文章目录
- Prologue
- 布隆过滤器去重
- 什么是布隆过滤器
- 实现的核心思想
- 怎么理解
- 内嵌RocksDB状态后端去重
- 引入外部K-V存储去重
Prologue
数据去重(data deduplication)是我们大数据攻城狮司空见惯的问题了。除了统计UV等传统用法之外,去重的意义更在于消除不可靠数据源产生的脏数据——即重复上报数据或重复投递数据的影响,使流式计算产生的结果更加准确。本文以Flink处理日均亿级别及以上的日志数据为背景,讨论除了朴素方法(HashSet)之外的三种实时去重方案,即:布隆过滤器、RocksDB状态后端、外部存储。
布隆过滤器去重
什么是布隆过滤器
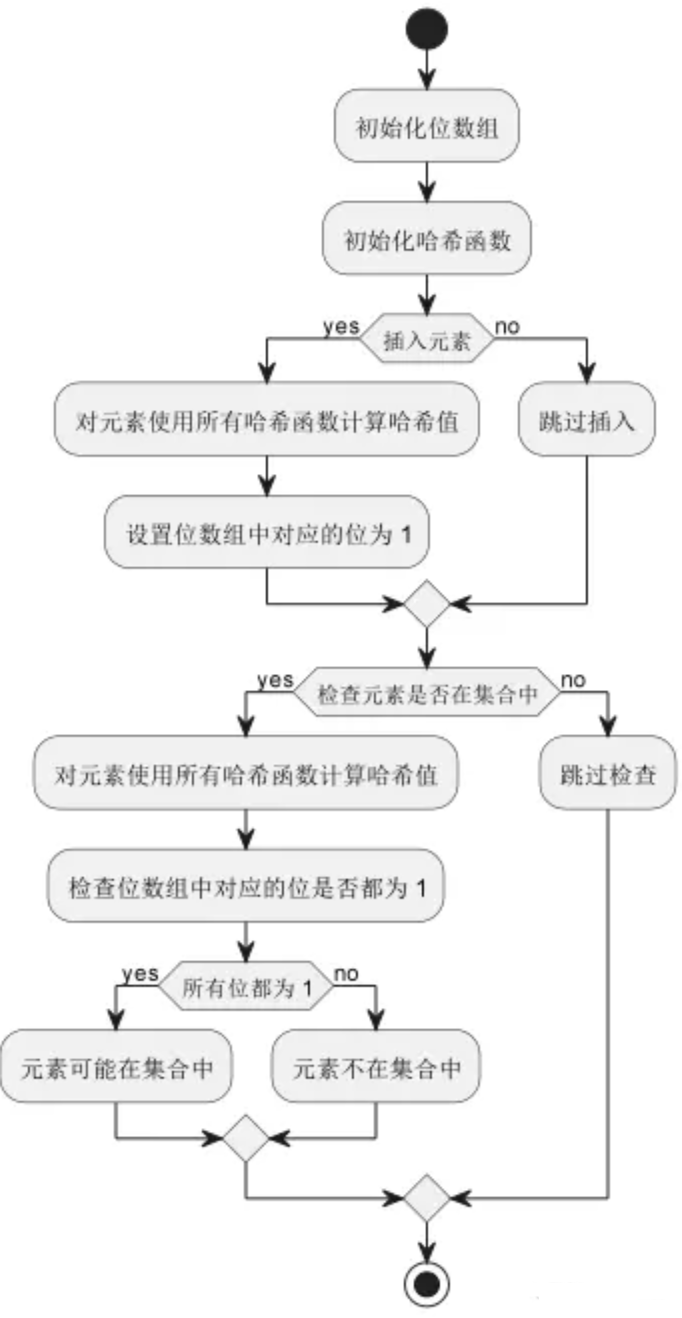
布隆过滤器(Bloom Filter)是一种空间效率非常高的随机数据结构,它利用位数组(BitSet)表示一个集合,并通过一定数量的哈希函数将元素映射为位数组中的位置,用于检查一个元素是否属于这个集合。
实现的核心思想
对于一个元素,通过多个哈希函数生成多个哈希值,将对应的位在位数组中设为 1,若多个哈希值对应的位都为 1,则认为该元素可能在集合中;若至少有一个哈希值对应的位为 0,则该元素一定不在集合中。这种方法可以在较小的空间中实现高效的查找,但可能存在误判率(false positive)。
怎么理解
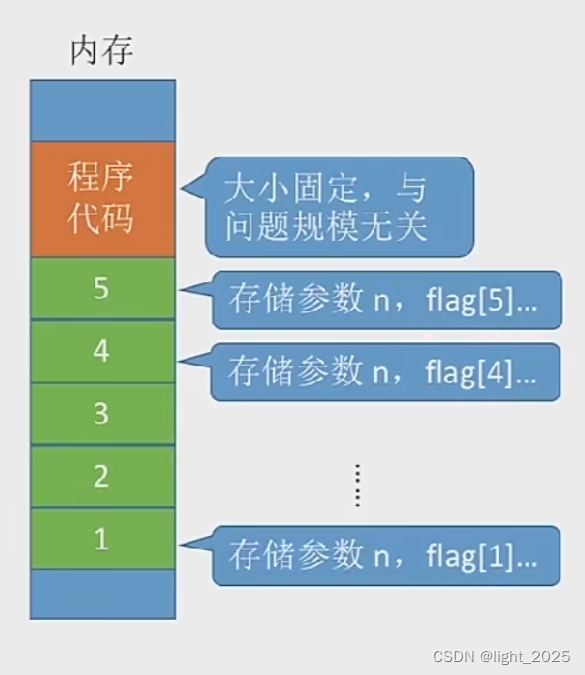
一个典型的布隆过滤器包含三个参数: 位数组的大小(即存储元素的个数); 哈希函数的个数; 填充因子(即误判率),即将元素数量与位数组大小的比值。
以之前用过的子订单日志模型为例,假设上游数据源产生的消息为<Integer, Long, String>三元组,三个元素分别代表站点ID、子订单ID和数据载荷。由于数据源只能保证at least once语义(例如未开启correlation ID机制的RabbitMQ队列),会重复投递子订单数据,导致下游各统计结果偏高。现引入Guava的BloomFilter来去重,直接上代码说事。
// dimensionedStream是个DataStream<Tuple3<Integer, Long, String>>
DataStream<String> dedupStream = dimensionedStream
.keyBy(0)
.process(new SubOrderDeduplicateProcessFunc(), TypeInformation.of(String.class))
.name("process_sub_order_dedup").uid("process_sub_order_dedup");
// 去重用的ProcessFunction
public static final class SubOrderDeduplicateProcessFunc
extends KeyedProcessFunction<Tuple, Tuple3<Integer, Long, String>, String> {
private static final long serialVersionUID = 1L;
private static final Logger LOGGER = LoggerFactory.getLogger(SubOrderDeduplicateProcessFunc.class);
private static final int BF_CARDINAL_THRESHOLD = 1000000;
private static final double BF_FALSE_POSITIVE_RATE = 0.01;
private volatile BloomFilter<Long> subOrderFilter;
@Override
public void open(Configuration parameters) throws Exception {
long s = System.currentTimeMillis();
subOrderFilter = BloomFilter.create(Funnels.longFunnel(), BF_CARDINAL_THRESHOLD, BF_FALSE_POSITIVE_RATE);
long e = System.currentTimeMillis();
LOGGER.info("Created Guava BloomFilter, time cost: " + (e - s));
}
@Override
public void processElement(Tuple3<Integer, Long, String> value, Context ctx, Collector<String> out) throws Exception {
long subOrderId = value.f1;
if (!subOrderFilter.mightContain(subOrderId)) {
subOrderFilter.put(subOrderId);
