一、需求分析
根据之前做训练的模型,对不同等级的标准样卡进行测试
测试样本有48张,其中包括起球个数、起球总面积、起球最大面积、起球平均面积、对比度、光学体积六个指标,最终确定出织物的等级
数据集fiber.csv大致结构如下:
(数据集是我自己测试收集的,这里就不公开分享了,个人数据,理解万岁)

csv格式注意事项:
N,S,Max_s,Aver_s,C,V,Grade最后没有空格
27,111542.5,38299.5,4131.2,31.91,3559537.61,1(空格)1后面有个空格,要注意!!!
| 变量 | 含义 |
|---|---|
| N | 起球个数 |
| S | 起球总面积 |
| Max_s | 起球最大面积 |
| Aver_s | 起球平均面积 |
| C | 对比度 |
| V | 光学体积 |
| Grade | 最终评定等级 |
二、尝试多种方法去实现预测等级评定
1、导包
pip install scikit-learn 安装sklearn相关包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import BernoulliNB
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
from sklearn.svm import LinearSVC
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
2、读取展示数据集
fiber = pd.read_csv("./fiber.csv")
fiber.head(15)
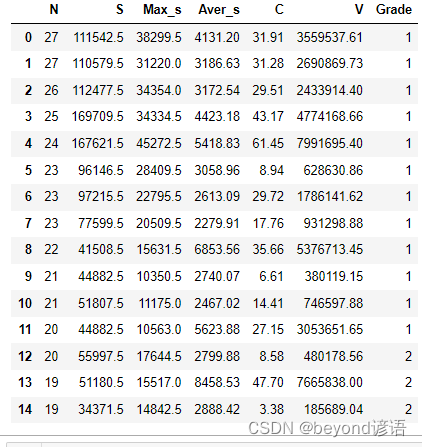
print(fiber)
"""
N S Max_s Aver_s C V Grade
0 27 111542.5 38299.5 4131.20 31.91 3559537.61 1
1 27 110579.5 31220.0 3186.63 31.28 2690869.73 1
......
47 9 33853.0 6329.0 3761.44 41.17 1393863.42 4
"""
3、划分数据集
最后一列为结果,其余的六个因素为自变量
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
将数据集分为验证集和测试集两部分
random_state随机数种子,保证每次分割训练集和测试集都相同
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=0)
查看下shape值
训练集36个,测试集12个,总共也就48个数据
print(X_test.shape) #(36, 6)
print(y_train.shape) #(36,)
print(X_test.shape) #(12, 6)
4、不同算法拟合
①K近邻算法,KNeighborsClassifier()
n_neighbors:选取最近的点的个数
通过这4个数据来对其他的数据进行拟合
knn = KNeighborsClassifier(n_neighbors=4)
对训练集进行训练拟合
knn.fit(X_train,y_train)
对测试集X_test进行预测,得到预测结果y_pred
y_pred = knn.predict(X_test)
预测结果y_pred和正确的答案y_test进行对比,求均值mean,看下正确率accuracy
accuracy = np.mean(y_pred==y_test)
print(accuracy)
也可以看下最终的得分
score = knn.score(X_test,y_test)
print(score)
随便生成一条数据对模型进行测试
16,18312.5,6614.5,2842.31,25.23,1147430.19,2
最终的等级为2

test = np.array([[16,18312.5,6614.5,2842.31,25.23,1147430.19]])
prediction = knn.predict(test)
print(prediction)
"""
[2]
"""
这是从训练集中抽取的,实际肯定不能这样干,这里只是在进行测试而已。
K近邻算法完整代码
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
fiber = pd.read_csv("./fiber.csv")
# 划分自变量和因变量
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
#划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=0)
knn = KNeighborsClassifier(n_neighbors=4)
knn.fit(X_train,y_train)
y_pred = knn.predict(X_test)#模型预测结果
accuracy = np.mean(y_pred==y_test)#准确度
score = knn.score(X_test,y_test)#得分
print(accuracy)
print(score)
#测试
test = np.array([[16,18312.5,6614.5,2842.31,25.23,1147430.19]])#随便找的一条数据
prediction = knn.predict(test)#带入数据,预测一下
print(prediction)
②逻辑回归算法,LogisticRegression()
实例化逻辑回归对象
lr = LogisticRegression()
将训练集传入,进行训练拟合
lr.fit(X_train,y_train)#模型拟合
对测试集X_test进行预测,得到预测结果y_pred
y_pred = lr.predict(X_test)#模型预测结果
预测结果y_pred和正确的答案y_test进行对比,求均值mean,看下正确率accuracy
accuracy = np.mean(y_pred==y_test)
print(accuracy)
也可以看下最终的得分
score = lr.score(X_test,y_test)
print(score)
随便生成一条数据对模型进行测试
20,44882.5,10563,5623.88,27.15,3053651.65,1
最终的等级为1

