侯捷 C++八部曲笔记汇总 - - - 持续更新 ! ! !
一、C++ 面向对象高级开发
1、C++面向对象高级编程(上)
2、C++面向对象高级编程(下)
二、STL 标准库和泛型编程
1、分配器、序列式容器
2、关联式容器
3、迭代器、 算法、仿函数
4、适配器、补充
三、C++ 设计模式
四、C++ 新标准
五、C++ 内存管理机制
六、C++ 程序的生前和死后
二、C++、STL标准模板库和泛型编程 ——适配器、补充 (侯捷)
- 适配器(Adapters)
- 容器适配器(Container Adapters)
- 仿函数适配器(Functor Adapters)
- bind2nd(绑定第二实参)
- not1
- bind(新型适配器)
- 迭代器适配器(Iterator Adapters)
- reverse_iterator
- inserter
- X适配器
- ostream_iterator
- istream_iterator
- 补充
- Hash Function
- tuple
- type traits
- cout
- movable
使用一个东西,却不明白它的道理,不高明!—— 林语堂
阶段学习
使用C++标准库
认识C++标准库(胸中自有丘壑!)
良好使用C++标准库
扩充C++标准库
所谓 Generic Programming (GP,泛型编程),就是使用 template (模板)为主要工具来编写程序。
-
GP是将datas和methods分开来;Containers和Algorithms可各自闭门造车﹐其间以Iterator连通即可·Algorithms通过Iterators确定操作范围﹐也通过Iterators取用Container元素。
-
OOP(Object-Oriented Programming),企图将datas和methods关联在一起。
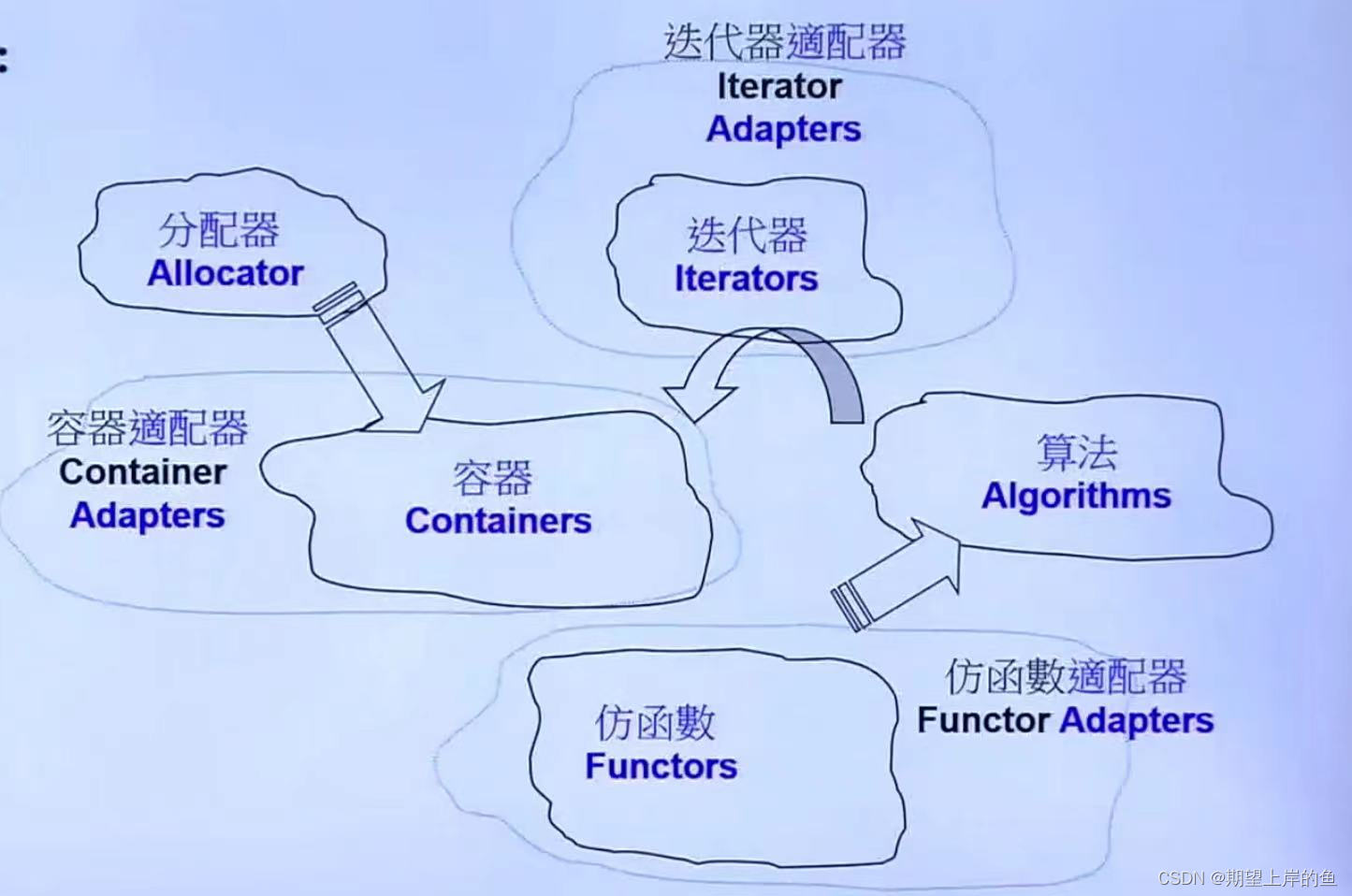
C++标准模板库Standard Template 最重要的六大部件(Components):容器、算法、仿函数、迭代器、适配器、分配器
- 容器(
Containers)是class template - 算法(
Algorithms)是function template(其内最终涉及元素本身的操作,无非就是比大小!) - 迭代器(
Iterators)是class template - 仿函数(
Functors)是class template - 适配器(
Adapters)是class template - 分配器(
Allocators)是class template
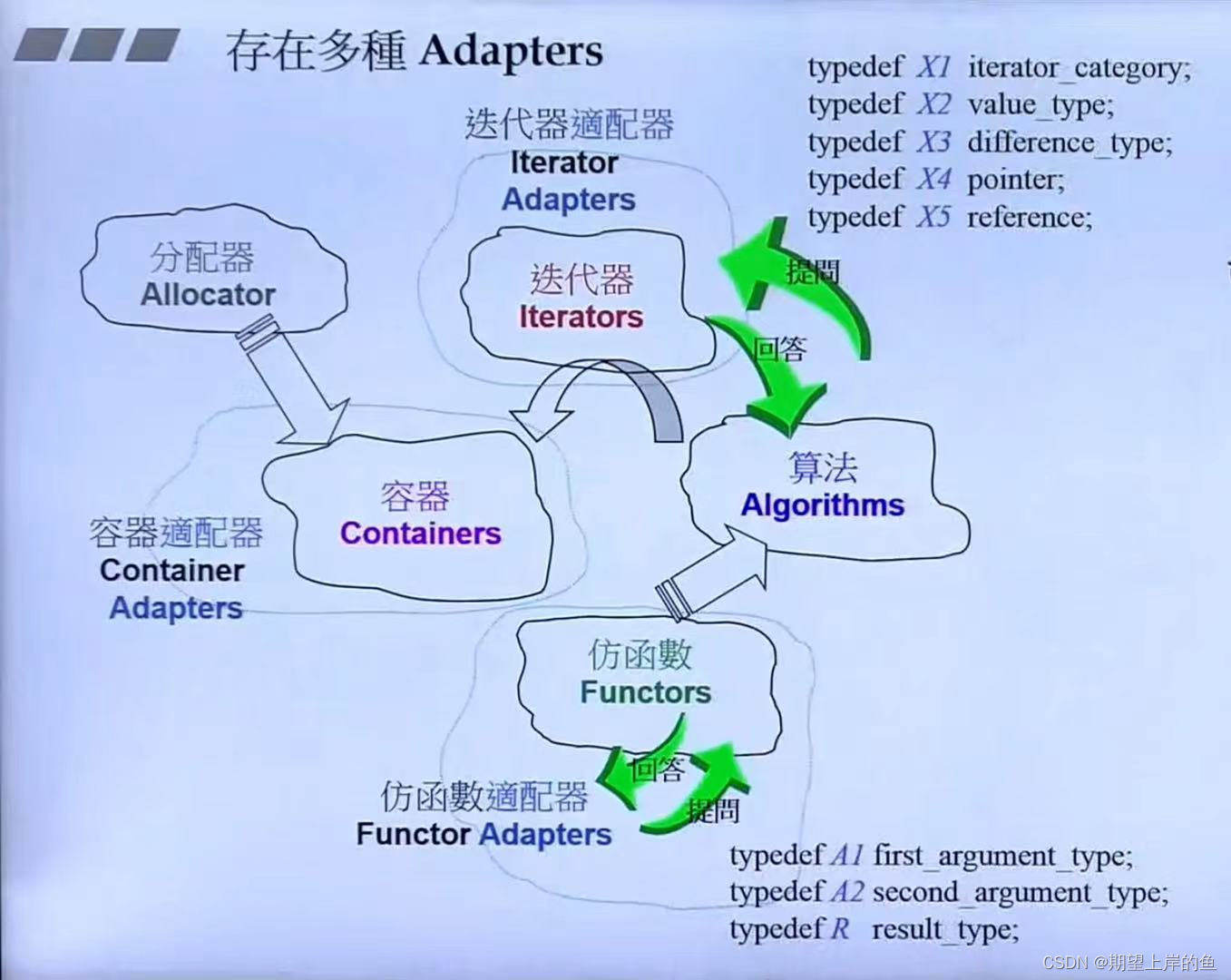
关系图:
适配器(Adapters)
可以把它理解为改造器,它要去改造一些东西;也可以理解为实现换肤功能。
已经存在的东西,改接口,改函数名等。。。
实现适配,可以使用继承(is a)、复合(has a) 的两种方式实现。
共性:STL使用 复合(has a) 来实现适配!
容器适配器(Container Adapters)
例如:stack和queue
