SpringBoot开发实用篇
KF-1.热部署
什么是热部署?简单说就是你程序改了,现在要重新启动服务器,嫌麻烦?不用重启,服务器会自己悄悄的把更新后的程序给重新加载一遍,这就是热部署。
热部署的功能是如何实现的呢?这就要分两种情况来说了,非springboot工程和springboot工程的热部署实现方式完全不一样。先说一下原始的非springboot项目是如何实现热部署的。
非springboot项目热部署实现原理
开发非springboot项目时,我们要制作一个web工程并通过tomcat启动,通常需要先安装tomcat服务器到磁盘中,开发的程序配置发布到安装的tomcat服务器上。如果想实现热部署的效果,这种情况其实有两种做法,一种是在tomcat服务器的配置文件中进行配置,这种做法与你使用什么IDE工具无关,不管你使用eclipse还是idea都行。还有一种做法是通过IDE工具进行配置,比如在idea工具中进行设置,这种形式需要依赖IDE工具,每款IDE工具不同,对应的配置也不太一样。但是核心思想是一样的,就是使用服务器去监控其中加载的应用,发现产生了变化就重新加载一次。
上面所说的非springboot项目实现热部署看上去是一个非常简单的过程,几乎每个小伙伴都能自己写出来。如果你不会写,我给你个最简单的思路,但是实际设计要比这复杂一些。例如启动一个定时任务,任务启动时记录每个文件的大小,以后每5秒比对一下每个文件的大小是否有改变,或者是否有新文件。如果没有改变,放行,如果有改变,刷新当前记录的文件信息,然后重新启动服务器,这就可以实现热部署了。当然,这个过程肯定不能这么做,比如我把一个打印输出的字符串"abc"改成"cba",比对大小是没有变化的,但是内容缺实变了,所以这么做肯定不行,只是给大家打个比方,而且重启服务器这就是冷启动了,不能算热部署,领会精神吧。
看上去这个过程也没多复杂,在springboot项目中难道还有其他的弯弯绕吗?还真有。
springboot项目热部署实现原理
基于springboot开发的web工程其实有一个显著的特征,就是tomcat服务器内置了,还记得内嵌服务器吗?服务器是以一个对象的形式在spring容器中运行的。本来我们期望于tomcat服务器加载程序后由tomcat服务器盯着程序,你变化后我就重新启动重新加载,但是现在tomcat和我们的程序是平级的了,都是spring容器中的组件,这下就麻烦了,缺乏了一个直接的管理权,那该怎么做呢?简单,再搞一个程序X在spring容器中盯着你原始开发的程序A不就行了吗?确实,搞一个盯着程序A的程序X就行了,如果你自己开发的程序A变化了,那么程序X就命令tomcat容器重新加载程序A就OK了。并且这样做有一个好处,spring容器中东西不用全部重新加载一遍,只需要重新加载你开发的程序那一部分就可以了,这下效率又高了,挺好。
下面就说说,怎么搞出来这么一个程序X,肯定不是我们自己手写了,springboot早就做好了,搞一个坐标导入进去就行了。
KF-1-1.手动启动热部署
步骤①:导入开发者工具对应的坐标
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
步骤②:构建项目,可以使用快捷键激活此功能
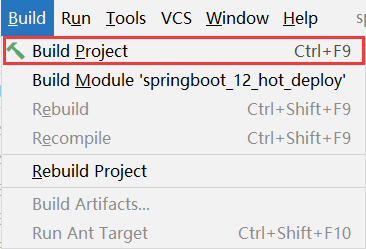
<CTR>L+<F9>
重启与重载
一个springboot项目在运行时实际上是分两个过程进行的,根据加载的东西不同,划分成base类加载器与restart类加载器。
- base类加载器:用来加载jar包中的类,jar包中的类和配置文件由于不会发生变化,因此不管加载多少次,加载的内容不会发生变化
- restart类加载器:用来加载开发者自己开发的类、配置文件、页面等信息,这一类文件受开发者影响
- 热部署只执行restart
KF-1-2.自动启动热部署
自动热部署其实就是设计一个开关,打开这个开关后,IDE工具就可以自动热部署。因此这个操作和IDE工具有关,以下以idea为例设置idea中启动热部署
步骤①:设置自动构建项目
