【22-23 春学期】AI作业2-监督学习_HBU_David的博客-CSDN博客
用自己的语言,解释以下概念
1 结构风险最小化
2 正则化
3 线性回归
4 逻辑斯蒂回归
5 Sigmoid 与 SoftMax 函数
6 决策树
7 信息熵 条件熵 信息增益
8 线性判别分析 LDA
9 概率近似正确 PAC
10 自适应提升AdaBoost
结构风险最小化
- 为了防止由数据量、噪声或模型本身造成的过拟合问题,往往需要对模型本身进行限制,使其不要过度地经验风险最小化,因此在经验风险之上再引入正则化项(或惩罚项),以此来平衡经验最小化和模型复杂度。
正则化
- 正则化是一种为了防止过拟合和提高模型泛化能力的方法,它通过对模型参数的约束来避免模型复杂度过高,在损失函数中加入一个正则项,如 L1 正则或 L2 正则,来惩罚模型参数的大小。
补:L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓惩罚是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
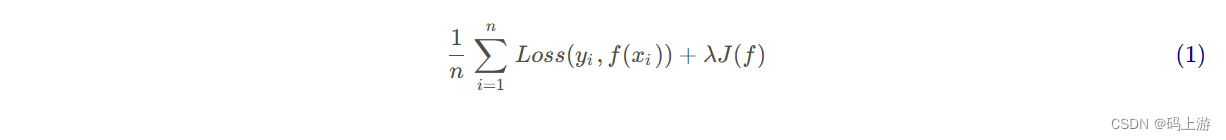
线性回归
- 刻画目标变量与一个或者多个变量之间关系的模型就是回归模型,如果这种关系是线性的,这个模型就称为线性回归模型。对原数据进行一系列数据拟合,并尽可能构造一条可以拟合数据的数学模型,根据这个模型,输入测试数据进而预测数据的结果。
逻辑斯蒂回归(对数几率回归)
- logistic 回归分析实质是一种分类,它是研究因变量为二项分类或多项分类结果与某些影响因素之间关系的一种多重回归分析方法。同线性回归一样通过对一系列数据拟合模型,来预测未来某一数据的走向,但是不同的时逻辑斯蒂回归则是建立模型将数据分为不同的类别,然后预测某个数据的类别。
- logistic回归是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域(概率问题)。
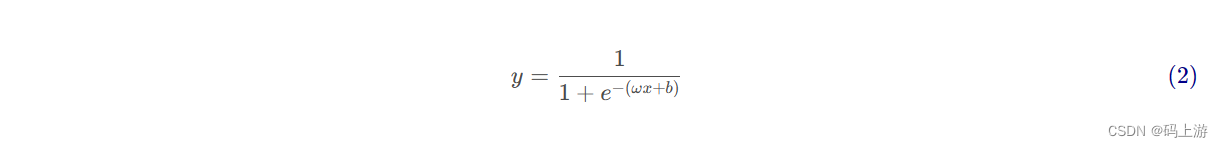
Sigmoid & SoftMax 函数
- S 型函数(英语:sigmoid function,或称乙状函数)是一种函数,因其函数图像形状像字母S得名。其形状曲线至少有2个焦点,也叫“二焦点曲线函数”。S型函数是有界、可微的实函数,在实数范围内均有取值,且导数恒为非负,有且只有一个拐点。
- 建立在 Sigmoid 函数基础上的逻辑斯蒂回归只能解决二分类问题。因此将其推广为了即多项逻辑斯蒂回归(muti-nominal logistic model,也即 softmax 函数)用于处理多分类问题,便可以得到 softmax 回归。
决策树
- 机器学习中的决策树是一种基于树形结构的分类或回归算法,它通过对数据集进行递归划分,根据不同属性的取值来生成决策规则。决策树的优点是易于理解和解释,并且可以处理缺失值、离散值和连续值等多种类型的数据。决策树的缺点是可能产生过拟合、不稳定和偏向性等问题。
信息熵 条件熵 信息增益
- 信息熵:信息熵时度量样本集合纯度的最常用的一种指标,它衡量了信息不确定性的量化,反映信息的复杂程度和随机性(即信息的混乱程度,类比物理学中的熵)。信息熵越大,表示信息的不确定性与混乱程度越高。信息熵越小,表示信息的不确定性与混乱程度也就越低。
- 条件熵: 条件熵是一种衡量在已知一个随机变量的情况下,另一随机变量不确定性的量化指标,它反映了两个随机变量之间的依赖关系。条件熵越大,表示两个随机变量之间的相关性越低,也就需要更多的信息来描述另一个随机变量。条件熵越小,表示两个随机变量之间的相关性越高,也就需要更少的信息来描述另一个随机变量。
- 信息增益:信息增益是一种衡量在已知一个特征或条件时,目标变量的不确定性减少程度(熵的减少程度)的量化指标,反映了一个特征或条件对于目标变量的区分能力。信息增益越大,表示一个特征或条件对于目标变量的影响越大,也就更利于分类或决策。信息增益越小,表示一个特征或条件对于目标变量的影响越小,也就更不利于分类或决策。
线性判别分析 LDA
- 线性判别分析LDA(Linear Discriminant Analysis)又称为Fisher线性判别分析(fisher Discriminant Analysis,FDA),是一种基于监督学习的降维技术,也就是说它的数据集的每个样本都是有类别输出的,这点与PCA(无监督学习)不同。LDA在模式识别领域(比如人脸识别,舰艇识别等图形图像识别领域)中有非常广泛的应用。
- LDA的思想是:最大化类间均值,最小化类内方差。意思就是将数据投影在低维度上,并且投影后同类别别数据的投影点尽可能的接近,不同类别数据的投影点的中心点尽可能的远。
概率近似正确 PAC
- 概率近似正确(Poably Approixmately Correct)是用来刻画机器学习中的可学习性问题。 PAC研究的问题包括:
- 如何知道学习所得的假设(hypothesis)是正确的、
- 为了接近真实假设所需要的训练数据是多少
- 假设空间的复杂度符合衡量以及如何选择假设空间。
- PAC的基本思想是,给定一个概念类(从输入空间到输出空间的映射集合),一个学习算法可以从有限的训练样本中找到一个近似于真实概念的假设,且这个假设以高于某个阈值的概率满足某个误差界。
自适应提升 AdaBoost
- 强可学习(strongly learnable):指学习模型可以以较高的学习精度对绝大多数样本完成识别任务;
- 弱可学习(weakly learnable):指学习模型仅能完成若干部分的样本识别和分类。
- AdaBoost:自适应提升 AdaBoost是一种集成学习的方法,它通过迭代地训练一系列的弱分类器,并根据每个弱分类器的误差率给予不同的权重,最后将它们组合成一个强分类器。AdaBoost可以处理分类和回归问题,具有很好的泛化能力和抗噪声能力。