1. 获取时间序列数据(官方文档是多特征,本文举例是单特征)
未安装pycaret的先安装:pip install --pre pycaret (也可以pip install pycaret)

2.用pycaret检测异常一般用pycaret.anomaly
pycaret.anomaly的所有功能: assign_model, create_model, deploy_model, evaluate_model, get_config, get_logs, load_config, load_model, models, plot_model, predict_model, pull, save_config, save_model, set_config, set_current_experiment, setup, tune_model,
from pycaret.anomaly import *
setup = setup(df, session_id = 123) 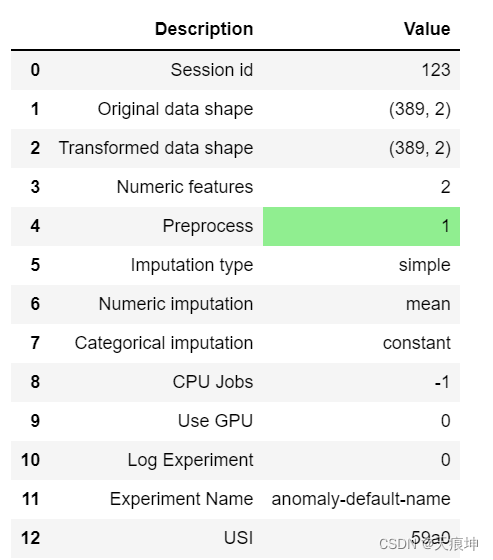
3.获取pycaret支持的所有检测异常模型
models()
def create_model( model: Union[str, Any], fraction: float = 0.05, verbose: bool = True, fit_kwargs: Optional[dict] = None, experiment_custom_tags: Optional[Dict[str, Any]] = None, **kwargs, ):""" This function trains a given model from the model library. All available models can be accessed using the ``models`` function.model: str or scikit-learn