目录
一、背景
二、数据输入
2.1 赔率示意图
2.2 代码
三、数据处理
3.1 计算各种组合可能性
3.2 修正概率
四、输出结果
一、背景
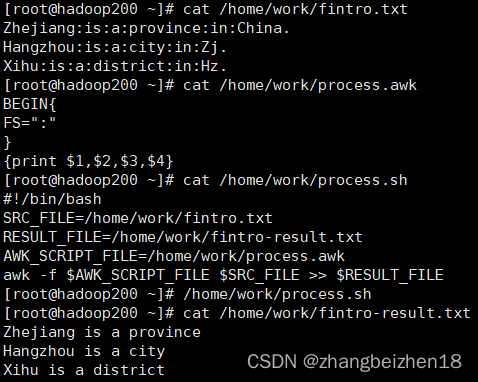
本文以世界杯体彩“混合过关”4场串胜平负为的赔率进行编码
其他类型如比分 、总进球数可以参考代码进行相应修改
需要的库:numpy与pandas
二、数据输入
2.1 赔率示意图

2.2 代码
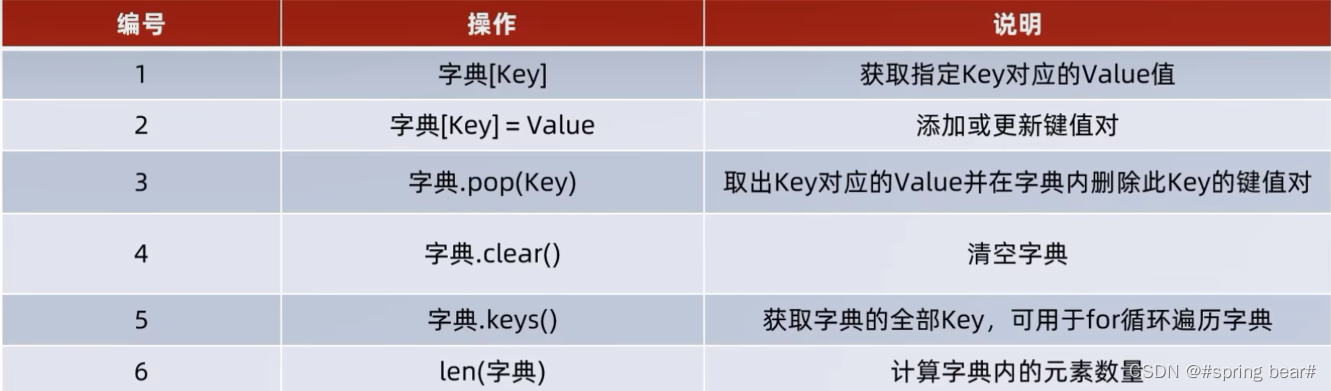
采用字典保存各比赛对应的胜平负的赔率
import pandas as pd
import numpy as np
vs1 = {"胜":2.38,"平":2.93,"负":2.65} #厄瓜多尔-塞内加尔
vs2 = {"胜":13.0,"平":6.20,"负":1.11} #卡塔尔-荷兰
vs3 = {"胜":3.58,"平":3.16,"负":1.84} #伊朗-美国
vs4 = {"胜":7.35,"平":4.16,"负":1.31} #威尔士-英格兰三、数据处理
3.1 计算各种组合可能性
计算采用的公式主要为:(图中10%为抽水率,仅为假设)

其中0.9913为初步计算得到的体彩抽水率,实际不准确,该数值仅供初步计算,之后需要根据计算所得的概率进行相应修正。
count = 1
probList = []
probListIndex = []
probVs = []
timesList = []
vsCode1 = []
vsCode2 = []
vsCode3 = []
vsCode4 = []
for key1,each1 in vs1.items():
for key2,each2 in vs2.items():
for key3,each3 in vs3.items():
for key4,each4 in vs4.items():
# print(count,key1,key2,key3,each1*each2*each3)
prob = 99.13 / (each1*each2*each3*each4)
#print(count,key1,key2,key3,key4,prob)
probList.append(prob)
probListIndex.append(count)
probVs.append(key1+key2+key3+key4)
timesList.append(each1*each2*each3*each4)
vsCode1.append(key1)
vsCode2.append(key2)
vsCode3.append(key3)
vsCode4.append(key4)
count += 1
data = pd.DataFrame(probList,index = probListIndex,columns=["prob"])
data_temp = pd.DataFrame(probVs,index = probListIndex,columns=["vs"])
data_times = pd.DataFrame(timesList,index = probListIndex,columns=["times"])
data_vs1 = pd.DataFrame(vsCode1,index = probListIndex,columns=["vs1"])
data_vs2 = pd.DataFrame(vsCode2,index = probListIndex,columns=["vs2"])
data_vs3 = pd.DataFrame(vsCode3,index = probListIndex,columns=["vs3"])
data_vs4 = pd.DataFrame(vsCode4,index = probListIndex,columns=["vs4"])
# data = data.add(data_temp,fill_value=False)
data["vs"] = data_temp["vs"]
