高级教程
- 1.正则表达式
- re.compile()
- re.match()函数
- re.search()函数
- re.search()函数与re.match()函数的区别
- group(num) 或 groups()
- 检索和替换re.sub()
- 替换函数中的re.sub可以是一个函数
- findAll()方法
- re.finditer()方法
- re.split()
- regex修饰符
- 正则表达式模式
- 2.CGI编程
- 什么是CGI
- 网页浏览
- 具体实现
- 3.Mysql
- 4.网络编程
- 5.STMP发送邮件
- 6.多线程
- 多线程简介
- 多线程的使用
- 函数式
- 线程优先级队列
- 线程同步
- 7.XML解析
- 8.JSON
- json.dumps
- json.loads
- 9.日期和时间
- 10.内置函数
- 11.MongoDB
- 12.urllib
- 简介
- urllib.request
- urllib.parse
- urllib.robotparser
- urllib.error
- 13.uWSGI安装配置
- 简介
- 14.pip
- 15.operator
- 16.math
- 17.requests
- 18.random
- 一个函数最终状态
1.正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
re 模块使 Python 语言拥有全部的正则表达式功能。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
re.compile()
import re
# compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
# 语法:re.compile(pattern[, flags])
# 参数:pattern : 一个字符串形式的正则表达式
# flags:可选。re.I 忽略大小写 re.L表示特殊字符集\w,\W
# re.M多行模式 re.S即为.并且包括换行符在内的任意字符
# re.U表示特殊字符集
# re.X为了增强可读性,忽略空格和#后面的注释
# compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换
pattern = re.compile(r'\d+') # 查找数字
print(f"该模式为{pattern},模式类型为{type(pattern)}") # 该模式为re.compile('\\d+'),模式类型为<class 're.Pattern'>
re.match()函数
# re.match()函数
# 语法:re.match(pattern, string, flags=0)
# pattern :匹配的正则表达式
# string :艺匹配的字符串
# flags :标志位,用于控制正则表达式的匹配方式。如是否区分大小写,多行匹配等
# 这个函数只从第一个函数开始匹配
# 成功返回一个匹配的对象,否则返回None
import re
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配 (0, 3)
# <re.Match object; span=(0, 3), match='www'> <class 're.Match'>
print("不带span的", re.match('www', 'www.runoob.com'),
type(re.match('www', 'www.runoob.com')))
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
re.search()函数
# re.search方法
# re.search 扫描整个字符串并返回第一个成功的匹配。
# re.search 扫描整个字符串并返回第一个成功的匹配。
# 语法:re.search(pattern, string, flags=0)
re.search()函数与re.match()函数的区别
# re.match与re.search的区别
# re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
# 而re.search匹配整个字符串,直到找到一个匹配。 返回也是匹配位置的下标
group(num) 或 groups()
# group(num=0) :匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。返回的是元组
# groups(): 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
#!/usr/bin/python3
import re
line = "Cats are smarter than dogs"
# .* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符
# (.*?) 表示"非贪婪"模式,只保存第一个匹配到的子串
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
# matchObj.group()输出整个
print ("matchObj.group() : ", matchObj.group()) # matchObj.group() : Cats are smarter than dogs
# matchObj.group(1)输出第一个括号里对应匹配的字符串
print ("matchObj.group(1) : ", matchObj.group(1)) # matchObj.group(1) : Cats
# matchObj.group(2)输出第二个括号里对应匹配的字符串
print ("matchObj.group(2) : ", matchObj.group(2)) # matchObj.group(2) : smarter
else:
print ("No match!!")
