引言
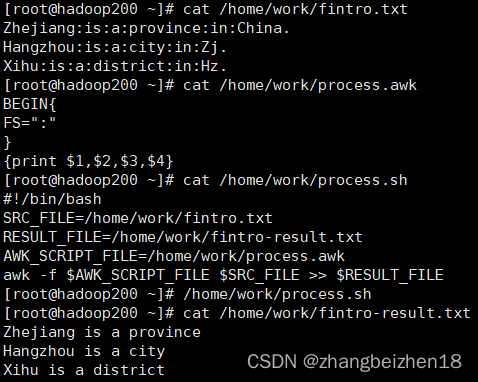
Hostlink是欧姆龙PLC默认的串口上行通信协议,使用默认的通信协议可免除PLC端的配置工作,易于实现分工协作。下面以CP1E-E的PLC为例进行说明,CP系列的PLC规则都是一样的。
读离散量
请求报文
字节流
40 33 31 46 41 30 30 30 30 30 30 30 30 30 30 31 30 31 30 32 30 30 34 30 30 30 30 30 30 41 30 41 2a 0d
字符流
@31FA000000000010102004000000A0A*\r
说明
@:起始字符;
31:节点号、站号、设备编号或其它类似的含义,用于识别目标PLC。相当于收件人地址。在Hostlink中,只有这两个字符是十进制的。固定长度2字符,取值范围00~31;
FA:使用FINS。对于上位机编程而言,这是一个常量;
0:超时,单位是厘秒,取值范围是0~F,一般写0,固定1位十六进制;
00000000:共有四个编号ICF、DA2、SA2、SID。对于请求报文,如果不想过多了解,这8个字符全为'0'就好;
0101:读指令,读离散量和读寄存器都是它;
02:读D系列寄存器的位;
0040:读这个系列的第0个寄存器,4位十六进制字符串,这里是读D64;
00:位地址,2位16进制,虽然占两个字符,但只有右边那个有用,取值范围是00~0F,对这条指令,它代表读取的第一个离散量为D64.00;
000A:个数,这里是读取10个离散量;
0A:校验码,校验算法将在后面的章节展示;
*\r:结束符;
应答报文
字节流
40 33 31 46 41 30 30 34 30 30 30 30 30 30 30 30 31 30 31 30 30 30 30 30 31 30 31 30 31 30 31 30 31 30 31 30 31 30 31 30 31 30 31 34 31 2a 0d
字符流
@31FA0040000000010100000101010101010101010141*\r
说明
@31FA00400000000101:与上一节类似,不同之处在于超时这个位置,由1位16进制变成了2个'0',所以这一部分长度比之前的多一个字符;另外,ICF在响应时会变成40,所以中间那8个'0'就变成了"40000000";由于是PLC返回的报文,只关心上位机编程的话,就不要在意这里的ICF变成40了;
0000:这个是错误码,为0表示无错误,如果不为0,则需要查手册;
01010101010101010101:返回了10个离散量的值,对于离散量的读写,每2个字符代表一个离散量,00是断,01是通,其它数值表示这个PLC已经不正常了,要换一台新的;
41*\r:校验码和结束符;
读寄存器
请求报文
字节流
40 33 31 46 41 30 30 30 30 30 30 30 30 30 30 31 30 31 38 32 30 30 36 34 30 30 30 30 30 37 37 41 2a 0d
字符流
@31FA00000000001018200640000077A*\r
说明
红色部分见之前的章节。
82:与02相呼应,同是D系列寄存器,但是02是读它的位,82是读它的整体数值;
0064:读D100;
00:当前面用了82而不是02时,这里只能是"00";
0007:读7个寄存器;
响应报文
字节流
40 33 31 46 41 30 30 34 30 30 30 30 30 30 30 30 31 30 31 30 30 30 30 30 30 30 31 30 30 30 32 30 30 30 33 30 30 30 34 30 30 30 35 30 30 30 36 30 30 30 37 34 31 2a 0d
字符流
@31FA004000000001010000000100020003000400050006000741*\r
说明
红色部分见之前的章节。
0000:错误码;
0001000200030004000500060007:7个寄存器值,对于寄存器读写,每4个字符代表1个寄存器值,即4位16进制,至于类型是short、unsigned short还是wchar_t则是由上位机程序的缓存类型决定的;
写离散量
请求报文
字节流
40 30 30 46 41 30 30 30 30 30 30 30 30 30 30 31 30 32 30 32 30 33 45 38 30 38 30 30 30 36 30 31 30 30 30 30 30 30 30 31 30 31 30 37 2a 0d
字符流
@00FA00000000001020203E808000601000000010107*\r
说明
红色部分见之前的章节。
0102:写指令,写离散量和写寄存器是同一个;
02:D系列寄存器;
03E8:D1000;
08:D1000.08;
0006:后面有6个数据;
010000000101:离散量数据,两个字符代表一个离散量;
执行后,D1000的值变成了&12544。
响应报文
字节流
40 30 30 46 41 30 30 34 30 30 30 30 30 30 30 30 31 30 32 30 30 30 30 34 30 2a 0d
字符流
@00FA00400000000102000040*\r
说明
红色部分见之前的章节。
0000:错误码;
写寄存器
请求报文
字节流
40 30 30 46 41 30 30 30 30 30 30 30 30 30 30 31 30 32 38 32 30 33 45 38 30 30 30 30 30 32 66 66 66 66 66 66 66 66 30 32 2a 0d
字符流
@00FA00000000001028203E8000002ffffffff02*\r
说明
红色部分见之前的章节。
0102:写指令,写离散量和写寄存器是同一个;
82:D系列寄存器;
03E8:D1000;
00:不起作用,设为00即可;
0002:后面有2个数据;
ffffffff:寄存器数据,4个字符代表一个寄存器;
执行后,D1000的值变成了&65535。
响应报文
字节流
40 30 30 46 41 30 30 34 30 30 30 30 30 30 30 30 31 30 32 30 30 30 30 34 30 2a 0d
