TCC(补偿事务)
TCC 属于目前比较火的一种柔性事务解决方案。TCC 这个概念最早诞生于数据库专家帕特 · 赫兰德(Pat Helland)于 2007 发表的 《Life beyond Distributed Transactions: an Apostate’s Opinion》 这篇论文,感兴趣的小伙伴可以阅读一下这篇论文。
三个阶段
简单来说,TCC 是 Try、Confirm、Cancel 三个词的缩写,它分为三个阶段:
- Try(尝试)阶段 : 尝试执行
完成业务检查,并预留好必需的业务资源。
- Confirm(确认)阶段 :确认执行
当所有事务参与者的 Try 阶段执行成功就会执行 Confirm ,Confirm 阶段会处理 Try 阶段预留的业务资源。否则,就会执行 Cancel 。
通常情况下,采用 TCC 则认为 Confirm 阶段是不会出错的。即:只要 Try 成功,Confirm 一定成功。若 Confirm 阶段真的出错了,需引入重试机制或人工处理。
- Cancel(取消)阶段 :取消执行,释放 Try 阶段预留的业务资源
通常情况下,采用 TCC 则认为 Cancel 阶段也是一定成功的。若 Cancel 阶段真的出错了,需引入重试机制或人工处理。
TM 事务管理器
- TM 事务管理器可以实现为独立的服务,也可以让全局事务发起方充当 TM 的角色,TM 独立出来是为了成为公共组件,是为了考虑系统结构和软件复用
- TM 在发起全局事务时生成全局事务记录,全局事务 ID 贯穿整个分布式事务调用链条,用来记录事务上下文,追踪和记录状态,由于 Confirm 和 Cancel 失败需要重试,因此需要实现幂等性,幂等性是指同一个操作无论请求多少次,其结果都相同
示例介绍
我们拿转账场景来说:
-
Try(尝试)阶段 : 在转账场景下,Try 要做的事情是就是检查账户余额是否充足,预留的资源就是转账资金
-
Confirm(确认)阶段 : 如果 Try 阶段执行成功的话,Confirm 阶段就会执行真正的扣钱操作
-
Cancel(取消)阶段 :释放 Try 阶段预留的转账资金
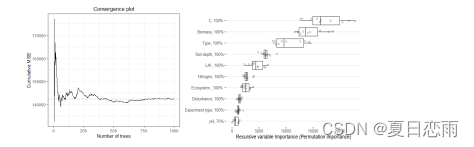
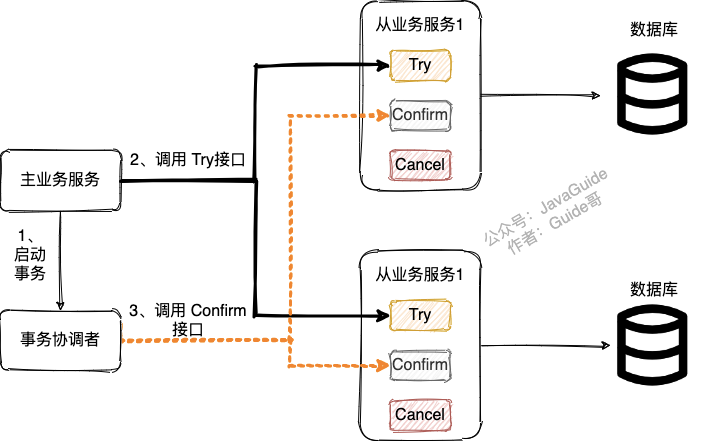
一般情况下,当我们使用 TCC 模式的时候,需要自己实现 try, confirm, cancel 这三个方法,来达到最终一致性。也就是说,正常情况下会执行 try, confirm,如下图所示。
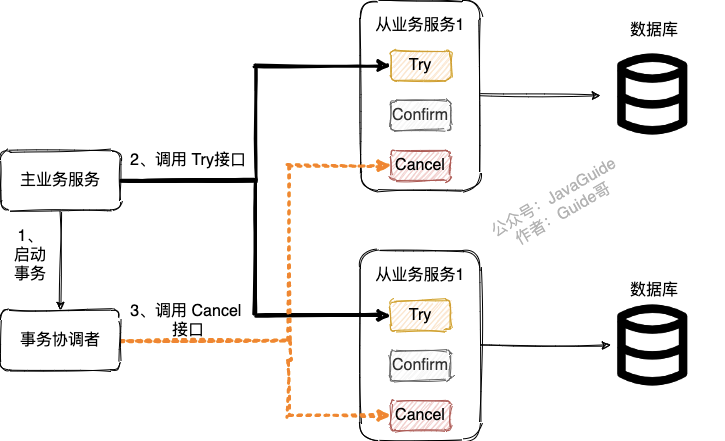
出现异常的话会执行 try, cancel ,如下图所示。
因此,TCC 模式不需要依赖于底层数据资源的事务支持,但是需要我们手动实现更多的代码,属于 侵入业务代码 的一种分布式解决方案。