检索和替换re.sub()
# Python 的re模块提供了re.sub用于替换字符串中的匹配项。
# 语法:re.sub(pattern, repl, string, count=0, flags=0) 前三个必需的 后两个可选
# 参数:pattern是正则表达式 rep1是要替换的字符串(可以是一个函数) string是需要匹配的字符串,count是替换的最大次数(默认表示替换所有),flags表示编译时用的匹配模式
#!/usr/bin/python3
import re
phone = "2004-959-559 # 这是一个电话号码"
# 删除注释
num = re.sub(r'#.*$', "", phone) # r'#.*$'是参数pattern ,"" 表示将要用""替换与正则匹配的字符串,phone表示将要被匹配的字符串
print ("电话号码 : ", num)
# 移除非数字的内容
num = re.sub(r'\D', "", phone)
print ("电话号码 : ", num)
替换函数中的re.sub可以是一个函数
#!/usr/bin/python
import re
# replace可用函数名作为参数,返回值即为参数
# 将匹配的数字乘以 2
def double(matched):
value = int(matched.group('value'))
return str(value * 2)
s = 'A23G4HFD567'
print(re.sub('(?P<value>\d+)', double, s))
findAll()方法
# 在字符串中找到符合正则表达式的字符串,如果有多个匹配,则返回元组列表,如果没有找到匹配的,则返回空列表
# 注意:match和search是匹配一次,返回下标。而findAll是返回符合条件的子串
# 语法:re.findall(pattern, string, flags=0) string为戴培培的字符串
import re
result1 = re.findall(r'\d+','runoob 123 google 456')
pattern = re.compile(r'\d+') # 查找数字
# 还可以直接使用pattern替代re,因为pattren本身就是re对象
result2 = pattern.findall('runoob 123 google 456')
result3 = pattern.findall('run88oob123google456', 0, 10)
print(result1) #['123', '456']
print(result2) #['123', '456']
print(result3) #['88', '12']
# 多个匹配模式,返回元组列表
result = re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10')
print(result) # [('width', '20'), ('height', '10')]
re.finditer()方法
# 与findAll方法类似,在字符串中找到与正则表达式所匹配的所有子串,并把他们作为迭代器返回
# re.finditer(pattern, string, flags=0)
import re
it = re.finditer(r"\d+","12a32bc43jf3")
for match in it:
print (match.group() ) # 12 32 43 3
re.split()
# split方法按照能够匹配的子串将字符串分隔后返回列表,返回类型是列表
# 形式:re.split(pattern, string[, maxsplit=0, flags=0]) maxsplit表示分割次数
import re
re.split('\W+', 'runoob, runoob, runoob.') # ['runoob', 'runoob', 'runoob', '']
re.split('(\W+)', ' runoob, runoob, runoob.') # ['', ' ', 'runoob', ', ', 'runoob', ', ', 'runoob', '.', '']
re.split('\W+', ' runoob, runoob, runoob.', 1) #['', 'runoob, runoob, runoob.']
re.split('a*', 'hello world') # 对于一个找不到匹配的字符串而言,split 不会对其作出分割 ['hello world']
regex修饰符
| 项目 | Value |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
正则表达式模式
| 项目 | Value |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| […] | 用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’ |
| [^…] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。[0,n] |
| re+ | 匹配1个或多个的表达式。[1,n] |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 匹配n个前面表达式。例如,"o{2}“不能匹配"Bob"中的"o”,但是能匹配"food"中的两个o。 |
| re{ n,} | 精确匹配n个前面表达式。例如,"o{2,}“不能匹配"Bob"中的"o”,但能匹配"foooood"中的所有o。"o{1,}“等价于"o+”。"o{0,}“则等价于"o*”。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a | b |
| (re) | 匹配括号内的表达式,也表示一个组group |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (…), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#…) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 … 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功。 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配数字字母下划线 |
| \W | 匹配非数字字母下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]。 |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
| \B | 匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
| \n, \t, 等。 | 匹配一个换行符。匹配一个制表符, 等 |
| \1…\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
2.CGI编程
什么是CGI
CGI 目前由NCSA维护,NCSA定义CGI如下:
CGI(Common Gateway Interface),通用网关接口,它是一段程序,运行在服务器上如:HTTP服务器,提供同客户端HTML页面的接口。
网页浏览
为了更好的了解CGI是如何工作的,我们可以从在网页上点击一个链接或URL的流程:
- 使用你的浏览器访问URL并连接到HTTP web 服务器。
- Web服务器接收到请求信息后会解析URL,并查找访问的文件在服务器上是否存在,如果存在返回文件的内容,否则返回错误信息。
- 浏览器从服务器上接收信息,并显示接收的文件或者错误信息。
- CGI程序可以是 Python脚本,PERL脚本,SHELL 脚本,C或者C++程序等。
同时也需要在HTTP服务器上设置CGI配置。
具体实现
见菜鸟网,略略略
3.Mysql
4.网络编程
socket()函数
socket.socket([family[, type[, proto]]])