字符流
@00FA00400000000102000040*\r
说明
红色部分见之前的章节。
0000:错误码;
强制置位与取消
请求报文
字节流
40 30 30 46 41 30 30 30 30 30 30 30 30 30 32 33 30 31 30 30 30 31 30 30 30 30 33 30 30 30 36 34 30 30 37 37 2a 0d
字符流
@00FA0000000002301000100003000640077*\r
说明
红色部分见之前的章节。
2301:强制线圈状态命令,只能对CIO生效,对输入也有效果;
0000:操作代号,文档中只提及0000、0001、8000、8001、FFFF这五种状态,实测得:0000代表强制断、0001代表强制通、8000|8001|FFFF都代表取消这个点的强制状态;
30:CIO区;
0064:100,也就是第一个输出线圈的那个寄存器;
00:位地址为0,与上下文结合,表达了100.00,即第一个输出线圈;
执行后,Q:100.00强制为断;
响应报文
字节流
40 30 30 46 41 30 30 34 30 30 30 30 30 30 30 32 33 30 31 30 30 30 30 34 33 2a 0d
字符流
@00FA00400000002301000043*\r
说明
红色部分见之前的章节。
0000:错误码;
校验码
static final String fcs(CharSequence string, int length) {
int xor = 0;//初始化校验码变量
for (int i = 0; i < length; ++i) {
char c = string.charAt(i);//取每一个需要校验的字符的ASCII码
xor ^= 0xff & c;//进行8位校验
}
return toHex(xor, 2);//返回16进制的字符串
}校验码函数中的length就是校验码第0个字符的位置。
@Override
public String getString() {
try {
StringBuilder body = new StringBuilder();//报文的缓存
if (!m_message.getHeader().isResponse()) {//这个标志存在于ICF中,第6个Bit
m_message.encodeRequest(body);//编码请求包
} else {
m_message.encodeResponse(body);//编码响应包
}
if (m_message.getHeader().isNet()) {//这个标志存在于ICF中,第7个Bit
int length = body.length() - 16;
body.replace(8, 16, toHex(length / 2, 8));//FINS/TCP中的内容,与本文无关
} else {
String fcs = StaticOmronPLCHostlinkUtils.fcs(body, body.length());//对之前缓存的所有字符进行校验
body.append(fcs).append("*\r");//将校验码附加到缓存尾部,最后加上结束符
}
return body.toString();//完成报文的编码
} catch (Throwable e) {
}
return null;
}双重角色编码解码器结构
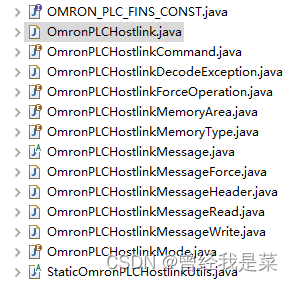
OmronPLCHostlink:Hostlink协议包装者,具备主、从机的双重能力;
OmronPLCHostlinkMessage:Hostlink协议的具体报文生成器的基类,需要被OmronPLCHostlink类包装;
需要3个实现类,如图,从上到下依次是强制线圈状态报文编码解码器、读数据编码解码器、写数据编码解码器;
Hostlink的两种模式类型:
public enum OmronPLCHostlinkMode {
CS_CJ, CV,;
}CP系列的PLC使用的是CS_CJ,而那个CV应该是大型机,本文只考虑小型机,上文所用的报文都是CP系列的报文,对大型机可能无效;
OmronPLCHostlinkMessageHeader:公共部分的编码解码器,(即上文中开头到命令的那一段),被OmronPLCHostlinkMessage包装;
关于强制线圈状态的枚举
package pers.laserpen.util.protocol.omron;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import pers.laserpen.util.java.StaticJavaUtils;
public enum OmronPLCHostlinkForceOperation {
OFF(0), ON(1), CANCEL_OFF(0x8000), CANCEL_ON(0x8001), CANCEL_ALL(0xffff),;
private static Map<Integer, OmronPLCHostlinkForceOperation> s_dict;
private final int m_code;
private OmronPLCHostlinkForceOperation(int code) {
m_code = code;
}
public final int getCode() {
return m_code;
}
public static OmronPLCHostlinkForceOperation valueOf(int code) {
if (s_dict == null) {
synchronized (OmronPLCHostlinkCommand.class) {
if (s_dict == null) {
s_dict = new ConcurrentHashMap<>();
OmronPLCHostlinkForceOperation[] values = values();
for (OmronPLCHostlinkForceOperation v : values) {