具体定义查看:序列式容器的stack和queue容器
- 只使用一部分以及改接口,改函数名等。。。
- 把 复合(内涵) 的东西换一个风貌换一种风格出来!
仿函数适配器(Functor Adapters)
bind2nd(绑定第二实参)
把东西记起来,以备后面使用!
可以看到下面的这个例子,使用算法count_if:
- 第三个参数是一个
predicate,也就是判断条件,有一个仿函数对象less<int>(),但是他被仿函数适配器bind2nd(将less的第二个参数绑定为40)和not1(取反)修饰,从而实现判断条件为是否小于40。

bind2nd调用binder2nd:
- 图上灰色的东西就是仿函数适配器和仿函数之间的问答!
- 这里就体现了仿函数为什么要继承适合的
unary_function或者binary_function等类的原因!
- 这里就体现了仿函数为什么要继承适合的
- 还有一个细节:适配器适配之后的仿函数也能够继续被适配:
- 所以适配器要继承
unary_function或者binary_function等类,这样才能回答另外一个适配器的问题。 - 问 bianry_fucntion 三个参数
first_argument_type、second_argument_type、result_type。 - 提问前面都要加上
typename,是为了让编译通过!
- 所以适配器要继承
- 所以,仿函数必须能够回答适配器的问题,这个仿函数才是可适配的!
相对绑定第二实参,绑定第一实参为
bind1st
not1
对一个Predicate取反。
not1是构造一个与谓词结果相反的一元函数对象。not2是构造一个与谓词结果相反的二元函数对象。
一层套一层,像乐高积木一样!

bind(新型适配器)
替换了一些过时(bind1st、bind2st)的仿函数适配器!

std::bind 可以绑定:
functionsfunction objectsmember functions,_1(占位符号)必须是某个object地址。data members,_1必须是某个object地址。
返回一个function object ret。调用ret相当于调用上述的1,2,3或者相当于取出4.
示例:
// bind example
#include <iostream> // std::cout
#include <functional> // std::bind
// a function: (also works with function object: std::divides<double> my_divide;)
double my_divide (double x, double y) {return x/y;}
struct MyPair {
double a,b;
double multiply() {return a*b;}
};
int main () {
// 占位符的使用方法!!!!!!!!
using namespace std::placeholders; // adds visibility of _1, _2, _3,...