# family: 套接字家族可以是 AF_UNIX 或者 AF_INET
# type: 套接字类型可以根据是面向连接的还是非连接分为SOCK_STREAM或SOCK_DGRAM
# proto: 一般不填默认为0.
具体见菜鸟官网
5.STMP发送邮件
SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。
python的smtplib提供了一种很方便的途径发送电子邮件。它对smtp协议进行了简单的封装。
import smtplib
smtpObj = smtplib.SMTP( [host [, port [, local_hostname]]] )
#host: SMTP 服务器主机。 你可以指定主机的ip地址或者域名如:runoob.com,这个是可选参数。
#port: 如果你提供了 host 参数, 你需要指定 # #SMTP 服务使用的端口号,一般情况下SMTP端口号为25。
# local_hostname: 如果SMTP在你的本机上,你只需要指定服务器地址为 localhost 即可。
SMTP.sendmail(from_addr, to_addrs, msg[, mail_options, rcpt_options]
# 参数:第一个为发送者地址,第二个是接受者地址,第三个参数是mas表示发送的消息
实例
#!/usr/bin/python3
import smtplib
from email.mime.text import MIMEText
from email.header import Header
sender = 'from@runoob.com'
receivers = ['xxxxxxxxx@qq.com'] # 接收邮件,可设置为你的QQ邮箱或者其他邮箱
# 三个参数:第一个为文本内容,第二个 plain 设置文本格式,第三个 utf-8 设置编码
message = MIMEText('Python 邮件发送测试...', 'plain', 'utf-8')
message['From'] = Header("菜鸟教程", 'utf-8') # 发送者
message['To'] = Header("测试", 'utf-8') # 接收者
subject = 'Python SMTP 邮件测试'
message['Subject'] = Header(subject, 'utf-8')
try:
smtpObj = smtplib.SMTP('localhost')
smtpObj.sendmail(sender, receivers, message.as_string())
print ("邮件发送成功")
except smtplib.SMTPException:
print ("Error: 无法发送邮件")
## 温馨提示:很有可能报错
# ConnectionRefusedError: [WinError 10061] 由于目标计算机积极拒绝,无法连接。
# 新手退避
见菜鸟官网
6.多线程
多线程简介
多线程类似于同时执行多个不同程序,有以下优点:
- 使用线程可以把占据长时间的程序中的任务放到后台去处理。
- 用户界面可以更加吸引人,比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度。
- 程序的运行速度可能加快。
- 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
如果大家想要详细的了解进程相关知识:请重温操作系统
多线程的使用
Python3线程中常用的两个模块式为:_thread和threading(推荐使用)。thread 模块已被废弃。用户可以使用 threading 模块代替。所以,在 Python3 中不能再使用"thread" 模块。为了兼容性,Python3 将 thread 重命名为 “_thread”。
使用多线程有两种方式:函数或者用类来包装线程对象
函数式
调用_thread模块中的start_new_thread()函数来产生新线程。语法如下:_thread.start_new_thread ( function, args[, kwargs] )。function为线程函数,args表示传递给线程函数的参数,她必需是个tuple类型,kwargs - 可选参数。
# 实例
#!/usr/bin/python3
import _thread
import time
# 为线程定义一个函数
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
# 创建两个线程
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: 无法启动线程")
while 1:
pass
线程优先级队列
线程同步
7.XML解析
XML 指可扩展标记语言(eXtensible Markup Language),标准通用标记语言的子集,是一种用于标记电子文件使其具有结构性的标记语言。
XML 被设计用来传输和存储数据。
Python 对 XML 的解析
8.JSON
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式。Python3 中可以使用 json 模块来对 JSON 数据进行编解码,它包含了两个函数:
- json.dumps(): 对数据进行编码。将python string变成JSON Object。 py —>json
- json.loads(): 对数据进行解码.将JSON string 编码成Python Object。json -->py
json.dumps
# 语法
# json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding="utf-8", default=None, sort_keys=False, **kw)
#!/usr/bin/python
import json
# 列表里面包字典
data = [ { 'a' : 1, 'b' : 2, 'c' : 3, 'd' : 4, 'e' : 5 } ]
data2 = json.dumps(data)
print(data2) # [{"a": 1, "c": 3, "b": 2, "e": 5, "d": 4}]
json.loads
# 语法:json.loads(s[, encoding[, cls[, object_hook[, parse_float[, parse_int[, parse_constant[, object_pairs_hook[, **kw]]]]]]]])
# 将json ---> py string
# 实例
#!/usr/bin/python
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}';
text = json.loads(jsonData)
print(text)
Python 编码为 JSON 类型转换对应表
| 项目 | Value |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float, int- & float-derived Enums | number |
| True | true |
| False | false |
| None | null |
9.日期和时间
Python 程序能用很多方式处理日期和时间,转换日期格式是一个常见的功能。
Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间。
时间间隔是以秒为单位的浮点小数。
每个时间戳都以自从 1970 年 1 月 1 日午夜(历元)经过了多长时间来表示。
Python 的 time 模块下有很多函数可以转换常见日期格式。如函数 time.time() 用于获取当前时间戳,
什么是时间元组?