test = np.array([[20,44882.5,10563,5623.88,27.15,3053651.65]])#随便找的一条数据,正确等级为1
prediction = lr.predict(test)#带入数据,预测一下
print(prediction)
"""
[1]
"""
这是从训练集中抽取的,实际肯定不能这样干,这里只是在进行测试而已。
逻辑回归完整代码
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
fiber = pd.read_csv("./fiber.csv")
# 划分自变量和因变量
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
#划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=0)
lr = LogisticRegression()
lr.fit(X_train,y_train)#模型拟合
y_pred = lr.predict(X_test)#模型预测结果
accuracy = np.mean(y_pred==y_test)#准确度
score = lr.score(X_test,y_test)#得分
print(accuracy)
print(score)
test = np.array([[20,44882.5,10563,5623.88,27.15,3053651.65]])#随便找的一条数据
prediction = lr.predict(test)#带入数据,预测一下
print(prediction)
③线性支持向量机 ,LinearSVC()
实例化线性支持向量机对象
lsvc = LinearSVC()
将训练集传入,进行训练拟合
lsvc.fit(X_train,y_train)#模型拟合
对测试集X_test进行预测,得到预测结果y_pred
y_pred = lsvc.predict(X_test)#模型预测结果
预测结果y_pred和正确的答案y_test进行对比,求均值mean,看下正确率accuracy
accuracy = np.mean(y_pred==y_test)
print(accuracy)
也可以看下最终的得分
score = lsvc.score(X_test,y_test)
print(score)
随便生成一条数据对模型进行测试
20,55997.5,17644.5,2799.88,8.58,480178.56,2
最终的等级为2

test = np.array([[20,55997.5,17644.5,2799.88,8.58,480178.56]])#随便找的一条数据
prediction = lsvc.predict(test)#带入数据,预测一下
print(prediction)
"""
[2]
"""
这是从训练集中抽取的,实际肯定不能这样干,这里只是在进行测试而已。
线性支持向量机完整代码
from sklearn.svm import LinearSVC
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
fiber = pd.read_csv("./fiber.csv")
# 划分自变量和因变量
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
#划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=0)
lsvc = LinearSVC()
lsvc.fit(X_train,y_train)#模型拟合
y_pred = lsvc.predict(X_test)#模型预测结果
accuracy = np.mean(y_pred==y_test)#准确度
score = lsvc.score(X_test,y_test)#得分
print(accuracy)
print(score)
test = np.array([[20,55997.5,17644.5,2799.88,8.58,480178.56]])#随便找的一条数据
prediction = lsvc.predict(test)#带入数据,预测一下
print(prediction)
④支持向量机,SVC()
实例化支持向量机对象
svc = SVC()
将训练集传入,进行训练拟合
svc.fit(X_train,y_train)#模型拟合
对测试集X_test进行预测,得到预测结果y_pred
y_pred = svc.predict(X_test)#模型预测结果
预测结果y_pred和正确的答案y_test进行对比,求均值mean,看下正确率accuracy
accuracy = np.mean(y_pred==y_test)
print(accuracy)
也可以看下最终的得分
score = svc.score(X_test,y_test)
print(score)
随便生成一条数据对模型进行测试
23,97215.5,22795.5,2613.09,29.72,1786141.62,1
最终的等级为1

test = np.array([[23,97215.5,22795.5,2613.09,29.72,1786141.62]])#随便找的一条数据
prediction = svc.predict(test)#带入数据,预测一下
print(prediction)
"""
[1]
"""
这是从训练集中抽取的,实际肯定不能这样干,这里只是在进行测试而已。
支持向量机完整代码
from sklearn.svm import SVC
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
fiber = pd.read_csv("./fiber.csv")
# 划分自变量和因变量
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
#划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=0)
svc = SVC(gamma='auto')
svc.fit(X_train,y_train)#模型拟合
y_pred = svc.predict(X_test)#模型预测结果
accuracy = np.mean(y_pred==y_test)#准确度
score = svc.score(X_test,y_test)#得分
print(accuracy)
print(score)
test = np.array([[23,97215.5,22795.5,2613.09,29.72,1786141.62]])#随便找的一条数据
prediction = svc.predict(test)#带入数据,预测一下
print(prediction)
⑤决策树,DecisionTreeClassifier()
发现没,前四个方法步骤几乎都是一样的,只不过实例化的对象不同,仅此而已,至此就不再赘述了。
随便生成一条数据对模型进行测试
11,99498,5369,9045.27,28.47,3827588.56,4
最终的等级为4