compatible object ID of an model available in the model library or pass an untrained model object consistent with scikit-learn API. Estimators available in the model library (ID - Name): * 'abod' - Angle-base Outlier Detection * 'cluster' - Clustering-Based Local Outlier * 'cof' - Connectivity-Based Outlier Factor * 'histogram' - Histogram-based Outlier Detection * 'knn' - k-Nearest Neighbors Detector * 'lof' - Local Outlier Factor * 'svm' - One-class SVM detector * 'pca' - Principal Component Analysis * 'mcd' - Minimum Covariance Determinant * 'sod' - Subspace Outlier Detection * 'sos' - Stochastic Outlier Selectionfraction: float, default = 0.05 The amount of contamination of the data set, i.e. the proportion of outliers in the data set. Used when fitting to define the threshold on the decision function. verbose: bool, default = True Status update is not printed when verbose is set to False. experiment_custom_tags: dict, default = None Dictionary of tag_name: String -> value: (String, but will be string-ified if not) passed to the mlflow.set_tags to add new custom tags for the experiment. fit_kwargs: dict, default = {} (empty dict) Dictionary of arguments passed to the fit method of the model. **kwargs: Additional keyword arguments to pass to the estimator. Returns: Trained Model """
4. 使用其中一个算法测试(使用的算法参数都是默认的,调参的话效果会更好)
import plotly.express as px
def get_line(df_p):
# print(df_test)
fig = px.line(df_p, x="date", y="y", color='mark', title="Sorted Input")
fig.update_xaxes(tickformat="%Y-%m-%d", hoverformat="%Y-%m-%d", row=1)
fig.update_traces(dict(mode="markers+lines"))
fig.update_layout(title_text="趋势图", title_x=0.5)
fig.update(layout=dict(xaxis=dict(title="日期", tickangle=-45,
showline=True, nticks=20),