| 项目 | Value |
|---|---|
| 0 4位数年 | 2008 |
| 1 月 | 1 到 12 |
| 2 日 | 1到31 |
| 3 | 小时 0到23 |
| 4 | 分钟 0到59 |
| 5 | 秒 0到61 (60或61 是闰秒) |
| 6 | 一周的第几日 0到6 (0是周一) |
| 7 | 一年的第几日 1到366 (儒略历) |
| 8 | 夏令时 -1, 0, 1, -1是决定是否为夏令时的标 |
这些结构具有以下的属性
| 项目 | Value |
|---|---|
| 0 | tm_year 2008 |
| 1 | tm_mon 1 到 12 |
| 2 | tm_mday 1 到 31 |
| 3 | tm_hour 0 到 23 |
| 4 | tm_min 0 到 59 |
| 5 | tm_sec 0 到 61 (60或61 是闰秒) |
| 6 | tm_wday 0 到 6 (0是周一) |
| 7 | tm_yday 一年中的第几天,1 到 366 |
| 8 | tm_isdst 是否为夏令时,值有:1(夏令时)、0(不是夏令时)、-1(未知),默认 -1 |
10.内置函数
见官网
11.MongoDB
见菜鸟官网
12.urllib
简介
Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。url包含以下几个模块
- urllib.request - 打开和读取 URL。
- urllib.error - 包含 urllib.request 抛出的异常。
- urllib.parse - 解析 URL。
- urllib.robotparser - 解析 robots.txt 文件。
urllib.request
见菜鸟官网 ,遇到了才看
urllib.parse
urllib.robotparser
urllib.error
13.uWSGI安装配置
简介
见百度
安装模块结合WEB服务器使用,配置nginx配置,部署Python Web框架
14.pip
pip 是 Python 包管理工具,该工具提供了对 Python 包的查找、下载、安装、卸载的功能。
软件包也可以在 https://pypi.org/ 中找到。
目前最新的 Python 版本已经预装了 pip。
注意:Python 2.7.9 + 或 Python 3.4+ 以上版本都自带 pip 工具。
如果没有安装可以参考:[Python pip 安装与使用。](https://www.runoob.com/w3cnote/python-pip-install-usage.html)
注意: 现在使用清华大学镜像的比较多,比较快,可以避免一些由于局域网而出现的链接超时的问题
常用命令
| 命令 | 代码 |
|---|---|
| 显示版本和路径 | pip --version |
| 获取帮助 | pip --help |
| 升级 pip | pip install -U pip |
| 安装包 | pip install SomePackage # 最新版本 |
| 卸载包 | pip uninstall SomePackage |
| 搜索包 | pip search SomePackage |
| 显示安装包信息 | pip show |
| 查看指定包的详细信息 | pip show -f SomePackage |
| 列出已安装的包 | pip list |
15.operator
Python2.x 版本中,使用 cmp() 函数来比较两个列表、数字或字符串等大小关系。
Python 3.X 的版本中已经没有 cmp() 函数,如果你需要实现比较功能,
# 导入 operator 模块
import operator
# 数字
x = 10
y = 20
print("x:",x, ", y:",y)
print("operator.lt(x,y): ", operator.lt(x,y))
print("operator.gt(y,x): ", operator.gt(y,x))
print("operator.eq(x,x): ", operator.eq(x,x))
print("operator.ne(y,y): ", operator.ne(y,y))
print("operator.le(x,y): ", operator.le(x,y))
print("operator.ge(y,x): ", operator.ge(y,x))
print()
# 字符串
x = "Google"
y = "Runoob"
print("x:",x, ", y:",y)
print("operator.lt(x,y): ", operator.lt(x,y))
print("operator.gt(y,x): ", operator.gt(y,x))
print("operator.eq(x,x): ", operator.eq(x,x))
