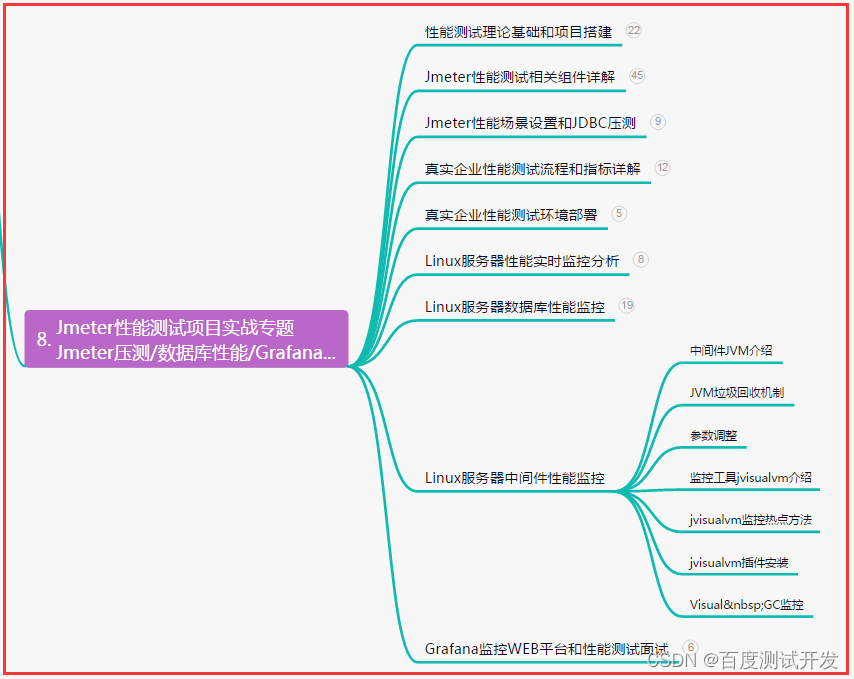
我将用图文的形式,把市面上优质的课程加以自己的理解,详细的把:创建一个uniCloud的应用,其中的每一步记录出来,方便大家写项目中,做到哪一步不会了,可以轻松翻看文章进行查阅。(此文长期更新连载)
目录
读操作getById(了解)
调用云函数
查询条件
limit
skip
orderBy
field
where查询
根据id查
多条件查询
command
neq
in 在数组中(非区间)
且/或(区间)
db.RegExp正则表达式查询
updated修改更新
批量
update结合command的数组高级操作
set与update区别
读操作getById(了解)
先写一个容器,一会放查出来的数据
<view class="home">
<view class="out">
<view class="row">
姓名:{{}}
</view>
</view>
</view>
调用云函数
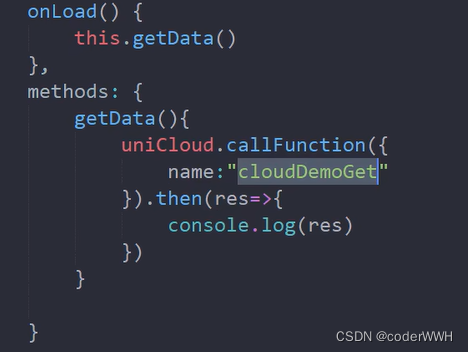
云函数这样写
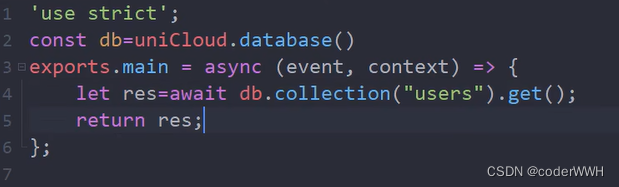
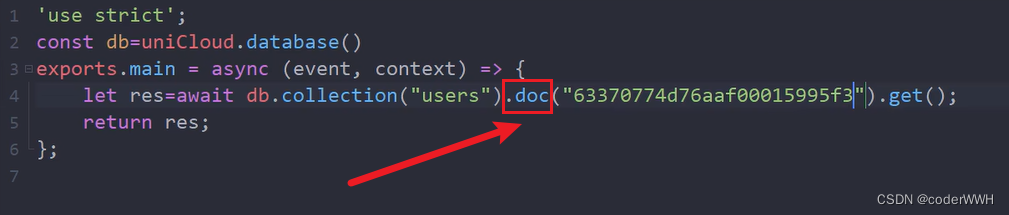
也就是说 .doc 要配合 .get 使用
我理解的就是:getById
查询条件
| 查询条件 | where | 通过指定条件筛选出匹配的记录,可搭配查询指令(eq, gt, in, ...)使用 |
| skip | 跳过指定数量的文档,常用于分页,传入 offset | |
| orderBy | 排序方式 | |
| limit | 返回的结果集(文档数量)的限制,有默认值和上限值 | |
| field | 指定需要返回的字段 |
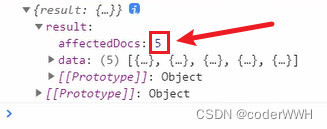
limit

限制数量
结果:
skip
配合limit,用于分页
比如1页5条,要查第2页的数据,就需要把前5条过滤掉不是?
