目录
前言
一、txt文件读写
二、excel文件读写
总结
前言
本文介绍使用Python进行文件读写操作,包括txt文件、excel文件(xlsx、xls、csv)
编译器使用的是PyCharm
一、txt文件读写
- read() # 一次性读取全部内容
- readline() # 读取第一行内容
- readlines() # 读取文本全部内容,并以数列的格式返回
- write() # 写入文件内容
txt文件读写规则
- r:读取文件,若文件不存在则会报错
- w:写入文件,若文件不存在则会先创建再写入,会覆盖原文件
- a:写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾
- rb,wb:分别与r,w类似,但是用于读写二进制文件
- r+:可读、可写,文件不存在也会报错,写操作时会覆盖
- w+:可读,可写,文件不存在先创建,会覆盖
- a+:可读、可写,文件不存在先创建,不会覆盖,追加在末尾
def readTxt(str):
with open(str, "r", encoding="utf-8") as f:
# data = f.read() # 一次性读取全部内容
# data = f.readline() # 读取第一行内容
# data = f.readlines() # 读取文本全部内容,并以数列的格式返回
# print(data)
for line in f.readlines():
line = line.strip('\n') # 去掉readlines里的换行符'\n'
print(line)
def writeTxt(str):
with open(str, "w", encoding="utf-8") as f:
f.write("这是个测试!") # 自带文件关闭功能,不需要再写f.close()
if __name__ == '__main__':
str = "test.txt"
# readTxt(str) # 读txt文件
writeTxt(str) # 写txt文件二、excel文件读写
- 读excel文件需要安装xlrd模块,高版本xlrd模块不支持xlsx文件读取,可指定下载低版本,或者将xlsx文件保存为xls文件
- 写excel文件需要安装xlsxwriter模块
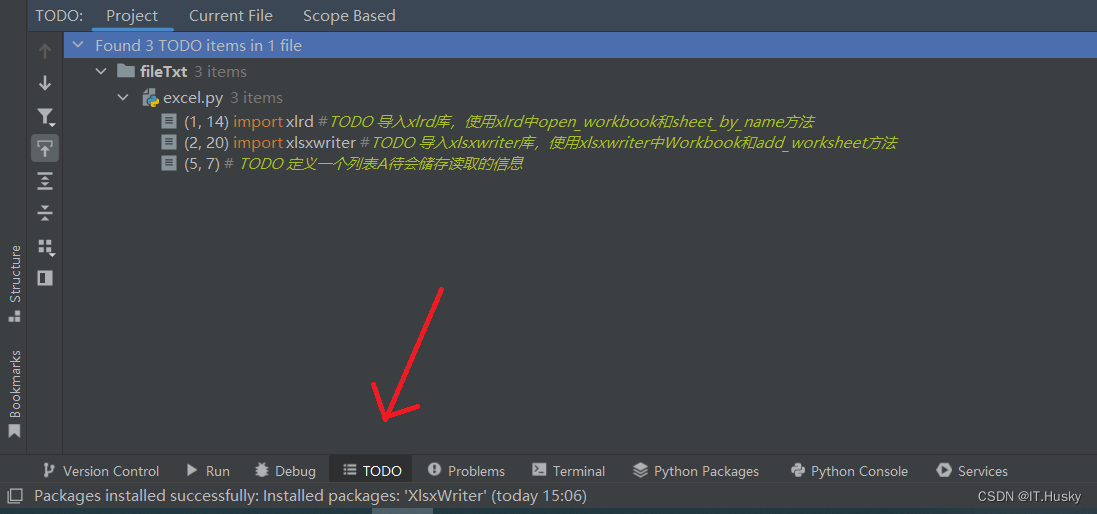
- 简单说明在注释前加TODO:表示待做任务,一般标明任务人、任务时间、任务人联系方式等信息。可以在PyCharm编辑器下统一查看
excel文件读取
- xx = xlrd.open_workbook(r"test.xls"):打开excel文件
- xs = xx.sheet_by_name('Sheet1'):单个读取名为Sheet1的表
- xs = xx['Sheet1']:等同于xx.sheet_by_name('Sheet1')
- xss = xx.sheet_names(): 读excel文件中全部表
excel文件写入
- workbook = xlsxwriter.Workbook(‘test.xlsx’):新建名为test的excel文件
- worksheet = workbook.add_worksheet(‘sheet’):新建名为sheet的表
- worksheet.write(‘A1’,‘100’):在A1写入100,只能单个写入
- worksheet.write_row(‘A1’,a):按行逐一写入列表a,多个写入
- worksheet.write_column(‘A1’,b):按行逐一写入列表b,多个写入
- wrokbook.close():关闭并保存文件
import xlrd #TODO 导入xlrd库,使用xlrd中open_workbook和sheet_by_name方法
import xlsxwriter #TODO 导入xlsxwriter库,使用xlsxwriter中Workbook和add_worksheet方法
def readExcel():
# TODO 定义一个列表A待会储存读取的信息
A = []
xx = xlrd.open_workbook(r"test.xls") # 高版本xlrd不支持xlsx,支持xls
# xs = xx.sheet_by_name('Sheet1')
# xs = xx['Sheet1'] # 读单个sheet
xss = xx.sheet_names() # 读全部sheet
for names in range(len(xss)):
name = xx[xss[names]]
if xss[names] == 'Sheet1' or xss[names] == 'sheet1': # sheet子表名称兼容
print(name)
xs = name
for i in range(0, 6):
k = xs.row_values(i) # row_values():行值
print(k)
A.append(k)
print(list(A))
# print(xs.row_values(0)) # row_values():行值
# N = xs.col_values(1) # col_values():列值
# print(N)
# # 这里我们查看一下G的格式是列表还是元组,或者其他的
# print(type(N))
def writeExcel():
# datas = (
# ['rent', 1000],
# ['gas', 120],
# ['food', 300],
# ['gym', 50],
# ['app', 600],
# ['lemon', 5000]
# )
# workbook = xlsxwriter.Workbook('excel01.xlsx') # csv、xls、xlsx格式都可 对文件操作
# worksheet = workbook.add_worksheet() # 对文件中的sheet操作
# row, col = 0, 0
# for item, cost in datas:
# worksheet.write(row, col, item)
# worksheet.write(row, col+1, cost)
# row += 1
# worksheet.write(row, 0, 'total')
# worksheet.write(row, 1, '=sum(B1:B6)')
# workbook.close()
head = ['姓名', '分数']
name = ['张三', '李四', '王五', '老六']
mark = [66, 77, 88, 99]
workbook = xlsxwriter.Workbook('chengji.xlsx')
worksheet = workbook.add_worksheet('chengji') # 可写指定sheet名
worksheet.write_row('A1', head) # write_row():行操作 多个写入
worksheet.write_column('A2', name) # write_column():列操作 多个写入
worksheet.write_column('B2', mark)
worksheet.write('A6', 'total') # 单个写入
worksheet.write('B6', '=sum(B2:B5)')
workbook.close()
if __name__ == '__main__':
print("Hello PyCharm!")
readExcel() # 读excel
# writeExcel() # 写excel总结
本文实现了Python的文件读写操作,包括txt文件、xlsx、xls、csv等文件。其次还标明了文件读写中的方法。这在实际应用中经常会遇到,觉得有用的记得关注收藏点赞鼓励哈!!!