相信大家在使用数据库中,提高SQL查询速度最简单的办法就是添加相关索引,但是其实我们创建的索引并不一定能用上,有时候顺序扫描也并不见的就比离散的索引扫描差,任何事物我们要辩证的看待,今天我们说明一下创建索引的一些消极影响,可以在生产使用环境中权衡利弊,再决定是否有必要使用索引。
首先可以参考一下索引无法使用的情况,参考https://mp.weixin.qq.com/s/9JZpGRJ_TfovqvA-kJR3CA
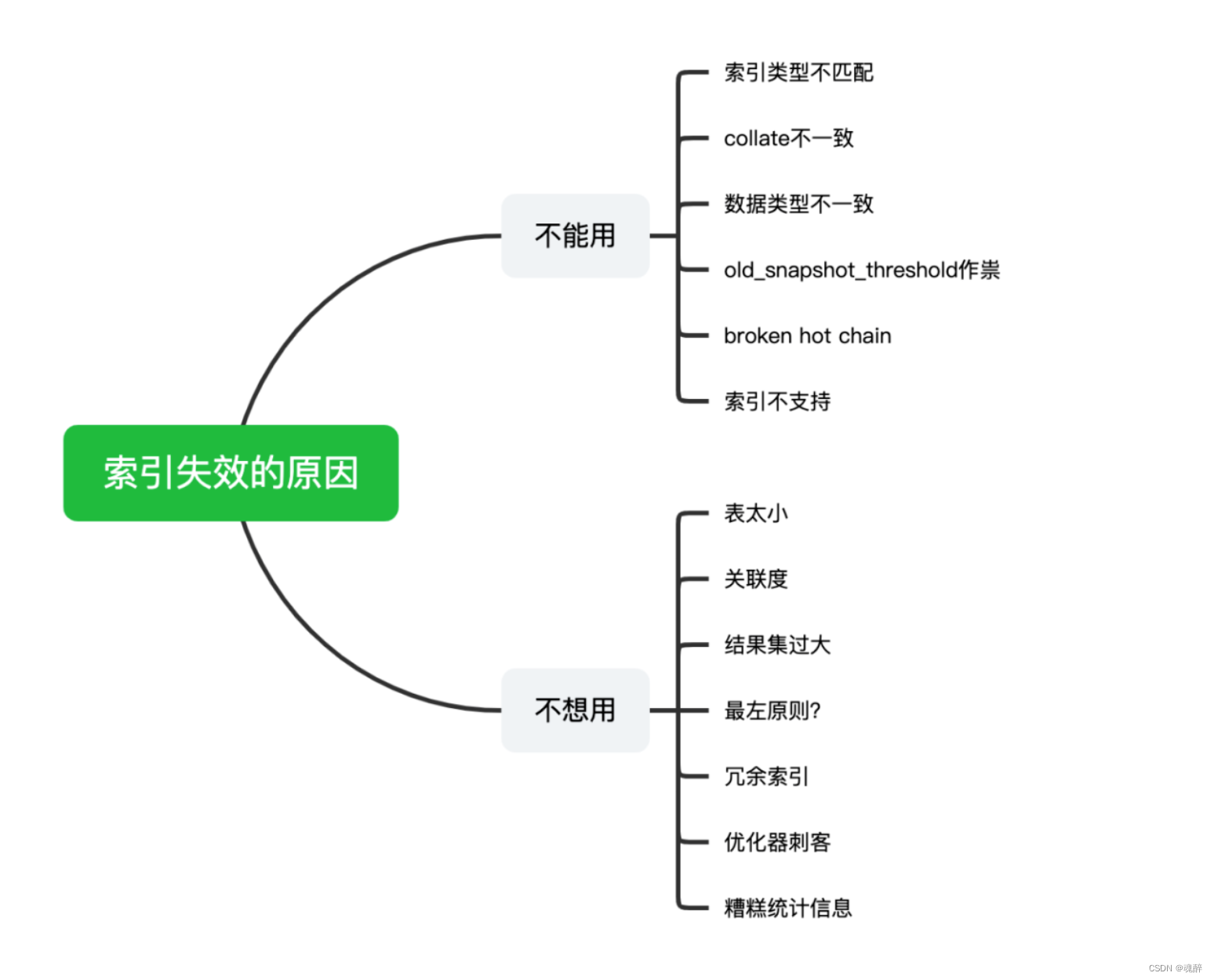
详情可以阅读以上链接,这里不再举例一一说明。
下面介绍一下创建索引的消极影响
-
DML导致写放大
如果一张表的索引比较多,DML可能会导致写放大,添加索引后,我们可能会看到SELECT语句的性能有所提高。从概念上讲,表上的每个DML语句都需要更新表的所有索引。尽管有很多优化可以减少写放大,但仍然是一个相当大的开销。 -
内存使用的增加,索引需要更多的缓存
要使用的索引页必须在内存中,无论是否有查询使用它们,因为它们需要通过事务进行更新。这样就导致表页可用的内存变得更少了。索引越多,有效缓存所需的内存就越多。由于随机的写入和读取索引,索引需要在缓存中存储更多的页面。索引的缓存需求通常比关联的表高很多。如果我们不增加可用内存,就可能会影响系统的整体性能。 -
随机写I/O
与行插入操作不同,行更新不太可能被插入到同一页中。众所周知,像B-Tree索引这样的索引会导致更多的随机写入。 -
WAL日志的增加
除了更新表的WAL记录外,还会有索引的WAL记录。这有助于崩溃恢复和复制。可以使用pg_gather插件进行观察,可以清楚地看到生成WAL的开销。实际影响取决于索引类型。 -
更多的I/O
不仅仅是WAL记录的生成会占用I/O;我们也会有更多的页面被弄脏。当索引页弄脏时,必须将它们写回到文件,从而导致更多的I/O,比如会有“DataFileWrite”等待事件。
另一个副作用是索引增加了活动数据集的总大小。这里活动数据集,指的是经常查询和使用的表和索引。随着活动数据集大小的增加,缓存变得越来越低效。低效的缓存会导致更多的物理数据文件读取,因此读I/O增加。这些增加的读I/O就是从物理存储中读取索引页面的I/O。也可以通过pg_gather查看具体信息。 -
VACUUM/AUTOVACUUM的影响
