目录
模糊查询
排序
单行函数
多行函数
分组函数
having
单表查询执行顺序总结
distinct
连接查询
子查询
union
limit
DQL语句执行顺序
DDL语句
日期化
date和date_format区别
update
table 的快速创建以及删除(及回滚)
约束
事务
索引和视图
数据库三大范式
JDBC
模糊查询
/**like就称为模糊查询
* :
* '_A%' 找出第二个字母是A的 ;
* A% ——第一个字母是A;
* %A——最后一个字母是A;
* %A%——整个单词中含有A;
* select name from ename where name like '_A%';
* 第三个字母类似,将_增多就可以了
* 但是如果要找到单词中间含有_的,要记得转义 select name from student where name like '%\_%';
*
* */排序
* 1.select salary from emp order by sal (asc);默认是升序
* 2.select salary from emp order by sal desc;降序
* 3.要求:按照员工工资升序排序,如果工资一样,则按照名字进行升序排序
* select name,salary from emp order by salary asc,name asc;
* 4.根据字段的位置也可以进行排序:
* select name,sal from emp order by 2;
* 5.salary在某某之间
* select(3)...from(1)... where(2)...order by(4)...
单行函数
**单行处理函数:
* select sum(salary) from emp;
* select lower(name) as name from student;
*
*找出第一个字母是A的学生
* 1.模糊查询 select name from student where name like 'A%';
* 2.substr函数:select name from student where substr(name,1,1)='A';
*
* 3.首字母大写:
* select upper(substr(name,1,1)) from student;
* select substr(name,2,length(name)-1) from student;
* select concat(,) as sum from student;
* 4.round 四舍五入 round(123.33,1)保留一位小数。-1的话保留到十位
* 5.当你使用select 'abc' from student,这样会把你原有表中所有的行的值都改为abc;
* 6.100以内的随机数:round(rand()*100,0)
* 7.ifnull(,0)
* 8.不修改原始数据,将对应职位工资的查询结果上调
* select name, job, sal as oldsal (case job when 'manager' then sal*1.1 when 'teacher' then sal*1.4 else sal end) as newsal from emp;
* case when then when then else end;
*
多行函数
**多行函数
* count,sum,avg,max,min
*1. 分组函数必须先分组,
*2. 分组函数自动忽略null,我们不需要处理null
*3. count(*)统计的是总行数,一行中只要有一列不为null,那这一行就是有效的
* count(某个字段)统计的该字段中是不为空的元素的总数
* 4.分组函数不能直接使用在where子句中,eg:select name sal from emp where sal>min(sal);实际上这个子句是错的
*
*
分组函数
**分组查询/多行处理:group by
*select4 from1 where2 ...group by3... order by5
*
* group by不写默认分为一组,他其实是存在的
* 根据第二行的那个顺序,可以解释select name sal from emp where sal>min(sal);
报错的原因,where执行的时候,还没有进行分组,
* select sum(sal) from emp;可以的是因为,先进行分组再select,group by默认存在;
*
*
* 找出 每个工作 对应的 工资平均值
* select job,avg(average) from emp group by job;
* 如果存在group by 语句的话,select后面只能跟参加分组的字段,以及分组函数
* having
**使用having对分完组的值进一步过滤, 这里已经使用了group by,就不能使用where了
*! having不能单独使用,必须与group by联合使用,having不能代替where
*
* 找出每个部门最高薪资,要求显示最高薪资大于3000的;
*
* 1.1找出每个部门的最高薪资,按照部门编号分组,求每一组的最大值
* select deptno,max(sal) from emp group by deptno;
* 1.2.要求显示最高薪资大于3000
* select deptno,max(sal) from emp group by deptno having max(sal)>3000;
*
*2.1先将大于3000的全部找出来,再进行分组
* select deptno,max(sal) from emp where sal>3000group by deptno;
*
* where,having优先where,where后面不能使用分组函数sum,avg等
* **
单表查询执行顺序总结
* select...from...where...group by...having...order by...