out.collect(value.f2);
}
ctx.timerService().registerProcessingTimeTimer(UnixTimeUtil.tomorrowZeroTimestampMs(System.currentTimeMillis(), 8) + 1);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
long s = System.currentTimeMillis();
subOrderFilter = BloomFilter.create(Funnels.longFunnel(), BF_CARDINAL_THRESHOLD, BF_FALSE_POSITIVE_RATE);
long e = System.currentTimeMillis();
LOGGER.info("Timer triggered & resetted Guava BloomFilter, time cost: " + (e - s));
}
@Override
public void close() throws Exception {
subOrderFilter = null;
}
}
// 根据当前时间戳获取第二天0时0分0秒的时间戳
public static long tomorrowZeroTimestampMs(long now, int timeZone) {
return now - (now + timeZone * 3600000) % 86400000 + 86400000;
}
这里先按照站点ID为key分组,然后在每个分组内创建存储子订单ID的布隆过滤器。布隆过滤器的期望最大数据量应该按每天产生子订单最多的那个站点来设置,这里设为100万,并且可容忍的误判率为1%。根据上面科普文中的讲解,单个布隆过滤器需要8个哈希函数,其位图占用内存约114MB,压力不大。
每当一条数据进入时,调用BloomFilter.mightContain()方法判断对应的子订单ID是否已出现过。当没出现过时,调用put()方法将其插入BloomFilter,并交给Collector输出。
另外,通过注册第二天凌晨0时0分0秒的processing time计时器,就可以在onTimer()方法内重置布隆过滤器,开始新一天的去重。
(吐槽一句,Guava的BloomFilter竟然没有提供清零的方法,有点诡异)
内嵌RocksDB状态后端去重
布隆过滤器虽然香,但是它不能做到100%精确。在必须保证万无一失的场合,我们可以选择Flink自带的RocksDB状态后端,这样不需要依赖其他的组件。之前已经讲过,RocksDB本身是一个类似于HBase的嵌入式K-V数据库,并且它的本地性比较好,用它维护一个较大的状态集合并不是什么难事。
首先我们要开启RocksDB状态后端(平常在生产环境中,也建议总是使用它),并配置好相应的参数。这些参数同样可以在flink-conf.yaml里写入。
RocksDBStateBackend rocksDBStateBackend = new RocksDBStateBackend(Consts.STATE_BACKEND_PATH, true);
rocksDBStateBackend.setPredefinedOptions(PredefinedOptions.FLASH_SSD_OPTIMIZED);
rocksDBStateBackend.setNumberOfTransferingThreads(2);
rocksDBStateBackend.enableTtlCompactionFilter();
env.setStateBackend(rocksDBStateBackend);
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
env.enableCheckpointing(5 * 60 * 1000);
RocksDB的调优是个很复杂的话题,详情参见官方提供的tuning guide,以及Flink配置中与RocksDB相关的参数,今后会挑时间重点分析一下RocksDB存储大状态时的调优方法。好在Flink已经为我们提供了一些预调优的参数,即PredefinedOptions,请务必根据服务器的实际情况选择。我们的Flink集群统一采用SSD做存储,故选择的是PredefinedOptions.FLASH_SSD_OPTIMIZED。
另外,由于状态空间不小,打开增量检查点以及设定多线程读写RocksDB,可以提高checkpointing效率,检查点周期也不能太短。还有,为了避免状态无限增长下去,我们仍然得定期清理它(即如同上节中布隆过滤器的复位)。当然,除了自己注册定时器之外,我们也可以利用Flink提供的状态TTL机制,并打开RocksDB状态后端的TTL compaction filter,让它们在RocksDB后台执行compaction操作时自动删除。特别注意,状态TTL仅对时间特征为处理时间时生效,对事件时间是无效的。