打开【File】,选择【settings…】,在面板左侧的菜单中找到【Compile】选项,然后勾选【Build project automatically】,意思是自动构建项目
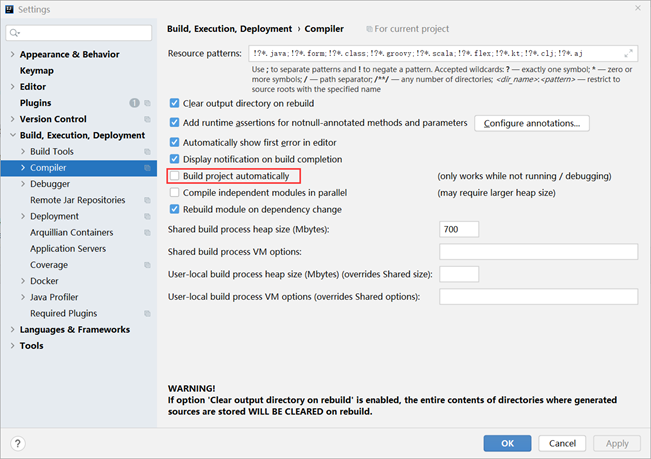
自动构建项目选项勾选后
步骤②:允许在程序运行时进行自动构建
使用快捷键【Ctrl】+【Alt】+【Shit】+【/】打开维护面板,选择第1项【Registry…】
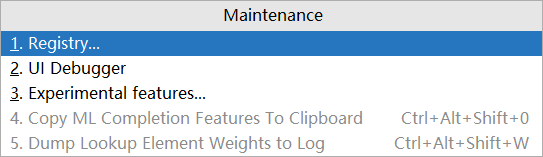
在选项中搜索comple,然后勾选对应项即可
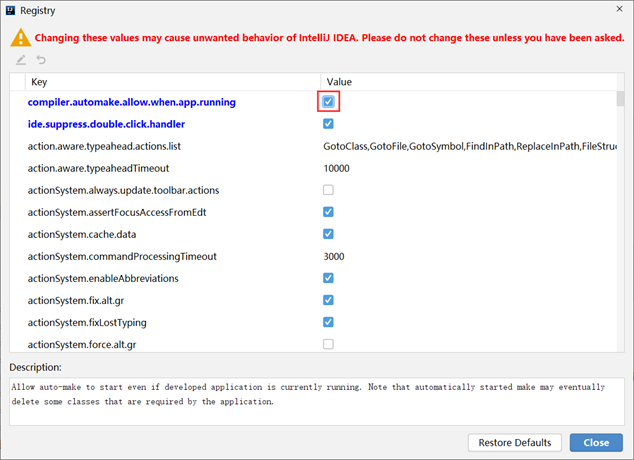
这样程序在运行的时候就可以进行自动构建了,实现了热部署的效果。
关注:如果你每敲一个字母,服务器就重新构建一次,这未免有点太频繁了,所以idea设置当idea工具失去焦点5秒后进行热部署。其实就是你从idea工具中切换到其他工具时进行热部署,比如改完程序需要到浏览器上去调试,这个时候idea就自动进行热部署操作。
KF-1-3.参与热部署监控的文件范围配置
- 设置不被热部署
通过修改项目中的文件,你可以发现其实并不是所有的文件修改都会激活热部署的,原因在于在开发者工具中有一组配置,当满足了配置中的条件后,才会启动热部署,配置中默认不参与热部署的目录信息如下
- /META-INF/maven
- /META-INF/resources
- /resources
- /static
- /public
- /templates
以上目录中的文件如果发生变化,是不参与热部署的。如果想修改配置,可以通过application.yml文件进行设定哪些文件不参与热部署操作
spring:
devtools:
restart:
# 设置不参与热部署的文件或文件夹
exclude: static/**,public/**,config/application.yml
总结
- 通过配置可以修改不参与热部署的文件或目录
思考
热部署功能是一个典型的开发阶段使用的功能,到了线上环境运行程序时,这个功能就没有意义了。能否关闭热部署功能呢?咱们下一节再说。
KF-1-4.关闭热部署
- 只在开发环境中有效,部署工程只有不能有效
通过配置可以关闭此功能。
spring:
devtools:
restart:
enabled: false
如果当心配置文件层级过多导致相符覆盖最终引起配置失效,可以提高配置的层级,在更高层级中配置关闭热部署。例如在启动容器前通过系统属性设置关闭热部署功能。
@SpringBootApplication
public class SSMPApplication {
public static void main(String[] args) {
System.setProperty("spring.devtools.restart.enabled","false");
SpringApplication.run(SSMPApplication.class);
}
}
其实上述担心略微有点多余,因为线上环境的维护是不可能出现修改代码的操作的,这么做唯一的作用是降低资源消耗,毕竟那双盯着你项目是不是产生变化的眼睛只要闭上了,就不具有热部署功能了,这个开关的作用就是禁用对应功能。
总结
- 通过配置可以关闭热部署功能降低线上程序的资源消耗
-
设置范围和关闭用到了devtools两个属性
spring: devtools: restart: enabled: false exclude: static/**,public/**,config/application.yml
KF-2.配置高级
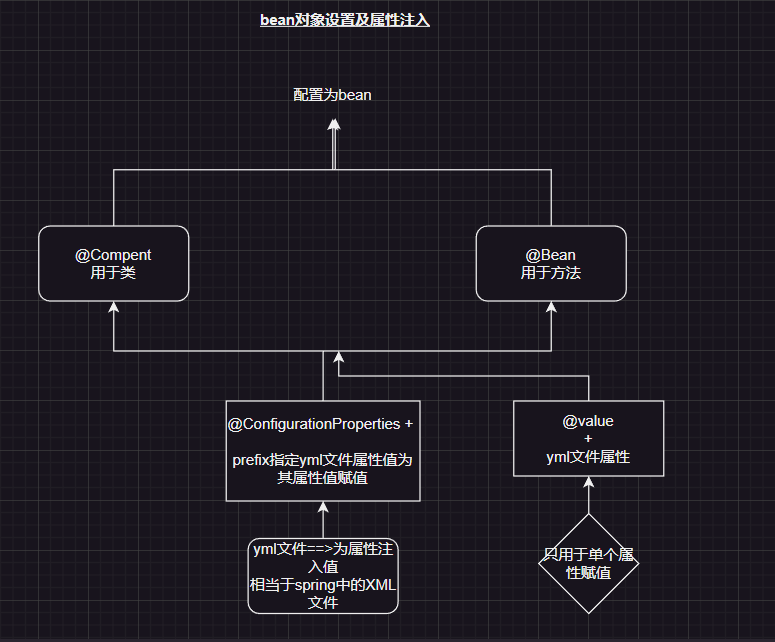
@Component是标注类,注册为bean;@Bean是标注方法返回的对象,将对象注册为bean
yml配置文件为具体的bean对象进行属性赋值
这里要搞明白一件事,凡是在pom.xml设置的依赖,如果没有整合springboot(就是没有导入特定的starter),那么这个jar包中的类就没有交给spring容器去管理,需要自己通过@Bean注解,将特定的类交给spring容器去管理;通过yml文件定义一个scope进行属性注入