print("operator.ne(y,y): ", operator.ne(y,y))
print("operator.le(x,y): ", operator.le(x,y))
print("operator.ge(y,x): ", operator.ge(y,x))
print()
# 查看返回值
print("type((operator.lt(x,y)): ", type(operator.lt(x,y)))
# 结果
# x: 10 , y: 20
# operator.lt(x,y): True
# operator.gt(y,x): True
# operator.eq(x,x): True
# operator.ne(y,y): False
# operator.le(x,y): True
# operator.ge(y,x): True
# x: Google , y: Runoob
# operator.lt(x,y): True
# operator.gt(y,x): True
# operator.eq(x,x): True
# operator.ne(y,y): False
# operator.le(x,y): True
# operator.ge(y,x): True
operator模块的其他方法
需要引入 operator 模块,
operator 模块提供了一套与 Python 的内置运算符对应的高效率函数。
函数包含的种类有:对象的比较运算、逻辑运算、数学运算以及序列运算。
许多函数名与特殊方法名相同,只是没有双下划线。
为了向后兼容性,也保留了许多包含双下 划线的函数,
为了表述清楚,建议使用没有双下划线的函数。
| 运算 | 语法 | 函数 |
|---|---|---|
| 加法 | a + b | add(a, b) |
| 字符串拼接 | seq1 + seq2 | concat(seq1, seq2) |
| 包含测试 | obj in seq | contains(seq, obj) |
| 除法 | a / b | truediv(a, b) |
| 除法 | a // b | floordiv(a, b) |
| 按位与 | a & b | and_(a, b) |
| 按位异或 | a ^ b | xor(a, b) |
| 按位取反 | ~ a | invert(a) |
| 按位或 | a | b |
| 取幂 | a ** b | pow(a, b) |
| 标识 | a is b | is_(a, b) |
| 标识 | a is not b | is_not(a, b) |
| 索引赋值 | obj[k] = v | setitem(obj, k, v) |
| 索引删除 | del obj[k] | delitem(obj, k) |
| 索引取值 | obj[k] | getitem(obj, k) |
| 左移 | a << b | lshift(a, b) |
| 取模 | a % b | mod(a, b) |
| 乘法 | a * b | mul(a, b) |
| 矩阵乘法 | a @ b | matmul(a, b) |
| 取反(算术) | - a | neg(a) |
| 取反(逻辑) | not a | not_(a) |
| 正数 | + a | pos(a) |
| 右移 | a >> b | rshift(a, b) |
| 切片赋值 | seq[i:j] = values | setitem(seq, slice(i, j), values) |
| 切片删除 | del seq[i:j] | delitem(seq, slice(i, j)) |
| 切片取值 | seq[i:j] | getitem(seq, slice(i, j)) |
| 字符串格式化 | s % obj | mod(s, obj) |
| 减法 | a - b | sub(a, b) |
| 真值测试 | obj | truth(obj) |
| 比较 | a < b | lt(a, b) |
| 比较 | a <= b | le(a, b) |
| 相等 | a == b | eq(a, b) |
| 不等 | a != b | ne(a, b) |
| 比较 | a >= b | ge(a, b) |
| 比较 | a > b | gt(a, b) |
16.math
Python math 模块提供了许多对浮点数的数学运算函数。
math 模块下的函数,返回值均为浮点数,除非另有明确说明。
如果你需要计算复数,请使用 cmath 模块中的同名函数。
math模块常量
| 常量 | 描述 |
|---|---|
| math.e | 返回欧拉数 (2.7182…) |
| math.inf | 返回正无穷大浮点数 |
| math.nan | 返回一个浮点值 NaN (not a number) |
| math.pi | π 一般指圆周率。 圆周率 PI (3.1415…) |
