在 PostgreSQL 中,常规表、外部表和分区表都可以通过 `CREATE TABLE` 语句进行创建,它们的创建语法略有不同,通过创建语句可以很明显地区分它们的类型。
以下是常规表、外部表和分区表的创建语法及示例:
1. 常规表
常规表是最常见的表类型,它将数据存储在数据库中,支持各种 CRUD 操作。常规表的创建语法如下:
CREATE TABLE table_name (
column1 data_type constraint,
column2 data_type constraint,
...
[ table_constraint ]
) [ INHERITS ( parent_table [, ... ] ) ]
[ WITH ( storage_parameter [= value] [, ... ] ) ]
[ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ]
[ TABLESPACE tablespace_name ]
[ PARTITION BY partition_type ( partition_column ) ]
[ SUBPARTITION BY subpartition_type ( subpartition_column ) ]
[ SUBPARTITION TEMPLATE ( subpartition_definitions ) ]
[ OPTIONS ( storage_parameter [= value] [, ... ] ) ]以下是创建一个常规表的示例:
CREATE TABLE employee (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
age INT,
salary NUMERIC(10,2)
);2. 外部表
对于外部表,确实是不会将数据存储在数据库中,因此在数据库中是看不到数据的。如果您尝试使用 SQL对外部表进行修改或删除操作,通常会导致错误。因为外部表只是一个定义不包含实际的数据,而且它的定义通常是根据外部数据源的格式而定义的,如果您强行修改或删除,可能会导致与外部数据源不一致,进而影响到查询结果。
外部表是一个虚拟表,它并不在 PostgreSQL 数据库中存储数据,而是通过外部数据源来访问数据。外部表的创建语法如下:
CREATE EXTERNAL TABLE table_name (
column1 data_type,
column2 data_type,
...
) [ OPTIONS ( option 'value', ... ) ]
LOCATION ( 'external_file_or_directory_path' [, ... ] )
FORMAT format_name
[ DELIMITER delimiter ]
[ HEADER [ boolean ] ]
[ QUOTE [ character ] ]
[ ESCAPE [ character ] ]
[ NULL [ string ] ]以下是创建一个外部表的示例:
CREATE EXTERNAL TABLE employee_ext (
id INT,
name VARCHAR(50),
age INT,
salary NUMERIC
) LOCATION ('/path/to/employee.csv') FORMAT 'CSV' HEADER DELIMITER ',';外部表的定义通常会包含外部数据源的元数据信息,如数据源的文件路径、文件格式、字段分隔符等等。因此,从创建的 SQL语句中可以很明显地区分出外部表和常规表之间的差异。
其中,关键字EXTERNAL TABLE指定了这是一个外部表,LOCATION指定了外部数据源的路径,FORMAT指定了外部数据源的格式,而常规表则是使用CREATE TABLE语法进行创建
3. 分区表
分区表是常规表的一种特殊形式,它将数据划分为多个子表,每个子表可以单独进行管理和查询,从而提高查询性能和维护效率。分区表的创建语法如下:
CREATE TABLE parent_table (
partition_key data_type constraint,
column1 data_type constraint,
column2 data_type constraint,
...
[ table_constraint ]
) PARTITION BY partition_type ( partition_key );以下是创建一个分区表的示例:
CREATE TABLE sales (
date DATE,
region VARCHAR(50),
product VARCHAR(50),
sales_amount NUMERIC
) PARTITION BY RANGE (date);从上面的示例中可以看出,分区表的创建语法与常规表的创建语法相似,但是增加了 `PARTITION BY` 子句用于指定分区键和分区类型。
分区表有哪几种?