//---------------------绑定function,也就是前面的1---------------------
// binding functions:
auto fn_five = std::bind (my_divide,10,2); // returns 10/2
std::cout << fn_five() << '\n'; // 5
auto fn_half = std::bind (my_divide,_1,2); // returns x/2
std::cout << fn_half(10) << '\n'; // 5
auto fn_invert = std::bind (my_divide,_2,_1); // returns y/x
std::cout << fn_invert(10,2) << '\n'; // 0.2
auto fn_rounding = std::bind<int> (my_divide,_1,_2); // returns int(x/y)
std::cout << fn_rounding(10,3) << '\n'; // 3
MyPair ten_two {10,2};
//---------------------绑定member functions,也就是前面的3---------------------
// binding members:
//member function 其实有一个看不见的实参argument :this
auto bound_member_fn = std::bind (&MyPair::multiply,_1); // returns x.multiply()
std::cout << bound_member_fn(ten_two) << '\n'; // 20
//---------------------绑定member data,也就是前面的4---------------------
auto bound_member_data = std::bind (&MyPair::a,ten_two); // returns ten_two.a
std::cout << bound_member_data() << '\n'; // 10
//-------------------------上面的bind2nd就可以替换了-------------------------
vector<int> v {15, 37, 94, 50, 73, 58, 28, 98};
int n = count_if(v.cbegin(), v.cend(), not1(bind2nd(less<int>(), 50)))
cout << "n=" << n << endl; //5
//替换
auto fn_ = bind(less<int>(), _1, 50);
cout << count_if(v.cbegin(), v.cend(), fn_) << endl; //3
return 0;
}
迭代器适配器(Iterator Adapters)
reverse_iterator
reverse_iterator
rbegin(){//取逆向的头,就是正向的尾巴
return reverse_iterator(end());
}
reverse_iterator
rend(){//取逆向的尾巴,就是正向的头
return reverse_iterator(begin());
}
也有五种关联类型:

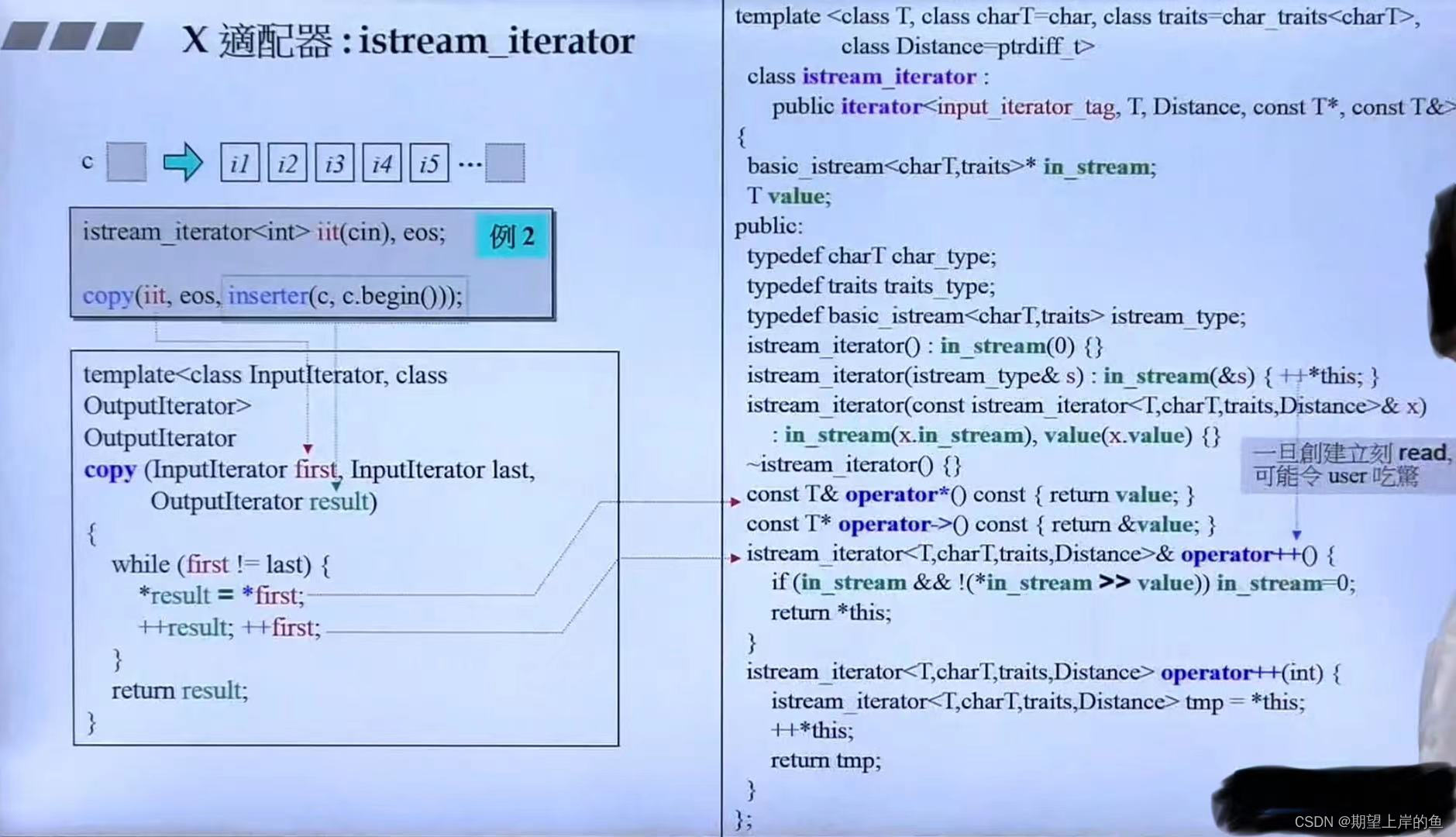
inserter
可以不用担心copy到的目的容器大小不匹配的问题。
copy是写死的,我们调用copy,希望完成在容器指定位置插入一些值!具体的实现:
- 把相应的容器和迭代器传入
inserter,对容器的迭代器中的=运算符进行重载,就能改变copy的行为! - 因为这个是对迭代器的
=运算符行为进行重定义,所以是迭代器的适配器。

X适配器
X表示未知:(容器、迭代器、函数,三大类之外的!)
- 包括
ostream、istream迭代器适配器
ostream_iterator
copy都是已经写好的,不能再改了!- 该适配器适配的是
basic_ostream,也是重载了=运算符,添加输出操作!