* 执行顺序:
* 1.from;
* 2.where;
* 3.group by;
* 4.having;
* 5.select;
* 6.order by;**找出每个岗位的平均薪资,要求显示平均薪资大于1500的,除manager外,要求按照平均薪资降序排列 *select job avg(sal) as avgsal from emp where job <> 'manager' group by job having avg(sal)>1500 order by sal desc;
distinct
***distinct关键字:
*把查询结果去除重复记录,原表数据不会被修改
*eg: select distinct job from emp;
* 部门和职位进行联合去重:select distinct job,deptno from emp;
* distinct只能出现在所有字段最前方
* select count(distinct job) from emp;
连接查询
*根据表的连接方式分为
* 1.内连接:完全能够匹配上某个条件的数据查询出来,并且没有主次关系
* 1.1等值连接;
* SQL92语法:select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno;
* SQL99语法:select e.ename,d.dname from emp e (inner)join dept d on e.deptno=d.deptno;
* SQL99优点:表的连接是独立的,连接之后,如果还需要进一步筛选,后面直接添加where
* 1.2非等值来凝结;
* 1.3自连接;
*
* 2.外连接:join前面有个outer,可省略
* 2.1左连接;
* 2.2右连接:join前面加right,表示将join关键字右边的这张表看作主表,主要讲这张表中的数据全部查询出来,捎带关联查询左边的表
* select e.ename,d.dname from emp e right join dept d on e.deptno=d.deptno;
* join左边是left说明left是主表,左边是right说明右边是的表是主表
*
* 外连接的查询结果条数一定是>=内连接的查询条数的/***笛卡尔积 *select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno; *但是最终的查询结果表并没有将emp改成e, * **/*
子查询
//子查询
/***where里的子查询:
* eg: 找出比最低工资高的员工姓名和工资
*1.查询最低工资是多少。
* select min(sal) from emp;最后找出来是800
*2. 找出员工姓名和工资
* select name , sal from emp where sal > 800;
*
* 整合,先进行子查询
* select name , sal from emp where sal > (select min(sal) from emp);
***/
/**from里的子查询:
*注意: from 后面的子查询,可以将子查询的查询结果当作一张临时表;(技巧)
* eg:找出每个岗位的平均工资的薪资等级
* 1.找出每个岗位的平均值
* select job,avg(sal) from emp group by job;
* 2.把上述操作得到的临时表当作一张真实存在的表t
* select *from salgrade; s表中有等级,等级对应的最低值和最高值
** select * t*,s.grade * from * (select job,avg(sal) as avgsal from emp group by job ) t * join * salgrade s * on * t.avgsal between s.lowsal and s.highsal; *
* 最终得到 job , avgsal , grade;
* **/
union
/**union合并查询结果集
* 查询工作岗位是manager和salesman的员工
* 1.select name,job from emp where job='manager' or job='salesman';
* 2.select name,job from emp where job in manager or job in salesman;
* 3.select name,job from emp where job in ('manager','salesman');
* 4.select name,job from emp where job in manager union select name,job from emp where jon in salesman;
* union效率更高,可以减少匹配的次数,在减少匹配次数的情况下,完成两个结果集的拼接
* union在进行结果集合并时,要求两个结果集的列数相同
* ***/limit
*limit:
* 是将查询结果集的一部分取出来,通常使用在分页查询中
* 完整用法: limit startIndex,length,起始下标从0开始!
* 缺省用法: limit 5,这里是取前五
* 注意:mysql中limit在order by 之后执行!!!!!
* 例如,网络上搜索结果的分页
* eg1.按照薪资降序排列,取出排名前五的员工:
* select ename,sal from emp order by sal desc limit 5;
* eg2.取出工资排名在【3-5】的人:
* select name,sal from emp order by sal desc limit 2,3;
*
* 分页:
* 每页显示3条记录(pageSize)
* 第一页:limit 0,3 [0 1 2]
* 第二页:limit 3,3 [3,4,5]
* 第三页:limit 6,3 [6,7,8]
* 第n 页:limit (n-1)*pageSize,pageSize
*
DQL语句执行顺序
关于DQL语句的总结:
* select...
* from...
* where...
* group by...
* having...
* order by...
* limit...