1、简介
表分区是解决一些因单表过大引用的性能问题的方式,比如某张表过大就会造成查询变慢,可能分区是一种解决方案。一般建议当单表大小超过内存就可以考虑表分区了。PostgreSQL的表分区有三种方式:
- Range:范围分区;
- List:列表分区;
- Hash:哈希分区。
本文通过示例讲解如何进行这三种方式的分区。
2、三种方式
为方便,我们通过Docker的方式启动一个PostgreSQL。我们要选择较高的版本,否则不支持Hash分区,命令如下:
docker run -itd \
--name pkslow-postgres \
-e POSTGRES_DB=pkslow \
-e POSTGRES_USER=pkslow \
-e POSTGRES_PASSWORD=pkslow \
-p 5432:5432 \
postgres:13
2.1、Range范围分区
先创建一张表带有年龄,然后我们根据年龄分段来进行分区,创建表语句如下:
CREATE TABLE pkslow_person_r (
age int not null,
city varchar not null
) PARTITION BY RANGE (age);
这个语句已经指定了按age字段来分区了,接着创建分区表:
create table pkslow_person_r1 partition of pkslow_person_r for values from (MINVALUE) to (10); create table pkslow_person_r2 partition of pkslow_person_r for values from (11) to (20); create table pkslow_person_r3 partition of pkslow_person_r for values from (21) to (30); create table pkslow_person_r4 partition of pkslow_person_r for values from (31) to (MAXVALUE);
这里创建了四张分区表,分别对应年龄是0到10岁、11到20岁、21到30岁、30岁以上。
接着我们插入一些数据:
insert into pkslow_person_r(age, city) VALUES (1, 'GZ'); insert into pkslow_person_r(age, city) VALUES (2, 'SZ'); insert into pkslow_person_r(age, city) VALUES (21, 'SZ'); insert into pkslow_person_r(age, city) VALUES (13, 'BJ'); insert into pkslow_person_r(age, city) VALUES (43, 'SH'); insert into pkslow_person_r(age, city) VALUES (28, 'HK');
