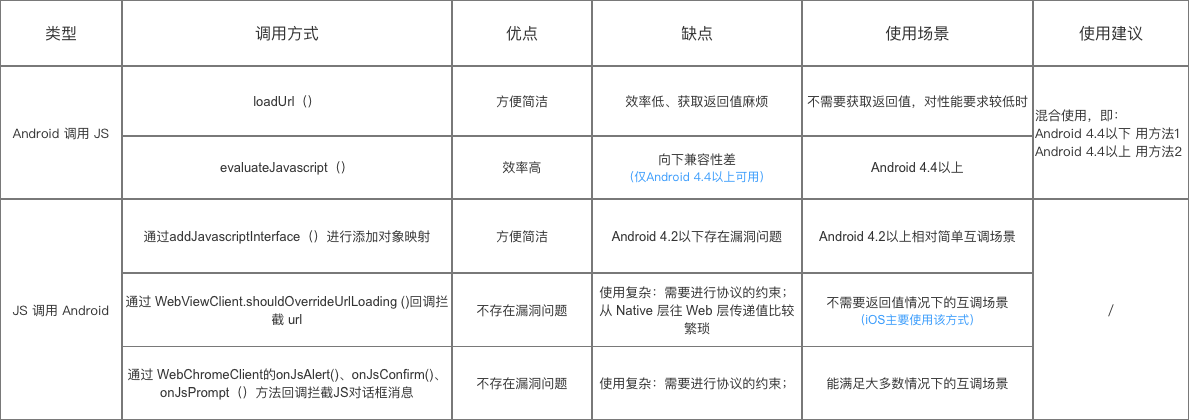
本篇文章是对yolov5_reid这篇文章训练部分的详解。
该项目目录为:
.
|-- config # reid输入大小,数据集名称,损失函数等配置
|-- configs # 训练时期超参数定义
|-- data # 存储数据集和数据处理等代码,以及yolov5类别名称等
|-- engine # 训练和测试mAP,rank等相关代码
|-- layers # loss定义
|-- logs # 训练好的权重将存储在这
|-- modeling # 定义的网络
|-- output # 输出
|-- person_search # 人员查找
|-- readme.md # readme
|-- solver # 优化器相关代码
|-- tests
|-- tools # 训练和测试代码
|-- utils # logger等相关代码
`-- weights # 存放预权重
数据集加载:
数据集加载与处理,需要调用头文件:
from data import make_data_loadermake_data_loader
传入参数为cfg,训练中的相关配置文件。
build_transforms函数
这个函数传入函数有两个,cfg是配置文件,is_train=True表示训练。normalize_transform是计算数据集的均值和方差。均值为[0.485, 0.456, 0.406],方差为[0.229, 0.224, 0.225](可以看配置文件)。
如果is_train=True的时候,对数据集进行处理。
T.Resize:将图像调整为[256,128]大小;
T.RandomHorizontalFlip(p=cfg.INPUT.PROB):随机水平翻转,设置为0.5;
T.Pad:padding值,10;
T.ToTensor():转为tensor;
normalize_transform:图像的均值和方差;
RandomErasing:数据增强(随机擦除),将图片内的某块区域填充相同的像素值,从而将该区域的图片信息遮盖,强迫模型学习该区域外的特征进行识别,在一定程度上避免模型陷入局部最优,从而提高模型的泛化能力。
将多个变换组合在一起。
如果测试的时候,is_train=False,不用数据增强。
def build_transforms(cfg, is_train=True):
normalize_transform = T.Normalize(mean=cfg.INPUT.PIXEL_MEAN, std=cfg.INPUT.PIXEL_STD)
if is_train:
transform = T.Compose([
T.Resize(cfg.INPUT.SIZE_TRAIN),
T.RandomHorizontalFlip(p=cfg.INPUT.PROB),
T.Pad(cfg.INPUT.PADDING),
T.RandomCrop(cfg.INPUT.SIZE_TRAIN),
T.ToTensor(),
normalize_transform,
RandomErasing(probability=cfg.INPUT.RE_PROB, mean=cfg.INPUT.PIXEL_MEAN)
])
else:
transform = T.Compose([
T.Resize(cfg.INPUT.SIZE_TEST),
T.ToTensor(),
normalize_transform
])
return transform继续返回make_data_loader函数。
通过build_transforms仅仅返回的是训练和测试需要用的一些数据处理方面的"规则"。
train_transforms = build_transforms(cfg, is_train=True)
val_transforms = build_transforms(cfg, is_train=False)num_workers:获取进程数量,我这里是4.