正如前面所说,不仅仅增加了插入或更新索引页的开销,由于索引还需要清理旧的元组引用,因此维护它有开销。
在现实情况中,我经常看到这样的情况,由于表比较大,而且表上的索引数量也比较多,单个表上的autovacuum运行了很长时间。实际中,用户也看到他们的autovacuum“卡住”了几个小时,没有进展,并持续很长时间。这是因为autovacuum的索引清理阶段是不透明的,在pg_stat_progress_vacuum等视图中是不可见的。
随着时间的推移,索引会变得膨胀,效率会降低。在许多数据库系统中可能需要定期索引维护(重建索引:REINDEX)。 -
更多的存储需求
索引越多,当然我们使用的存储空间越多,因此,备份也会占用更多的时间、存储和网络资源,而且同样的备份会给主机带来更多的负载。这还会增加恢复备份和恢复备份的时间。越大的数据库会影响很多事情,比如花更多的时间来构建备用实例。 -
索引导致的BUG
随着索引越来越多,可能导致的BUG也会越来越多,比如PG14中的静默索引损坏
那我们到底该如何做呢?
在考虑新建索引时,应该考虑一系列关键问题:是否必须有这个索引,或者是否有必要以增加索引为代价来加快查询速度?是否有一种方法可以重写查询以获得更好的性能? 放弃索引带来的小收益,不使用索引会怎么样?
现有的索引也需要定期进行严格的审查。应该考虑删除所有未使用的索引(那些在pg_stat_user_indexes中idx_scan为零的索引)。像pgexperts这样的脚本可以帮助进行分析。
今年即将发布的PostgreSQL 16在pg_stat_user_indexes / pg_stat_all_indexes中增加了一个列,名为last_idx_scan,它可以告诉我们最后一次使用索引是什么时候(时间戳)。这将帮助我们全面了解系统中的所有索引。
总结:
简单来说就是:索引是有代价的,而且代价可能是多方面的。索引并不总是合适的,顺序扫描也不总是坏的。调优策略一般是自顶而下的,可以从主机硬件、操作系统、PostgreSQL参数等开始调优,从而获得更好的结果。在创建索引之前,进行客观的“成本效益分析”很重要。
参考:
https://www.percona.com/blog/postgresql-indexes-can-hurt-you-negative-effects-and-the-costs-involved/