可以看到这里的表名还是pkslow_person_r,而不是具体的分区表,说明对于客户端是无感知的。
我们查询也一样的:
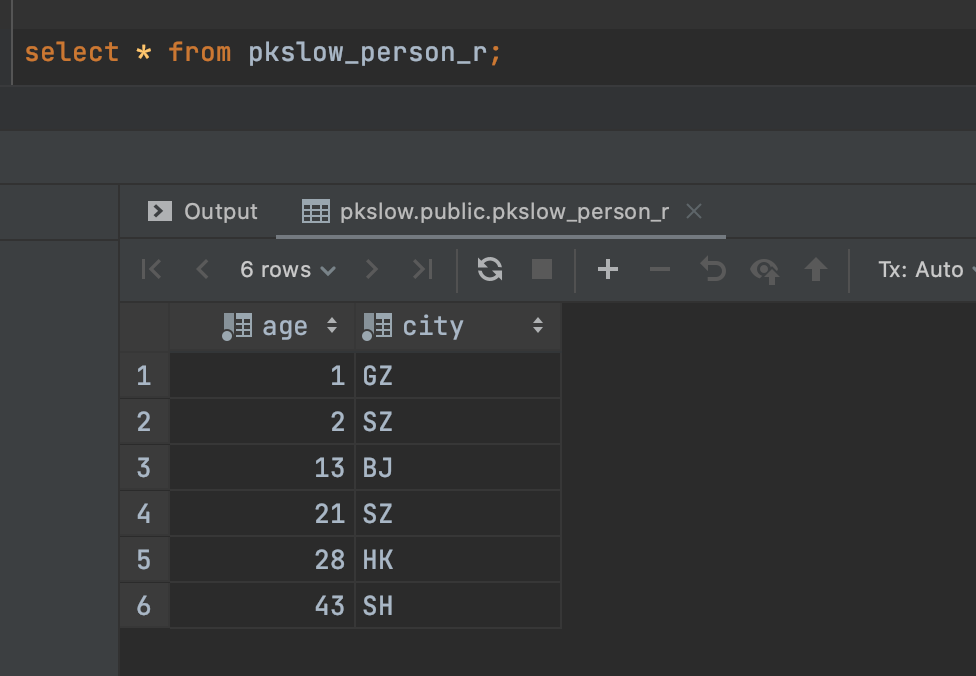
但实际上是有分区表存在的:
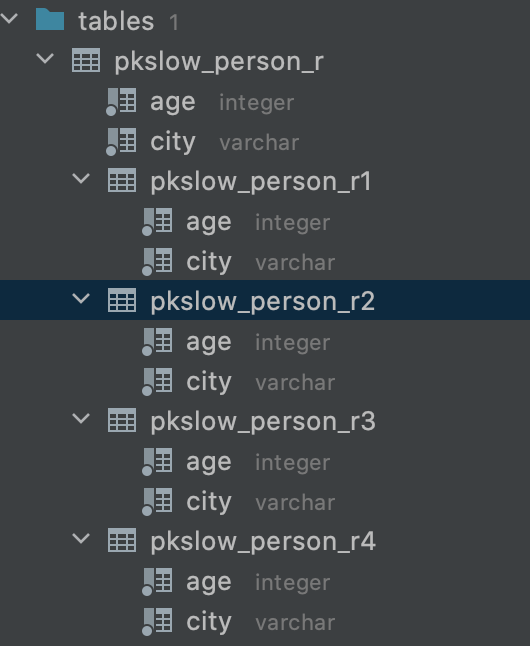
而且分区表与主表的字段是一致的。
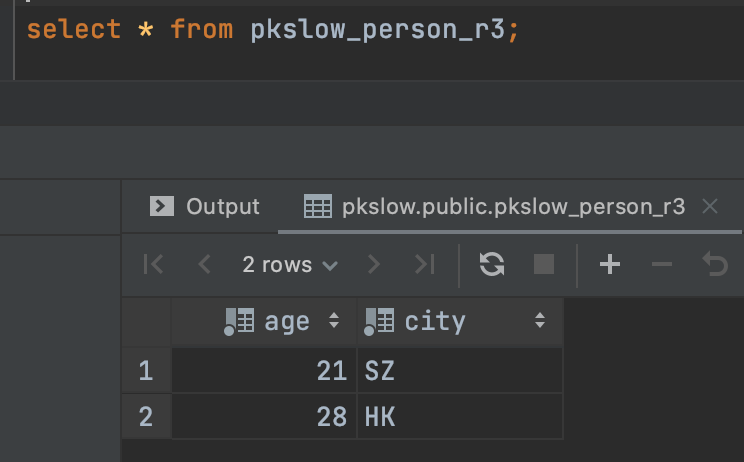
查询分区表,就只能查到那个特定分区的数据了:
2.2、List列表分区
类似的,列表分区是按特定的值来分区,比较某个城市的数据放在一个分区里。这里不再给出每一步的讲解,代码如下:
-- 创建主表 create table pkslow_person_l ( age int not null, city varchar not null ) partition by list (city); -- 创建分区表 CREATE TABLE pkslow_person_l1 PARTITION OF pkslow_person_l FOR VALUES IN ('GZ'); CREATE TABLE pkslow_person_l2 PARTITION OF pkslow_person_l FOR VALUES IN ('BJ'); CREATE TABLE pkslow_person_l3 PARTITION OF pkslow_person_l DEFAULT; -- 插入测试数据 insert into pkslow_person_l(age, city) VALUES (1, 'GZ'); insert into pkslow_person_l(age, city) VALUES (2, 'SZ'); insert into pkslow_person_l(age, city) VALUES (21, 'SZ'); insert into pkslow_person_l(age, city) VALUES (13, 'BJ'); insert into pkslow_person_l(age, city) VALUES (43, 'SH'); insert into pkslow_person_l(age, city) VALUES (28, 'HK'); insert into pkslow_person_l(age, city) VALUES (28, 'GZ');
当我们查询第一个分区的时候,只有广州的数据:
