前言
数据处理延迟的长短
- 实时数据处理:毫秒级别
- 离线数据处理:小时 or 天
数据处理的方式
- 流式(streaming)数据处理
- 批量(batch)数据处理
spark Streaming也是基于sparkCore,所以底层的核心没有变化。我们可以理解将spark Streaming为准实时(以秒、分钟为单位)、微批次的数据处理框架。
spark Streaming用于流式数据的处理。spark Streaming支持的数据输入源很多,如Kafka、flume、twitter、简单的TCP嵌套字等。数据输入后可以用spark的高度抽象原语如:map、reduce、join、window等进行运算。其结果也能保存在很多地方,如HDFS,数据库。

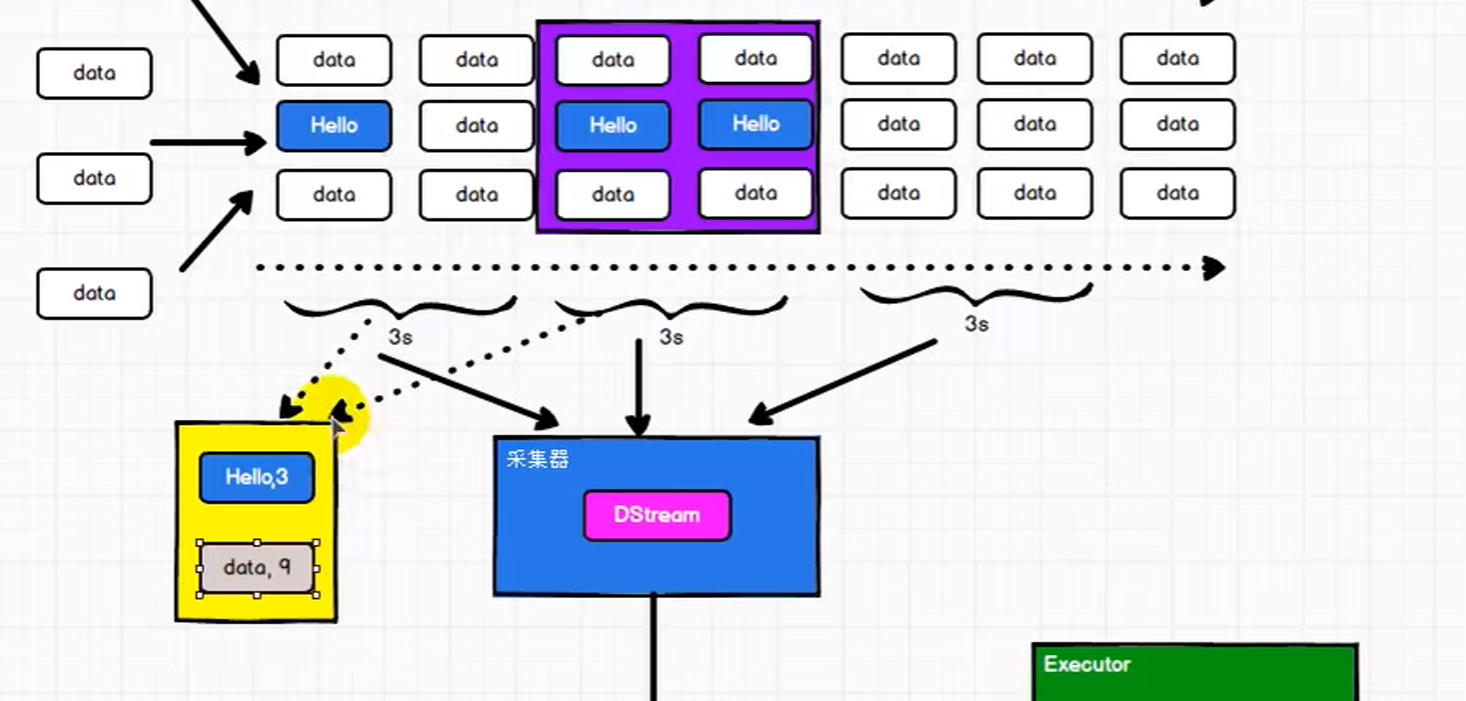
和Spark基于RDD的概念类似,Spark Streaming使用离散化流(discretized stream)作为抽象表示,叫做DStream。DStream是随着时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为RDD存在,而DStream是由这些RDD所组成的序列(因此得名“离散化”)。所以简单来说,DStream就是对RDD在实时数据处理场景的一种封装。
一、spark概述
1.1 背压机制
Spark 1.5 以前版本,用户如果要限制 Receiver 的数据接收速率,可以通过设置静态配制参数“spark.streaming.receiver.maxRate”的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer 数据生产高于 maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。
为了更好的协调数据接收速率与资源处理能力,1.5 版本开始 Spark Streaming 可以动态控制数据接收速率来适配集群数据处理能力。背压机制(即 Spark Streaming Backpressure): 根据JobScheduler 反馈作业的执行信息来动态调整 Receiver 数据接收率。
通过属性“spark.streaming.backpressure.enabled”来控制是否启用 backpressure 机制,默认值false,即不启用。
二、Dstream入门
2.1 什么是DStream
DStream是SS提供的基本抽象,其表现数据的连续流。这个输入数据流可以来自于源,也可以来自于转换输入流产生的已处理数据流。
内部而言,一个DStream以一系列连续的RDDs所展现,这些RDD是Spark对于不变的,分布式数据集的抽象。一个DStream中的每个RDD都包含来自一定间隔的数据,如下图:
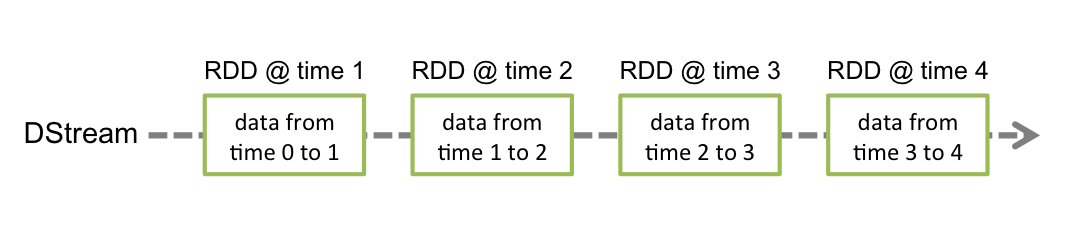
在DStream上使用的任何操作都会转换为针对底层RDD的操作。
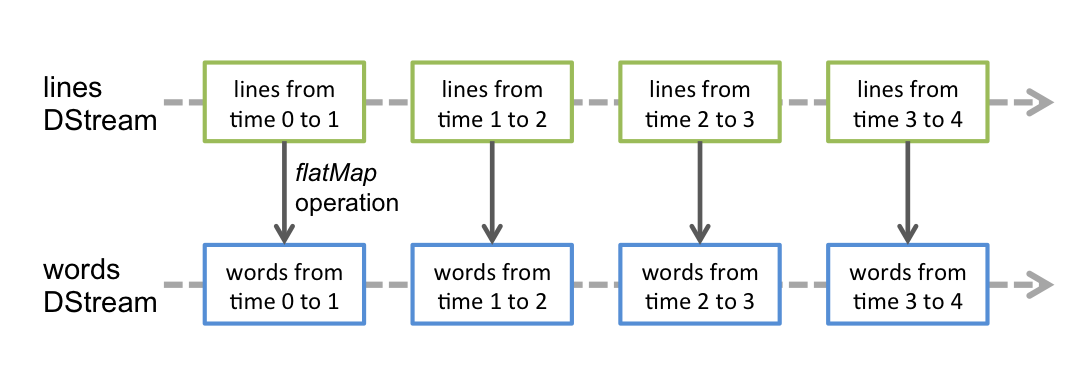
DStream
2.2 WordCount案例实操
需求:使用netcat工具向9999端口不断发送数据,通过SparkStreaming读取端口数据并统计不同单词出现的次数
1)添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
2)编写代码
package org.example
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object Word_Count {
def main(args: Array[String]): Unit = {
// TODO 创建环境对象
// StreamingContext创建时,需要传递两个参数
// 第一个参数表示环境配置
val conf = new SparkConf().setMaster("local").setAppName("SparkStream")