接下来写具体的业务代码,以上节的<站点ID, 子订单ID, 消息载荷>三元组为例,有两种可实现的思路:
仍然按站点ID分组,用存储子订单ID的MapState(当做Set来使用)保存状态;
直接按子订单ID分组,用单值的ValueState保存状态。
显然,如果我们要用状态TTL控制过期的话,第二种思路更好,因为粒度更细。代码如下。
// dimensionedStream是个DataStream<Tuple3<Integer, Long, String>>
DataStream<String> dedupStream = dimensionedStream
.keyBy(1)
.process(new SubOrderDeduplicateProcessFunc(), TypeInformation.of(String.class))
.name("process_sub_order_dedup").uid("process_sub_order_dedup");
// 去重用的ProcessFunction
public static final class SubOrderDeduplicateProcessFunc
extends KeyedProcessFunction<Tuple, Tuple3<Integer, Long, String>, String> {
private static final long serialVersionUID = 1L;
private static final Logger LOGGER = LoggerFactory.getLogger(SubOrderDeduplicateProcessFunc.class);
private ValueState<Boolean> existState;
@Override
public void open(Configuration parameters) throws Exception {
StateTtlConfig stateTtlConfig = StateTtlConfig.newBuilder(Time.days(1))
.setStateVisibility(StateVisibility.NeverReturnExpired)
.setUpdateType(UpdateType.OnCreateAndWrite)
.cleanupInRocksdbCompactFilter(10000)
.build();
ValueStateDescriptor<Boolean> existStateDesc = new ValueStateDescriptor<>(
"suborder-dedup-state",
Boolean.class
);
existStateDesc.enableTimeToLive(stateTtlConfig);
existState = this.getRuntimeContext().getState(existStateDesc);
}
@Override
public void processElement(Tuple3<Integer, Long, String> value, Context ctx, Collector<String> out) throws Exception {
if (existState.value() == null) {
existState.update(true);
out.collect(value.f2);
}
}
}
上述代码中设定了状态TTL的相关参数:
- 过期时间设为1天;
- 在状态值被创建和被更新时重设TTL;
- 已经过期的数据不能再被访问到;
- 在每处理10000条状态记录之后,更新检测过期的时间戳。这个参数要小心设定,更新太频繁会降低compaction的性能,更新过慢会使得compaction不及时,状态空间膨胀。
在实际处理数据时,如果数据的key(即子订单ID)对应的状态不存在,说明它没有出现过,可以更新状态并输出。反之,说明它已经出现过了,直接丢弃,so easy。
最后还需要注意一点,若数据的key占用的空间比较大(如长度可能会很长的字符串类型),也会造成状态膨胀。我们可以将它hash成整型再存储,这样每个key就最多只占用8个字节了。不过任何哈希算法都无法保证不产生冲突,所以还是得根据业务场景自行决定。
引入外部K-V存储去重
如果既不想用布隆过滤器,也不想在Flink作业内维护巨大的状态,就只能用折衷方案了:利用外部K-V数据库(Redis、HBase之类)存储需要去重的键。由于外部存储对内存和磁盘占用同样敏感,所以也得设定相应的TTL,以及对大的键进行压缩。另外,外部K-V存储毕竟是独立于Flink框架之外的,一旦作业出现问题重启,外部存储是不会与作业的checkpoint同步恢复到一致的状态的,也就是说结果仍然会出现偏差,需要注意。
鉴于这种方案对第三方组件有强依赖,要关心的东西太多,所以一般情况下是不用的,我们也没有实操过,所以抱歉没有代码了。
The End
如果有其他更高效的解决方法,欢迎批评指正哈。