🧸🧸🧸各位大佬大家好,我是猪皮兄弟🧸🧸🧸

文章目录
- 一、可变模板参数
- 1.通过递归推导参数包
- 2.通过列表初始化推导参数包
- 二、emplace
- 三、lambda表达式
- 1.lambda表达式语法
- 2.使用lambda
- 3.捕捉列表说明
- 4.lambda底层原理
- 四、包装器
- 1.定义包装器
- 2.使用包装器
- 五、bind绑定
一、可变模板参数
可变参数其实早就见过了,比如printf

可变模板参数这里,设计了一个模板参数包
//模板参数包
template<class ...Args>//args是随便起的,但一般都叫Args
void ShowList(Args...args)
{
}
但是其实我们不好从函数参数包中拿到这些参数,sizeof…(args)只能用来指导参数包中有多少个参数,参数包中的参数是不支持像数组一样去取的
template <class ...Args>
void ShowList(Args...args)
{
cout << sizeof...(args) << endl;
}
int main()
{
ShowList();//0
ShowList(1);//1
ShowList(1, 'A');//2
string str = "zhupi";
ShowList(1, 'A', str);//3
return 0;
}
那通过什么方式来推导每个参数呢
1.通过递归推导参数包
可以通过递归
template<class T,class ...Args>
void ShowList(const T&val,Args...args)
{
cout<<"ShowList"<<val<<", "<<sizeof...(args)<<"参数包)"<<endl;
ShowList(args...);
}
//这样就可以通过递归调用,推导出参数类型
但是别人只传一个参数包,我还要自己加一个T,很好方便,也看着不舒服
再看看emplace,它也没有加另外的参数T,它是怎么推出来的?

2.通过列表初始化推导参数包
template<class T>
int PrintArg(const T&x)
{
cout<<x<<" ";
return 0;
}
template<class ...Args>
void ShowList(Args...args)
{
int a[] = {PrintArg(args)...};
cout<<endl;
}
上面的这个了解就行
二、emplace

vector<int> v1;
v1.push_back(1);
v1.emplace_back(2);
这里没有任何却别,因为push_back就是传一个,emplace_back只是传多个而已
但是这里传多个并没有价值,因为数据类型是int,一个参数的,和一个参数的参数包没什么区别
vector<pair<string,int>> v2;
v2.push_back(make_pair("sort",1));
v2.emplace_back("sort",1);
push_back(make_pair(…))是一次构造+一次拷贝构造/移动构造(左值/右值)
而传参数包的话,我只需要传参数过去构造里面的pair(因为里面有列表初始化,可以生成pair)
所以emplace确实在某些地方更高效
所以以后的插入的接口,push/insert都推荐去使用emplace提高效率
三、lambda表达式
lambda表达式也叫作匿名函数
在这之前,可以像函数一样使用的有
①普通的函数指针
②仿函数/函数对象//仿函数是因为C的函数指针太复杂
但是仿函数也有诸多不便
比如
struct Goods
{
string _name;//名字
double _price;//价格
int _evaluate;//平价
};
要对这个商品进行排序的话,至少要写6个仿函数,就是六个类,每个类去重载operator(),按哪个字段来排序,就有两个对应的Less和Greater,非常的不便捷
1.lambda表达式语法
lambda表达式书写格式:
[capture-list](parameters)mutable->return-type{statemenr}
捕捉列表 参数列表 mutable -> 返回类型 函数体
[capture-list] : 捕捉列表,该列表总是出现在lmbda函数开始的位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量工lambda函数使用。
(paraments) : 参数列表,与普通函数的参数列表一致,如果不需要参数传递,则可以连()一起省略
mutable : 默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空,因为位置的识别问题)
->returntype : 返回值类型,用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略,返回值类型明确情况下,也可省略,由编译器对返回类型进行推导
{statement} : 函数体,在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量
注意:
在lambda函数定义中,参数列表和返回值类型都是可选部分,而捕捉列表和函数体可以为空,因此,C++最简单的lambda函数为: []{};该lambda函数不能做任何事情
lambda表达式/匿名函数 也是一个对象!!
2.使用lambda
两数相加lambda
auto add = [](int a,int b)/*mutable*/->int {return a+b;}
两数交换lambda
①捕捉列表
auto swap = [a,b]()mutable /*->void*/
//mutable使用的时候,不能省略参数列表,不然编译器识别有问题
//因为lambda表达式是一个const函数具有常性,所以需要mutable来取消常性,捕获到的a,b
{
int tmp =x;
x=y;
y=tmp;
}
虽然捕捉过来了,但是默认的捕捉是拷贝的捕捉 (传值捕捉),因为lambda是一个函数调用,是有函数栈帧的,在不同的两个作用域。所以mutable在实际当中其实没什么价值,一般要修改都要用传引用捕捉
②传引用捕捉
auto swap = [&a,&b]
{
int tmp =x;
x=y;
y=tmp;
}
比如说刚刚的商品
struct Goods
{
string _name;//名字
double _price;//价格
int _evaluate;//平价
};
sort(v.begin(),v.end(),[](const Goods&g1.const Goods&g2)
{
return g1._name<g2._name;//升序
});
sort(v.begin(),v.end(),[](const Goods&g1.const Goods&g2)
{
return g1._name>g2._name;//降序
});
//等等sort后面传的是一个比较函数,可以穿函数指针,仿函数,lambda
3.捕捉列表说明
如果有很多变量
[=] 传值捕捉所有变量
[&] 传引用捕捉所有变量
[var] 传值捕捉指定变量
[&var] 传引用捕捉指定变量
注意:
a.语法上捕捉列表可由多个捕捉项组成,并以逗号分割(可以混合捕捉)
[=,&a,&b],表示传值捕捉所有变量,传引用捕捉a,b
[&,a,b],表示传引用捕捉所有变量,传值捕捉a,b
但是[&,a]编译器会默认他为显示捕捉的那一种,需要加mutable才行
b.捕捉列表不允许变量以统一方式捕捉两次,否则编译错误
[=,a]等于传值捕捉a两次,编译报错
c.lambda函数仅能捕捉父作用域中的局部变量或者全局变量,捕捉任何非此作用域变量都会编译报错
d.任何lambda的类型都是不一样的,所以相互之间不能赋值
4.lambda底层原理

