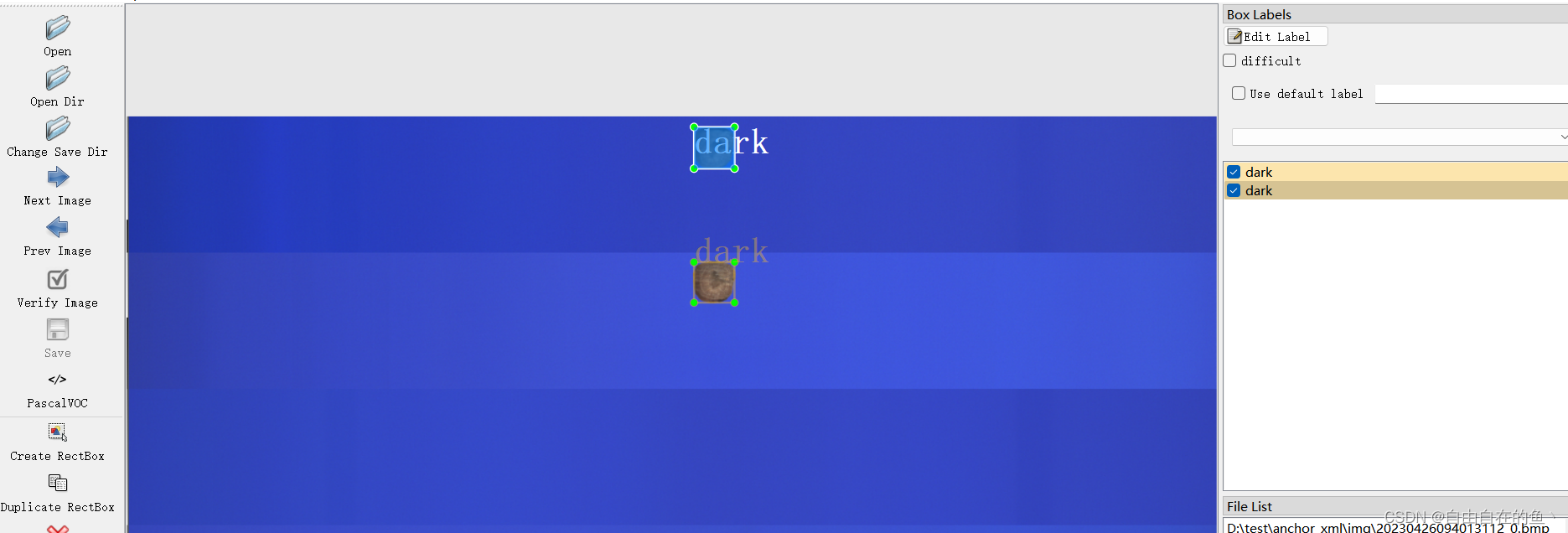
首先,故障预测与健康管理PHM基于先进传感器技术获取复杂设备的运行状态信息,借助智能算法实现复杂工程系统的故障诊断、健康状态预测与管理。基于机器学习的PHM技术能够充分挖掘多源异构数据的信息,提高故障诊断、健康状态预测以及剩余寿命估计的准确性。然而,这样的复杂高维非线性模型很难被解释,因此难以获取客户的信任,且设计者难以依据其内部运转机理作针对性的改进。
一般地,PHM由三部分功能支撑,即数据前处理、故障诊断、健康状态预测。数据前处理部分主要包括特征提取和特征选择,即在建模之前对原始的复杂信号进行特征提取,并依照特征的重要性进行特征选择,典型的方法有稀疏化信号处理,构建稀疏化的数据处理模型来得到非零个数最少的特征组合,降低信号的冗余度,这一做法实际与机器学习模型结构稀疏化思想近似,认为是增强模型透明度,提高可解释性的一种方式;最优特征选择则与机器学习中的特征重要性排序类似,在建模过程或建模以后分析特征对决策的影响,也认为是一种模型可解释性的探索;在PHM中的故障诊断和健康状态预测建模中,采用正则化函数约束深度模型的构建过程,促进模型稀疏化,也可以从模型结构上提高可解释性;以及在模型构建完成后结合系统的机理运作知识,对模型进行后验分析和讨论,实际上也属于对模型的事后可解释性探讨。
数据前处理的可解释性研究
PHM的数据前处理包括特征提取和特征选择。特征提取旨在从复杂时间序列信号中提取出能够表征设备运行状态的特征参数作为特征候选者,主要介绍与可解释性研究相关的稀疏化信号处理与特征选择。
(1)稀疏化信号处理
稀疏化信号处理旨在将传感器获取的存在噪声的复杂时间序列信号转换为有效的特征,且提取出原始信号中不同区域或时域内信息的重要性,提高后续模型的精度。稀疏表征是一种典型的稀疏化处理方法,其用超完备字典中较少的原子来表征信号,希望获得非零个数最少的线性表征,降低信号的冗余度。尽管很多学者在研究过程中没有明确指出模型的可解释性,但更加稀疏的特征编码方式诚然提高了模型的泛化性,同时也使得模型的解释性得到提升。
(2)最优特征选择
在对原始信号进行特征提取后,需筛选出对故障分类模型最有利的特征,在提高诊断精度的同时,一定程度上也为使用者提供了故障诱因及相应的诊断机制。根据算法与分类器训练的顺序可将应用在故障诊断特征选择方法分为三类,分别是过滤式、包裹式和嵌入式。
