前言
驾考不易,天天早起去练车,无论烈日还是下雨,通通都在室外进行,但想要拿证,一定要坚
持不懈的去练车。
所有文章完整的素材+源码都在👇👇
粉丝白嫖源码福利,请移步至CSDN社区或文末公众hao即可免费。

小编就是在一复一日的练习中,终于得到了我人生中以为不可能考证之驾照到手了!

这不?驾照到手了,下一步是需要什么呢?当然是需要车子了啦,为了方便练车上路开,新车
我是不敢上手的,这不小心磕着哪儿了不得心疼洗呢!哈哈哈,所以小编就想着看看有合适的
二手车没得,就有了今天的内容,今天手把手教大家用代码一键下载海量二手车资源,让我来
看看实惠又好用的款式给我爬下来并做一做实现数据可视化展示,挑一挑蛮~

正文
一、运行环境
1)开发环境
版 本: python 3.8
编辑器:pycharm 2022.3.2
requests、parsel >>> pip install requests 或parsel
+python安装包 安装教程视频。
+pycharm 社区版 专业版 及 激活码免费找我拿即可 。2)模块安装
pip install 模块名 镜像源安装 pip install -i pypi.douban.com/simple/ +模块名
Python 安 装包 安装教程视频 pycharm 社区版 专业版 及 激活码免费找我拿即可 !
(各种版本的都 有,可以一整套直接分享滴~)
按住键盘 win + r, 输入cmd回车 打开命令行窗口, 在里面输入 pip install 模块名 。二、爬虫基本思路流程: <公式>
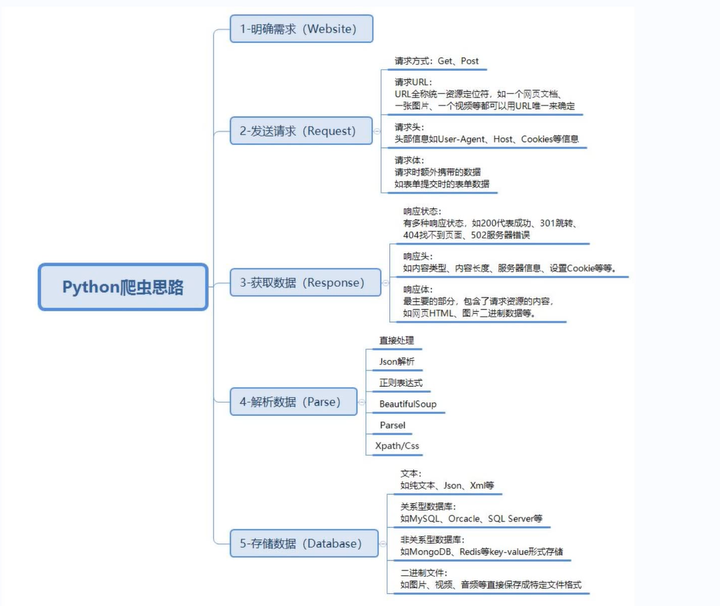
1. 明确需求
明确采集网站是什么? https://changsha.taoche.com/all/?page=1&#pagetag
明确采集数据是什么? 车辆基本信息 。
2. 发送请求
模拟浏览器对于url地址发送请求 。
请求链接: https://changsha.taoche.com/all/?page=1&#pagetag
3. 获取数据
获取网页源代码 <服务器返回响应数据> 。
4. 解析数据
提取我们想要的数据内容 5. 保存数据, 把数据内容保存表格 <csv Excel>。
三、代码展示
主程序——
"""
# 导入数据请求模块 <第三方模块, 需要安装 pip install requests>
import requests
# 导入数据解析模块 <第三方模块, 需要安装 pip install parsel>
import parsel
# 导入csv
import csv
# open内置函数 --> 创建文件
f = open('data1.csv', mode='w', encoding='utf-8', newline='')
# 调用csv模块里面字典写入DictWriter f文件对象 fieldnames 字段名 <表头>
csv_writer = csv.DictWriter(f, fieldnames=[
'标题'
'年份',
'里程',
'城市',
'价格',
'标签',
'保修',
'详情页',
])
# 写入表头
csv_writer.writeheader()
"""
1. 发送请求, 模拟浏览器对于url地址发送请求
请求链接: https://changsha.taoche.com/all/?page=1
"""
for page in range(1, 51):
try:
# 请求链接
url = f'https://changsha.taoche.com/all/?page={page}'
