 Exherbo 的多格式包管理器 Paludis
- CMake
-
压缩软件和文件浏览器
- Tarsnap
- Springy 用于处理 TAR, PAX 和 CPIO 格式的文件
- Archivemount 用于挂载归档文件
- KDE 的 ark
更多的用户可以参见 LibarchiveUsers
1.3 Libarchive都有哪些功能
libarchive 支持读取多种不同的格式,包括 tar、pax、cpio、7zip、zip、xar、mtree、rar 以及 ISO 映像等;可以写入 tar、pax、cpio、7zip、zip、xar、mtree、ISO 以及 shar 等格式。更多格式可以查看文档。

在读取归档文件时,libarchive 有一个健壮的格式自动检测器用以识别归档文件的格式,也可以识别 gzip、bzip2、xz、lzip 以及多种流行的压缩算法,包括像 tar.gz 这样的归档、压缩组合。
libarchive 允许灵活地处理数据的来源和去处。有一个方便的包装器可以读取、写入数据到磁盘上的常规文件或内存中,也可以注册你自己的 IO 函数来读取、写入磁带设备、网络套接字或任何数据源的归档文件。libarchive 的内部 IO 模型是零拷贝设计的,在操作非常大的归档文件时,可以最小化拷贝数据,以获取最佳性能。
1.4 我们可以通过这些获取更多信息
- 官方网站
- 仓库
- Wiki
- 邮件列表
- 手册
- Issues
- PR
1.5 如何贡献
libarchive 欢迎大家贡献,贡献前请先阅读相关文档,以免造成不必要的麻烦:
- 贡献到 Libarchive
- 愿望单
- 内部资料
如果您无法帮助编写 C 代码,开发者们依然欢迎其他帮忙:
- 改进 Wiki 文档
- 在邮件列表中解决问题
- 随着 libarchive 的发展进行测试
2 Libarchive归档与压缩
一个归档文件可以分为两个部分,归档 (仅存储) 和压缩。通常将需要添加到压缩包的文件先归档为一个文件,再对这个文件进行压缩。
像 tar、7z、zip 等被 libarchive 称为格式的就是归档文件,这些格式规定了压缩包内文件怎么存储,怎么记录词条,等等信息。
压缩就是对这个已经归档的文件选用什么算法进行操作。像 lzma、xz、zstd 等被 libarchive 称为 filter 的就是压缩算法。
一般来说,压缩包就是格式与压缩算法的组合,像常见的 7zip,就是 7zip 格式与默认算法 lzma2 的组合,而有些 7zip 文件也会不进行压缩,也就是用 7zip 格式将待打包的文件归档在一个文件里。而 unix-like 世界中常见的 tar/gzip、tar/bzip2 等就是 tar 格式与 gz、bz2 算法的组合。

3 Libarchive编译
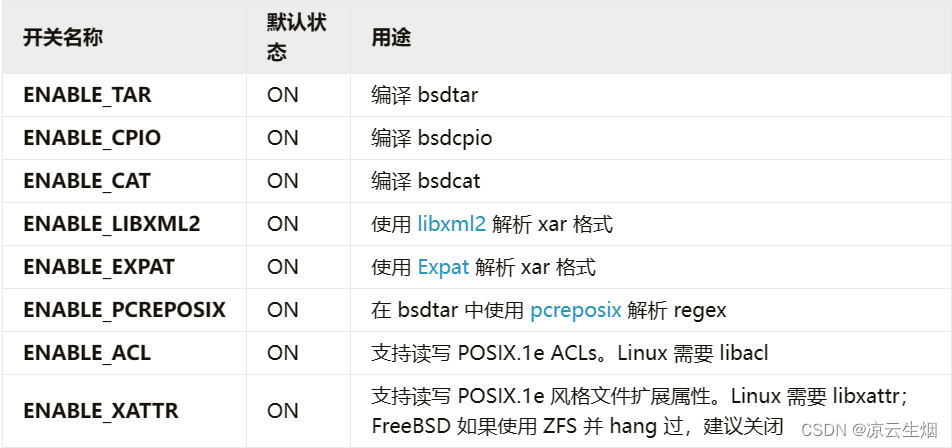
libarchive 用 format 和 filter 区分格式与压缩。格式通常只需要 libarchive 根据其文档实现就 okay。压缩由于算法基本都公开,因此有大量优秀的库来实现这些压缩算法,因此 libarchive 并不实现压缩算法。因此 libarchive 编译时有很多关于算法的开关
-
压缩算法开关