* 执行顺序:
* 1.from
* 2.where
* 3.group by
* 4.having
* 5.select
* 6.order by
* 7.limit
* DDL语句
*DDL:建表就属于DDL语句,create,drop,alter
*create table student(int id,name varchar(20));
*varchar255 可变长度的字符串,节省空间,会根据实际的数据长度动态分配空间
*优点:节省空间
*缺点:需要动态分配内存区,速度慢
*char255 优点:不需要动态分配内存,速度快;缺点:使用不当会导致空间的浪费
* int11
* datatime、clob(字符大对象)
* blob(二进制1大对象,专门用来存储图片,声音,视频等流媒体数据,需要使用IO流)
*insert into student(name) values('zhangsan');//字段不写的话默认值是null
*default指定默认值*删除数据delete * delete from 表名 where 条件 *没有条件整张表中全部内容都会被删除
日期化
insert 插入日期
* 1.数字化格式: format
* 2.字符串转换成日期类型(通常使用在insert语句):str_to_date('字符串日期','日期格式') eg:str_to_date('01-10-1990','%d-%m-%Y')
* 如果你提供的日期格式是%Y-%m-%d,就不用写这个函数了,mysql会自动进行类型转换
* mysql的日期格式:%Y年,%m月,%d日,%h时,%i分,%s秒
* 查询1981-02-20入职的员工
* select* from emp where hiredate='1981-02-20';
*
*date_format(日期类型数据,‘日期格式’)
* 将日期类型转换成特定格式字符串,通常使用在查询日期时
* select id,name,date_format(birth,'%m/%d/%Y') as birth from student;
*
* select id,name,birth from student;
* 以上的SQL语句实际上是进行了默认的日期格式化,自动将数据库中的date类型转换成varchar类型,并且采用的时mysql默认的日期格式
*
* Java中的日期格式:yyyy-MM--dd HH:mm:ss SSS
*
date和date_format区别
*date和datetime 区别:
* date是短日期:只包括年月日信息;
* datetime是长日期:包括年月日时分秒信息
* drop table if exists t_user;
* create table t_user(birth date,create_time datetime)
* }
*
*mysql中短日期格式:%Y-%m-%d;
*mysql中长日期格式:%Y-%m-%d %h:%i:%s
*now()用于获取当前时间
* insert into t_user(date,create_time) values('1990-10-10',now());
* insert into t_user(date,create_time) values('1990-10-10','1990-10-10 11:11:22');
*
update
*update 表名 set 字段1=值1,字段二=值2where 条件;
* 注意:没有条件限制会导致所有数据全部更新
* update t_user set name='jack',birth='2000-10-11' where id=2;table 的快速创建以及删除(及回滚)
