文章目录
- 一、PyTorch介绍
- 二、PyTorch的安装
- 1、CPU版本
- 2、GPU版本
- 三、Numpy与Tensor
- 1.Tensor的创建
- 2.Tensor的变形
- 相关推荐
一、PyTorch介绍
PyTorch是Facebook发布的一款深度学习框架,继承了Torch灵活、动态的编程环境和用户友好的界面,支持以快速和灵活的方式构建动态神经网络,还允许在训练的过程中快速更改代码而不妨碍其性能,支持动态图形等尖端AI模型的能力,是快速实验的理想选择。
主要由4个主要的包组成:
(1)torch:可将张量类型转换为torch.cuda.TensorFloat,并在GPU上进行计算。
(2)torch.autograd:用于构建计算图形并自动获取梯度的包
(3)torch.nn:具有共享层和损失函数的神经网络库
(4)torch.optim:具有通用优化算法(如SGD、Adam等)的优化包
二、PyTorch的安装
最好先安装一个anaconda或者miniconda,然后创建虚拟环境,再安装PyTorch
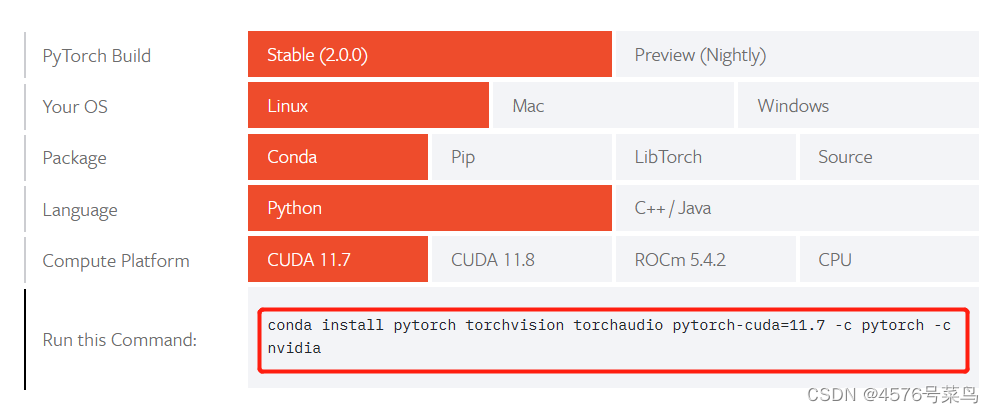
https://pytorch.org/get-started/locally/
1、CPU版本

2、GPU版本
GPU版本要先安装GPU驱动、CUDA、cuDNN计算框架。
可以参见:https://mp.csdn.net/mp_blog/creation/editor/120840528
再安装PyTorch:
三、Numpy与Tensor
PyTorch的Tensor可以是零维、也可以是一维、多维,它与Numpy相似,二者可以共享内存,转换方便高效。二者区别在于,Numpy只能在CPU上计算,而Tensor在GPU环境中可以选择在GPU上运行。
从接口上可以划分为两类:
(1)torch.function。如torch.sum、torch.add等
(2)tensor.function。如tensor.view、tensor.add等
但是这两者大都等价。如x.add(y)与torch.add(x,y)等价。
从是否修改自身数据也可以分成两类:
(1)不修改自身的数据:如x.add(y),运行结束后x值不变,返回一个新的tensor
(2)修改自身的数据:如x.add_(y),运行结果保存在x中,即x被修改。
import torch
x = torch.tensor([1,2])
y = torch.tensor([3,4])
z = x.add(y)
print(x)
>>>tensor([1, 2])
print(z)
>>>tensor([4, 6])
x.add_(y)
print(x)
>>>tensor([4, 6])
1.Tensor的创建
两点说明:
(1)torch.Tensor是torch.tensor和torch.empty的混合,但是,当传入数据时,torch.Tensor使用全局默认dtype(FloatTensor),而torch.tensor是从数据中推断数据类型。
(2)torch.tensor(1)返回的是固定值1,而torch.Tensor(1)返回的是大小为1的张量,值是随机的。
t1 = torch.Tensor(1)
print(t1)
>>>tensor([-1.0713])
t2 = torch.tensor(1)
print(t2)
>>>tensor(1)
(1)Tensor:直接从参数构造
print(torch.Tensor([1,2,3]))
>>>tensor([1., 2., 3.])
print(torch.Tensor([[1,2],[3,4]]))
>>>tensor([[1., 2.],
[3., 4.]])
(2)Tensor/eye:指定形状生成
# 指定形状,随机生成
print(torch.Tensor(2,3))
>>>tensor([[-3.5458e-16, -1.4412e+17, -3.5458e-16],
[ 4.2352e-22, -3.5457e-16, 5.6296e+14]])
print(torch.eye(2,3))
>>>tensor([[1., 0., 0.],
[0., 1., 0.]])