①过滤式方法
过滤式特征选择通过度量特征在后续分类任务中的重要性进行排序和选择,基于相关性准则的特征选择是一种典型的过滤式筛选方法。
②包裹式方法
包裹式方法借助诊断系统外的分类器对特征集进行评估,通过最大化其分类性能搜索最优特征子集,这样的方法具有比过滤式更高的精度。
③嵌入式方法
嵌入式方法将特征选择过程和模型训练过程结合,使二者同时进行,避免了包裹式方法庞大的搜索计算。
综上,最优特征选择方法实际上基于对特征本身的统计特征和特征与模型输出的量化关系进行特征分析,以分析后的结论选择对模型有利的特征。这实际上就是对模型输入输出的解释,以不同的方式(过滤式、嵌入式和包裹式)得到了特征的重要性,是PHM 领域中对诊断预测模型可解释性的重要探索。
故障诊断模型的可解释性研究
诸多学者致力于构建更稀疏、泛化性更好的模型来减轻训练过程中得过拟合现象,提高故障诊断模型的分类精度。一种典型的稀疏结构模型为稀疏贝叶斯网络。鉴于机器学习领域中的模型可解释性的定义和研究方法,很多研究在模型构建、以及模型事后分析中降低了模型的复杂度,增加了模型的被信任度,触及到机器学习模型内在可解释性的研究范畴。然而,进一步针对工业故障诊断模型的可解释性研究还需加强。
健康状态预测模型的可解释性研究
设备的健康状态预测根据系统现在或历史的数据预测未来一段时间的性能状态,包括整个设备或部件的退化程度评估和剩余寿命预测。相对于故障诊断,健康状态预测的本质任务是回归而非分类,且模型得到的是未来某时间段内的特征趋势。研究者在追求预测精度的同时,在一定程度上也展开了对预测模型特性与机理的探讨,涉及到模型事后解释的研究范畴。相对于故障诊断模型,健康状态预测深度模型的可解释性探索多停留在对模型建成后的模型决策原理讨论,未在建模过程中考虑对模型结构的可解释性优化。
当前PHM领域的机器学习可解释性研究与机器学习基础研究领域存在较大的差距,其中模型机理知识融入和模型可视化决策分析并未在PHM的机器学习研究中开展,而这两种研究方法也是实现模型可解释性的重要手段,在面向重要应用场合的PHM中研究需求迫切。


知乎咨询:哥廷根数学学派
算法代码地址:mbd.pub/o/GeBENHAGEN
擅长现代信号处理(改进小波分析系列,改进变分模态分解,改进经验小波变换,改进辛几何模态分解等等),改进机器学习,改进深度学习,机械故障诊断,改进时间序列分析(金融信号,心电信号,振动信号等)