lambda的类型是一个lambda_加一个字符串,这个字符串是随机的,它其实是uuid
uuid是通用唯一识别码的缩写(Universally Unique Identifier),让所有元素,都能有一个唯一表示信息
这是一个算法,基本上是唯一的字符串
lambda是匿名的,底层是把这个lambda转成一个仿函数类,类的名称就叫做
lambda_uuid,保证每个的lambda名称不一样
底层其实就是一个仿函数,自动生成一个lambda_uuid的方函数类,虽然用起来方便,但是编译阶段做了不少事,也就是说lambda并不是什么新东西,实际编译的时候就没有lambda了,看到的是lambda_uuid这个仿函数,lambda对于我们来说是匿名的,对于编译器来说有特定的名称。
四、包装器
①函数指针
②仿函数/函数对象
③lambda
T useF(F f,T x)
{
static int count=0;
cout<<"count:"<<++count<<endl;
cour<<"counr:"<<&count<<endl;
return f(x);//函数调用
}
double f(doubel i)
{
return i/2;
}
struct Functor
{
double operator()(double d)
{
return d/2;
}
}
int main()
{
cout<<useF(f,11.11)<<endl;
cout<<useF(Functor(),11.11)<<endl;
cout<<useF([](double d){return d/4;},11.11)<<endl;
return 0;
}
这段代码通过静态的count能够看出来,编译器会根据该模板生成三份函数
也太费事了,所以就有了包装器
包装器就可以让编译器只生成一份(用哪个函数就生成哪个)
1.定义包装器
template<class Ret,class...Args>
//Ret是返回值类型,Args是参数包
class function<Ret(Args...args)>;//这是类名
2.使用包装器
function<int(int,int)> f1 = f;//int f(int a,int b)
f1(1,2);
function<int(int,int)> f2 = Functor();//int operator()(int a,int b)
f2(1,2)
class Plus
{
public:
static int plusi(int a,int b)
{
return a+b;
}
double plusd(double a,double b)
{
return a+b;
}
}
function<int(int,int)> f3 = Plus::plusi;
f3(1,2);
//function<double(double,double)> f4 = &Plus::plusd;
//成员函数的指针不能直接调用,成员函数需要用对象去调用
function<double(Plus,double,double)> f4 = &Plus::plusd;