针对 TCC 的实现,业界也有一些不错的开源框架。不同的框架对于 TCC 的实现可能略有不同,不过大致思想都一样。
-
ByteTCC : ByteTCC 是基于 Try-Confirm-Cancel(TCC)机制的分布式事务管理器的实现。 相关阅读:关于如何实现一个 TCC 分布式事务框架的一点思考
-
Seata :Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。
-
Hmily : 金融级分布式事务解决方案。
空回滚、幂等、悬挂
空回滚:
- 在没调用 Try 方法的情况下,调用了第二阶段的 Cancel 方法,Cancel 方法需要识别出这是一个空回滚,然后直接返回成功
- 出现原因是当一个分支事务所在服务宕机或网络异常,分支事务调用记录为失败,这个时候其实是没有执行 Try 阶段,当故障恢复后,分布式事务进行回滚则会调用第二阶段的 Cacel 方法,从而形成空回滚
- 解决思路是关键就是要识别出这个空回滚。思路很简单就是需要知道一阶段是否执行,如果执行了,那就是正常回滚。如果没有执行,那就是空回滚。前面已经说过 TM 在发起全局事务时生成全局事务记录,全局事务 ID 贯穿整个分布式事务调用链条。再额外增加一张分支事务记录表,其中有全局事务 ID 和分支事务 ID,第一阶段 Try 方法里会插入一条记录,表示一阶段执行了。Cancel 接口里读取该记录,如果该记录存在,则正常回滚;如果该记录不存在,则是空回滚
幂等:
- 通过前面介绍已经了解到,为了保证 TCC 二阶段提交重试机制不会引发数据不一致,要求 TCC 的二阶段 Try、Confirm 和 Cancel 接口保证幂等,这样不会重复使用或者释放资源。如果幂等控制没有做好,很有可能导致数据不一致等严重问题
- 解决思路在上述“分支事务记录”中增加执行状态,每次执行前都查询该状态
悬挂:
- 悬挂就是对于一个分布式事务,其二阶段 Cancel 接口比 Try 接口先执行
- 出现原因是在 RPC 调用分支事务 try 时,先注册分支事务,再执行 RPC 调用,如果此时 RPC 调用的网络发生拥堵,通常 RPC 调用是有超时时间的,RPC 超时以后,TM 就会通知 RM 回滚该分布式事务,可能回滚完成后,RPC 请求才到达参与者真正执行,而一个 Try 方法预留的业务资源,只有该分布式事务才能使用,该分布式事务第一阶段预留的业务资源就再也没有人能够处理了,对于这种情况,我们就成为悬挂,即业务资源预留后没法继续处理
- 解决思路时候如果二阶段执行完成,那一阶段就不能再继续执行。再执行一阶段事务时判断在该全局事务下,“分支事务记录”表中是否已经有二阶段事务记录,如果有则不执行 Try
参考
- [JavaGuide]
- 分布式事务(三):分布式事务解决方案之TCC(Try、Confirm、Cancel)
- 分布式事务(五):分布式事务解决方案之最大努力通知