val ssc = new StreamingContext(conf,Seconds(3))
// TODO 逻辑处理
// 获取端口数据
val lines = ssc.socketTextStream("localhost",9999)
val words = lines.flatMap(_.split(" "))
val wordToOne = words.map((_,1))
val wordToCount = wordToOne.reduceByKey(_+_)
wordToCount.print()
// TODO 关闭环境
// 由于SparkStreaming采集器是长期执行的任务,所以不能直接关闭
// 如果main方法执行完毕,应用程序也会自动结束。不能让main方法执行完毕。
// ssc.stop()
// 1. 启动采集器
ssc.start()
// 2. 等待采集器的关闭
ssc.awaitTermination()
}
}
2.3 WordCount解析
Discretized Stream 是 Spark Streaming 的基础抽象,代表持续性的数据流和经过各种 Spark 原语操作后的结果数据流。在内部实现上,**DStream 是一系列连续的 RDD 来表示**。每个 RDD 含有一段时间间隔内的数据。
三、DStream创建
3.1 Kafka数据源
Kafka在数据源的采集过程中分为两个版本:ReceiverAPI和DirectAPI。
ReceiverAPI:需要专门的Executor作为接收器,采集和计算的速率不一定相同,可能会导致数据的积压。
DirectAPI:由计算的Executor节点主动消费Kafka的数据,速率由自身控制。
3.2 Kafka 0-10 Direct 模式
1)需求:
通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印到控制台。
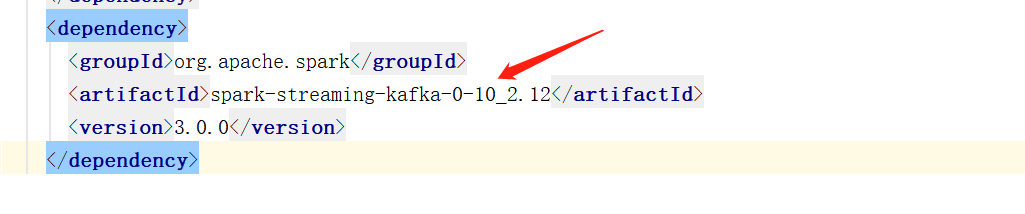
2)导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.10.1</version>
</dependency>
3)读取数据
1. 从命令行读取数据
val lines = streamingContext.socketTextStream("localhost",9999)
2. 从Kafka读取数据
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("events_raw"), kafkaParams)
)
4)代码编写
package org.example
import java.util
import java.util.ArrayList
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.kafka.streams.KeyValue
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
object SparkStreamEventAttendeesrawToEventAttends {
def main(args: Array[String]): Unit = {
// 1. 创建SparkConf
val conf = new SparkConf().setAppName("user_friends_raw").setMaster("local[*]")
// 2. 创建streamingContext
val streamingContext = new StreamingContext(conf,Seconds(5))
streamingContext.checkpoint("checkpoint")
// 3. 定义Kafka参数
val kafkaParams = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.136.20:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG -> "eventsraw"),