创建表----将一个查询结果当成一张表新建,这个可以完成表的快速复制 * create table emp2 as select* from emp; * 复制表中某几列的值 * create table mytable as select empno,ename from emp where job='manager'; * 将查询结果插到一张表中? * ** // ***快速删除表中的数据 * delete from student1; * 表中的数据被删除了,但是这歌数据在硬盘上的真实存储空间不会被释放 * 缺点:删除效率低; * 优点:支持回滚,后悔了再恢复数据 *回滚演示: *start transaction; * delete from student; * rollback; * select* from student; * * truncate:物理删除!!!删除表中的数据,表还在 * * drop table student;直接删除表的结构 /**对表的结构进行增删改 *alter * DDL:create drop alter * **/
约束
约束:constraint保证表中的数据有效 * 非空约束;not null * 唯一性约束;unique * 主键约束;primary key * 外键约束;foreign key * 检查约束:check(mysql不支持)
/**联合唯一:
* eg: 名字一样,身份证号不一样那麽就不是一个人
* create table person(id int,name varchar(255),unique(name,id));
*上述称为表级约束
*
*平时咋用就是 id int unique;这种称为列级约束
*not null只有列级约束
***PK主键
* unique和not null可以联合使用吗,必然可以
*
*drop table if exists t_vip;
*create table t_vip(id int,name varchar(255) not null unique);
*主键值是每一行记录的身份证号;
*主键字段:该字段上添加了主键约束
*任何一张表没有主键,无效
* create table student(id int primary key);
* primary key(id)表级约束
* 注意:主键只能有一个,可以是表级约束也可以是列级约束
* 主键值可以自增方式生成 id int primary key auto_increment;
* **外键
* drop table if exists student;
* drop table if exists class;
* create table class(classno int primary key,classname varchar(20));
* create table student (
* no int primary key auto_increment,
* name varchar(255);
* cno int,
* foreign key(cno) references class(classno);
* )
*所以student中的班级编号cno就只能来自于class中的classno编号
*
事务
*事务:是一个完整的业务逻辑,只有insert delete ypdate 以上三个语句与事务有关;一个事务是一个完整的业务逻辑,是一个最小的工作单元
* 一个事务其实就是多条DML语句同时成功,或者同时失败;
* 事务的特性:ACID
* A原子性:说明事务是最小的工作单元,不可再分;
* C一致性:要求事务要求,在同一个事务当中,所有操作必须同时成功,或者同时失败,保证数据的一致性
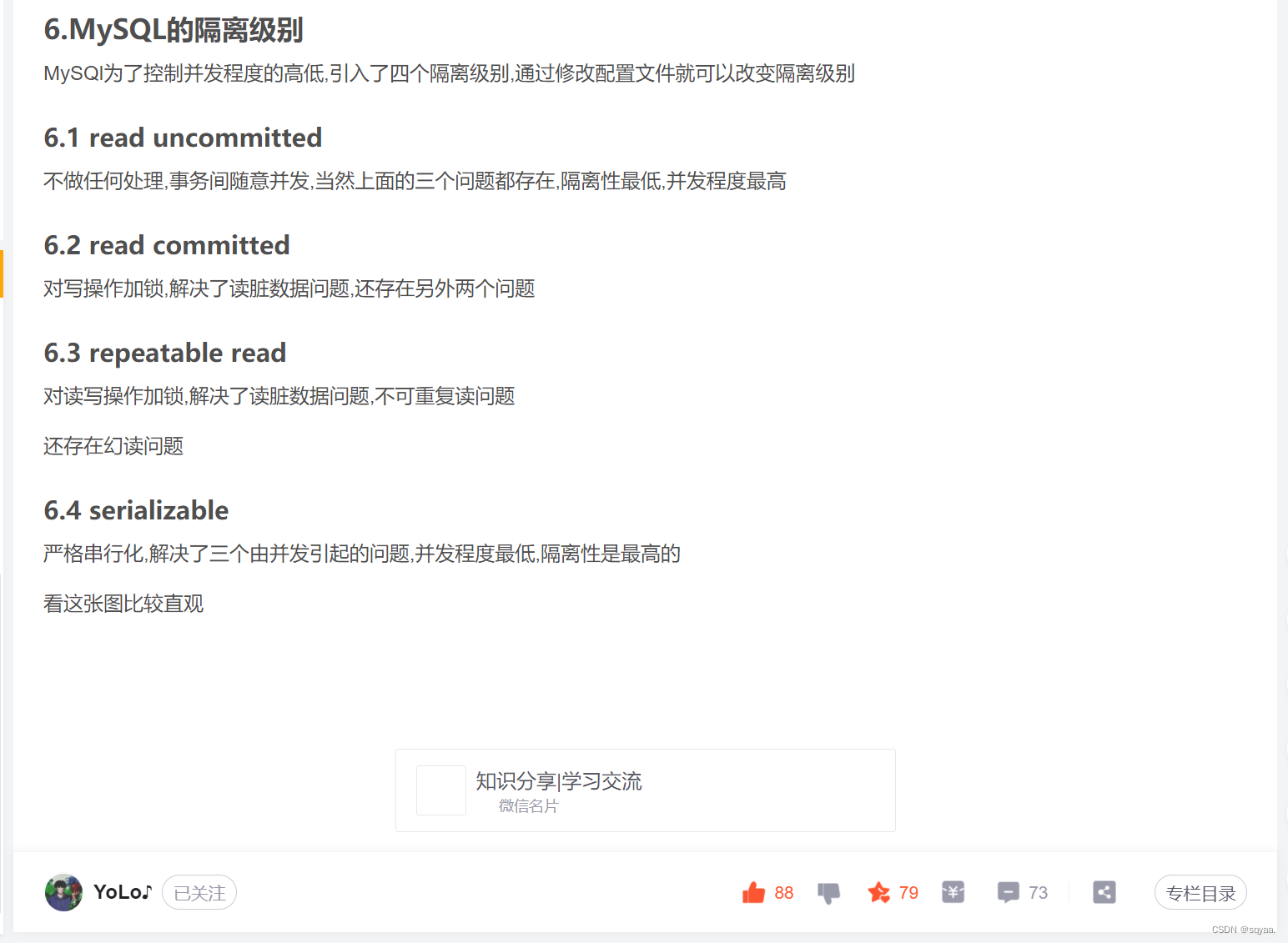
* I隔离性:相当于多线程并发访问同一张表。一个数据库服务器同时执行多个事务的 时 候,事务之间的互相影响程度。隔离性越高,事务之间的并发程度越低,执行效率越低,但数据准确率高,eg:银行转账;隔离性越低,事务之间并发程度越高,执行效率越快,数据准确率低,像点赞数;
* D持久性:事务提交,就相当于将没有保存在硬盘上的数据保存在硬盘上;接下来就算数据库发生故障,也对其没有影响。
*
*事务是如何做到多条DML语句同时成功和同时失败的?
