霍夫曼编码(Huffman Coding)是可变长编码(VLC)的一种。本质上使用变长编码表对源符号进行编码,通过评估源符号出现概率的方法进行分类,将出现几率较高的源字符使用较短的编码,出现几率较低的源字符使用较长的编码,使得整体的字符串的平均长度、期望值较低,从而达到无损压缩数据的目的。
霍夫曼编码的具体步骤
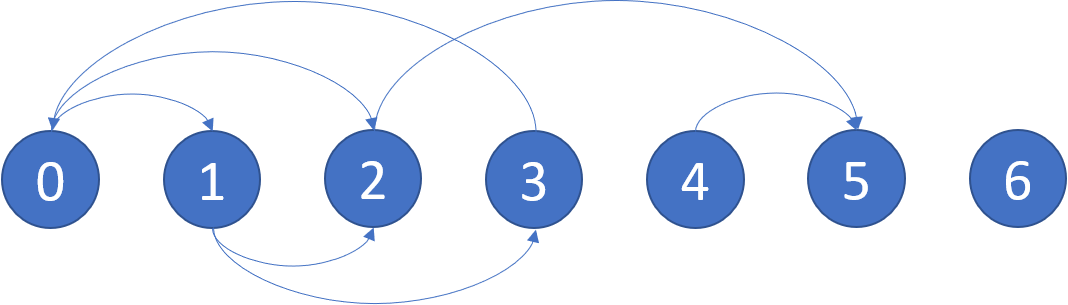
步骤1:将源符号的概率按从小到大排序成序列A;
步骤2:把两个最小的概率相加a、b, 得出概率值,放置在序列A中,记为z,同时删除a,b,和原序列中值按照从小到大排序,并记录a,b,z二叉树,且二叉树左叶值比右叶值小;
步骤3:重复步骤2,形成整体二叉树,左树标记为0,右树标记为1,从上到下即为该源符号的编码;
例:已知某文档包含5个字符,每个字符出现的频率如下,采用霍夫曼编码进行文档压缩,则单词"cade"的编码为?,文档的压缩比是多少?
| 字符 | a | b | c | d | e |
|---|---|---|---|---|---|
| 概率% | 40 | 10 | 20 | 16 | 14 |
解:
步骤1:将所有的字符按照从小到大排序,即b:10,e:14,d:16,c:20,a:40;
步骤2:将最小的两个概率值取出,左小右大组成二叉树,二叉树的节点为24

步骤3:重新将概率按照从小到大排序,即d:16,c:20,24,a:40;并选出最小的两个概率值,左小右大组成二叉树,二叉树节点为36;

步骤4:重复步骤3,将概率重拍,即24,36,a:40,并组成二叉树;左树标记为0,右树标记为1;

因此,a的编码为0,b的编码为101,e的编码为101,d的编码为110,c的编码为111;
cade的编码为 1110110101;
那么文档的压缩比怎么计算呢?
因为该文档有a、b、c、d、e五个字符,那么其处于2的2次方和2的3次方之间,则可用3位2进制数进行编码,假设a:000,b:001,c:010,d:011,e:100;
而采用霍夫曼编码,则文档压缩比计算为
压缩后编码长度
=
1
∗
40
%
+
3
∗
10
%
+
3
∗
20
%
+
3
∗
16
%
+
3
∗
14
%
=
2.2
文档压缩比
=
1
−
2.2
/
3
=
27
%
压缩后编码长度 = 1*40\% +3*10\%+3*20\%+3*16\%+3*14\% = 2.2\\ 文档压缩比 = 1 - 2.2/3 = 27\%
压缩后编码长度=1∗40%+3∗10%+3∗20%+3∗16%+3∗14%=2.2文档压缩比=1−2.2/3=27%





![Ignore insecure directories and continue [y] or abort compinit [n]?](https://img-blog.csdnimg.cn/1f2c1a24dc2c4a5d93b5cf86ba73daae.png)




![[架构之路-177]-《软考-系统分析师》-17-嵌入式系统分析与设计 -2- 系统分析与设计、低功耗设计](https://img-blog.csdnimg.cn/c2138a930de64b169b51d5aa3b3ee86d.png)