istream_iterator
ostream_iterator的兄弟,cin >> x被替换为了 x = *iit ,适配 basic_istream。
- 不断
++,就不断读内容。
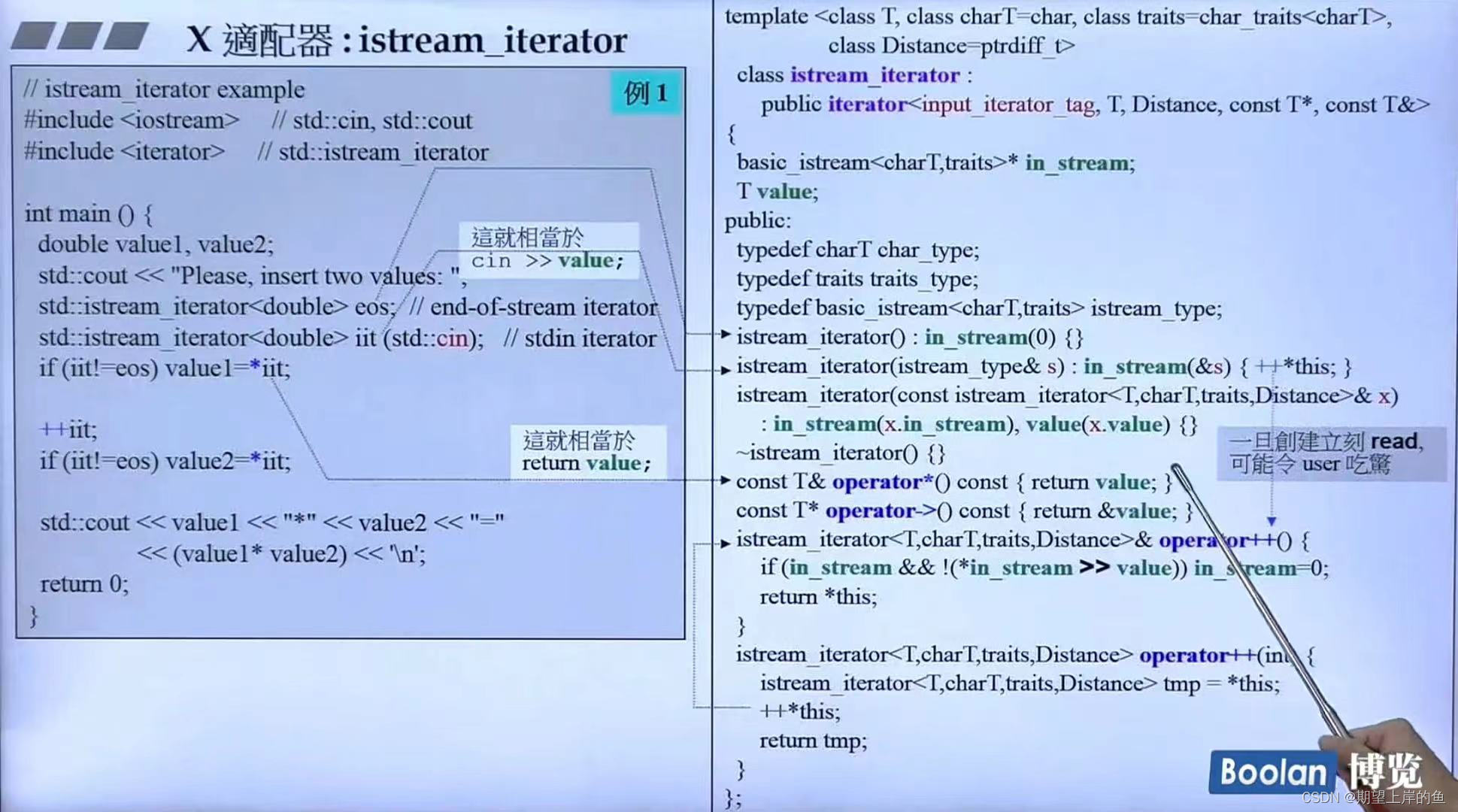
copy都是已经写好的,不能再改了!
当创建iit(cin),已经读入数据了!
不断++,就不断读内容。
补充
标准库STL周边还有一些东西需要知道。
Hash Function
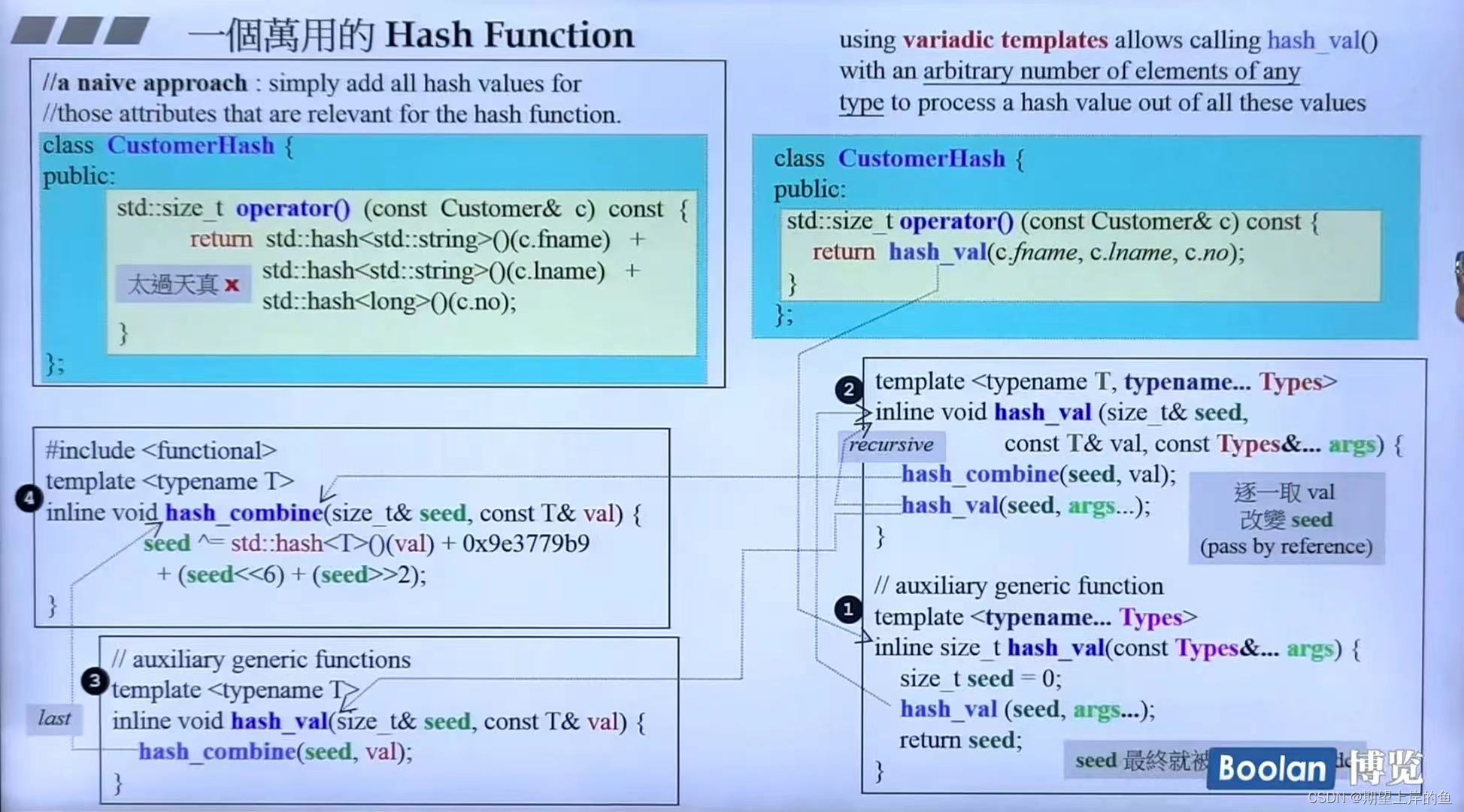
如果有一个我们自己的类,我们要怎么给这个类设计hash函数呢?