| math.tau | 数学常数 τ = 6.283185…,精确到可用精度。Tau 是一个圆周常数,等于 2π, |
math模块方法
由于math方法提供的方法特别多,因此我们在下表中只列举出较为重要和常用的
| 项目 | Value |
|---|---|
| math.asin(x) | 返回 x 的反正弦值,结果范围在 -pi/2 到 pi/2 之间。 |
| math.ceil(x) | 将 x 向上舍入到最接近的整数 |
| math.degrees(x) | 将角度 x 从弧度转换为度数。 |
| math.exp(x) | 返回 e 的 x 次幂,Ex, 其中 e = 2.718281… 是自然对数的基数。 |
| math.fabs(x) | 返回 x 的绝对值。 |
| math.factorial(x) | 返回 x 的阶乘。 如果 x 不是整数或为负数时则将引发 ValueError。 |
| math.floor() | 将数字向下舍入到最接近的整数 |
| math.fmod(x, y) | 返回 x/y 的余数 |
| math.gcd() | 返回给定的整数参数的最大公约数。 |
| math.isclose(a,b) | 检查两个值是否彼此接近,若 a 和 b 的值比较接近则返回 True,否则返回 False。。 |
| math.isfinite(x) | 判断 x 是否有限,如果 x 既不是无穷大也不是 NaN,则返回 True ,否则返回 False 。 |
| math.isinf(x) | 判断 x 是否是无穷大,如果 x 是正或负无穷大,则返回 True ,否则返回 False 。 |
| math.isnan() | 判断数字是否为 NaN,如果 x 是 NaN(不是数字),则返回 True ,否则返回 False 。 |
| math.isqrt() | 将平方根数向下舍入到最接近的整数 |
| math.log2(x) | 返回 x 以 2 为底的对数 |
| math.pow(x, y) | 将返回 x 的 y 次幂。 |
| math.sqrt(x) | 返回 x 的平方根。 |
| math.trunc(x) | 返回 x 截断整数的部分,即返回整数部分,删除小数部分 |
import math
print(f"0.5的反正炫值是:{math.asin(0.5)}")
print(f"0.5的向上取整是:{math.ceil(0.5) }")
print(f"0.5的向下取整是:{math.floor(0.5) }")
print(f"{math.tau}弧度转换成数字度数是:{math.degrees(math.tau)}")
print(f"{math.e}的2次幂是:{math.exp(2) }")
print(f"-1的绝对值是:{math.fabs(-1)}")
print(f"5的阶乘是:{math.factorial(5)}")
print(f"7/3 的余数是:{math.fmod(7, 3) }")
print(f"-12与-36的最大公约数是:{math.gcd(-12, -36)}")
print(f"8.005与8.450在容差为0.5的情况下是否相接近:{math.isclose(8.005, 8.450, abs_tol=0.5)}")
print(f"NAN是否有限:{math.isfinite(math.nan) }")
print(f"NAN是否是无穷大:{math.isinf(math.nan) }")
print(f"NAN是否是NaN:{math.isnan(math.nan) }")
print(f"7的平方根向下取整是:{math.isqrt(7)}")
print(f"7的平方根是:{math.sqrt(7)}")
print(f"7的对2取对数是是:{math.log2(7)}")
print(f"x的y次方是:{math.pow(2, 4) }")
print(f"3434.2341341424的整数部分是:{math.trunc(3434.2341341424) }")
# 结果如下:
# 0.5的反正炫值是:0.5235987755982989
# 0.5的向上取整是:1
# 0.5的向下取整是:0
# 6.283185307179586弧度转换成数字度数是:360.0
# 2.718281828459045的2次幂是:7.38905609893065
# -1的绝对值是:1.0
# 5的阶乘是:120
# 7/3 的余数是:1.0
# -12与-36的最大公约数是:12
# 8.005与8.450在容差为0.5的情况下是否相接近:True
# NAN是否有限:False
# NAN是否是无穷大:False
# NAN是否是NaN:True
# 7的平方根向下取整是:2
# 7的平方根是:2.6457513110645907
# 7的对2取对数是是:2.807354922057604
# x的y次方是:16.0
# 3434.2341341424的整数部分是:3434
17.requests
Python requests 是一个常用的 HTTP 请求库,可以方便地向网站发送 HTTP 请求,并获取响应结果。
requests 模块比 urllib 模块更简洁。
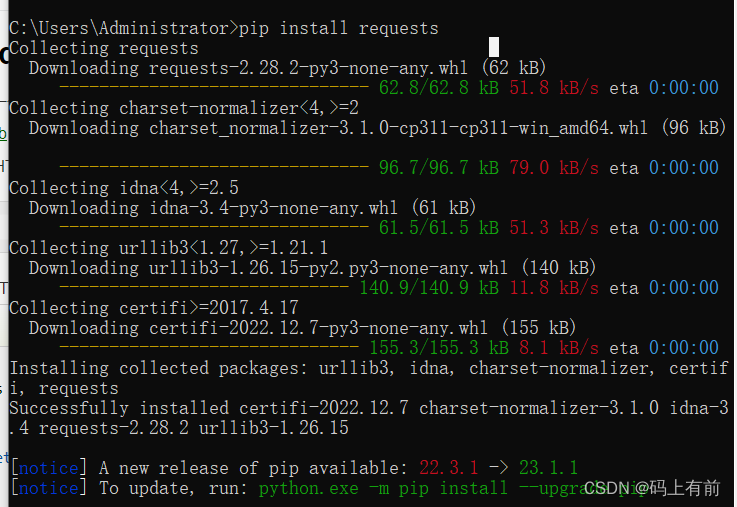
刚开始如果没安装模块到本地会报错

这时不要慌,打开我们的小黑窗口(win+R 输入cmd),然后使用pip install requests下载模块到本地就ok了
简单使用
import requests
x = requests.get('https://www.runoob.com/')
# 查看返回的内容
print(x) # <Response [200]> 返回一个response对象
# 此时这个x就是一个response对象
print("这个是响应体的状态码", x.status_code) # 获取响应状态码
print("这个是响应体的响应头", x.headers) # 获取响应头
print("这个是响应体的主体内容", x.content) # 获取响应内容
print("这个是响应体的编码方式", x.apparent_encoding) # 获取响应内容
print("这个是响应体的cookies", x.cookies) # 返回cookies <RequestsCookieJar[]>
print("这个是响应体的cookies",x.json())
print("这个是响应体的history", x.history) # 返回包含请求历史的响应对象列表[](url)
print("这个是响应体的next", x.cookies) # 返回重定向链中下一个请求的 PreparedRequest 对象
print("这个是响应体的reason", x.reason) # 返回reason
print("这个是响应体的text", x.text) # 返回text
print("这个是响应体的url", x.url) # 返回url
更多响应方法
| 方法 | 描述 |
|---|---|
| delete(url, args) | 发送 DELETE 请求到指定 url |
| get(url, params, args) | 发送 GET 请求到指定 url |
| head(url, args) | 发送 HEAD 请求到指定 url |
| patch(url, data, args) | 发送 PATCH 请求到指定 url |
| post(url, data, json, args) | 发送 POST 请求到指定 url |
| put(url, data, args) | 发送 PUT 请求到指定 url |
| request(method, url, args) | 向指定的 url 发送指定的请求方法 |
Post()方法
# requests.post(url, data={key: value}, json={key: value}, args)
# 语法:data参数为要发送到指定url的自带你,元组或者列表,字节或者文件对象
# json:json参数为要发送到指定的url的json对象
# args为其他参数,比如cookies,headers等
# 发送请求
x = requests.post('https://www.runoob.com/try/ajax/demo_post.php')
# 返回网页内容
print(x.text)
# 此外 我们还能另外附加请求头等,查询参数和请求体
headers = {'User-Agent': 'Mozilla/5.0'} # 设置请求头
params = {'key1': 'value1', 'key2': 'value2'} # 设置查询参数
data = {'username': 'example', 'password': '123456'} # 设置请求体
response = requests.post('https://www.runoob.com', headers=headers, params=params, data=data)
18.random
Python random 模块主要用于生成随机数。
random 模块实现了各种分布的伪随机数生成器。
导入包&基本操作
import random
print(random.random()) # 在半开放区间[0,1)范围内,包含0但是不包含1
send()方法
# seed()方法改变随机数生成器的种子,可以在调用其他随机模块函数之前调用此函数。
# 初始化随机数生成器
random.seed()
print ("使用默认种子生成随机数:", random.random())
random.seed(10)
print ("使用整数 10 种子生成随机数:", random.random())
random.seed("hello",2)
print ("使用字符串种子生成随机数:", random.random())
randrange()方法