决策树完整代码
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
fiber = pd.read_csv("./fiber.csv")
# 划分自变量和因变量
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
#划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=0)
dtc = DecisionTreeClassifier()
dtc.fit(X_train,y_train)#模型拟合
y_pred = dtc.predict(X_test)#模型预测结果
accuracy = np.mean(y_pred==y_test)#准确度
score = dtc.score(X_test,y_test)#得分
print(accuracy)
print(score)
test = np.array([[11,99498,5369,9045.27,28.47,3827588.56]])#随便找的一条数据
prediction = dtc.predict(test)#带入数据,预测一下
print(prediction)
⑥高斯贝叶斯,GaussianNB()
随便生成一条数据对模型进行测试
14,160712,3208,3681.25,36.31,1871275.09,3
最终的等级为3

高斯贝叶斯完整代码
from sklearn.naive_bayes import GaussianNB
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
fiber = pd.read_csv("./fiber.csv")
# 划分自变量和因变量
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
#划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=0)
gnb = GaussianNB()
gnb.fit(X_train,y_train)#模型拟合
y_pred = gnb.predict(X_test)#模型预测结果
accuracy = np.mean(y_pred==y_test)#准确度
score = gnb.score(X_test,y_test)#得分
print(accuracy)
print(score)
test = np.array([[14,160712,3208,3681.25,36.31,1871275.09]])#随便找的一条数据
prediction = gnb.predict(test)#带入数据,预测一下
print(prediction)
⑦伯努利贝叶斯,BernoulliNB()
随便生成一条数据对模型进行测试
18,57541.5,10455,2843.36,30.68,1570013.02,2
最终的等级为2

伯努利贝叶斯完整代码
from sklearn.naive_bayes import BernoulliNB
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
fiber = pd.read_csv("./fiber.csv")
# 划分自变量和因变量
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
#划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=0)
bnb = BernoulliNB()
bnb.fit(X_train,y_train)#模型拟合
y_pred = bnb.predict(X_test)#模型预测结果
accuracy = np.mean(y_pred==y_test)#准确度
score = bnb.score(X_test,y_test)#得分
print(accuracy)
print(score)
test = np.array([[18,57541.5,10455,2843.36,30.68,1570013.02]])#随便找的一条数据
prediction = bnb.predict(test)#带入数据,预测一下
print(prediction)
⑧多项式贝叶斯,MultinomialNB()
随便生成一条数据对模型进行测试
9,64794,5560,10682.94,38.99,3748367.45,4
最终的等级为4

多项式贝叶斯完整代码
from sklearn.naive_bayes import MultinomialNB
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
fiber = pd.read_csv("./fiber.csv")
# 划分自变量和因变量
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
#划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=0)
mnb = MultinomialNB()
mnb.fit(X_train,y_train)#模型拟合
y_pred = mnb.predict(X_test)#模型预测结果
accuracy = np.mean(y_pred==y_test)#准确度
score = mnb.score(X_test,y_test)#得分
print(accuracy)
print(score)
test = np.array([[9,64794,5560,10682.94,38.99,3748367.45]])#随便找的一条数据
prediction = mnb.predict(test)#带入数据,预测一下
print(prediction)
最终通过调节参数以及优化,确定使用决策树对本样本进行等级预测
5、模型保存与加载
这里以决策树算法为例
训练完成之后的模型通过joblib.dump(dtc, './dtc.model')进行保存
dtc为模型实例化对象
./dtc.model为保存模型名称和路径
通过dtc_yy = joblib.load('./dtc.model')加载模型
完整代码
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import joblib
fiber = pd.read_csv("./fiber.csv")
# 划分自变量和因变量
X = fiber.drop(['Grade'], axis=1)
Y = fiber['Grade']
#划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=0)
dtc = DecisionTreeClassifier()
dtc.fit(X_train,y_train)#模型拟合
joblib.dump(dtc, './dtc.model')#保存模型
y_pred = dtc.predict(X_test)#模型预测结果
accuracy = np.mean(y_pred==y_test)#准确度
score = dtc.score(X_test,y_test)#得分
print(accuracy)
print(score)
dtc_yy = joblib.load('./dtc.model')
test = np.array([[11,99498,5369,9045.27,28.47,3827588.56]])#随便找的一条数据
prediction = dtc_yy.predict(test)#带入数据,预测一下
print(prediction)
保存的模型如下: