1. 概述
应用场景:
给你一个巨大的文档数据,文档中存储着许多非结构化的数据,如下:
{“id” : “1”, “name” : “佛山张学友”, “age” : “15”},
{“name” : “广州周润发”, “height” : “182”},
…中间有10000万行…
{“style” : “music”, “name” : “深圳薛之谦”},
{“name” : “东莞赵丽颖”}
找出name的属性值为 “深圳薛之谦” 的数据。
方案一:解析文档数据,按顺序查找第一行数据、第二行数据 … 第n-1行数据(此时找到name属性值为 “深圳薛之谦” 的数据,提取)、第n行数据。
方案二:为name属性建立索引,然后通过name索引找到属性值为 “深圳薛之谦” 的name数据列,然后提取所有相关的数据;
方案一,在少量数据占据极大的优势,因为不用维护索引表,同时查找效率也较高;
方案二,在大量数据占据特大的优势,因为可以通过索引快速找到相关的列。
而方案二的这种思想就是Elesticesearch的设计理念。
同时,Elesticesearch还引入中文分词插件。他会对搜索词进行分词,然后再进行查找(跟我们的搜索引擎类似,对搜索关键词进行分词后再查找。)
2. Elesticesearch VS MySQL
Elesticesearch做的更多的是在大数据中快速的检索出与搜索词相关的数据; MySQL更多的是存储少量数据并操作,在大量的数据并不能发挥出很大的查询性能。例如:
在百亿数据中查找包含 “深圳薛之谦” 的数据,
- MySQL有强大的索引功能,但是还是需要在小时的时间成本上,才能搜索相关的数据出来;
- Elesticesearch可以在毫秒级别响应,同时可以根据综合评分,搜索出其他相关的数据,例如深圳薛之谦的住处、行业等数据(可以类比搜索引擎)。
3. 安装
-
ElasticSearch
下载地址:https://www.elastic.co/cn/ -
ElasticSearch连接可视化界面
下载地址:https://github.com/mobz/elasticsearch-head.git(npm install+npm run start)

连接会出现跨域问题(后端9200端口,前端9100端口),修改ElasticSearch的config-elasticsearch.yml文件,添加跨域请求
http:
cors:
enabled: true
allow-origin: "*"
连接成功!

- Kibana
下载地址:https://www.elastic.co/cn/kibana/
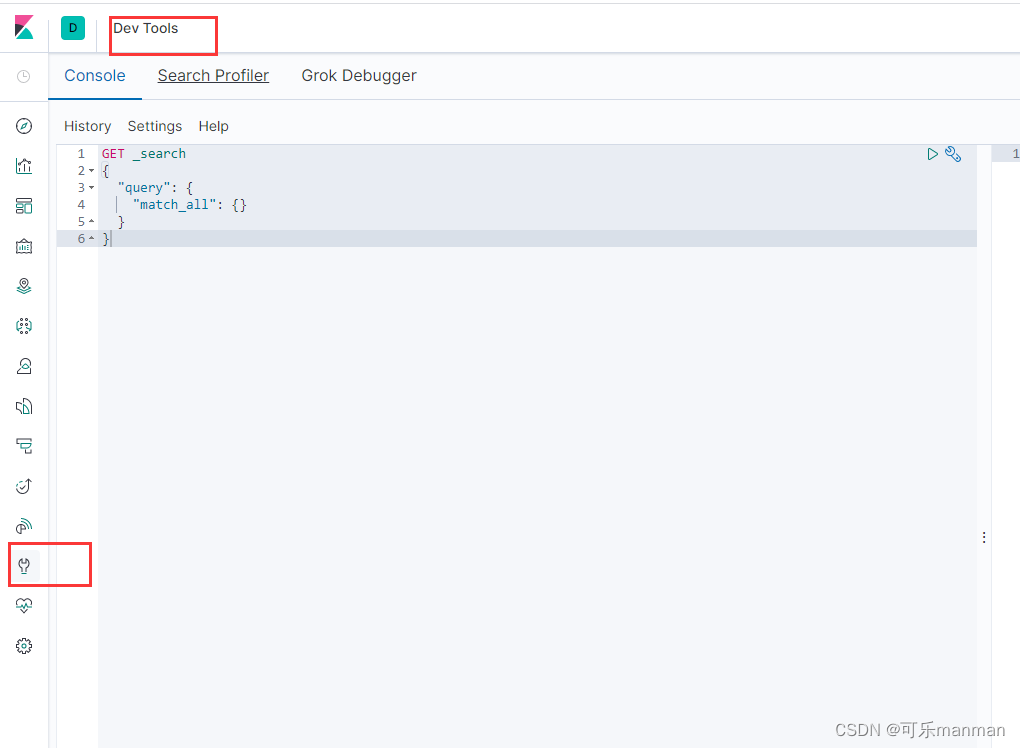
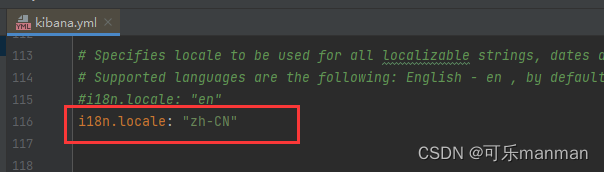
Kibana汉化(config-kibana.yml):
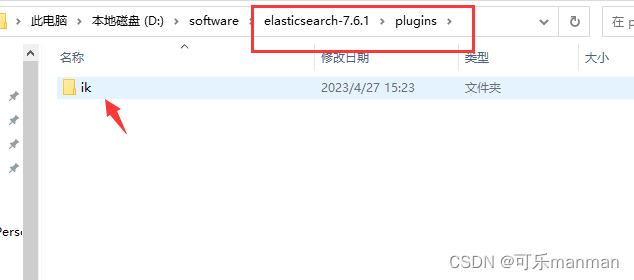
- ik分词器
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
下载后放到ElasticSearch的插件中去
利用kibana对输入进行分词操作:
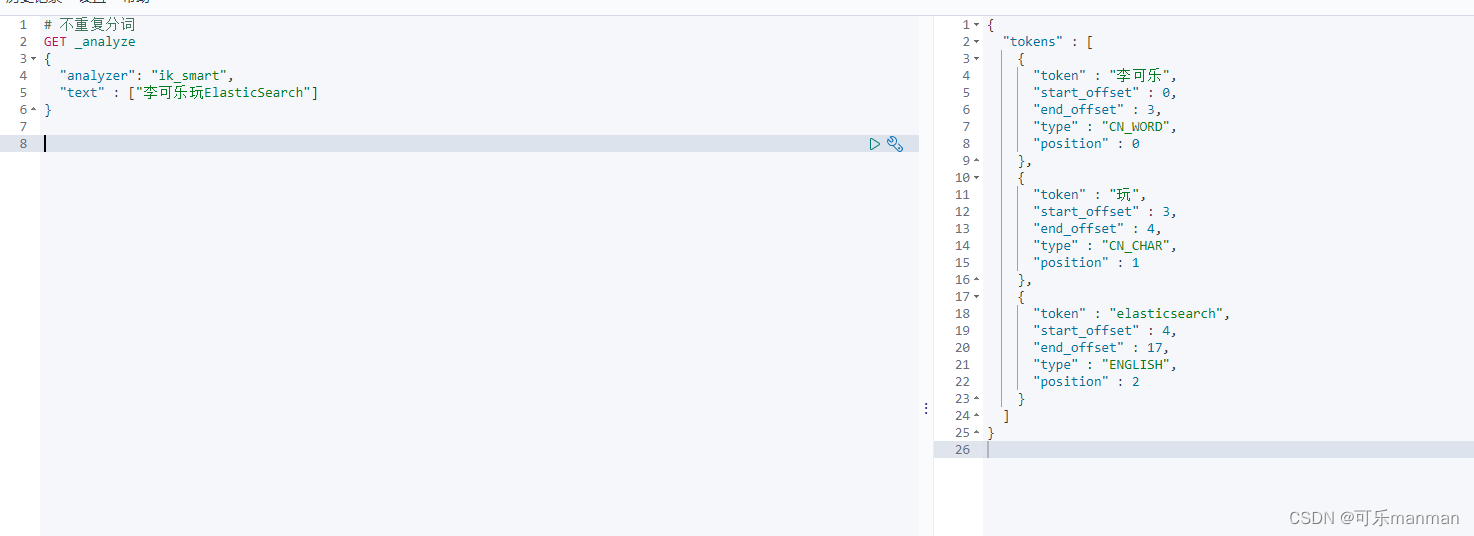
所有软件都放在微信公众号上:可乐大数据
发送:ElasticSearch
3. ES的一些名词
| 数据库 | ES |
|---|---|
| 数据库 | 索引 |
| 表 | types |
| 行 | documents |
| 字段 | fields |
物理设计:
将索引切成多个文件,然后存储在不同的ElasticSearch服务器上(DB:将数据库划分成多个表)
倒排索引:
类比搜索引擎,如果查找 “李可乐玩ElasticSearch” 应该怎么在百亿数据中对应关键句子呢?