# 从 range(start, stop, step) 返回一个随机选择的元素。
# 语法:start-可选,一个整数,指定开始值,默认0。stop-必需,一个整数,指定结束值。step-可选,一个整数,指定步长,默认值为 1。
# 导入 random 包
import random
# 返回一个 1 到 9 之间的数字
print(random.randrange(1, 100, 2)) # 寻找1~100之间的奇数,因为步长为2
randint()方法
import random
# random.randint(start, stop)
# 语法:start必需 整数,stop必需 整数
# 返回一个 1 到 9 之间的数字
print(random.randint(1, 9)) # 8
** shuffle() 方法–打乱**
import random
# 将序列的所有元素随机排序。传入一个列表
# 返回一个被打乱的列表
list = [1, 12, 23, 34, 45]
#当调用这个方法后,被传入的参数就已经被打乱,不会有返回值
list_shuffled = random.shuffle(list)
print(f"被打乱之后的列表{list_shuffled}") # None
print(f"被打乱之后的列表{list}") # [34, 23, 12, 45, 1]
# 注意: random.shuffle 具有破坏性,需要每次都重置列表。
uniform()方法
# uniform() 方法将随机生成下一个实数,它在 [x,y] 范围内。
# x -- 随机数的最小值,包含该值。y -- 随机数的最大值,包含该值。
print("uniform返回一个随机浮点数 : ", random.uniform(1, 10))
# 6.674137831336333
其他方法
| 方法 | 作用 |
|---|---|
| triangular(low, high, mode) | 返回一个随机浮点数 N ,使得 low <= N <= high 并在这些边界之间使用指定的 mode 。 low 和 high 边界默认为零和一。 mode 参数默认为边界之间的中点,给出对称分布。 |
| betavariate(alpha, beta) | Beta 分布。 参数的条件是 alpha > 0 和 beta > 0。 返回值的范围介于 0 和 1 之间。 |
| expovariate(lambd) | 指数分布。 lambd 是 1.0 除以所需的平均值,它应该是非零的。 |
| gammavariate() | Gamma 分布( 不是伽马函数) 参数的条件是 alpha > 0 和 beta > 0。 |
| gauss(mu, sigma) | 正态分布,也称高斯分布。 mu 为平均值,而 sigma 为标准差。 此函数要稍快于下面所定义的 normalvariate() 函数。 |
| lognormvariate(mu, sigma) | 对数正态分布。 如果你采用这个分布的自然对数,你将得到一个正态分布,平均值为 mu 和标准差为 sigma 。 mu 可以是任何值,sigma 必须大于零。 |
| normalvariate(mu, sigma) | 正态分布。 mu 是平均值,sigma 是标准差。 |
| vonmisesvariate(mu, kappa) | 冯·米塞斯分布。 mu 是平均角度,以弧度表示,介于0和 2pi 之间,kappa 是浓度参数,必须大于或等于零。 如果 kappa 等于零,则该分布在 0 到 2pi 的范围内减小到均匀的随机角度。 |
| paretovariate(alpha) | 帕累托分布。 alpha 是形状参数。 |
| weibullvariate(alpha, beta) | 威布尔分布。 alpha 是比例参数,beta 是形状参数。 |
一个函数最终状态
- 显性返回return
- 无return(隐式reurn None)
- 改变空间下的值(多用于类中),显性return
- 改变空间下的值(多用于类中),无return(隐式return None)
- 改变入参[,改变空间下的值(多用于类中)],显性return
- 改变入参[,改变空间下的值(多用于类中)],无return(隐式return None)
其中所有无return的结构都是合法的,只是我们通常都手动显性给个返回值而已。
这样做的意义在于: 从外部看就知道这个函数他是有返回值的,便于代码理解与维护)关于 5 和 6 的“改变入参”,这个说起来就和PHP的引用传参如出一辙(我猜的, 本想看下底层实现来验证的但没有找到地方):函数内部改变入参,函数外部也跟着被改变;因为他们(外部变量和入参变量)指向了同一个内存地址。



![[Android Studio Tool]如何将AS的gradle文件迁移到D盘](https://img-blog.csdnimg.cn/36aa27b098794c5bbdb11ba80e47a03e.png)