(3)linspace:给定范围均分
print(torch.linspace(1,10,10))
>>>tensor([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
(4)logspace:给定范围均分(区别于3,范围以10为底)
print(torch.logspace(1,2,10))
>>>tensor([ 10.0000, 12.9155, 16.6810, 21.5443, 27.8256, 35.9381, 46.4159,
59.9484, 77.4264, 100.0000])
(5)rand:指定形状,【0,1)均匀分布
print(torch.rand(2,3))
>>>tensor([[0.4956, 0.5236, 0.1909],
[0.5445, 0.1571, 0.3773]])
(6)randn:指定形状,标准正态分布
print(torch.randn(2,3))
>>>tensor([[-0.6656, -0.0725, 1.9198],
[ 0.6756, -1.8594, -0.8263]])
(7)ones:指定形状,初始值为1
print(torch.ones(2,3))
>>>tensor([[1., 1., 1.],
[1., 1., 1.]])
(8)zeros:指定形状,初始值为0
print(torch.zeros(2,3))
>>>tensor([[0., 0., 0.],
[0., 0., 0.]])
(9)ones_like:模仿形状,初始值为1
a = torch.Tensor(2,3)
print(torch.ones_like(a))
>>>tensor([[1., 1., 1.],
[1., 1., 1.]])
(10)zeros_like:模仿形状,初始值为0
a = torch.Tensor(2,3)
print(torch.zeros_like(a))
>>>tensor([[0., 0., 0.],
[0., 0., 0.]])
(11)arange:在指定区间,以指定间隔生成一个序列张量
print(torch.arange(1,10,1))
>>>print(torch.arange(1,10,1))
(12)from_Numpy:从ndarray创建一个Tensor
a = np.arange(1,10,1)
print(a)
>>>[1 2 3 4 5 6 7 8 9]
print(torch.from_numpy(a))
>>>tensor([1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=torch.int32)
2.Tensor的变形
(1)查看形状
a = torch.randn(2,3)
print(a.size())
>>>torch.Size([2, 3])
print(a.shape)
>>>torch.Size([2, 3])
# 返回a的维度
print(a.dim())
>>>2
(2)计算元素个数
a = torch.randn(2,3)
print(torch.numel(a))
>>>6
(3)修改形状
a = torch.randn(2,3)
print(a)
>>>tensor([[-0.0169, 0.3507, -0.8997],
[ 0.1978, -1.3577, 0.7491]])
print(a.view(3,2))
>>>tensor([[-0.0169, 0.3507],
[-0.8997, 0.1978],
[-1.3577, 0.7491]])
print(a) # 可见,view没有修改a自身
>>>tensor([[-0.0169, 0.3507, -0.8997],
[ 0.1978, -1.3577, 0.7491]])
print(a.resize(2,3))
>>>UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
tensor([[-0.0169, 0.3507, -0.8997],
[ 0.1978, -1.3577, 0.7491]])
print(a) # 可见,resize修改了a自身,官方也不建议这样修改。
>>>tensor([[-0.0169, 0.3507, -0.8997],
[ 0.1978, -1.3577, 0.7491]])
a = torch.randn(2,3)
print(a.reshape(3,2))
>>>tensor([[-2.1509, 1.9620],
[-0.3320, -1.8106],
[-2.1936, 0.1626]])
print(a)
>>>tensor([[-2.1509, 1.9620, -0.3320],
[-1.8106, -2.1936, 0.1626]])
# 增加维度
a = torch.randn(2,3)
print(a)
>>>tensor([[ 0.3440, -0.9412, 1.0980],
[-1.2131, 1.1445, 2.2529]])
z = torch.unsqueeze(a,0)
print(z)
>>>tensor([[[ 0.3440, -0.9412, 1.0980],
[-1.2131, 1.1445, 2.2529]]])
# 压缩维度
a = torch.randn(2,1,3,1)
print(a.size())
>>>torch.Size([2, 1, 3, 1])
z = torch.squeeze(a)
print(z.size()) # 将全部大小为1的维压缩
>>>torch.Size([2, 3])
z = torch.squeeze(a,3)
print(z.size())# 若指定维的大小为1则压缩该维,不为1不压缩
>>>torch.Size([2, 1, 3])
相关推荐
【pyTorch学习笔记①】Numpy基础·上篇
【pyTorch学习笔记②】Numpy基础·下篇



![[ICLR 2020] Reducing Transformer Depth on Demand with Structured Dropout](https://img-blog.csdnimg.cn/1acae1b46cb24108b2e3ae3f9a804baf.png#pic_center)