(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG->"earliest")
)
// 4. 读取Kafka数据创建DStream
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] =
KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("events_raw"), kafkaParams)
)
// 5. 将每条消息的 KV 取出
val valueDstream: DStream[String) = kafkaDstream,map(record => record.value())
// 6. 计算wordCount
valueDStream.flatMap(_.split(" ") )
.map((_,_1))
.reduceByKey(_+_)
.print ()
// 7. 开启任务
streamingContext.start()
streamingContext.awaitTermination()
}
}
5)查看Kafka消费进度
kafka-consumer-groups.sh --describe --bootstrap-server 192.168.136.20:9092 --group events
四、DStream转换
DStream转换和RDD转换类似,对比RDD中的转换算子和行动算子,DStream也有Transformations(转换)和Output Operations(输出)两者。
4.1 无状态转换操作
相当于没有血缘关系的RDD。
| 函数名称 | 目的 | 示例 |
|---|---|---|
| map() | 对DStream中的每个元素应用没定函数,返回由各元素输出的元素组成的DStream | ds.map(x=>x+1) |
| flatMap() | 对DStream中的每个元素应用没定函数,返回由各元素输出的迭代器组成的DStream | ds.flatMap(x=>x.split(" ")) |
| filter() | 返回由给定DStream中通过筛选的元素组成的DStream | ds.filter(x=>x!=1) |
| repartition() | 改变DStream的分区数 | ds.repartition(10) |
| reduceByKey() | 将每个批次中key相同的记录规约 | ds.reduceByKey((x,y)=>x+y) |
| groupByKey() | 将每个批次中的记录根据key分组 | ds.groupByKey() |
无状态和有状态其实就是看是否保存某一个采集周期的数据。如果保存就是有状态,不保存就是无状态。
4.1.1 Transform
可以拿到最底层的RDD进行操作。DStream无法实现的功能可以通过Transform实现。
object SparkStreamKafkaSource {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("sparkKafkaStream").setMaster("local[*]")
val streamingContext = new StreamingContext(conf, Seconds(5))
val lines = streamingContext.socketTextStream("localhost",9999)
// Transform方法可以将底层的RDD获取到后进行操作
val newRS: DStream[String] = lines.transform(rdd=>rdd)
streamingContext.start()
streamingContext.awaitTermination()
}
}
lines.transform() 和 lines.map() 都能够实现对算子的转换,那么有什么区别呢?
