简介
Zookeeper集群;(必须事先准备);
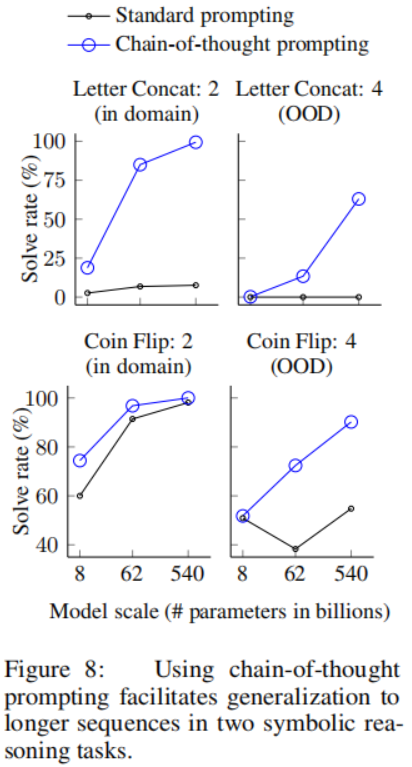
1、介绍kafka是什么;
消息队列;kafka就是一个消息队列MQ; elk需要使用kafka来传递日志消息;
一、传统方式部署kafka集群
1 环境说明
192.168.79.34 node1
192.168.79.35 node2
192.168.79.36 node3
#仍在之前的kafka环境
2 node节点操作:
#所有节点操作:
yum install java java-devel -y
wget https://archive.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz
tar xf kafka_2.12-2.2.0.tgz -C /opt
ln -s /opt/kafka_2.12-2.2.0/ /opt/kafka
mkdir /opt/kafka/data
3 修改kafka配置
cat /opt/kafka/config/server.properties
node1
############################# Server Basics
# broker的id,值为整数,且必须唯一,在一个集群中不能重复
broker.id=1
############################# Socket ServerSettings
# kafka监听端口,默认9092
listeners=PLAINTEXT://192.168.79.34:9092
# 处理网络请求的线程数量,默认为3个
num.network.threads=3
# 执行磁盘IO操作的线程数量,默认为8个
num.io.threads=8
# socket服务发送数据的缓冲区大小,默认100KB
socket.send.buffer.bytes=102400
# socket服务接受数据的缓冲区大小,默认100KB
socket.receive.buffer.bytes=102400
# socket服务所能接受的一个请求的最大大小,默认为100M
socket.request.max.bytes=104857600
############################# Log Basics
# kafka存储消息数据的目录
log.dirs=../data
# 每个topic默认的partition
num.partitions=1
# 设置副本数量为3,当Leader的Replication故障,会进行故障自动转移。
default.replication.factor=3
# 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量
num.recovery.threads.per.data.dir=1
############################# Log Flush Policy
# 消息刷新到磁盘中的消息条数阈值
log.flush.interval.messages=10000
# 消息刷新到磁盘中的最大时间间隔,1s
log.flush.interval.ms=1000
############################# Log Retention Policy
# 日志保留小时数,超时会自动删除,默认为7天
log.retention.hours=168
# 日志保留大小,超出大小会自动删除,默认为1G
#log.retention.bytes=1073741824
# 日志分片策略,单个日志文件的大小最大为1G,超出后则创建一个新的日志文件
log.segment.bytes=1073741824
# 每隔多长时间检测数据是否达到删除条件,300s
log.retention.check.interval.ms=300000
############################# Zookeeper
# Zookeeper连接信息,如果是zookeeper集群,则以逗号隔开
zookeeper.connect=192.168.79.34:2181,192.168.79.35:2181,192.168.79.36:2181
# 连接zookeeper的超时时间,6s
zookeeper.connection.timeout.ms=6000
node2
############################# Server Basics
# broker的id,值为整数,且必须唯一,在一个集群中不能重复
broker.id=2
############################# Socket ServerSettings
# kafka监听端口,默认9092
listeners=PLAINTEXT://192.168.79.35:9092
# 处理网络请求的线程数量,默认为3个
num.network.threads=3
# 执行磁盘IO操作的线程数量,默认为8个
num.io.threads=8
# socket服务发送数据的缓冲区大小,默认100KB
socket.send.buffer.bytes=102400
# socket服务接受数据的缓冲区大小,默认100KB
socket.receive.buffer.bytes=102400
# socket服务所能接受的一个请求的最大大小,默认为100M
socket.request.max.bytes=104857600
############################# Log Basics
# kafka存储消息数据的目录
log.dirs=../data
# 每个topic默认的partition
num.partitions=1
# 设置副本数量为3,当Leader的Replication故障,会进行故障自动转移。
default.replication.factor=3
# 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量
num.recovery.threads.per.data.dir=1