- 加密库开关

- 其他开关
-
编译变量
- POSIX_REGEX_LIB,使用哪个库解析 POSIX 正则表达式
AUTO(Default)LIBCLIBREGEX
- ENABLE_SAFESEH
- WINDOWS_VERSION
- POSIX_REGEX_LIB,使用哪个库解析 POSIX 正则表达式
4 Libarchive简单的入门
Libarchive 使用时需要两个对用户透明的基础类型对象:struct archive 指针和 struct archive_entry 指针。在 libarchive 中 archive 对象的生命周期是十分简单的:
- 使用
archive_xxx_new创建一个对象 - 使用
support或set对 archive 对象进行配置- support 允许库决定何时启用功能
- set 无条件的启用功能
open打开一个数据源- 迭代读取内容:从 entry 中获取 archive 词条的 header 信息和数据。
- 结束时,使用
close写入信息,free则会释放 archive 对象
4.1 读取归档中的文件名
struct archive *a = archive_read_new();
archive_read_support_filter_all(a);
archive_read_support_format_all(a);
if (archive_read_open_filename(a, "archive.tar", 10240) != ARCHIVE_OK) {
exit(EXIT_FAILURE);
}
struct archive_entry *entry;
while (archive_read_next_header(a, &entry) == ARCHIVE_OK) {
printf("%s\n", archive_entry_pathname(entry));
archive_read_data_skip(a); // Note 2
}
if (archive_read_free(a) != ARCHIVE_OK) {
exit(EXIT_FAILURE);
}
代码开始时的 support_filter_all 与 support_format_all 就是 libacrhive 所说的自动推导数据源的压缩算法与格式。
这里使用的 open 是 filename,即打开一个磁盘上的文件作为数据源,另外 libarchive 还可以对内存 (memory) 进行读写,或文件指针 (FILE*)、文件描述符 (fd) 进行读写。
archive_read_open_memory(a, buff, sizeof(buff));
archive_read_open_FILE(a, fileptr);
archive_read_open_fd(a, fd, 10240);
之后在 loop 中使用 next_header 来获取归档中的文件信息,也就是之前说到的迭代读取内容。该函数可以将目前待读取的文件信息写入到 entry 结构中,以便用户之后进行操作。如 archive_entry_pathname 获取文件名称。实际上 archive_read_data_skip 并不需要调用,这里作为不对数据进行任何处理的标志。如果没有使用数据,在 next_header 中 libarchive 会自动调用该函数。
最后调用了 archive_read_free 来释放掉 archive 结构,这也会自动关闭已经打开的数据源。如果你还有其他用途,可以使用 close 关闭打开的数据源,并重新打开新的数据源,防止重复分配释放 archive 以获得更高的性能。另外显式调用 close 有一个好处是你可以获取到错误状态,而 free 中隐式调用 close 则用户无法接收到 close 的状态。
另外需要注意的是,只有从磁盘上打开的数据源,libarchive 会真正的 close 掉,内存、文件指针以及文件描述符,libarchive 并不会 close 它们,因为这是不属于 libarchive 的资源,需要调用者自己承担这些资源的释放。但是也不能因为 libarchive 不会释放它们而不调用 close 函数,因为该函数中会释放一些 libarchive 自己申请的一些资源。

4.2 注册自己的函数
4.2.1 read / write / close callback
libarchive 提供了更低级的 open 函数,该函数接收 3 个回调函数和你定义的数据类型:
- 一个打开数据源的 open 回调,不过这是个遗留参数,不需要也不应该被使用
- 一个 read / write 的回调函数
- 一个 close 的回调函数
因此你可以定制一个如从 HTTP 中读取归档文件的实现。
回调函数应该遵循基本的 libarchive 约定:
- open 与 close 函数在成功时应该返回
ARCHIVE_OK(0),而失败时应该返回一个负数。通常来说使用ARCHIVE_WARN表示有问题的情况,而ARCHIVE_FATAL表示不能恢复或不能重试的问题。 - read 与 write 返回成功读取、写入的字节数,0 表示 EOF,出现错误与上一回调函数一样。read 回调还会返回一个指向读取的数据的指针。
- Libarchive 不在意数据的块大小,在访问下一个块前会完成当前块,因此回调函数中不需要处理这些块。唯一要求时块的大小必须不为 0,因为 0 字节大小表示 EOF。
ssize_t myread(struct archive *a, void *client_data, const void **buff) {
struct mydata *mydata = (struct mydata *) client_data;
*buff = mydata->buff;
return (read(mydata->fd, mydata->buff, 1024));
}
int myclose(struct archive *a, void *client_data) {
struct mydata *mydata = (struct mydata *) client_data;
if (mydata->fd > 0) {
close(mydata->fd);
}
free(mydata);
return (ARCHIVE_OK);
}
// in main
struct mydata mydata = {
.fd = open(name, O_RDONLY),
};
archive_read_open(a, &mydata, NULL, myread, myclose);
4.2.2 skip callback
Libarhive 提供了和 open 类似的函数 open2,额外提供了 skip 回调函数。一般来说时用不到该回调的,但有时 libarchive 可以利用该回调优化某些格式的读取,快速搜索整个正文条目。当然也必须满足一些必要条件:
- 必须返回实际跳过的字节数,如果不能跳过则应该返回一个负数
- 可以跳过比请求更少的字节,但不能跳过超过请求的字节数
- 只有向前 (正向) 跳过才被允许
- 如果未提供 skip 回调或失败,libarchive 将调用 read() 简单地忽略不需要的数据
4.2.3 seek callback
Libarchive 3.0 支持了 seek 回调,该回调用于读取不适合流式传输的格式,如 7zip 和某些 zip 的变种。