lines.map()


lines.transform():

说明:
transform方法可以将底层RDD获取到后进行操作
1、DStream功能不完善
2、需要代码周期性的执行
4.1.2 join
object SparkStreamKafkaSource {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("sparkKafkaStream").setMaster("local[*]")
val streamingContext = new StreamingContext(conf, Seconds(5))
val data9998 = streamingContext.socketTextStream("localhost",9999)
val data8868 = streamingContext.socketTextStream("localhost",8888)
val map9999: DStream[(String, Int)] = data9999.map((_,8))
val map8888: DStream[(String, Int)] = data8888.map((_,8))
// DS的join操作就是两个RDD的join
val joinDS: DStream[String, (Int, Int)] = map9999.join(map8888)
joinDS.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
4.2 有状态转化操作
4.2.1 UpdateStateByKey
有状态转化操作由于需要将计算的结果保存至内存,所以需要设置检查点checkpoint。
object SparkStreamEventAttendeesrawToEventAttends {
def main(args: Array[String]): Unit = {
// 创建SparkConf
val conf = new SparkConf().setAppName("user_friends_raw").setMaster("local[*]")
// 创建streamingContext
val streamingContext = new StreamingContext(conf,Seconds(5))
streamingContext.checkpoint("checkpoint")
// 无状态数据操作。只对当前的 采集周期内 的数据进行处理。
// 在某些场合下,需要保留数据统计结果(状态),实现数据的汇总。
val datas = streamingContext.socketTextStream("localhost",9999)
val wordToOne = datas.map((_,1))
val wordToCount = wordToOne.reduceByKey(_+_)
wordToCount.print()
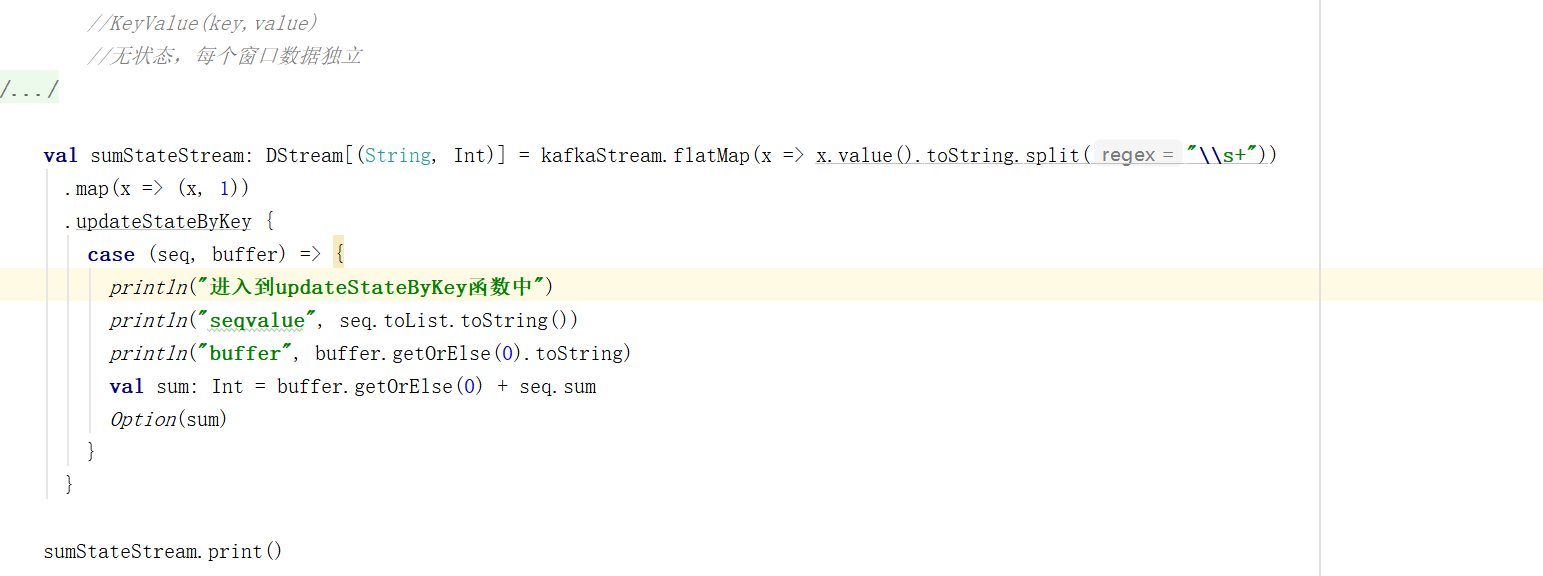
// updateStateByKey:根据key对数据的状态进行更新
// 传递的参数中含有两个值:
// 1:相同的key的value数据
// 2:缓冲区相同key的value值
val state = wordToOne.updateStateByKey(
(seq:Seq[Int],buff:Option[Int]) => {
val newCount = buff.getOrElse(0)+seq.sum
Option(newCount)
}
)
state.print()
// 开启任务
streamingContext.start()
streamingContext.awaitTermination()
}
}