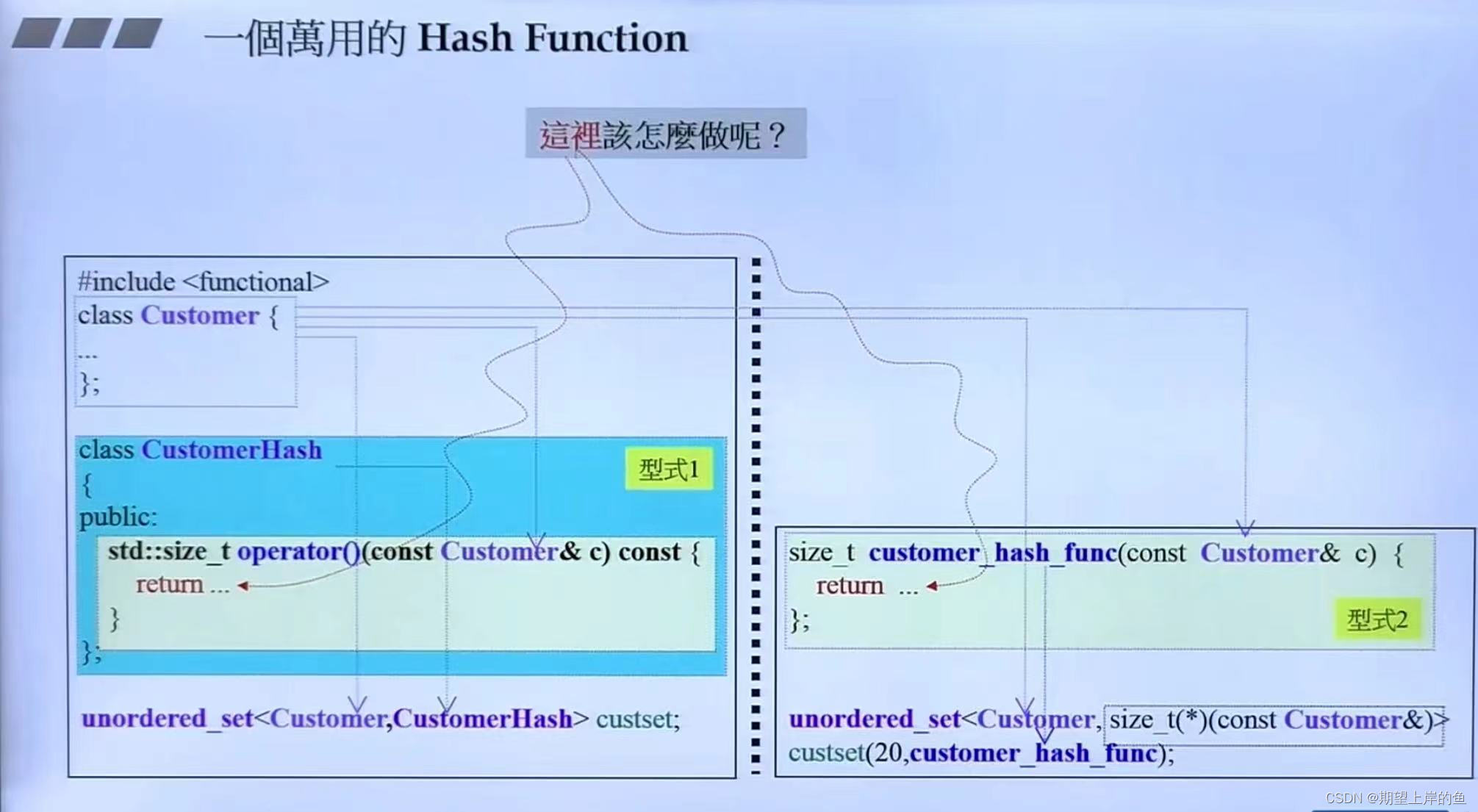
使用类中的成员变量的hash函数得到hash值,然后相加,(下面左上角)这个太naive了,可能会产生很多冲突。
所以使用右边那个!