yaxis=dict(title="值", showline=True)))
return fig
def mark(df):
df['date'] = df.index
df = df.reset_index(drop=True)
df_start_time = str(df.date.min()).split(' ')[0]
df_end_time = str(df.date.max()).split(' ')[0]
df_end_time_next = (datetime.datetime.strptime(df_end_time, '%Y-%m-%d') + datetime.timedelta(days=1)).strftime('%Y-%m-%d')
date_range = pd.date_range(df_start_time, df_end_time_next, freq='D')
df_raw = pd.DataFrame()
df_outliers = pd.DataFrame()
df_raw["date"] = date_range
df_outliers["date"] = date_range
df_outliers_is = df[df['Anomaly']==1]
df_outliers = pd.merge(df_outliers, df_outliers_is[['date','y']], on=["date"], how="left")
df_outliers.columns = ['date','y']
df_outliers['mark'] = 'outliers'
df_outliers_no = df[df['Anomaly']==0]
df_raw = pd.merge(df_raw, df_outliers_no[['date','y']], on=["date"], how="left")
df_raw.columns = ['date','y']
df_raw['mark'] = 'true'
df_all = pd.concat([df_raw, df_outliers])
return df_alliforest = create_model('iforest') # 默认异常值比例为0.05
iforest_results = assign_model(iforest)
iforest_results = mark(iforest_results)
iforest_results
get_line(iforest_results)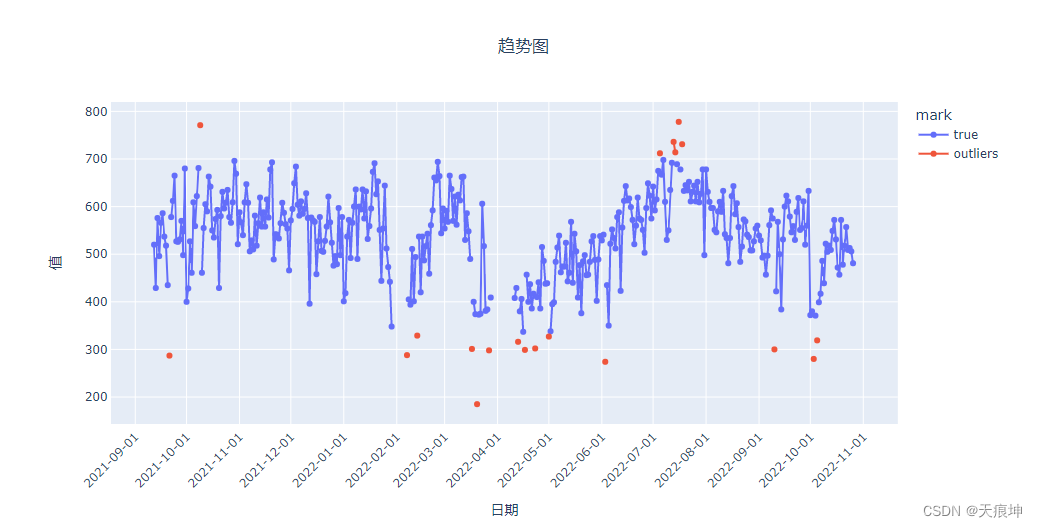
下一个算法:
knn = create_model('knn')
knn_results = assign_model(knn)
knn_results = mark(knn_results)
get_line(knn_results) 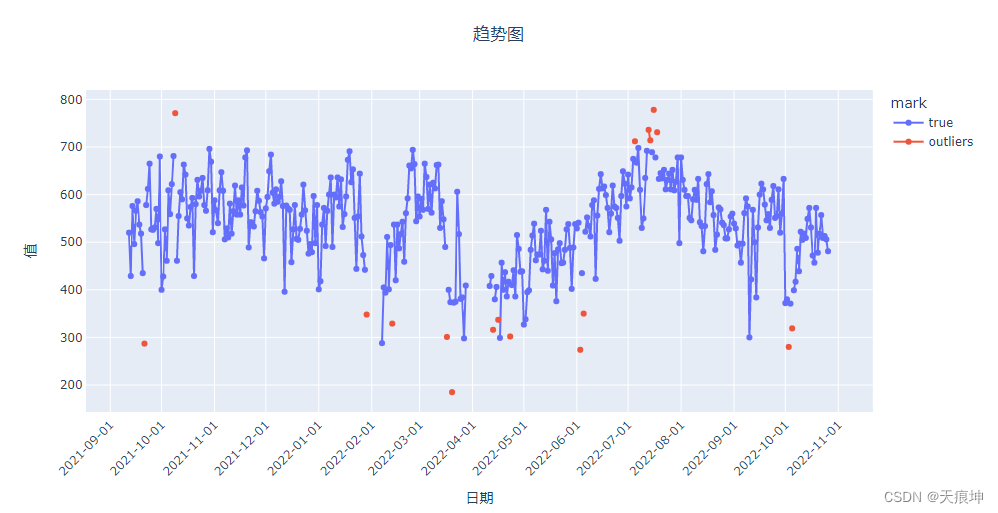
下一个算法:
lof = create_model('lof')
lof_results = assign_model(lof)
lof_results = mark(lof_results)
get_line(lof_results)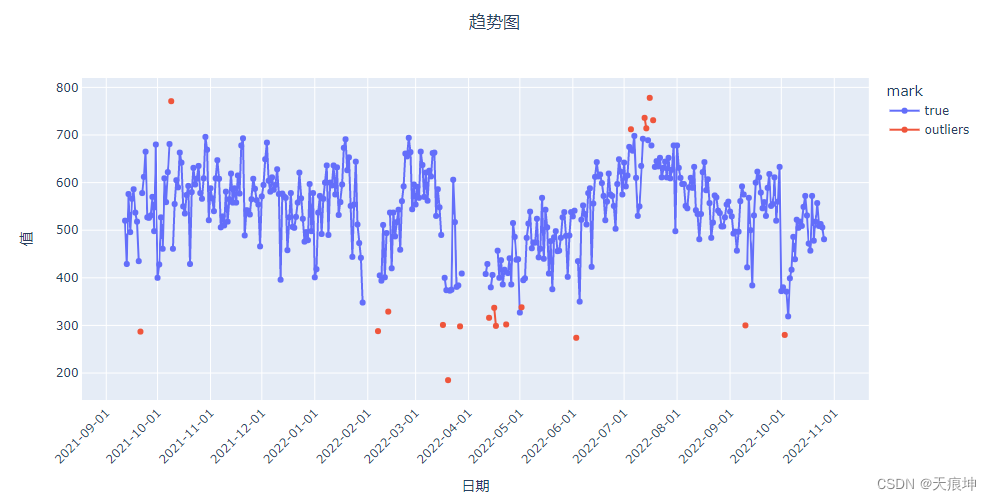
下一个算法:
svm = create_model('svm')
svm_results = assign_model(svm)
svm_results = mark(svm_results)
get_line(svm_results)
下一个算法:
pca = create_model('pca')
pca_results = assign_model(pca)
pca_results = mark(pca_results)
get_line(pca_results)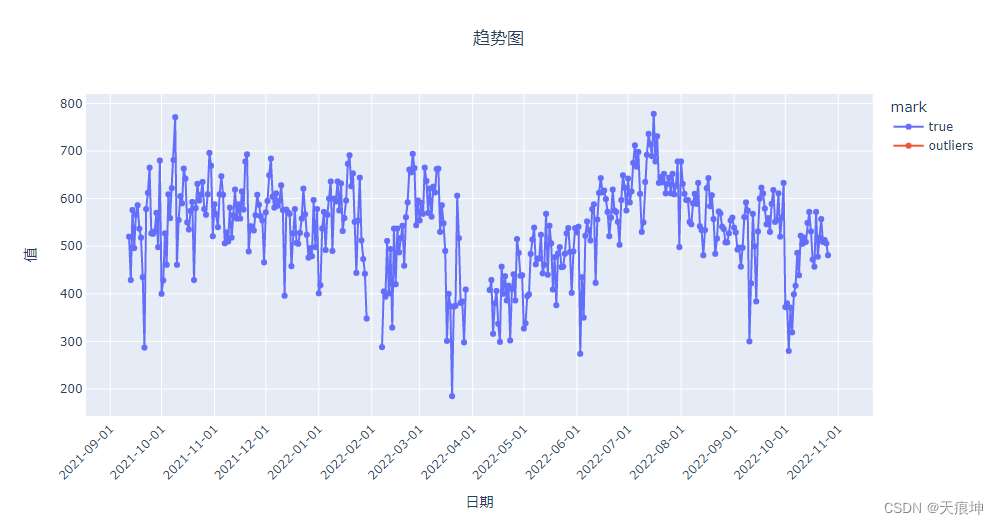