所以就这样写

当然一般不会直接写个 skip(5),一般会写 skip(页数 * 每页几条)
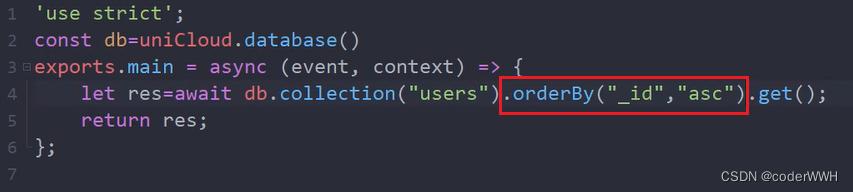
orderBy
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| field | string | 是 | 排序的字段 |
| orderType | string | 是 | 排序的顺序,升序(asc) 或 降序(desc) |
field
指定需要返回的字段
collection.field({ 'name': true }) //只返回name字段、_id字段,其他字段不返回
where查询
可以代替doc
doc只能根据id查,where可以查任何字段
根据id查
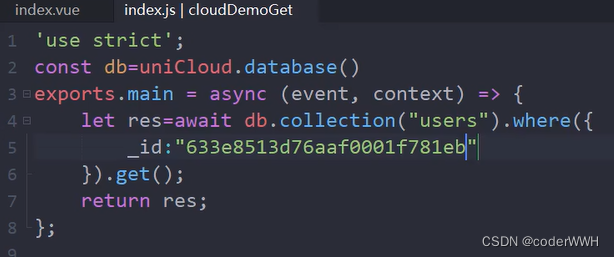
就像这样!
也可以查询别的字段
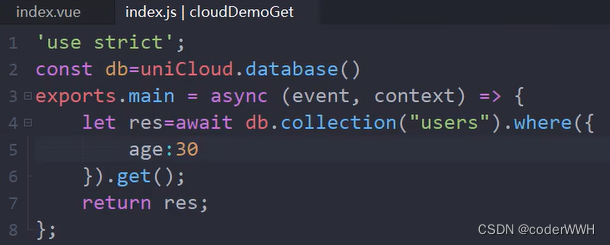
多条件查询
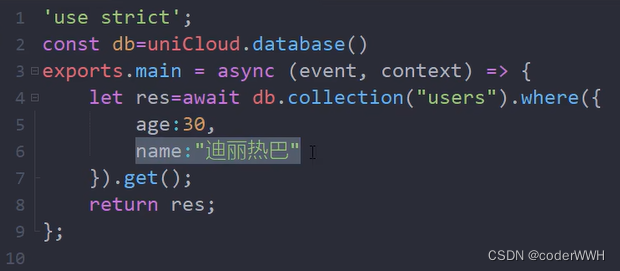
command
就把他理解成对要查询的字段的一些限制

这个等于30,是看不出什么区别,重点是其他,比如大于小于之类的
| 类型 | 接口 | 说明 |
|---|---|---|
| 比较运算 | eq | 字段等于 == |
| neq | 字段不等于 != | |
| gt | 字段大于 > | |
| gte | 字段大于等于 >= | |
| lt | 字段小于 < | |
| lte | 字段小于等于 <= | |
| in | 字段值在数组里 | |
| nin | 字段值不在数组里 | |
| 逻辑运算 | and | 表示需同时满足指定的所有条件 |
| or | 表示需同时满足指定条件中的至少一个 |
neq