*
*1.在事务执行过程中,每一条DML操作都会被记录到事务性活动的日志文件中,在事务执行过程中,我们可以提交事务,也可以回滚事务;
* 提交事务?
* 清空事务性活动的日志文件,将那个数据全部彻底持久化到数据库表中。
* 提交事务标志着,事物的结束,并且是一种全部成功的结束;
* 回滚事务?(回滚永远只能回滚到上一次的提交点)
* 将之前所有的DML操作全部撤销,并且清空事务性活动的日志文件。
* 回滚事务标志着事务的结束,并且是一种全部失败的结束;
*2.怎末提交事务,怎末回滚事务?
* 提交事务:commit;
* 回滚事务:rollback;
* 事务:transaction;
* mysql中默认的事务行为是自动提交的,每执行一条就提交
*自动提交并不符合我们的开发习惯
* 3.怎末将mysql的自动提交机制关闭掉呢?
* 先:start transaction;

索引和视图
/**索引:(底层B树)索引是用来优化的 *创建:create index name_index on emp(name);(emp表中的name字段添加索引:) *删除:drop index name_index on emp; *在mysql中怎末查看一个SQL语句是否使用了索引进行检索? * explain select* from emp where name='KIng'; * 索引的失效: * 1.select* from emp where name like '%T'; * 原因是因为模糊匹配中以“%”开头了! * 2.使用or的时候会失效,如果or,要求or两边的字段都要有索引,才会走索引 * 3.使用复合索引,没有使用左侧的列查找,索引失效. * 神魔是复合索引?两个字段或者更多的字段联合起来添加一个索引,叫做复合索引 * create index emp_job_sal_index on emp(job,sal); * explain select* from emp where job='manager';可以 * explain select* from emp where sal=800;不可以 * 4.索引中添加了运算 * 索引的分类: * 单一索引:一个字段上添加索引。 * 复合索引:两个字段或者更多的字段上添加索引 * 主键索引:竹简上添加索引。 * 唯一性索引:具有unique约束的字段上添加索引 * 注意:唯一性比较弱的字段上添加索引用处不大 * * **/ /**视图: * 创建:create view student_view as select* from student; * 删除: drop view student_view; * 作用:面向视图对象进行增删改查,并且这会导致原表被操作!会影响原表数据 * 视图在实际开发中用于简化 * create voiew emp_dept_view as select emp e join dept d on e.deptno=d.deptno; * 可以对试图进行增删查改CRUD,视图不是在内存中,视图对象也是存储在硬盘上的,不会消失 * * ***/
数据库三大范式
/**数据库设计范示: * 1.任何一张表都需要有主键,每一个字段原子性不可再分; * 2.建立第一范示基础上,所有非主键字段完全依赖主键,不要产生部份依赖; * 3.建立在第二范式基础上,要求所有非主键字段直接依赖主键,不要产生传递依赖; * * ------------------------------ * 学生编号 教师编号 学生姓名 教师姓名 * 1001 001 张三 王 * 1002 002 李四 赵 * 1003 001 王五 王 * 1001 002 张三 赵 * ------------------------------- * eg * :1.如何满足第一范式 * 学生编号和教师编号两个字段联合做逐渐,复合主键 * * 但是此时还产生了部分依赖(一个学生可以有多个老师,一个老师也可以有多个学生,出现多对多) * 部分依赖造成数据冗余,空间浪费 * 2.为了满足第二范式,设计三张表来表示多对多的关系: * * 多对多如何设计??? * * 多对多,三张表,关系表两个外键!!! *学生表: * 学生编号(pk) 学生姓名 * ----------------------- * 1001 张三 * 1002 李四 * 1003 王五 *------------------------- * *教师表: * 教师编号(pk) 教师姓名 * ------------------------ * 001 王 * 002 赵 *-------------------------- * * 学生教师关系表 * id(pk) 学生编号(fk) 教师编号(fk) * --------------------------------------------- * 1 1001 001 * 2 1002 002 * 3 1003 001 * 4 1001 002 *----------------------------------------------- * * 多对多如何设计??? * 多对多,三张表,关系表两个外键!!! * *3.第三范式:不要产生传递依赖 * 一对多,两张表,多的表加外键!!!! * eg:一个班级可以有多个学生, * 学生编号 学生姓名 班级编号 班级名称 * -------------------------------- * 1001 张三 01 一年1班 * 1002 李四 02 一年2班 * 1003 王五 03 一年3班 * 1004 赵六 03 一年3班 *---------------------------------- * * [班级表]: 一 * 班级编号(pk) 班级编号 * ---------------------------------- * 01 一年1班 * 02 一年2班 * 03 一年3班 * ------------------------------------ * * [学生表]: 多 * 学生编号(pk) 学生姓名 班级编号(fk) * ------------------------------------ * 1001 张三 01 * 1002 李四 02 * 1003 王五 03 * 1004 赵六 03 * * **/