下一个算法:
sos = create_model('sos')
sos_results = assign_model(sos)
sos_results = mark(sos_results)
get_line(sos_results) 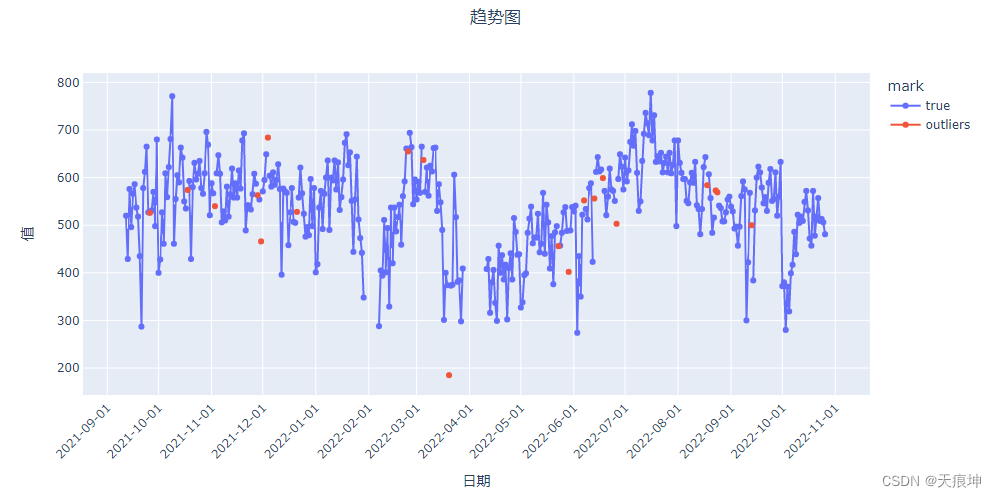
下一个算法:
sod = create_model('sod')
sod_results = assign_model(sod)
sod_results = mark(sod_results)
get_line(sod_results)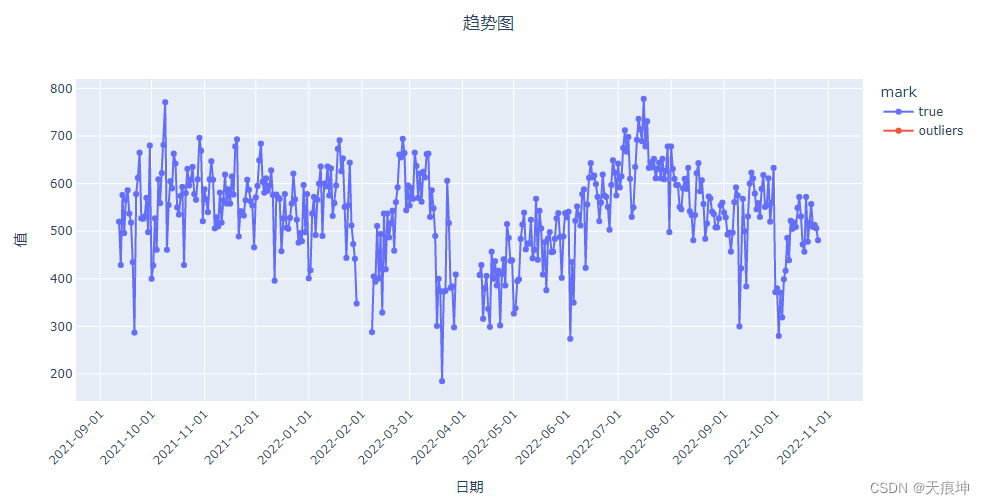
下一个算法:
mcd = create_model('mcd')
mcd_results = assign_model(mcd)
mcd_results = mark(mcd_results)
get_line(mcd_results)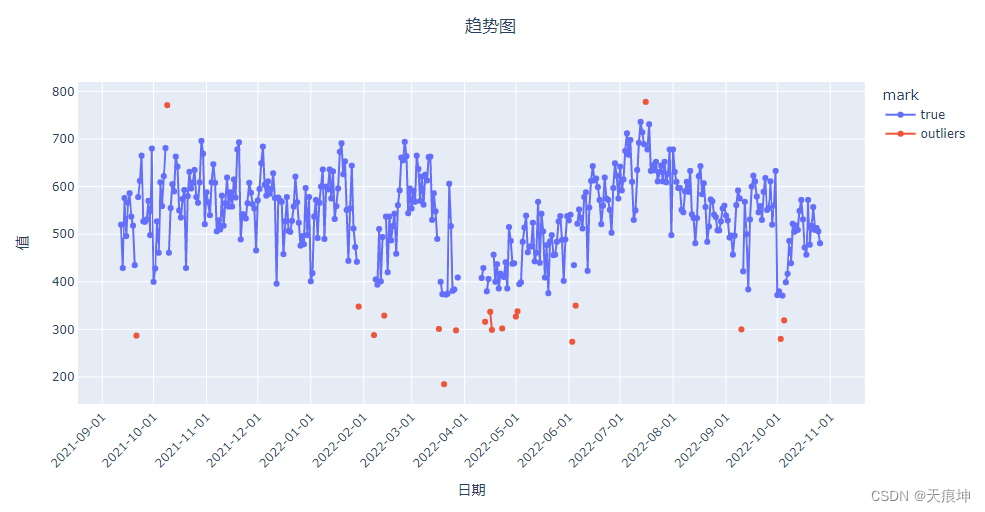
下一个算法:
histogram = create_model('histogram')
histogram_results = assign_model(histogram)
histogram_results = mark(histogram_results)
get_line(histogram_results)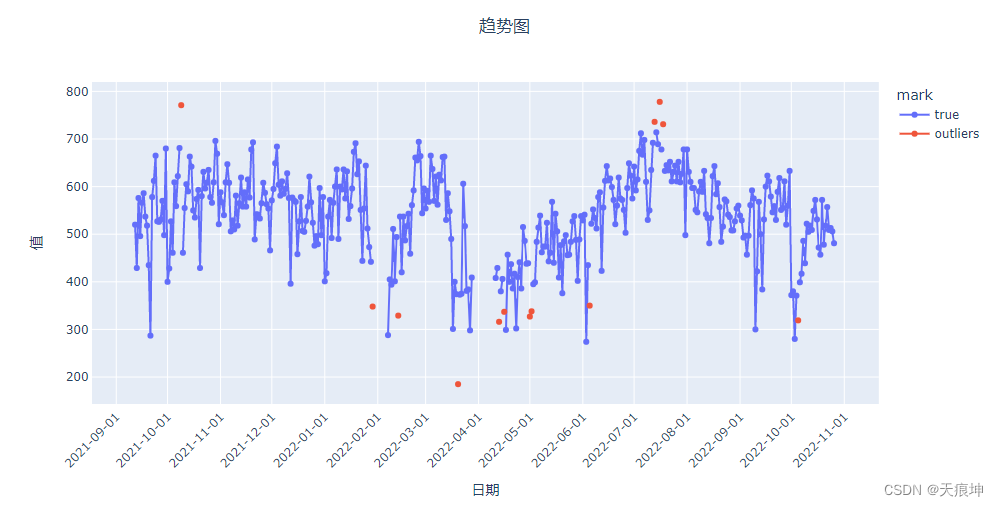
下一个算法:
abod = create_model('abod')
abod_results = assign_model(abod)
abod_results = mark(abod_results)
get_line(abod_results)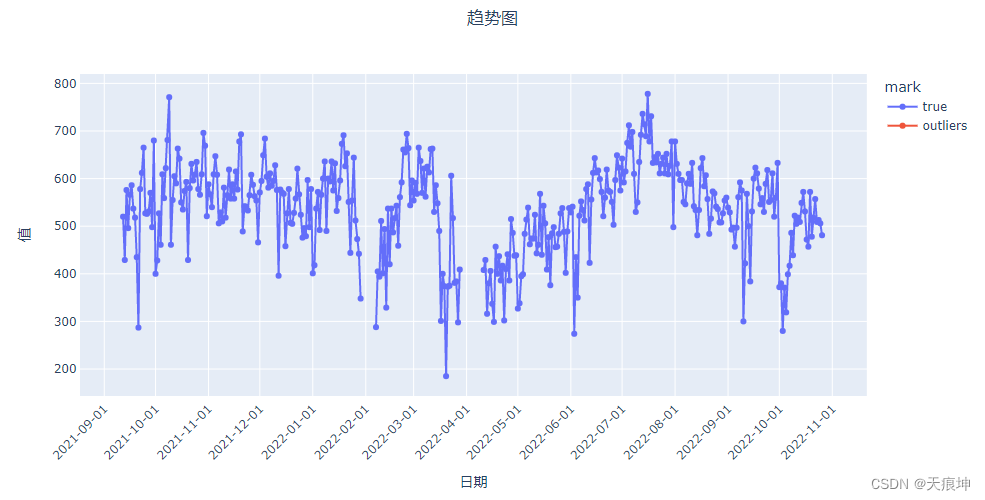
下一个算法:
cluster = create_model('cluster')