4.3 写入文件
struct archive *a = archive_write_new();
archive_write_add_filter_gzip(a); // gzip compression
archive_write_add_format_pax_restricted(a); // tar format (pax extensions)
// archive_write_add_format_ustar(a); // tar format (POSIX.1-1988)
// archive_write_add_format_gnutar(a); // tar format (GNU extensions)
archive_write_open_filename(a, outname);
char buff[8192];
while (*filelist) {
struct stat st;
stat(*filelist, &st);
struct archive_entry *entry = archive_entry_new();
archive_entry_set_pathname(entry, *filelist);
archive_entry_set_size(entry, st.st_size);
archive_entry_set_filetype(entry, AE_IFREG);
archive_entry_set_perm(entry, 0644);
archive_write_header(a, entry);
int fd = open(*filename, O_RDONLY);
ssize_t len = read(fd, buff, sizeof(buff));
while (len > 0) {
archive_write_data(a, buff, len);
len = read(fd, buff, sizeof(buff));
}
close(fd);
archive_entry_free(entry);
filename++;
}
archive_write_free(a);
将文件加入归档时,每次都会申请一份新的 entry 结构,而在处理下一个文件前会释放掉它。如果为了更高的性能,可以不释放掉该结构,而是采用 archive_entry_clear 来清除掉其中的数据,以安全地复用该结构。
对于写入归档的 entry 来说,文件的大小、类型和路径是必要属性。如果比较懒也可以使用 archive_entry_copy_stat 从文件的 struct stat 中来拷贝属性,也包括 ACL 与 xattr。拷贝属性这个函数也可以在 Windows 下使用。

4.4 在磁盘上构造对象
Libarchive 提供了一个 archive_write_disk 这样的直接在磁盘上构建文件对象的方式,而不是将文件构造在归档中。并且对于如常规文件 (regular)、目录 (directory)、符号链接 (symlink)、硬链接 (hard link) 等不同的磁盘对象都可以正确处理。
struct archive *a = archive_write_disk_new();
archive_write_disk_set_options(a, ARCHIVE_EXTRACT_TIME);
struct archive_entry *entry = archive_entry_new();
archive_entry_set_pathname(entry, "my_file.txt");
archive_entry_set_filetype(entry, AE_IFREG);
archive_entry_set_size(ae, 5);
archive_entry_set_mtime(ae, 123456789, 0);
archive_write_header(a, entry);
archive_write_data(a, "abcde", 5);
archive_write_finish_entry(a);
archive_write_free(a);
archive_entry_free(entry);
如果在 entry 中使用 archive_entry_set_size 设置了大小的话,写入磁盘将会强制使用该大小。如果对数据实际的写入 archive_write_data 大小多于 entry 中设置的大小,那会将后面的数据强制截取掉;如果不足 entry 设置的大小的话,那也会填充 0 补齐文件大小。
虽然可以处理不同的磁盘对象,但是对于符号链接和硬链接还是需要特殊的操作:
- 符号链接需要设置文件类型为
AE_IFLNK并使用archive_entry_set_symlink - 硬链接同样需要使用
archive_entry_set_hardlink。调用了该函数的话,常规文件类型会被忽略;如果设置了大小,那么需要写入文件数据,如果不希望覆盖文件内容则不要设置硬链接大小。
4.5 错误处理
-
ARCHIVE_EOF 只会在
archive_read_data到达数据结尾时,或archive_read_next_header词条到达归档文件末尾时,被返回。 -
ARCHIVE_OK 在操作成功时被返回
-
ARCHIVE_WARN 在操作完成并有些问题时返回。你可以将这个问题报告给用户,
archive_error_string可以获取到对应的字符串信息,而archive_errno可以返回关联的系统 errno 值。(并非所有错误都有系统调用引起,因此 archive_errno 并不总是返回有效值) -
ARCHIVE_FAILED 在操作失败时返回。通常来说该状态意味着目前的词条无法再进行下一步操作。比如写不支持的归档格式。通常恢复的手段就是操作下一个词条。
-
ARCHIVE_FATAL 通常在 archive 对象无法使用时返回,典型原因就是 IO 错误或内存分配失败。通常你需要调用
archive_write_free来释放掉这个对象。
通常一些极端情况下 libarchive 会调用 abort 终止程序,这通常只发生 libarchive 的内部一致性检查检测到自身存在严重错误时才会发生。