############################# Log Flush Policy
# 消息刷新到磁盘中的消息条数阈值
log.flush.interval.messages=10000
# 消息刷新到磁盘中的最大时间间隔,1s
log.flush.interval.ms=1000
############################# Log Retention Policy
# 日志保留小时数,超时会自动删除,默认为7天
log.retention.hours=168
# 日志保留大小,超出大小会自动删除,默认为1G
#log.retention.bytes=1073741824
# 日志分片策略,单个日志文件的大小最大为1G,超出后则创建一个新的日志文件
log.segment.bytes=1073741824
# 每隔多长时间检测数据是否达到删除条件,300s
log.retention.check.interval.ms=300000
############################# Zookeeper
# Zookeeper连接信息,如果是zookeeper集群,则以逗号隔开
zookeeper.connect=192.168.79.34:2181,192.168.79.35:2181,192.168.79.36:2181
# 连接zookeeper的超时时间,6s
zookeeper.connection.timeout.ms=6000
node3
############################# Server Basics
# broker的id,值为整数,且必须唯一,在一个集群中不能重复
broker.id=3
############################# Socket ServerSettings
# kafka监听端口,默认9092
listeners=PLAINTEXT://192.168.79.36:9092
# 处理网络请求的线程数量,默认为3个
num.network.threads=3
# 执行磁盘IO操作的线程数量,默认为8个
num.io.threads=8
# socket服务发送数据的缓冲区大小,默认100KB
socket.send.buffer.bytes=102400
# socket服务接受数据的缓冲区大小,默认100KB
socket.receive.buffer.bytes=102400
# socket服务所能接受的一个请求的最大大小,默认为100M
socket.request.max.bytes=104857600
############################# Log Basics
# kafka存储消息数据的目录
log.dirs=../data
# 每个topic默认的partition
num.partitions=1
# 设置副本数量为3,当Leader的Replication故障,会进行故障自动转移。
default.replication.factor=3
# 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量
num.recovery.threads.per.data.dir=1
############################# Log Flush Policy
# 消息刷新到磁盘中的消息条数阈值
log.flush.interval.messages=10000
# 消息刷新到磁盘中的最大时间间隔,1s
log.flush.interval.ms=1000
############################# Log Retention Policy
# 日志保留小时数,超时会自动删除,默认为7天
log.retention.hours=168
# 日志保留大小,超出大小会自动删除,默认为1G
#log.retention.bytes=1073741824
# 日志分片策略,单个日志文件的大小最大为1G,超出后则创建一个新的日志文件
log.segment.bytes=1073741824
# 每隔多长时间检测数据是否达到删除条件,300s
log.retention.check.interval.ms=300000
############################# Zookeeper
# Zookeeper连接信息,如果是zookeeper集群,则以逗号隔开
zookeeper.connect=192.168.79.34:2181,192.168.79.35:2181,192.168.79.36:2181
# 连接zookeeper的超时时间,6s
zookeeper.connection.timeout.ms=6000
4 启动kafka
cd /opt/kafka/bin
./kafka-server-start.sh -daemon ../config/server.properties
5 kafka集群验证
1、使用kafka创建一个top
cd /opt/kafka/bin
./kafka-topics.sh --create --zookeeper 192.168.79.34:2181,192.168.79.35:2181,192.168.79.36:2181 --partitions 1 --replication-factor 3 --topic lss
2、模拟消息发布者
cd /opt/kafka/bin
# ./kafka-console-producer.sh --broker-list 192.168.79.34:9092,192.168.79.35:9092,192.168.79.36:9092 --topic lss
[root@node4 bin]# ./kafka-console-producer.sh \
> --broker-list 192.168.79.34:9092,192.168.79.35:9092,192.168.79.36:9092 \
