缓存笔记 来自 程序员囧辉
黑马博学谷 幂等问题
1 缓存一致问题
1.1.同步删除
核心流程:
- 更新数据库数据
- 删除缓存数据
问题:
- . 并发场景下存在脏数据 (
并发有脏数据问题) - . 难以收拢所有更新数据库入口 (
可能通过命令行、工具等删除db,那么redis 无法删除) - . 删除缓存失败存在脏数据

1.2. 延时双删
核心流程:
- 删除缓存数据
- 更新数据库数据
- 等待一小段时间
- 再次删除缓存数据
问题:
- 延时时间难以确认 (
延时时间无法确认) - 延时无法绝对保障数据的一致性 (
主从情况下主从的库)

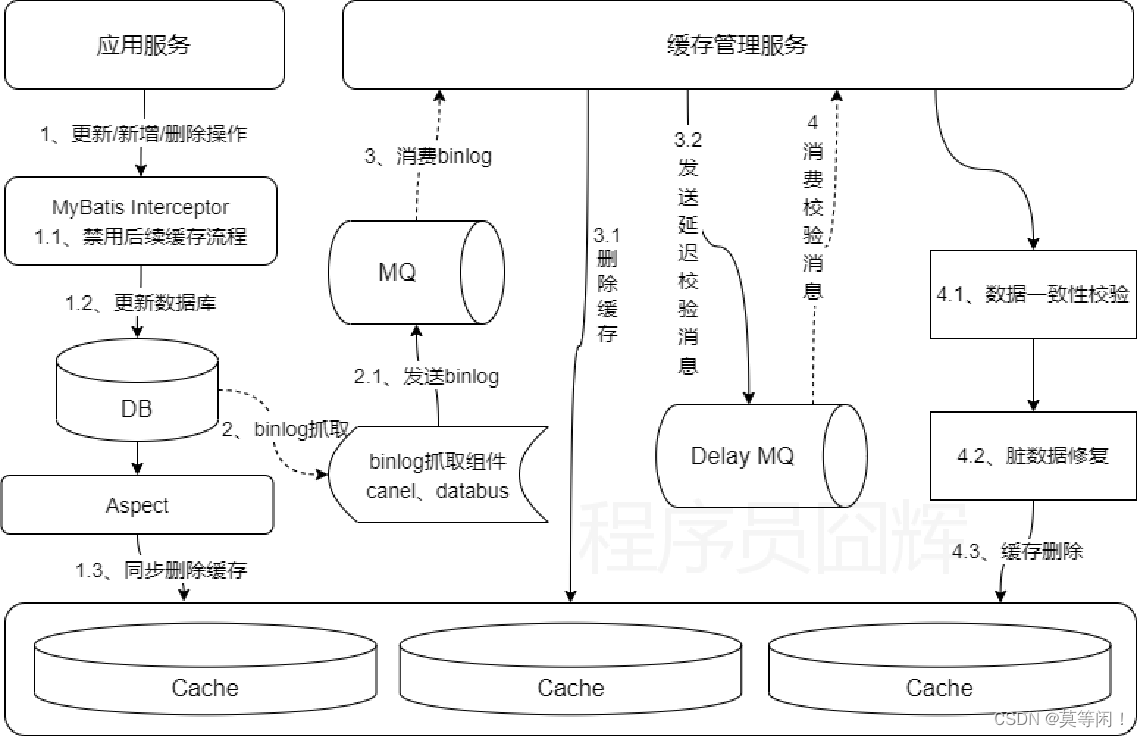
1.3:异步监听从库binlog删除 + 重试
核心流程:
- 更新数据库
- 监听binlog删除缓存
- 缓存删除失败则通过MQ不断重试,直至删除成功
存在问题:
- 缓存 脏数据时间窗口“较大” (
针对于同步删除来说的)- 更新完 db,产生binlog ,binlog发到从库,mq消费 删除缓存 都需要时间
- 在上面期间,缓存没删除,
那也是有脏数据。
- 极端场景下存在长期脏数据问题
- binlog抓取组件宕机
- 拆库拆表流程

1.3.1 推荐监听从库
这是一个权衡吧,你直接监听主库也是可以的,但是为什么我们不这么干了。
因为主从延迟通常情况下是很低的,基本在毫秒级別,几乎可以忽略不计。而监听主库会有什么问题了,如果我们的binlog中间件在功能迭代期间出现了bug,直接将主库搞挂或者影响到主库,那可能就直接影响到整个链路了,而如果影响的是从库,即使挂了可能也几乎没影响,因为我们一般会有预留容量,挂1台从库理论不会影响业务。
所以没有必要为了几毫秒的延迟去冒这个风险。
1.4. 最终保证
- 更新数据库后 同步删除缓存。(
减少异步删除不一致 时间窗口 太久的情况) 为了应对并发问题。引入监听binlog,异步删除。带有重试,一定要成功。- 缓存数据带过期时间。过期后删除。
- 主要用于进一步防止并发下的脏数据问题
- 解决一些由于未知情况,导致需要更换缓存结构的问题
- 监听数据库的binlog延迟N秒后进行数据一致性校验
- 解决一些极端场景下的脏数据问题
- 存在数据库更新的链路禁用对应缓存
比如更新完数据库后,马上又查询一次可能查询的数据还是脏数据。- 就是在更新请求链路中的查询请求都直接查db
- 防止并发下短期内的脏数据影响到更新流程
- 强制读Redis主节点
- 查询异步数据一致性校验、灰度放量
2.jvm 调优
- Serial GC:Full GC整个过程STW,Young GC整个过程STW
- Parallel GC:Full GC整个过程STW,Young GC整个过程STW
- CMS GC:Full GC整个过程STW,Young GC整个过程STW,Old GC只有两个小阶段STW
- G1 GC:Full GC整个过程STW,Young GC整个过程STW,Mixed GC由全局并发标记和对象复制组成,全局并发标记其中两个小阶段STW,其它并发
- Shenandoah GC/ZGC:它们都是回收堆的一部分,所以没有Full GC(Full GC是指回收整个堆,与之相对的是Partial GC,比如CMS GC的Old GC和G1的Mixed GC均属于此类)的概念
2.1 分区比例不合适问题
eden 比较小,导致:YGC次数变多。
eden 比较大,导致:扫描增多,YGC时间增加。
YGC STW的。影响接口请求时间。
survivor 偏小,导致:有些对象动态年龄规则,提前。直接晋升到老年代。
survior 偏大。导致浪费一些空间。
2.2 gc
软引用
当gc后,空间还是不够用,将软引用作为gcroot,在进行一次gc。GC cause last dist collection。
cms 内存碎片,标记清除。
碎片化严重,影响大对象分配,没有连续的空间
![[Golang] 设计模式以及单例设计模式实例实现](https://img-blog.csdnimg.cn/290cb82ff7834878aff2daa6c4a0bf4f.gif#pic_center)