*sum:
* 一对一 ,外键唯一(表大的话拆分,有的是主键共享,但是一般是foreign key + unique);
* 多对多,三张表,关系表两个外键;
* 一对多,两张表,多的表加外键;
*
/**取得每个部门最高薪水的人员名称
* 1.找出每个部门的最高薪水
* select deptno,max(sal) as maxsal from emp group by deptno;
* 2.将以上查询结果当作一张临时表t,t与emp连接,
* 条件:t.deptno=e.deptno and t.maxsal=e.sal
* select
* e.ename,t.*
* from
* emp e
* join
* (select deptno,max(sal) as maxsal from emp group by deptno) t
* on
* t.deptno=e.depyno and t.maxsal=e.sal;
*
* **/
/**不使用组函数max取得最高薪水
*1.降序
* select ename,sal from emp order by sal desc limit 1;
*2.表的自连接
*select distinct a.sal from emp a join emp b on a.sal<b.sal;(这些就除了最高值查不出来,其他都能查出来)
*用distinct进行去重
* 所以最后
* select sal from emp where sal not in(elect distinct a.sal from emp a join emp b on a.sal<b.sal);
*
* **/
/**取得平均薪水最高的部门的部门编号
*一. 降序取第一个
* 1.找每个部门平均薪水
* select deptno ,avg(sal) as avgsal from emp group by deptno;
* 2.降序选第一个
* select deptno,avg(sal) as avgsal from emp group by deptno order by avgsal desc limit 1;
*二.max
* 1.找平均薪水
* select deptno,avg(sal) as avgsal from emp group by deptno;
* 2.找以上结果
* select max(t.avgsal) from (select deptno,avg(sal) as avgsal from emp group by deptno)t;
*
* select deptno,avg(sal) as avgsal from emp group by deptno having avgsal=(select max(t.avgsal) from (select deptno ,avg(sal) as avgsal from emp group by deptno));
*
*/
/**取得薪水最高的前五名员工
*select ename,sal from emp order by sal desc limit 5;
* 6-10的员工
* select ename,sal from emp order by sal desc limit 5,5;
*
* */
/**取得每个薪水等级有多少个员工?
* 1. 找出每个
*
*
* **/
/**列出所有员工和领导的名字:
* select a.ename '员工' ,b.ename '领导' from emp a left join emp b on a.mgr=b.empno;
* 列出至少有5个员工的所有部门编号:
* select deptno from emp group by deptno having count(*)>=5;
*
* 下面这个比较简单;
* 列出薪资比smith多的员工:
* select sal from emp where name='smith';
* select ename from emp where sal> (select sal from emp where name='smith');
*
*最低工资大于1500的工作以及从事此工作的全部雇员人数。
* select job ,count(*) from emp group by job having min(sal)>1500;
*
*
*
* **/
JDBC
insert等
import com.mysql.jdbc.jdbc2.optional.MysqlDataSource;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Scanner;
/**
* Created with IntelliJ IDEA.