args是C++11的新特性,任意多个参数都行,n个参数的args作为另外一个函数的输入的时候- 先调用①,分配一个种子
seed,再调用②; - 在②里面拆分
args,拆分成1+n-1的形式,递归调用自身,直到args只剩下一个参数时,调用③; - 在②中拆分时,会不断改变种子
seed:基本类型的hash函数+0x9e3779b9+...(越乱越好,没有数学可言,)。
- 先调用①,分配一个种子
也是使用想法一的思想,但是加入了更多的复杂的操作,使得得到的hash code冲突更少。
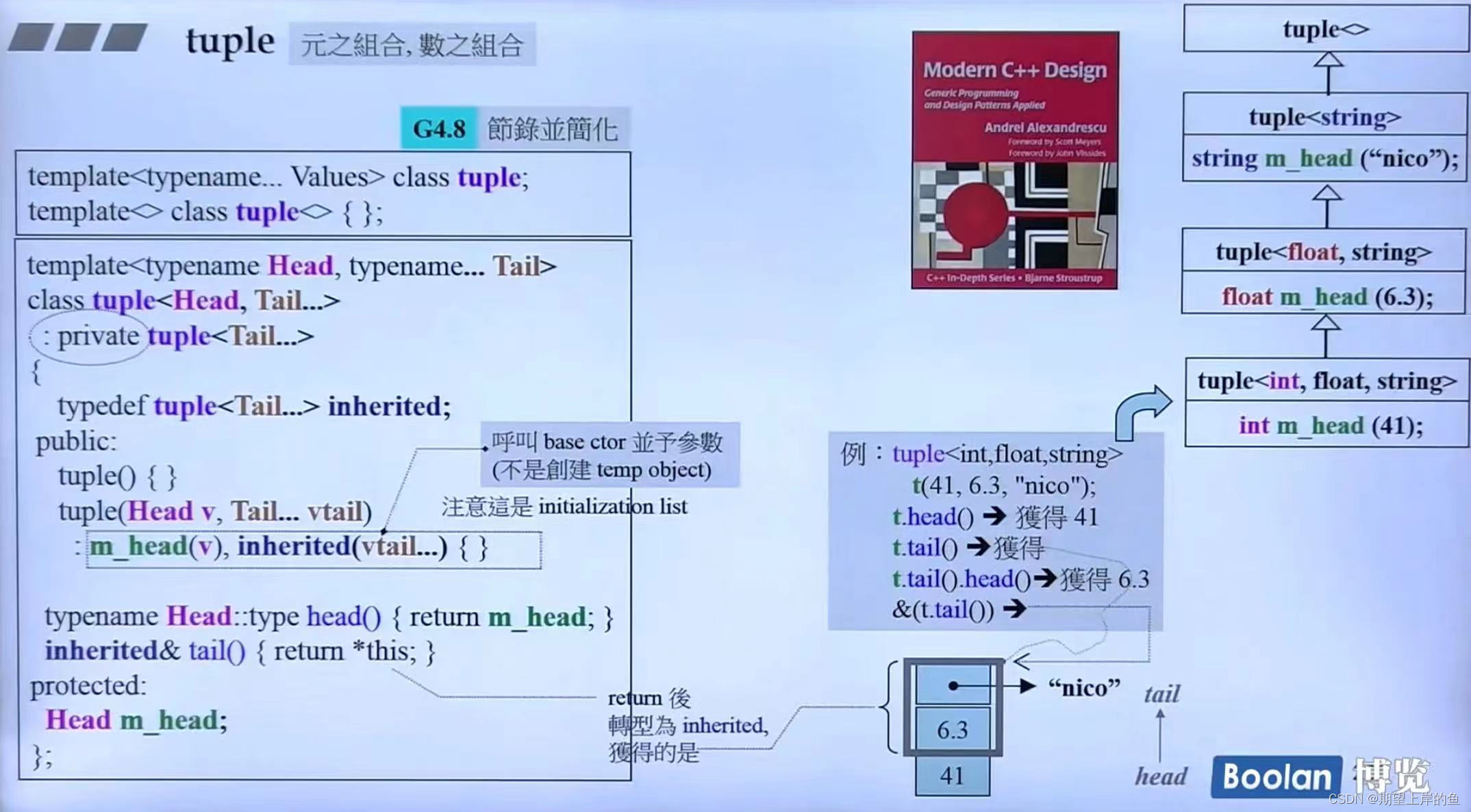
tuple
一组东西的组合,可以任意指定多少个元素,这些元素可以是任意的类型。
使用示例:
tuple<string, int, int, complex<double>> t;
sizeof(t); // 32, 为什么是32,而不是28呢?啊~侯捷也无法理解啊!
tuple<int, float, string> t1(41, 6.3, "test");
cout << "t1:" << get<0>(t1) << ' ' << get<1>(t1) << ' ' << get<2>(t1) << endl;
auto t2 = make_tuple(22, 44, "test2"); // t2也是一个tuple,自动推导类型