4.2.2 WindowOperations
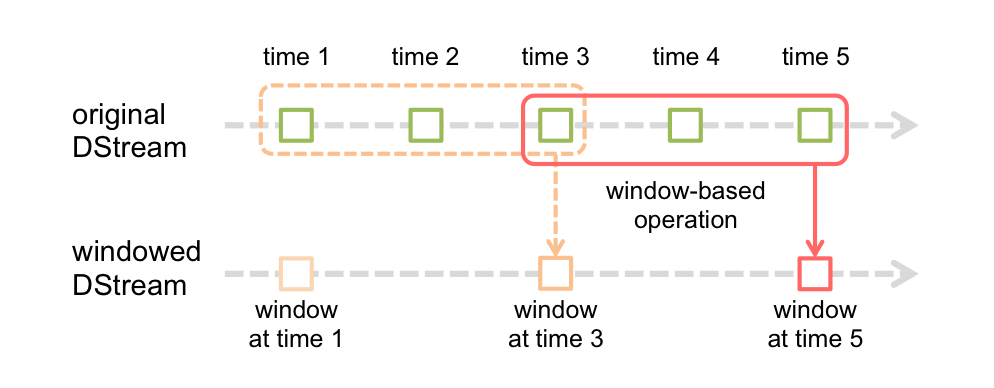
WindowOperations可以设置窗口的大小和滑动窗口的间隔来动态的获取当前 Steaming 的允许状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
窗口时长:计算内容的时间范围;
滑动步长:隔多久触发一次计算。
这两者都必须为采集周期大小的整数倍。
package org.example.window
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
object SparkWindowDemo1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("sparkwindow1").setMaster("local[*]")
val streamingContext = new StreamingContext(conf,Seconds(3))
streamingContext.checkpoint("checkpoint")
val kafkaParams = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.136.20:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG -> "sparkwindow01"),
(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG->"latest")
)
val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("sparkkafkastu"), kafkaParams)
)
// 滑动窗口,窗口的范围应该是采集周期的整数倍
// 窗口可以滑动,但是默认情况下,一个采集周期进行滑动
// 这样的话可能会出现重复数据的计算。为了避免这种情况,可以改变滑动的幅度(步长)
// window(Seconds(9)) => window(Seconds(9),Seconds(3))
val winStream: DStream[(String, Int)] = kafkaStream.flatMap(x => x.value().trim.split("\\s+"))
.map(x => (x, 1))
.window(Seconds(9),Seconds(3))
.reduceByKey(_+_)
winStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
通过图片我们可以看出:
1、window中的数据会重复计算
2、状态基于当前窗口进行操作
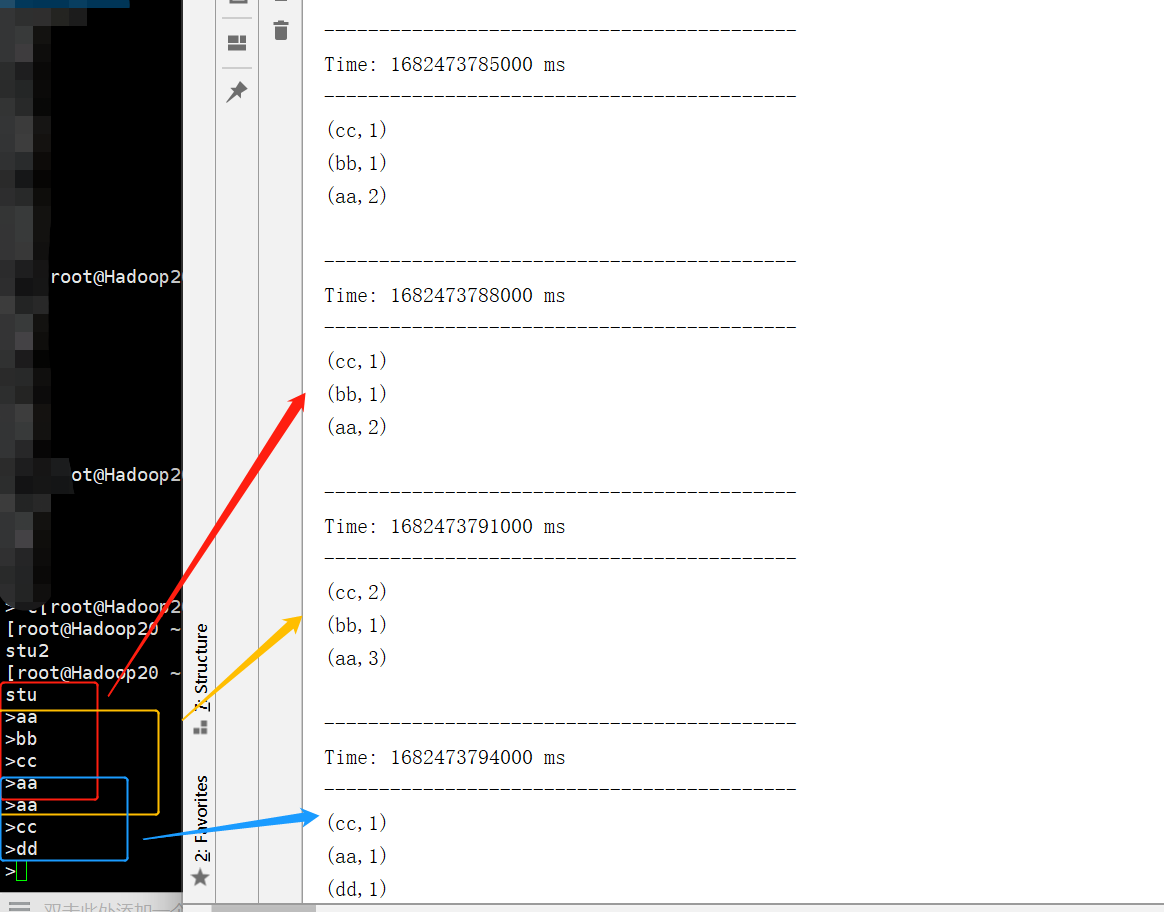
关于 Window 的操作还有如下方法:
(1)window(windowLength, slideInterval): 基于对源 DStream 窗化的批次进行计算返回一个新的 Dstream;
(2)countByWindow(windowLength, slideInterval): 返回一个滑动窗口计数流中的元素个数;
(3)reduceByWindow(func, windowLength, slideInterval): 通过使用自定义函数整合滑动区间流元素来创建一个新的单元素流;
(4)reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]): 当在一个(K,V)对的 DStream 上调用此函数,会返回一个新(K,V)对的 DStream,此处通过对滑动窗口中批次数据使用 reduce 函数来整合每个 key 的 value 值。