OmronPLCHostlinkForceOperation ok = s_dict.putIfAbsent(v.getCode(), v);
if (ok != null) {
StaticJavaUtils.exit("初始化错误,出现了重复定义的编码:" + ok);
}
}
}
}
}
return s_dict.get(code);
}
}
寄存器前缀枚举
package pers.laserpen.util.protocol.omron;
import static pers.laserpen.util.protocol.omron.OmronPLCHostlinkMemoryType.*;
import pers.laserpen.util.data.collection.Tree;
public enum OmronPLCHostlinkMemoryArea {
CS_CJ_CIO_BIT(0x30, Bit, 6),
CV_CIO_BIT(0x00, Bit, 6),
CS_CJ_WORK_BIT(0x31, Bit, 6),
CS_CJ_HOLDING_BIT(0x32, Bit, 6),
CS_CJ_AUXILIARY_BIT(0x33, Bit, 6),
CS_CJ_CIO_BIT_FORCED(0x70, Bit, 6),
CV_CIO_BIT_FORCED(0x40, Bit, 6),
CS_CJ_WORK_BIT_FORCED(0x71, Bit, 6),
CS_CJ_HOLDING_BIT_FORCED(0x72, Bit, 6),
CS_CJ_CIO_WORD(0xB0, Word, 6),
CV_CIO_WORD(0x80, Word, 6),
CS_CJ_WORK_WORD(0xB1, Word, 6),
CS_CJ_HOLDING_WORD(0xB2, Word, 6),
CS_CJ_AUXILIARY_WORD(0xB3, Word, 6),
CS_CJ_CIO_WORD_FORCED(0xF0, Word, 6),
CV_CIO_WORD_FORCED(0xC0, Word, 6),
CS_CJ_WORK_WORD_FORCED(0xF1, Word, 6),
CS_CJ_HOLDING_WORD_FORCED(0xF2, Word, 6),
CS_CJ_DM_BIT(0x02, Bit, 6),
CS_CJ_DM_WORD(0x82, Word, 6),
CV_DM_WORD(0x82, Word, 6),
CS_CJ_EM0_BIT(0x20, Bit, 6),
CS_CJ_EM0_WORD(0xA0, Word, 6),
CV_EM0_WORD(0x90, Word, 6),
CS_CJ_EM_CURRENT_WORD(0x98, Word, 6),
CV_EM_CURRENT_WORD(0x98, Word, 6),
CS_CJ_EM_CURRENT_NO(0xBC, Undefined, 6),
CV_EM_CURRENT_NO(0x9C, Undefined, 6),
;
private static Tree<Object, OmronPLCHostlinkMemoryArea> m_dict;
private final int m_area;
private final OmronPLCHostlinkMemoryType m_type;
private final int m_addressBytes;
private OmronPLCHostlinkMemoryArea(int cmd, OmronPLCHostlinkMemoryType type, int addressBytes) {
m_area = cmd;
m_type = type;
m_addressBytes = addressBytes;
}
public final int getCode() {
return m_area;
}
public final OmronPLCHostlinkMemoryType getType() {
return m_type;
}
public static OmronPLCHostlinkMemoryArea valueOf(OmronPLCHostlinkMode mode, int code) {
if (m_dict == null) {
synchronized (OmronPLCHostlinkMemoryArea.class) {
if (m_dict == null) {
m_dict = new Tree<>();
OmronPLCHostlinkMemoryArea[] values = values();
for (OmronPLCHostlinkMemoryArea v : values) {
if (v.name().startsWith("CS_CJ_")) {
m_dict.path(true, OmronPLCHostlinkMode.CS_CJ, v.getCode()).set(v);
} else if (v.name().startsWith("CV_")) {
m_dict.path(true, OmronPLCHostlinkMode.CV, v.getCode()).set(v);
}
}
}
}
}
Tree<Object, OmronPLCHostlinkMemoryArea> node = m_dict.path(false, mode, code);
return node == null ? null : node.get();
}
public int getAddressBytes() {
return m_addressBytes;
}
}
之前被一些博文骗了,其实所有的读写地址都是6个字符的,就算后面两个字符无效也必须写上。
代码仅供参考,它是配合通信程序使用的。将编码解码器与通信接口分开设计可以消除通信方面的重复代码,并且可以对编码解码器进行单独调试。
![[Jetson]在nvidia orin/xavier上快速配置深度学习环境(Tensorflow,Pytorch都可以参考)](https://img-blog.csdnimg.cn/9f3af581b2ad42a0a29744f7f72545af.png)