KNN最近邻算法分析及实现(代码附录后文)
- 1 KNN算法简介
- 2 KNN基本原理
- 3 简单实现KNN分析
- 代码附录(Python):
- 呆,站住别跑,留个赞,给个关注嘛都看到这了
Author: Nirvana Of Phoenixl
Proverbs for you:There is no doubt that good things will always come, and when it comes late, it can be a surprise.
(送给你的)
1 KNN算法简介
最近邻(K-Nearest Neighbor,KNN)算法,是著名的模式识别统计学方法,在机器学习分类算法中占有相当大的地位。它是一个理论上比较成熟的方法。既是最简单的机器学习算法之一,也是基于实例的学习方法中最基本的,又是最好的文本分类算法之一。
K近邻法(K-Nearest Neighbor, KNN)是一种基本分类与回归方法,其基本做法是:给定测试实例,基于某种距离度量找出训练集中与其最靠近的K个实例点,然后基于这K个最近邻的信息来进行预测。
通常,在分类任务中可使用“投票法”,即选择这K个实例中出现最多的标记类别作为预测结果;在回归任务中可使用“平均法”,即将这K个实例的实值输出标记的平均值作为预测结果;还可基于距离远近进行加权平均或加权投票,距离越近的实例权重越大。
2 KNN基本原理
KNN最邻近分类算法的实现原理:为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的投票法则(majority-voting),将未知样本与K个最邻近样本中所属类别占比较多的归为一类。
K近邻算法的主要任务是通过判断距离来选取未知样本,它包含的又一下核心公式:
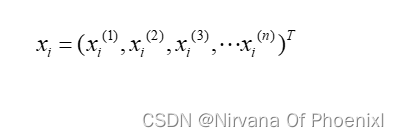
其中xi表示样本集
通过未知样本和已知样本的距离来判断取舍,主要是根据闵可夫斯基距离(LP)距离,其距离可以表示为:
其中xi,xj表示两个样本,n表示样本数,l表示维度,p表示参数其值取不同则表示不同距离。

根据LP距离可以推到得到不同的衡量距离,具体如下:
当p=1时,LP距离为曼哈顿距离,则可表示为:
当p=2时,LP距离为欧式距离,则可以表示为:
当P= 时,LP距离为切比雪夫距离,它表示两个点之间距离最大的坐标系之间的距离,可以表示为:
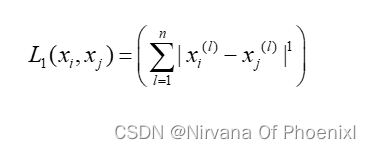
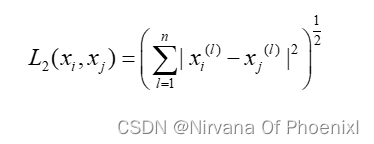
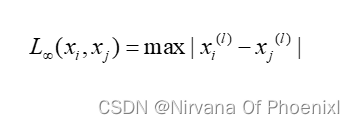
3 简单实现KNN分析
通过基本原理设计一个简单的数据分类,通过随机取点分为两份作为样本点,再随机几个点作为待测点,并且通过KNN判断该点可能属于的类。
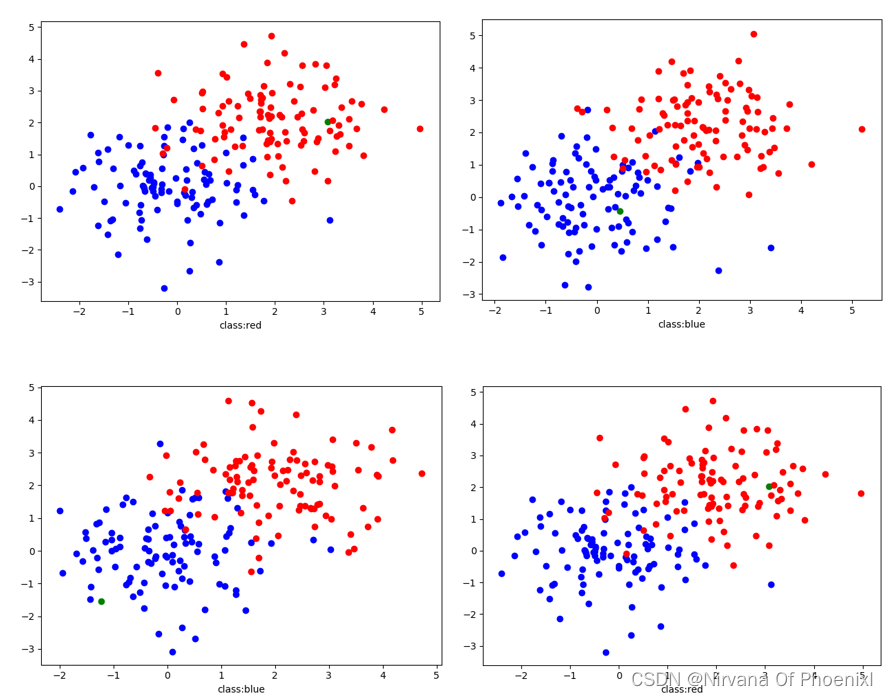
随机点分类可视化图
代码附录(Python):
from matplotlib.pyplot import *
import numpy as np
k = 5 # 简单例子,取k值为5即可
n=100 # 随机点分为两种颜色点的个数
def creatdot(rangex, rangey, dotnum, classtyap): # 产生随机点分为x,y
x = np.random.normal(rangex, rangey, dotnum)
y = np.random.normal(rangex, rangey, dotnum) # 调用正态分布
scatter(x, y, color=classtyap) # 产生点集
return x, y
def discal(X, Y, markx, marky, classtyap): # KNN计算距离
for i in range(len(X)):
x = X[i]
y = Y[i]
dis = ((x - markx)**2 + (y - marky)**2)**0.5
dismp.append([dis, classtyap])
return dismp
def creatmark(): # 产生随机点作为被测数据
x, y = creatdot(0, 2, 1, "green")
return x, y
markx, marky = creatmark()
dismp = []
X, Y = creatdot(0, 1, n, "blue")
dismp.append(discal(X, Y, markx, marky, "blue"))
X, Y = creatdot(2, 1, n, "red")
dismp.append(discal(X, Y, markx, marky, "red"))


![[SWPUCTF 2018]SimplePHP](https://img-blog.csdnimg.cn/5764a8376a1b4bc2847bffb9aedce22e.png)