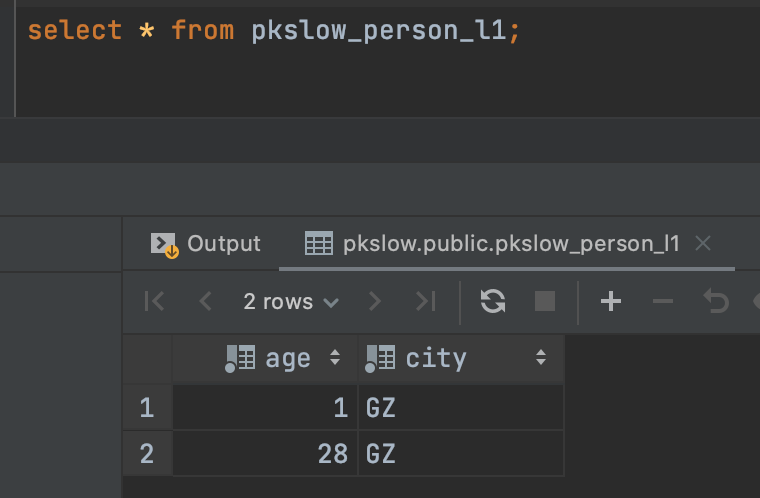
2.3、Hash哈希分区
哈希分区是指按字段取哈希值后再分区。具体的语句如下:
-- 创建主表 create table pkslow_person_h ( age int not null, city varchar not null ) partition by hash (city); -- 创建分区表 create table pkslow_person_h1 partition of pkslow_person_h for values with (modulus 4, remainder 0); create table pkslow_person_h2 partition of pkslow_person_h for values with (modulus 4, remainder 1); create table pkslow_person_h3 partition of pkslow_person_h for values with (modulus 4, remainder 2); create table pkslow_person_h4 partition of pkslow_person_h for values with (modulus 4, remainder 3); -- 插入测试数据 insert into pkslow_person_h(age, city) VALUES (1, 'GZ'); insert into pkslow_person_h(age, city) VALUES (2, 'SZ'); insert into pkslow_person_h(age, city) VALUES (21, 'SZ'); insert into pkslow_person_h(age, city) VALUES (13, 'BJ'); insert into pkslow_person_h(age, city) VALUES (43, 'SH'); insert into pkslow_person_h(age, city) VALUES (28, 'HK');
可以看到创建分区表的时候,我们用了取模的方式,所以如果要创建N个分区表,就要取N取模。
随便查询一张分区表如下:
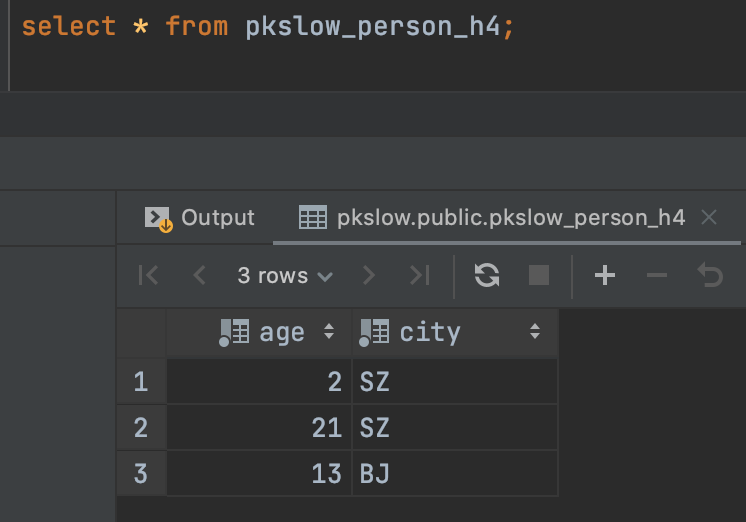
可以看到同是SZ的哈希值是一样的,肯定会分在同一个分区,而BJ的哈希值取模后也属于同一个分区。












![C嘎嘎~~ [类 上篇]](https://img-blog.csdnimg.cn/5b45fc66fd7f40b09ca9b4ad379f3ba4.png)