# 模拟浏览器 < headers请求头 >
headers = {
# User-Agent 用户代理, 表示浏览器基本身份信息
'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求
# 通过requests模块里面get请求方法对于url地址发送请求, 并且携带上headers请求头伪装, 最后用自定义变量名接受返回数据
response = requests.get(url=url, headers=headers)
# <Response [200]> 响应对象 200 状态码表示请求成功
print(response)
"""
2. 获取数据, 获取网页源代码 <服务器返回响应数据>
response.text 获取响应的文本数据 <获取网页源代码>
3. 解析数据, 提取我们想要的数据内容
解析方法: 都要掌握, 那个方便用那个
re : 直接提取字符串数据
css : 根据标签属性提取数据内容
xpath: 根据标签节点提取数据内容
css选择器: 会 1 不会 0
1. 查看车次信息, 所对应标签位置是什么
"""
# 转换数据, 把获取到 html字符串数据 <response.text>, 转成可解析对象
selector = parsel.Selector(response.text) # <Selector xpath=None data='<html lang="en">\n<head>\n <meta cha...'>
print(selector)
# 获取所有li标签 --> 获取多个数据, 返回列表
lis = selector.css('.Content_left .gongge_ul .li')
# for循环遍历, 把列表里面元素一个一个提取出来
for li in lis:
"""
根据具体数据所对应标签进行提取
语法规定:
get 提取第一个标签数据 字符串
getall 提取所有标签数据 列表
"""
# 标题
title = li.css('a.title span::text').get()
# 信息
info = li.css('.gongge_main p i::text').getall()
year = info[0].replace('年', '')# 年份
km = info[1].replace('万公里', '') # 里程
city = info[2].strip() # 城市
# 价格
price = li.css('.price .Total::text').get()
tag = li.css('.car_tag em::text').get().strip() # 标签
label = li.css('.tc_label::text').get() # 是否保修
href = li.css('a.title::attr(href)').get() # 详情页
dit = {
'标题': title,
'年份': year,
'里程': km,
'城市': city,
'价格': price,
'标签': tag,
'保修': label,
'详情页': href,
}
# 写入数据
csv_writer.writerow(dit)
print(title, year, km, city, price, tag, label, href)
except:
print('有小bug哦,需要视频学习记得找我哦') 四、效果展示
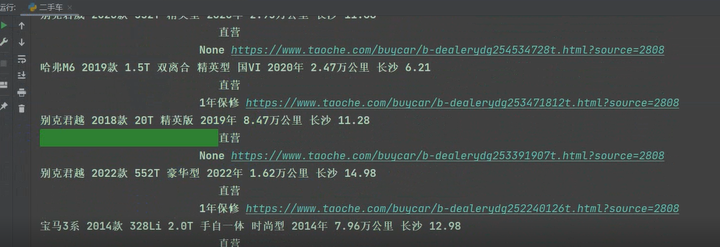
四、效果展示
1)爬虫下载效果