* Description:
* User: 86180
* Date: 2023-04-19
* Time: 22:54
*/
/**
* URL
* 唯一资源定位符,描述网络上某个资源所在位置
* mysql是一个客户端服务器的程序,客户端与服务器之间通过网络来通信,
* 网络上确定主机的位置就是通过ip地址来确定的;
* **/
/**
* ssl是加密协议
* */
/***
* jdbc使用DataSource这样的方式进行编写
* 还有一种DriverManager,通过反射的方式加载驱动里的包,进一步进行后续操作的
* 反射伤敌1000,自损800
* 1.反射的可读性较差, 编译器难以对代码的正确性进行检查,容易产生运行时异常
* 2.dataSource内置数据库连接池,可以复用链接,提高服务器效率
* (池:对资源进行预申请)
* **/
public class IDBCinsert {
public static void main(String[] args) {
//1.创建并且初始化一个数据源
//2.和数据库连接器进行连接
//3.构造sql语句
//
}
public static void main1(String[] args) throws SQLException {
Scanner scan=new Scanner(System.in);
//Idbc需要以下步骤来完成开发
//1.创建并且初始化一个 数据源(描述数据服务器在哪)
DataSource dataSource=new MysqlDataSource();//向上转型,父类引用指向子类对象;
((MysqlDataSource)dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/java0411?characterEncoding=utf8&useSSL=false");//这个方法子类有父类没有,向下转型
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("123456");
// MysqlDataSource dataSource1=new MysqlDataSource();
// dataSource1.setUrl();
// 与上述方法是等价的·仅仅是因为上述写法比较流行
//2.和数据库连接器进行连接
Connection connection=dataSource.getConnection();
//3.1从控制台读取内容
System.out.println("请输入学生姓名");
String name=scan.next();
System.out.println("请输入学生学号");
int id=scan.nextInt();
//3.构造一个sql语句
// String sql1="insert into student value(1,'qqq')";
// String sql2="insert into student value("+id+",'"+ name +"')";
String sql="insert into student value(?,?)";
PreparedStatement statement=connection.prepareStatement(sql);//预编译
statement.setInt(1,id);
statement.setString(2,name);
/***
* 如果请求是sql字符串,服务器是可以单独处理的,
* 服务器需要对sql进行解析,理解其中含义并且进行,如果有几万个客户端在发这个请求,压力超级答
* 让客户端对sql进行预编译,服务器做的工作就稍微简单,
* **/
//4.执行sql语句
int ret=statement.executeUpdate();
/**
* 把sql语句(预编译过的)发送给数据库服务器由服务器做出响应
* insert,delete,update操作都是使用executeUpdate()操作
* excuteUpdate()返回整数,表示你影响到的行数
*
* select() 使用的是executeQuery(),更复杂一点
*
* **/
System.out.println("ret="+ret);
//5.释放必要的资源
/**
* 客户端和服务器通过网络进行通信的时候,是需要消耗一定的系统资源的,
*包括不限于硬盘,内存,带宽。。。。服务器同时提供给很多客户端
*
* 一定先释放语句,后释放连接
* */
statement.close();
connection.close();
}
}select等
/**
* Created with IntelliJ IDEA.
* Description:
* User: 86180
* Date: 2023-04-21
* Time: 18:42
*/
import com.mysql.jdbc.jdbc2.optional.MysqlDataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
/**
* insert操作返回int;
* 查询操作返回ResultSet对象
*
* */
public class JDBCselect {
public static void main(String[] args) throws SQLException {
//1.创建并初始化数据源
MysqlDataSource dataSource=new MysqlDataSource();
((MysqlDataSource)dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/java0411?characterEncoding=utf8&useSSL=false");//这个方法子类有父类没有,向下转型
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("123456");
//2.建立链接
Connection connection= dataSource.getConnection();
//3.构造sql
String sql="select* from student";
PreparedStatement statement= connection.prepareStatement(sql);
//4.执行sql
ResultSet resultSet=statement.executeQuery();
//5.遍历结果集和
while(resultSet.next()){
int id=resultSet.getInt("id");
String name=resultSet.getString("name");
System.out.println("id="+id+",name="+name);
}
//6.释放资源
resultSet.close();
statement.close();
connection.close();
}
}这里详细步骤可参考http://t.csdn.cn/TdMtq