正序索引:将输入进行分词 ==> “李可乐”、“玩”、“ElasticSearch”。然后到相关文档(document)查找包含这些词,然后返回对应的句子即可。
逆序索引:将字典统计出来,字典的key就是单词,value就是文档id,如下图。
4. 常用命令
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | locahost:9200/索引名称/类型名称/文档id | 删除文档,通过文档id |
| GET | localhost:9200/索引名称/类型名称/文档id | 查询文档,通过文档id |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 |
# 插入数据
PUT /test_db/user/1
{
"name" : "李可乐",
"age" : 14
}
PUT /test_db/user/2
{
"name" : "张三"
}
PUT /test_db/user/3
{
"name" : "李四",
"age" : 15
}
PUT /test_db/user/4
{
"name" : "王五"
}
PUT /test_db/user/5
{
"name" : "赵六"
}
# 查询所有
GET /test_db/user/_search
# 查询 + 条件(模糊查询,top-k返回)
GET /test_db/user/_search?q=name:李可乐
# 多条件查询
GET /test_db/user/_search
{
"query": {
"match": {
"name": "李"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 1
}
# 查询单个
GET /test_db/user/1
# 更新
POST /test_db/user/1/_update
{
"doc" : {
"name" : "李可乐"
}
}
5. SpringBoot集成ES
1. 导入maven依赖<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
</dependencies>
- ES连接配置类
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("127.0.0.1", 9200, "http")
)
);
return client;
}
}
- 一些相关的CRUD
@SpringBootTest(classes = TestApp.class)
public class ESApp {
@Autowired
private RestHighLevelClient client;
/**
* 索引操作
* @throws Exception
*/
@Test
public void createIndex() throws Exception{
IndicesClient indicesClient = client.indices();
CreateIndexRequest request = new CreateIndexRequest("cola_index_1");
CreateIndexResponse createIndexResponse = indicesClient.create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse.toString());
}
@Test
public void existIndex() throws Exception{
GetIndexRequest getIndexRequest = new GetIndexRequest("cola_index_1");
boolean exists = client.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
@Test
public void deleteIndex() throws Exception{
DeleteIndexRequest request = new DeleteIndexRequest("cola_index_1");
AcknowledgedResponse response = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}
/**
* 文档操作
* @throws Exception
*/
@Test
public void addDocument() throws Exception{
User user = new User("1", "张三");
IndexRequest request = new IndexRequest("cola_index_1");
// cola_index_1/_doc/1
request.id("1");
request.source(JSON.toJSONString(user), XContentType.JSON);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
System.out.println(response.toString());
}
@Test
public void updateDocument() throws Exception{
User user = new User("1", "小张三");
UpdateRequest request = new UpdateRequest("cola_index_1", "1");
UpdateRequest updateRequest = request.doc(JSON.toJSONString(user), XContentType.JSON);
UpdateResponse response = client.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(response.toString());
}
@Test
public void deleteDocument() throws Exception{
DeleteRequest request = new DeleteRequest("cola_index_1", "1");
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
System.out.println(response.toString());
}
@Test
public void getDocument() throws Exception{
SearchRequest request = new SearchRequest("cola_index_1");
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
}
}








![博客系统[Java]](https://img-blog.csdnimg.cn/27ee73fa76c64a0faa8b89f152654113.png)