data["vs1"] = data_vs1["vs1"]
data["vs2"] = data_vs2["vs2"]
data["vs3"] = data_vs3["vs3"]
data["vs4"] = data_vs4["vs4"]
data["times"] = data_times["times"]
data = data.sort_values(by="prob",ascending=False)
data["total_prob"] = 0
sum_prob = 0
for each in data.index:
# print(each)
sum_prob += data["prob"].loc[each]
data["total_prob"].loc[each] = sum_prob
3.2 修正概率
该段代码无实际含义,仅为修正由于采用估计抽水率计算所得的概率偏差
主要思路是采用数据标准化后并将数据映射到合理的区间,并对部分概率进行转换
total_prob_min = data["total_prob"].min()
data["total_prob"] = (data["total_prob"]-data["total_prob"].min())/(data["total_prob"].max()-data["total_prob"].min())*(100-total_prob_min)+total_prob_min
data["total_prob"].iloc[0] = (data["total_prob"].iloc[1]*data["total_prob"].iloc[0])/(data["prob"].iloc[1]+data["total_prob"].iloc[0])
temp = data["total_prob"] - data["total_prob"].shift(1)
temp[0] = data["total_prob"].iloc[0]
data["prob"] = temp
data["prob"].iloc[0] = data["total_prob"].iloc[0]
data.to_csv(r"C:\Users\kkkk\Desktop\世界杯1129.csv")四、输出结果
prob该组合可能性,total_prob为累计可能性,times为赔率,VS1~4为该组合对应的胜平负
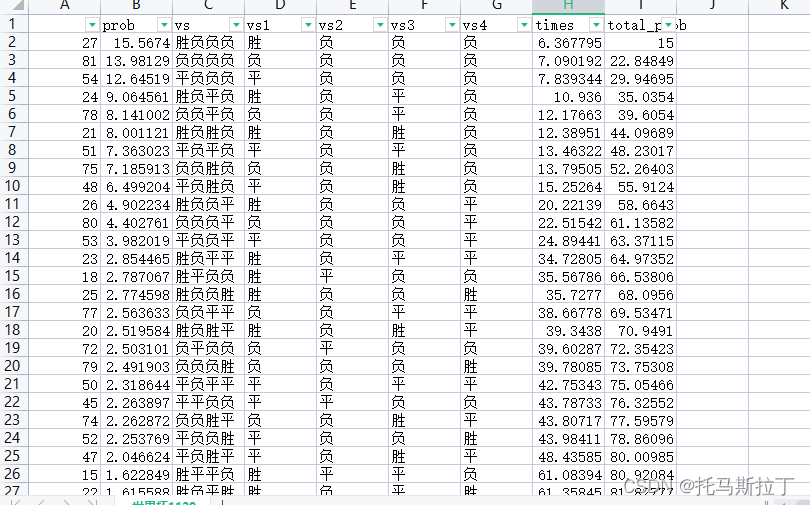
以11.29日赛程为参考,卡塔尔与威尔士大概率负,因此采用Excel筛选出相关组合,在所列组合中选取赔率较高的组合。
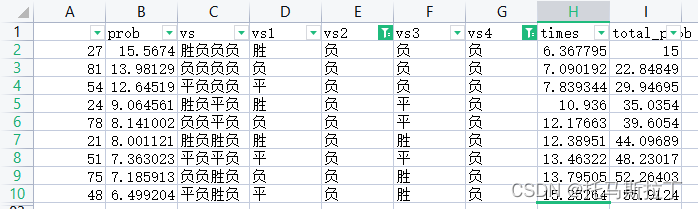
五、代码
import pandas as pd
import numpy as np
vs1 = {"胜":2.38,"平":2.93,"负":2.65}
vs2 = {"胜":13.0,"平":6.20,"负":1.11}
vs3 = {"胜":3.58,"平":3.16,"负":1.84}
vs4 = {"胜":7.35,"平":4.16,"负":1.31}
count = 1
probList = []
probListIndex = []
probVs = []
timesList = []
vsCode1 = []
vsCode2 = []
vsCode3 = []
vsCode4 = []
for key1,each1 in vs1.items():
for key2,each2 in vs2.items():
for key3,each3 in vs3.items():
for key4,each4 in vs4.items():
# print(count,key1,key2,key3,each1*each2*each3)
prob = 99.13 / (each1*each2*each3*each4)
print(count,key1,key2,key3,key4,prob)
probList.append(prob)
probListIndex.append(count)