tuple_size< tuple<int, float, string> >::value; // 3
tuple_element< tuple<int, float, string> >::type; // 取tuple里面的类型
继承的是自己,会自动形成一个类的继承关系,注意有一个空的 tuple 类。
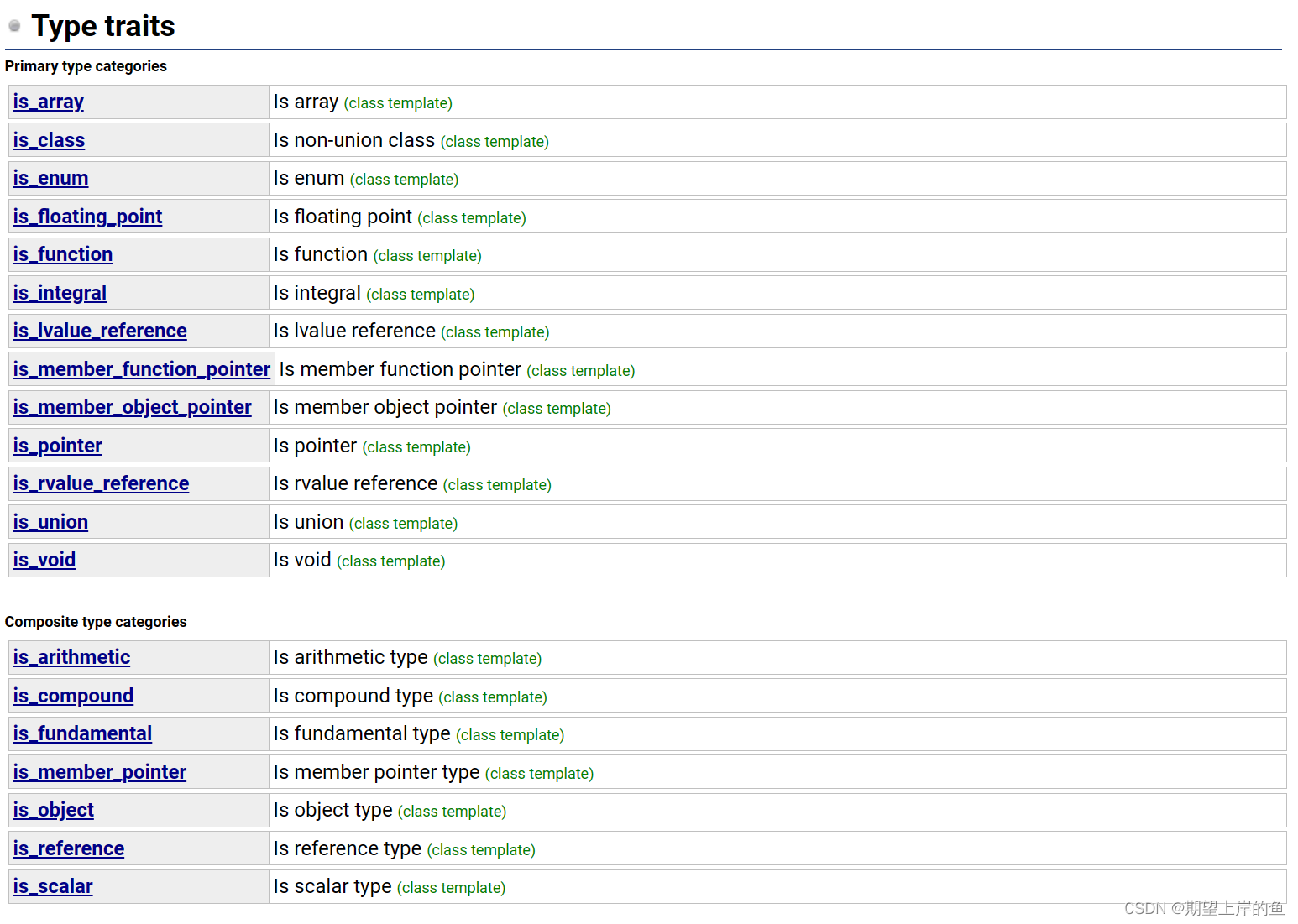
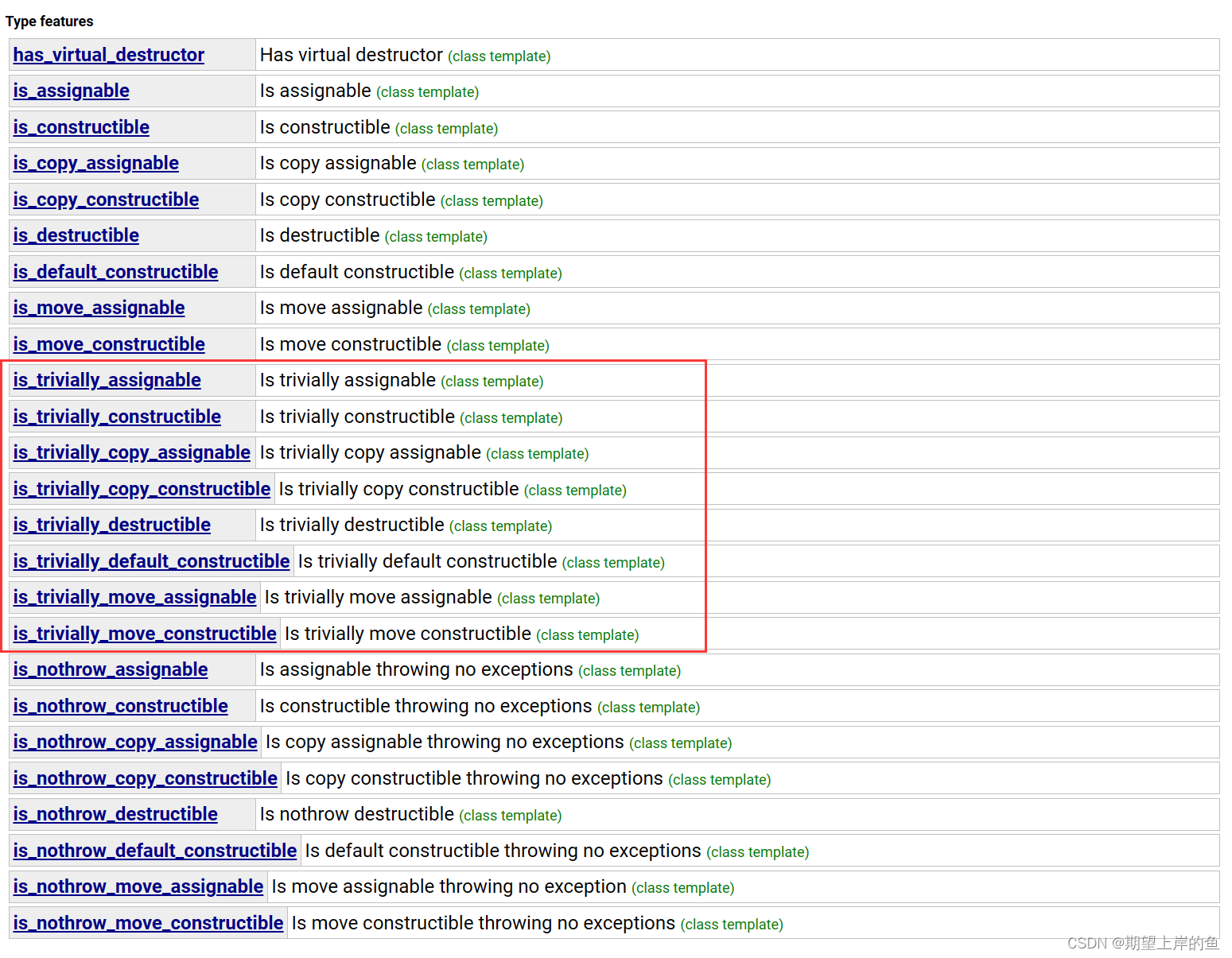
type traits
trivial:琐碎的,平凡的,平淡无奇的,无关痛痒的,无价值的,不重要的。
泛化模板类,包括五种比较重要的typedef: 默认的回答都是重要的!
typedef _false_type has_trivial_default_constructor; //默认构造函数是不重要吗?
typedef _false_type has_trivial_copy_constructor; //拷贝构造函数是不重要嘛?
typedef _false_type has_trivial_assignment_operator; //拷贝赋值构造函数是不重要嘛?
typedef _false_type has_trivial_destructor; //析构函数是不重要嘛?
typedef _false_type is_POD_type; //是不是旧格式(struct,只有数据,没有方法)?