num_workers = cfg.DATALOADER.NUM_WORKERSinit_dataset函数
传入参数name:数据集的名称,我这里是mark1501;
还传入了数据集的路径:我这里是./data
该函数主要是判断支持的数据集格式。
def init_dataset(name, *args, **kwargs):
if name not in __factory.keys():
raise KeyError("Unknown datasets: {}".format(name))
return __factory[name](*args, **kwargs)继续看make_data_loader函数。
训练时分类的数量,这里是751。注意!在训练的时候是751,在测试的是1501.
num_classes = dataset.num_train_pidsImageDataset函数
该类基础Dataset,因此说明该类是做数据集处理的。上面我们说到的build_transforms仅仅是一些数据集处理的"规则"。
在调用该类的时候,传入两个参数,一个是dataset.train[训练数据集的图片路径],另一个就是train_transforms[处理的规则]。所以这个类就知道了,是用上面定义的“规则”来处理我们的数据集。
在下面这段代码中self.dataset[index]就是对数据集遍历(__getitem__就是迭代器),加入此时index=0,此时获得为:('./data\\Market1501\\bounding_box_train\\0002_c1s1_000451_03.jpg', 0, 0)。img_path就为数据集的路径,pid为类,camid为相机id[这个需要了解markt1501数据集]。
read_image函数就是通过PIL读取的图像。然后用transform处理。返回值有四个,img[数据增强后的图像],pid[类别],camid[相机id],img_path[图像路径]。
class ImageDataset(Dataset):
"""Image Person ReID Dataset"""
def __init__(self, dataset, transform=None):
self.dataset = dataset
self.transform = transform
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
img_path, pid, camid = self.dataset[index]
img = read_image(img_path)
if self.transform is not None:
img = self.transform(img)
return img, pid, camid, img_path下面的两个图就是增强后的效果


接下来再回到make_data_loader函数。
下面一段代码是对处理后的数据集进行加载,这里调用的torch中DataLoader函数。传入的参数有batch,我这里是8,shuffle表示打乱,collate_fn这个很重要,就是把这些按batch处理。
if cfg.DATALOADER.SAMPLER == 'softmax':
train_loader = DataLoader(
train_set, batch_size=cfg.SOLVER.IMS_PER_BATCH, shuffle=True, num_workers=num_workers,
collate_fn=train_collate_fn
)
else:
train_loader = DataLoader(
train_set, batch_size=cfg.SOLVER.IMS_PER_BATCH,
sampler=RandomIdentitySampler(dataset.train, cfg.SOLVER.IMS_PER_BATCH, cfg.DATALOADER.NUM_INSTANCE),
num_workers=num_workers, collate_fn=train_collate_fn
)同理,验证集也是这样处理。
最终返回训练集,验证集,数据集长度(数量),类别:751
完整代码
def make_data_loader(cfg):
train_transforms = build_transforms(cfg, is_train=True)
val_transforms = build_transforms(cfg, is_train=False)
num_workers = cfg.DATALOADER.NUM_WORKERS
if len(cfg.DATASETS.NAMES) == 1:
dataset = init_dataset(cfg.DATASETS.NAMES, root=cfg.DATASETS.ROOT_DIR)
else:
# TODO: add multi dataset to train
dataset = init_dataset(cfg.DATASETS.NAMES, root=cfg.DATASETS.ROOT_DIR)
num_classes = dataset.num_train_pids
train_set = ImageDataset(dataset.train, train_transforms)
if cfg.DATALOADER.SAMPLER == 'softmax':
train_loader = DataLoader(
train_set, batch_size=cfg.SOLVER.IMS_PER_BATCH, shuffle=True, num_workers=num_workers,
collate_fn=train_collate_fn
)
else:
train_loader = DataLoader(
train_set, batch_size=cfg.SOLVER.IMS_PER_BATCH,
sampler=RandomIdentitySampler(dataset.train, cfg.SOLVER.IMS_PER_BATCH, cfg.DATALOADER.NUM_INSTANCE),
num_workers=num_workers, collate_fn=train_collate_fn
)
val_set = ImageDataset(dataset.query + dataset.gallery, val_transforms)
val_loader = DataLoader(
val_set, batch_size=cfg.TEST.IMS_PER_BATCH, shuffle=False, num_workers=num_workers,
collate_fn=val_collate_fn
)
return train_loader, val_loader, len(dataset.query), num_classes