cluster_results = assign_model(cluster)
cluster_results = mark(cluster_results)
get_line(cluster_results)
下一个算法:
cof = create_model('cof')
cof_results = assign_model(cof)
cof_results = mark(cof_results)
get_line(cof_results)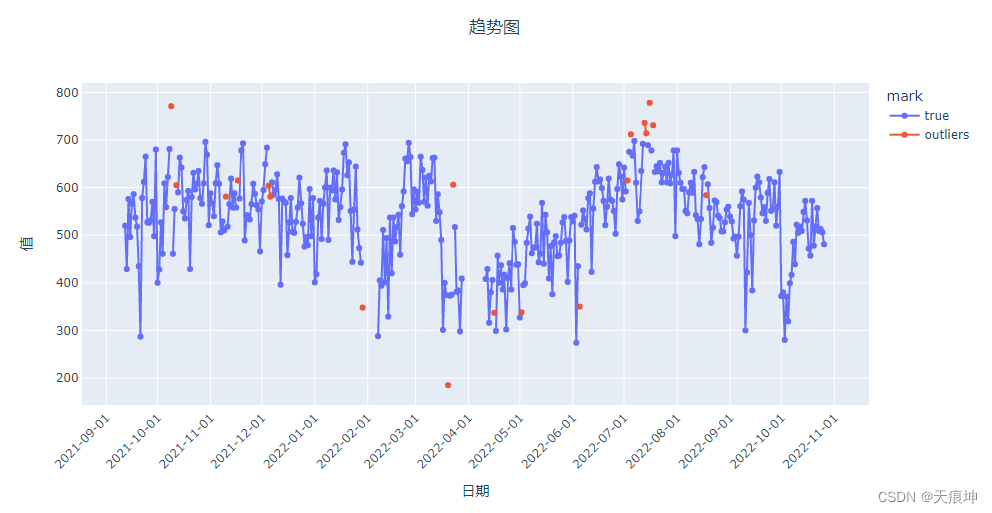
5.PyCaret 中为 算法使用evaluate_model() 函数,查看流程
evaluate_model(iforest)
6.PyCaret 中为 算法使用plot_model() 函数,它将为异常值创建一个 3D 图,在其中我们可以看到为什么某些特征被视为异常。
plot_model(iforest)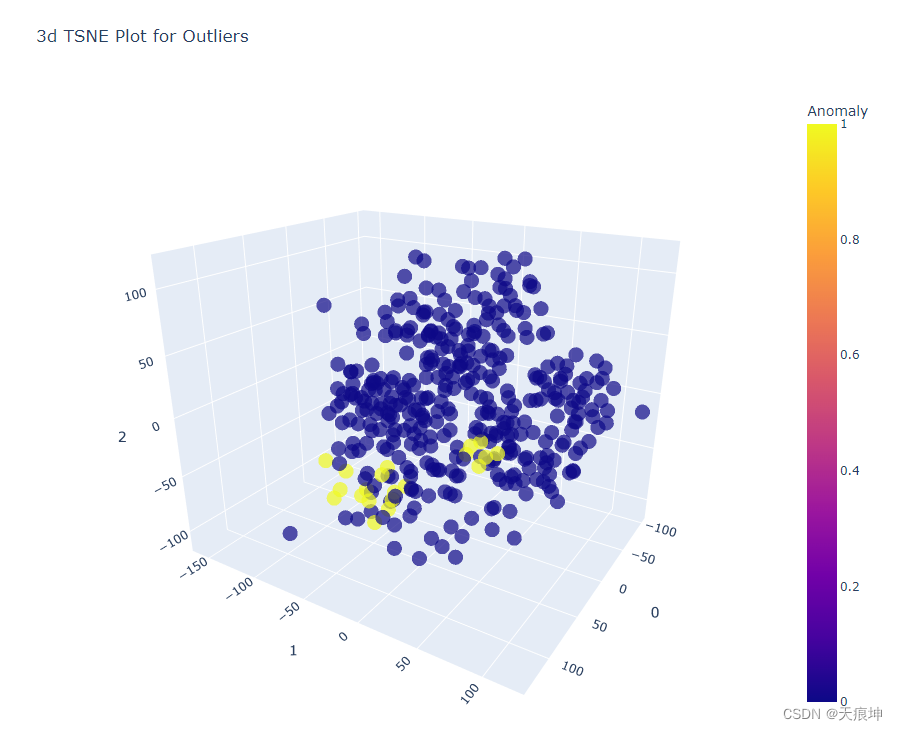
plot_model(knn)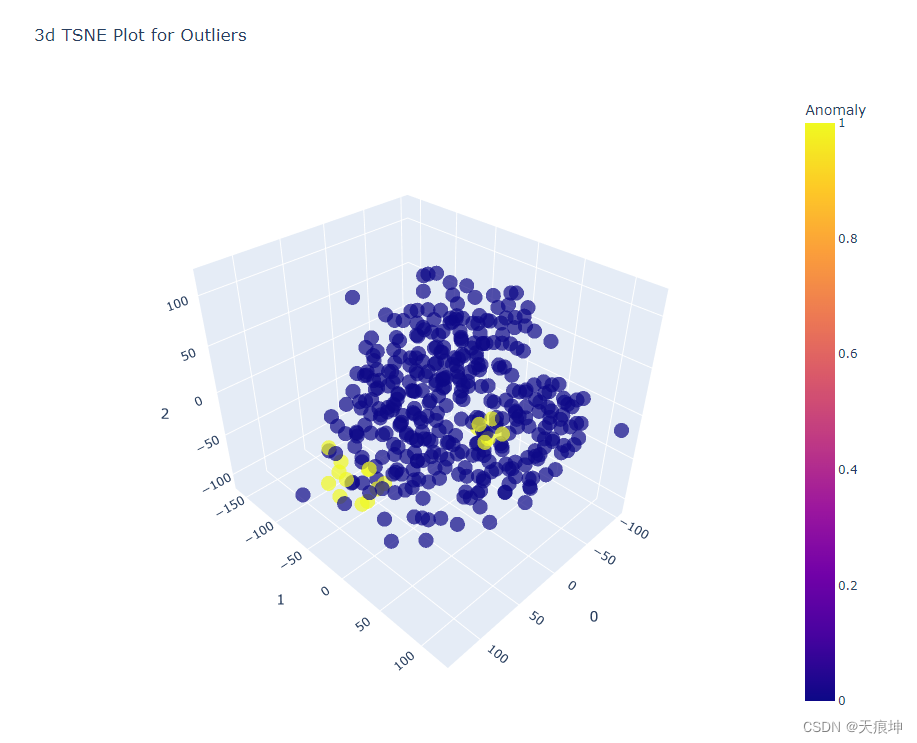
我们可以放大这个二维图来查看哪些点被认为是异常值。
可以再次为配对图创建另一个视觉效果,现在使用异常来查看哪些点将被视为异常。
import seaborn as sns
iforest = create_model('iforest')
iforest_results = assign_model(iforest)
sns.pairplot(iforest_results, hue = "Anomaly")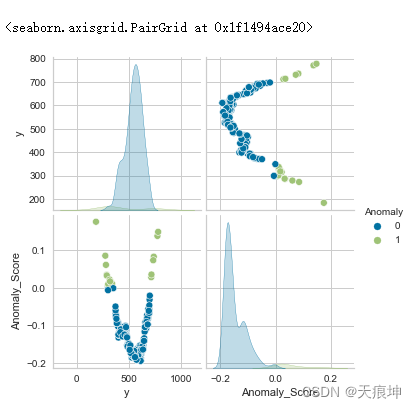
最后,我们可以保存模型。可以保存任何合适的模型。这里我们保存了 iforest 模型。
save_model(iforest,'IForest_Model') 
先这样,有时间再完善吧