> --topic lss
>hello lss
>hello kafka
>
>hellp enchanted
>
3、模拟消息订阅者
cd /opt/kafka/bin
#./kafka-console-consumer.sh --bootstrap-server 192.168.79.34:9092,192.168.79.35:9092,192.168.79.36:9092 --topic lss --from-beginning
[root@node4 bin]# ./kafka-console-consumer.sh \
> --bootstrap-server 192.168.79.34:9092,192.168.79.35:9092,192.168.79.36:9092 \
> --topic lss \
> --from-beginning
hello lss
hello kafka
hellp enchanted
二、传统方式部署efak (kafka可视化)
安装配置jdk (略)
1 efak安装
wget https://linux.oldxu.net/efak-web-3.0.1-bin.tar.gz
tar xf efak-web-3.0.1-bin.tar.gz -C /opt/
ln -s /opt/efak-web-3.0.1/ /opt/efak-web
vim /etc/profile
export KE_HOME=/opt/efak
export PATH=$PATH:$KE_HOME/bin
source /etc/profile
3.1 efak配置修改
cat /opt/efak-web/conf/system-config.properties
# 填写 zookeeper集群列表
efak.zk.cluster.alias=cluster1
cluster1.zk.list=192.168.79.34:2181,192.168.79.35:2181,192.168.79.36:2181
# broker 最大规模数量
cluster1.efak.broker.size=20
# zk 客户端线程数
kafka.zk.limit.size=32
# EFAK webui 端口
efak.webui.port=8048
# kafka offset storage
cluster1.efak.offset.storage=kafka
# kafka jmx uri
cluster1.efak.jmx.uri=service:jmx:rmi://jndi/rmi://%s/jmxrmi
# kafka metrics 指标,默认存储15天
efak.metrics.charts=true
efak.metrics.retain=15
# kafka sql topic records max
efak.sql.topic.records.max=5000
efak.sql.topic.preview.records.max=10
# delete kafka topic token
efak.topic.token=keadmin
# kafka sqlite 数据库地址(需要修改存储路径)
efak.driver=org.sqlite.JDBC
efak.url=jdbc:sqlite:/opt/efak/db/ke.db
efak.username=root
efak.password=www.kafka-eagle.org
# kafka mysql 数据库地址(需要提前创建ke库)
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://192.168.79.35:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=ke
efak.password=123456
3.2 配置数据库
#79.35操作
mysql -uroot -p123456 -e "create database ke"
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=1;
mysql> create user 'ke'@'%' identified by '123456';
mysql> grant all privileges on *.* to 'ke'@'192.168.79.%' IDENTIFIED BY '123456';
mysql> flush privileges;
4 启动efak
/opt/efak-web/bin/ke.sh start
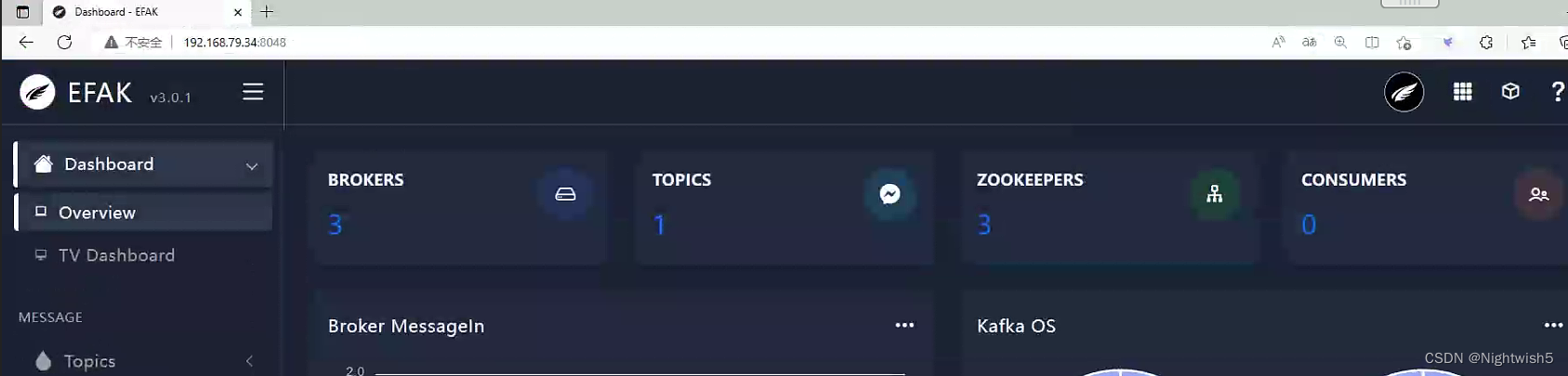
5 访问efak (admin / 123456)
二、制作Kafka集群镜像
2.1 Dockerfile
FROM openjdk:8-jre
RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
echo 'Asia/Shanghai' > /etc/timezone
ENV VERSION=2.12-2.2.0
ADD ./kafka_${VERSION}.tgz /
ADD ./server.properties /kafka_${VERSION}/config/server.properties
RUN mv /kafka_${VERSION} /kafka
ADD ./entrypoint.sh /entrypoint.sh
EXPOSE 9092 9999
CMD ["bin/bash","/entrypoint.sh"]
2.2 server.properties
2.3 entrypoint.sh
2.4 构建镜像并推送仓库
![C++——类和对象[上]](https://img-blog.csdnimg.cn/img_convert/72e265b270c8b0f3f4349794a11d16a6.png)