比如说对于int的type traits,五个问题的回答都不重要。一般是算法会对traits进行提问。实用性不高。

type traits
现在的 traits机 ,非常智能:
- 只要把自己写的或者系统自带的类,作为
is_()::value就能得到问题的答案,这些问题包括下面几种,不全:
测试:
//global function template
template <typename T>
void type_traits_output(const T& x)
{
cout << "\ntype traits for type:" << typeid(T).name() << endl;
cout << "is_void\t" << is_void<T>::value << endl;
cout << "is_integral\t" << is_integral<T>::value << endl;
cout << "is_array\t" << is_array<T>::value << endl;
cout << "is_class\t" << is_class<T>::value << endl;
cout << "is_function\t" << is_function<T>::value << endl;
cout << "is_pointer\t" << is_pointer<T>::value << endl;
cout << "is_object\t" << is_object<T>::value << endl;
...
}
类型萃取机这么强的功能,是怎么实现的呢?下面以is_void为例:
- 首先去掉
const和volatile这两种对得到类特征无用的修饰关键字,做法如下(主要是用模板技巧); - 然后将去掉
cv(就是const和volatile)关键字之后,再传入__is_void_helper模板类中,让其自己匹配是不是空类型,匹配到不同的模板类,返回不同的bool值。

cout
是一个对象object,不是一个类,源码如下:
- 想要用
cout输出自己的类型,就可以重载<<运算符。

movable
movable元素会对各种容器的速度效能产生影响!!!
由vector的增长方式,对vector的影响很大,对其他的容器影响不是很大!
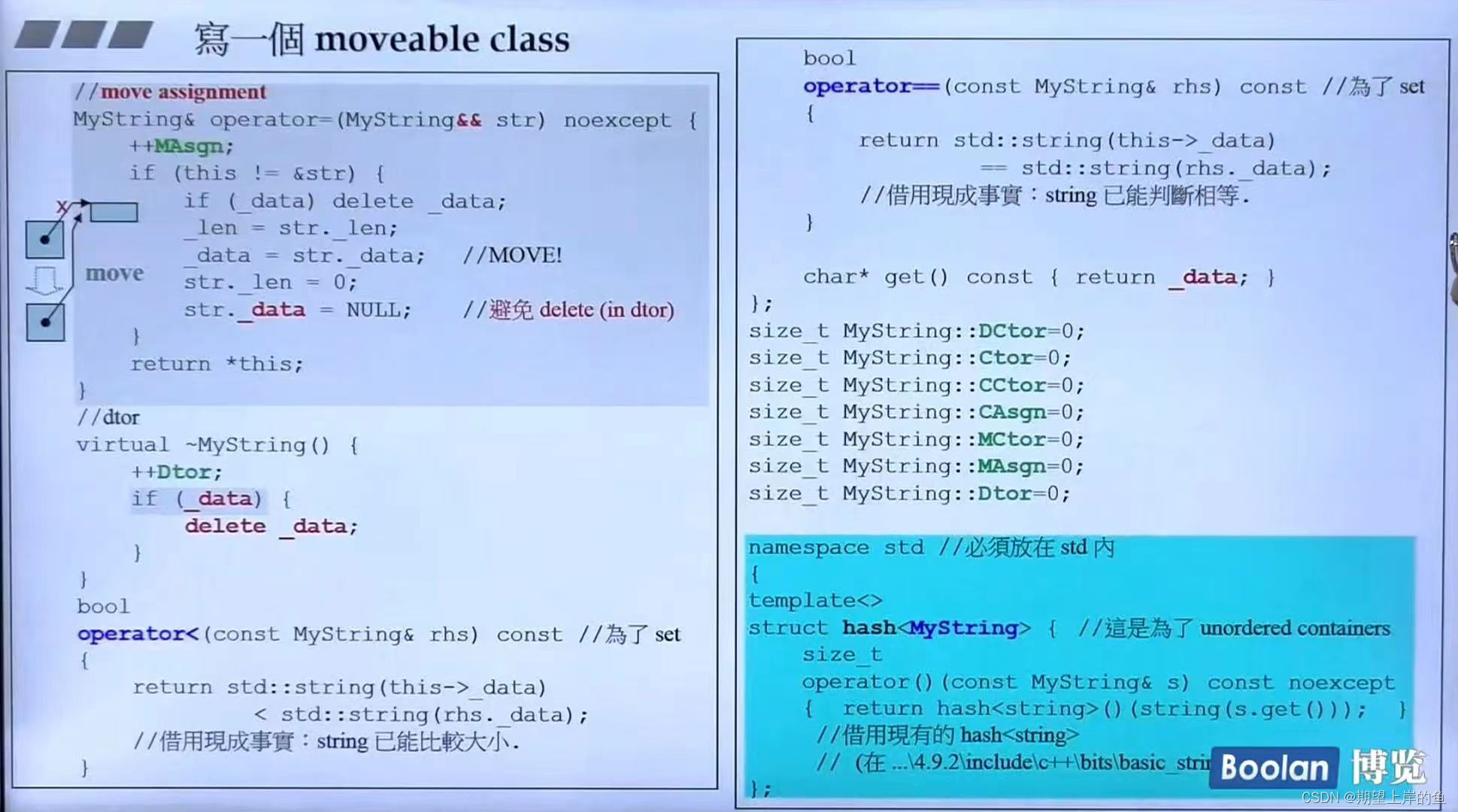
moveable 指的是 move 构造、move 赋值
move():是一种浅层拷贝,当用a初始化b后,a不再需要时,最好是初始化完成后就将a析构,使用move最优。- 如果说,我们用
a初始化了b后,仍要对a进行操作,用这种浅层复制的方法就不合适了。
所以C++引入了移动构造函数,专门处理这种,用 a 初始化 b 后,就将 a 析构的情况。这种操作的好处是:
- 将
a对象的内容复制一份到b中之后,b直接使用a的内存空间,这样就避免了新的空间的分配,大大降低了构造的成本。这就是移动构造函数设计的初衷。
move的使用场景是:原来的对象不再使用。如果再用就很危险!!!

测试函数:
移动构造函数实现是:调用拷贝构造函数,但是会将原来的对象中的成员变量置0!这样就不会调用原对象的析构函数了!如下图加深的部分,而且用的是引用的引用 && !&&是右值引用,右值有一个很重要的性质:只能绑定到一个将要销毁的对象。
调用移动构造函数方法,显示调用move:
classObj_1(std::move(classObj_2))
move焊copy:

注:仅供学习参考,如有不足,欢迎指正!