(5)reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]): 这个函数是上述函数的变化版本,每个窗口的 reduce 值都是通过用前一个窗的 reduce 值来递增计算。通过 reduce 进入到滑动窗口数据并”反向 reduce”离开窗口的旧数据来实现这个操作。一个例子是随着窗口滑动对 keys 的“加”“减”计数。通过前边介绍可以想到,这个函数只适用于”可逆的 reduce 函数”,也就是这些 reduce 函数有相应的”反 reduce”函数(以参数 invFunc 形式传入)。如前述函数,reduce 任务的数量通过可选参数来配置。
reduceByWindow和reduceByKeyAndWindow
reduceByWindow输入的是两个参数,没有(k,v)键值对,操作时需要对value进行指定。
reduceByKeyAndWindow输入的是(k,v)类型的键值对。可以直接对value进行操作。
reduceByKeyAndWindow:
当窗口范围比较大,但是滑动幅度比较小,那么可以采用增加数据和删除数据的方式。
无序重复计算,提高效率


五、DStream输出
如果我们没有输出的语句,会直接抛出异常。
这是因为DStream与RDD的惰性求值类似,如果一个DStream没有被执行输出操作,那么DStream不会被求值。StreamingContext没有设定输出操作,那么整个context就不会启动。

输出操作如下:
print():在运行流程序的驱动结点上打印 DStream 中每一批次数据的最开始 10 个元素。用于开发和调试。
saveAsTextFiles(prefix, [suffix]):以 text 文件形式存储这个 DStream 的内容。每一批次的存储文件名基于参数中的 prefix 和suffix prefix-Time_IN_MS[.suffix]。
saveAsObjectFiles(prefix, [suffix]):以 Java 对象序列化的方式将 Stream 中的数据保存为SequenceFiles 。每一批次的存储文件名基于参数中的为prefix-TIME_IN_MS[.suffix]。
saveAsHadoopFiles(prefix, [suffix]):将 Stream 中的数据保存为 Hadoop file。s. 每一批次的存储文件名基于参数中的为prefix-TIME_IN_MS[.suffix]。
foreachRDD(func):最通用的输出操作,即将函数 func 用于产生于 stream 的每一个RDD。其中参数传入的函数 func 应该实现将每一个 RDD 中数据推送到外部系统,如将RDD 存入文件或者通过网络将其写入数据库。注意: 1) 连接不能写在 driver 层面(序列化) 2) 如果写在 foreach 则每个 RDD 中的每一条数据都创建,得不偿失; 3) 增加 foreachPartition,在分区创建(获取)。
package org.example
import java.util
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamUserFriendrawToUserFriend {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("user_friends_raw").setMaster("local[*]")
val streamingContext = new StreamingContext(conf,Seconds(5))
streamingContext.checkpoint("checkpoint")