//非静态成员函数的地址必须加这个&,语法规定
f4(Plus(),1.1,1.2);
//绑定成员函数的时候需要多传一个类名过去
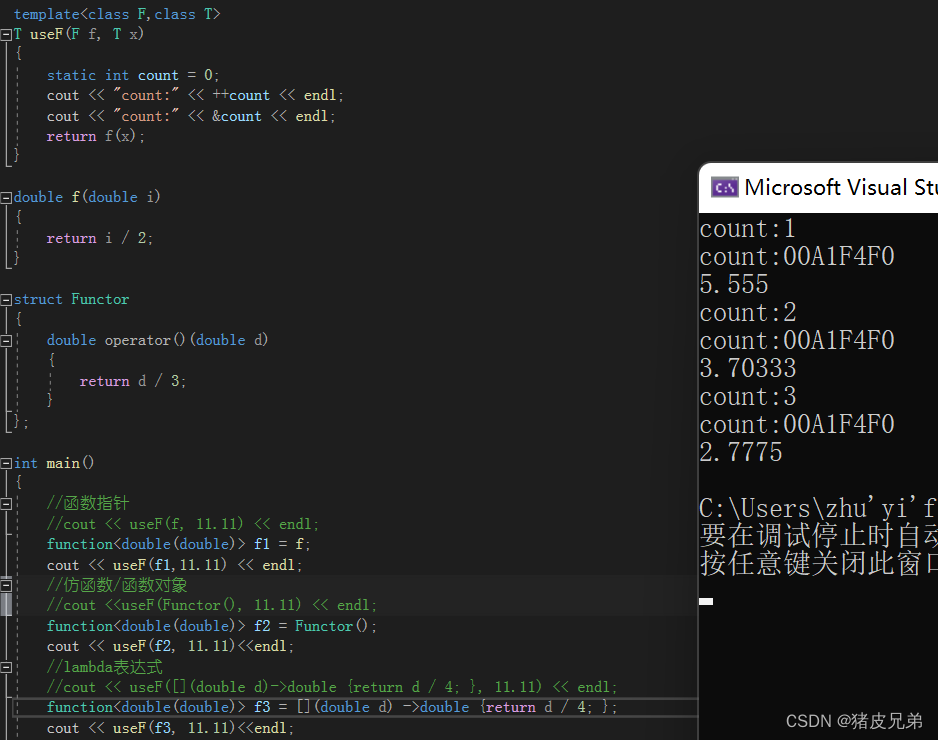
这样的话传同类对象给usef就只会推导出一个函数,而不会生成三个
五、bind绑定
bind是一个函数模板,他就是是函数包装器(适配器),接收一个可调用对象,生成一个新的可调用对象以适应原对象的参数列表
template<class Ret,class Fn,class ...Args>
bind(Fn&&fn,Args&&...args);
比如
function<int(int,int)> f1 = f;//int f(int a,int b)
function<int(int,int)> f2 = Functor();//int operator()(int a,int b)
class Plus
{
public:
double plus(double a,double b)
{
return a+b;
}
}
function<int(Plus,int,int)> f3 = &Plus::plus;
map<string,function<int(int,int)>> opFuncMap;
像这样,需要使用成员函数的时候,还要多传一个类名过去,那这时候写的包装器就用不了了
bind中有一个placeholder命名空间中的占位符,也就是_1,_2.
_1代表的是第一个参数,_2代表的是第二个参数,所以调整参数也就是调整占位符
int x=10,y=2;
cout<<Div(x,y)<<endl;
//对Div绑定,调整顺序
auto bindFun1 = bind(Div,_1,_2);
auto bindFun2 = bind(Div,_2,_1);
//交换顺序其实用不上,因为这只需要我们传参的时候反着传就行了
//对于上面传包装器还需要多传一个类名,那么就可以进行绑定来调整参数个数
function<int(int,int)> funcPlus = Plus;
function<int(int,int)> funcSub = bind(&Sub::sub,Sub(),_1,_2);
通过bind把第一个参数绑定死,然后_1,_2就可以占用两个形参的位置,传两个int就可以了,但是对于绑定死的哪个参数是变化的就不行。也就是说,bind真正需要的参数个数就是占位符的个数,想减少原可调用对象的参数个数,就绑定死某些参数


![[世界杯]根据赔率计算各种组合可能性与赔率](https://img-blog.csdnimg.cn/7f2a3967841e4c8f80462733d5178590.png)






![[Jetson]在nvidia orin/xavier上快速配置深度学习环境(Tensorflow,Pytorch都可以参考)](https://img-blog.csdnimg.cn/9f3af581b2ad42a0a29744f7f72545af.png)