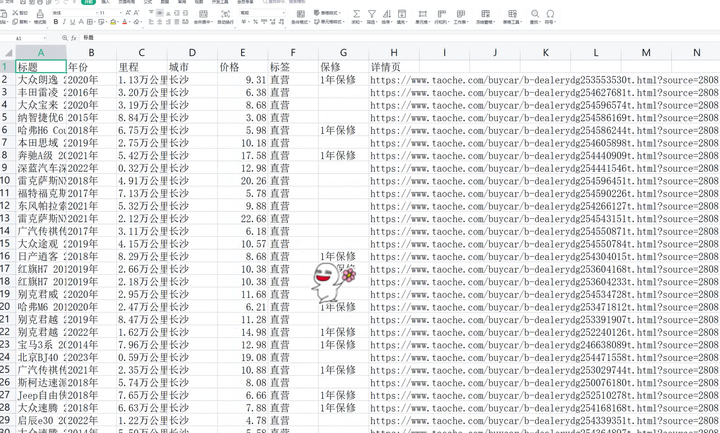
2)保存在excel
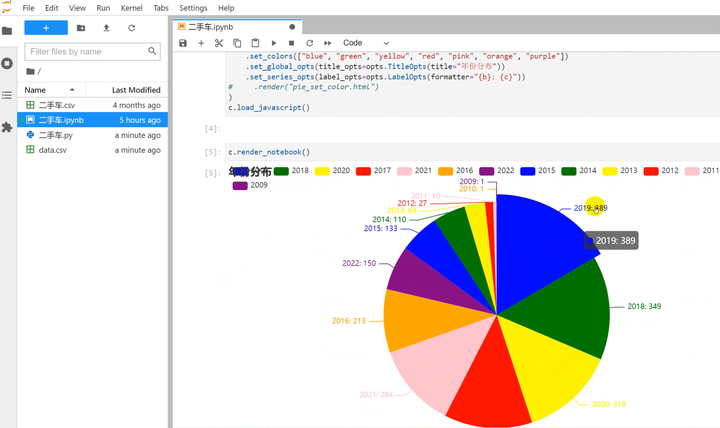
3)数据分析可视化
可视化效果只展示小部分,需要的直接滴滴我即可拿数据跟数据的代码等。
二手车年份分布可视化
汽车平牌数量前十
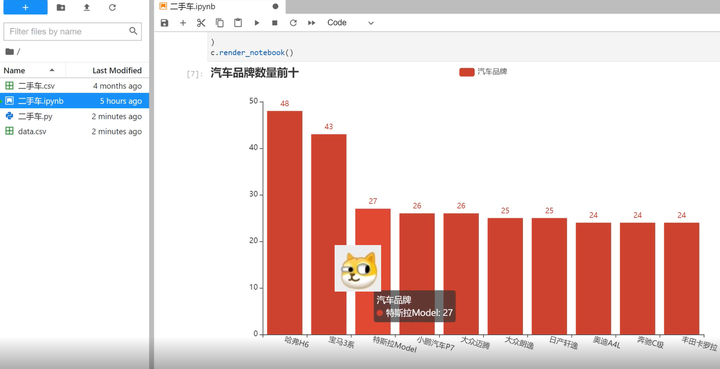
总结
当然了,没有一款车是完美的,多看看的话,总能找到适合自己的车子啦~
今天栗子教大家写的代码就到这里正是结束了呢,想要学习爬虫跟数据分析的小伙伴儿记得赶
紧关注我啦!
✨完整的素材源码等:可以滴滴我吖!或者点击文末hao自取免费拿的哈~
🔨推荐往期文章——
项目1.3 高清壁纸爬虫
【Python实战】美哭你的极品壁纸推荐|1800+壁纸自动换?美女动漫随心选(高清无码)
项目0.9 【Python实战】WIFI密码小工具,甩万能钥匙十条街,WIFI任意连哦~(附源码)
项目1.0 【Python实战】再分享一款商品秒杀小工具,我已经把压箱底的宝贝拿出来啦~
项目0.1 宝藏拼图神秘上线,三种玩法刷爆朋友圈—玩家直呼太上瘾了。
🎁文章汇总——
Python文章合集 | (入门到实战、游戏、Turtle、案例等)
(文章汇总还有更多你案例等你来学习啦~源码找我即可免费!)








![博客系统[Java]](https://img-blog.csdnimg.cn/27ee73fa76c64a0faa8b89f152654113.png)


![C++——类和对象[上]](https://img-blog.csdnimg.cn/img_convert/72e265b270c8b0f3f4349794a11d16a6.png)