val kafkaParams = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.136.20:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG -> "uf"),
(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG->"earliest")
)
val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("user_friends_raw"), kafkaParams)
)
kafkaStream.foreachRDD(
rdd=>{
rdd.foreachPartition(x=>{
val props = new util.HashMap[String,Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.136.20:9092")
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String,String](props)
x.foreach(y=>{
val splits = y.value().split(",")
if(splits.length==2){
val userid = splits(0)
val friends = splits(1).split("\\s+")
for(friend<-friends){
val record = new ProducerRecord[String,String]("user_friends2",userid+","+friend)
producer.send(record)
}
}
})
})
}
)
streamingContext.start()
streamingContext.awaitTermination()
}
}
五、关闭任务
流式任务需要7*24小时执行,但是代码升级需要主动停止程序时,没办法做到一个个进程去关闭,所有配置的关闭就显得尤为重要。
// 线程的关闭
val thread = new Thread()
thread.start()
thread.stop // 强制关闭
优雅的关闭
优雅的关闭就是指计算节点不再接受新的数据,而是将现有的数据处理完毕,然后关闭。
但是如果直接写一个stop()方法放在awaitTermination()方法之后,awaitTermination()会阻塞main线程,stop()方法无法被执行到。
所以如果想要关闭采集器,那么需要创建新的线程,而且需要在第三方程序中增加关闭状态。
ssc.start()
new Thread(
new Runnable{
override def run(): Unit = {
Thread.sleep(5000)
val state: StreamingContextState = ssc.getState()
if ( state == StreamingContextState.ACTIVE ){
ssc.stop(true,true)
}
System.exit(0)
}
}
).start()
ssc.awaitTermination()
恢复数据
val ssc = StreamingContext.getActiveOrCreate("cp",()=>{
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.soctetTextStream("localhost",9999)
val wordToOne = lines.map((_,1))
wordToOne.print()
ssc
})
ssc.checkpoint("cp")
ssc.start()
ssc.awaitTermination()