1、背景
由数据分析师提出的需求,需要分析每10s各个区域(颗粒度到H3Code 8级 面积约0.7平方公里)的司机分布情况,实现准实时的区域司机分布。
H3Code的概念可以参考以下博客:
Uber H3简单介绍_Scc_hy的博客-CSDN博客一、什么是H3?将地球空间划分成可是识别的单元。将经纬度H3编码成六边形的网格索引。二、为什么用H3?2.1 GEOHASH存在一些不足不同精度下网格的形状不一且精度的变化幅度时小时大在不同维度的地区会出现地理单元单位面积差异较大的情况存在8邻域到中心网格的距离不相等问题2.2 H3的映射原理简述基于正多边形内角和公式( \theta=(x-2)*180 ), 和顶点和为360计算出,360/ y = (x-2)*180/x 所有y(正多边形个数), x的组合六边形因为边数最多,最接近https://blog.csdn.net/Scc_hy/article/details/120898390uber h3 地理编码_坦桑尼亚奥杜威峡谷能人的博客-CSDN博客python 包:from h3 import h3def geth3(lon, lat, levelnum): h3_address = h3.geo_to_h3(lat, lon, levelnum) # 纬度,经度,地块级别 hex_center_coordinates = h3.h3_to_geo(h3_address) hex_boundary = h3.h3_to_geo_boundary(h3_address) return h3_addresslo
https://blog.csdn.net/l1159015838/article/details/115796715?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165072203416780271554412%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=165072203416780271554412&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-29-115796715.142%5Ev9%5Econtrol,157%5Ev4%5Econtrol&utm_term=H3code+%E7%BA%A7%E5%88%AB&spm=1018.2226.3001.4187
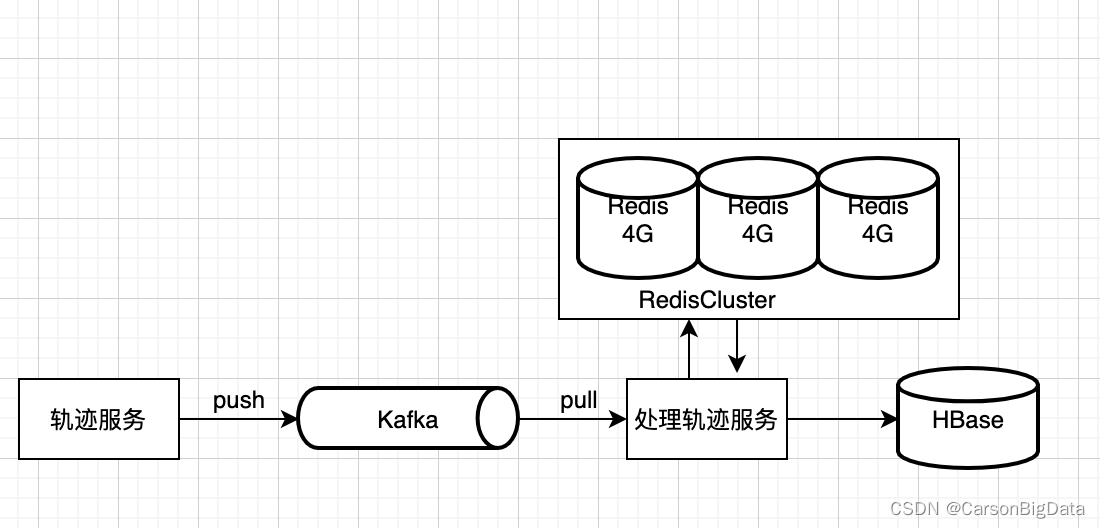
2、技术架构
数据来源:Kafka
处理端:Springboot + 线程池
数据缓存:RedisCluster
定时调度: SpringScheduer + Redis分布式锁
数据写入:Hbase
架构图如下:
3 数据处理流程
3.1 流程说明
流程说明”
- 消费kafka的司机轨迹数据
- 计算轨迹的H3Core,按照设计的一级缓存和二级缓存,采用pipeline写入Redis;
- 定时调度每分钟执行一次,采用Redis分布式锁保证调度的幂等,先获取二级索引,从而获取一级索引;
- 查询出值之后,写入Hbase环境,配置200条flush一次;
流程图如下:
待补充
3.2 Key的设计
3.1 Redis
一级索引设计:
key设计:{特定业务前缀:时间}:H3Core反转
{driver:202104271530}:3426776776
{order:202104271530}:4356557677
{ext:202104271530}:7686654564
value设计:(hash 格式)
key:司机id
value:kafka每条轨迹的详细信息
二级索引设计:
key设计: {特定业务前缀:时间yyyymmddhhMMss}:分片id
例:
{driver:202104271530}:1
{driver:202104271530}:2
.....................................
{driver:202104271530}:10
value: 一级索引的key
例:
3.2 Hbase
Rowkey设计
H3Core反转+日期yyyymmddhhMMss
列族设计(时间精确到每10s)分成三个 分别是 driver order ext
列分别是 列族:时间
例如:
| 司机:时间 | 订单:时间 | 其他附加信息:时间 |
| driver:20220601123000 | order:20220601123000 | ext:20220601123000 |
4 考虑的一些细节
4.1 考虑RedisCluster、Hbase的数据倾斜
H3Core进行反转
4.2 考虑司机轨迹消息迟到太久的补偿
做了一个类似Flink水印的设计,超过定时调度的时间就直接push到kafka的补偿队列,补偿队列1小时处理一次;
4.3 考虑Redis性能,包括二级索引的是否分片、司机轨迹是否去重、采用pipeline的方式写入数据
1、二级索引分片:考虑到后期开城的数量越来越多、H3Core越来越多会导致Key越来越多,如果一个key里面存太多key
2、司机轨迹去重: 考虑到10s内司机的轨迹不会太大变化,去重可以提升计算速度和优化Hbase的存储空间,降到1/10(如果实在没办法再考虑,下策);
3、采用pipeline的方式写入数据:由于Kafka批量消费,所以里面会有不同司机的不同轨迹,所以会产生多个H3Core,因此会产生多个Key,这时采用pipeline管道写入,可以提升Redis的写入效率;
4.4 考虑kafka是否为了提高性能,是否允许极少部分数据丢失
允许自动offset,设置批量消费,kafka的配置
5 遇到的问题以及处理
5.1 RedisCluster的CPU和内存占用过高
分析原因:scan指令
解决方法:Redis的key的二级索引
5.2 处理端处理速度过慢,每分钟司机轨迹的处理速度需要30s,有安全隐患
分析原因:scan Redis集群上的key速度过慢,司机轨迹去重处理导致处理时间过长;
解决方法:采用二级索引存放Redis的key,Redis的数据格式,由原来的list改成hash,减少处理时间;