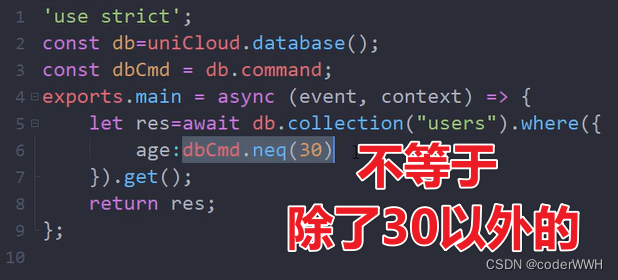
其他也同样
in 在数组中(非区间)
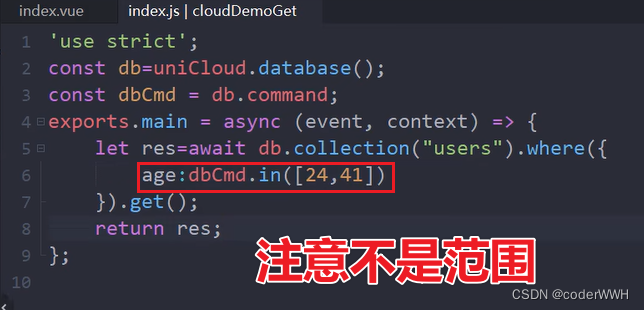
这不是年龄段 就是单独的每一个值
且/或(区间)

就是2个操作符结合起来
db.RegExp正则表达式查询
db.RegExp
// 可以直接使用正则表达式
db.collection('articles').where({
version: /^\ds/i
})
// 也可以使用new RegExp
db.collection('user').where({
name: new RegExp('^\\ds', 'i')
})
// 或者使用new db.RegExp,这种方式阿里云不支持
db.collection('articles').where({
version: new db.RegExp({
regex: '^\\ds', // 正则表达式为 /^\ds/,转义后变成 '^\\ds'
options: 'i' // i表示忽略大小写
})
})
有关正则后面单独出文章讲解
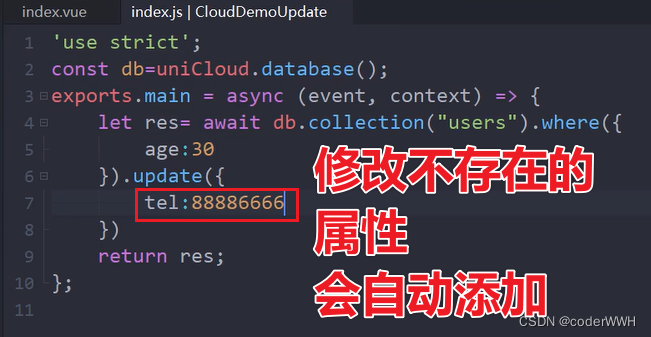
updated修改更新
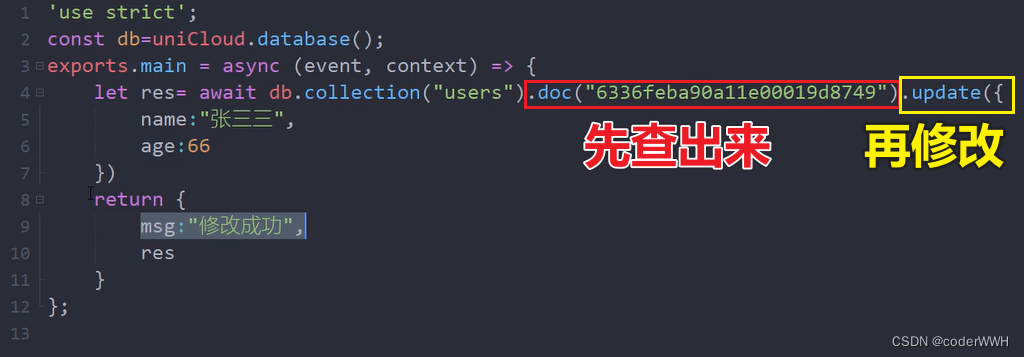
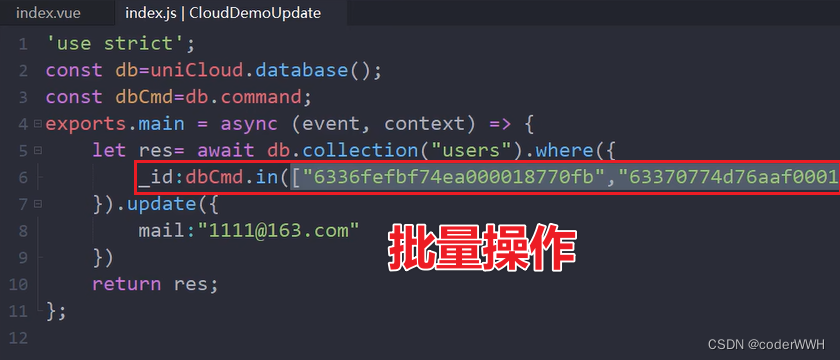
批量
update结合command的数组高级操作
set与update区别
| 接口 | 说明 | |
|---|---|---|
| 写 | update | 局部更新记录(触发请求)只更新传入的字段。如果被更新的记录不存在,会直接返回更新失败 |
| set | 覆写记录;会删除操作的记录中的所有字段,创建传入的字段。如果操作的记录不存在,会自动创建新的记录 |
set会整个覆盖