probVs.append(key1+key2+key3+key4)
timesList.append(each1*each2*each3*each4)
vsCode1.append(key1)
vsCode2.append(key2)
vsCode3.append(key3)
vsCode4.append(key4)
count += 1
data = pd.DataFrame(probList,index = probListIndex,columns=["prob"])
data_temp = pd.DataFrame(probVs,index = probListIndex,columns=["vs"])
data_times = pd.DataFrame(timesList,index = probListIndex,columns=["times"])
data_vs1 = pd.DataFrame(vsCode1,index = probListIndex,columns=["vs1"])
data_vs2 = pd.DataFrame(vsCode2,index = probListIndex,columns=["vs2"])
data_vs3 = pd.DataFrame(vsCode3,index = probListIndex,columns=["vs3"])
data_vs4 = pd.DataFrame(vsCode4,index = probListIndex,columns=["vs4"])
# data = data.add(data_temp,fill_value=False)
data["vs"] = data_temp["vs"]
data["vs1"] = data_vs1["vs1"]
data["vs2"] = data_vs2["vs2"]
data["vs3"] = data_vs3["vs3"]
data["vs4"] = data_vs4["vs4"]
data["times"] = data_times["times"]
data = data.sort_values(by="prob",ascending=False)
data["total_prob"] = 0
sum_prob = 0
for each in data.index:
# print(each)
sum_prob += data["prob"].loc[each]
data["total_prob"].loc[each] = sum_prob
total_prob_min = data["total_prob"].min()
data["total_prob"] = (data["total_prob"]-data["total_prob"].min())/(data["total_prob"].max()-data["total_prob"].min())*(100-total_prob_min)+total_prob_min
data["total_prob"].iloc[0] = (data["total_prob"].iloc[1]*data["total_prob"].iloc[0])/(data["prob"].iloc[1]+data["total_prob"].iloc[0])
temp = data["total_prob"] - data["total_prob"].shift(1)
temp[0] = data["total_prob"].iloc[0]
data["prob"] = temp
data["prob"].iloc[0] = data["total_prob"].iloc[0]
data.to_csv(r"C:\Users\kkkk\Desktop\世界杯1129.csv")






![[Jetson]在nvidia orin/xavier上快速配置深度学习环境(Tensorflow,Pytorch都可以参考)](https://img-blog.csdnimg.cn/9f3af581b2ad42a0a29744f7f72545af.png)