KF-2-1.@ConfigurationProperties
在基础篇学习了@ConfigurationProperties注解,此注解的作用是用来为bean绑定属性的。开发者可以在yml配置文件中以对象的格式添加若干属性
servers:
ip-address: 192.168.0.1
port: 2345
timeout: -1
然后再开发一个用来封装数据的实体类,注意要提供属性对应的setter方法
@Component
@Data
public class ServerConfig {
private String ipAddress;
private int port;
private long timeout;
}
使用@ConfigurationProperties注解就可以将配置中的属性值关联到开发的模型类上
@Component
@Data
@ConfigurationProperties(prefix = "servers")
public class ServerConfig {
private String ipAddress;
private int port;
private long timeout;
}
这样加载对应bean的时候就可以直接加载配置属性值了。但是目前我们学的都是给自定义的bean使用这种形式加载属性值,如果是第三方的bean呢?能不能用这种形式加载属性值呢?为什么会提出这个疑问?原因就在于当前@ConfigurationProperties注解是写在类定义的上方,而第三方开发的bean源代码不是你自己书写的,你也不可能到源代码中去添加@ConfigurationProperties注解,这种问题该怎么解决呢?下面就来说说这个问题。
使用@ConfigurationProperties注解其实可以为第三方bean加载属性,格式特殊一点而已。
步骤①:使用@Bean注解定义第三方bean
@Bean
public DruidDataSource datasource(){
DruidDataSource ds = new DruidDataSource();
return ds;
}
步骤②:在yml中定义要绑定的属性,注意datasource此时全小写,第三方bean
datasource:
driverClassName: com.mysql.jdbc.Driver
步骤③:使用@ConfigurationProperties注解为第三方bean进行属性绑定,注意前缀是全小写的datasource
@Bean
@ConfigurationProperties(prefix = "datasource")
public DruidDataSource datasource(){
DruidDataSource ds = new DruidDataSource();
return ds;
}
操作方式完全一样,只不过@ConfigurationProperties注解不仅能添加到类上,还可以添加到方法上,添加到类上是为spring容器管理的当前类的对象绑定属性,添加到方法上是为spring容器管理的当前方法的返回值对象绑定属性,其实本质上都一样。
做到这其实就出现了一个新的问题,目前我们定义bean不是通过类注解定义就是通过@Bean定义,使用@ConfigurationProperties注解可以为bean进行属性绑定,那在一个业务系统中,哪些bean通过注解@ConfigurationProperties去绑定属性了呢?因为这个注解不仅可以写在类上,还可以写在方法上,所以找起来就比较麻烦了。为了解决这个问题,spring给我们提供了一个全新的注解,专门标注使用@ConfigurationProperties注解绑定属性的bean是哪些。这个注解叫做@EnableConfigurationProperties。具体如何使用呢?
步骤①:在配置类上开启@EnableConfigurationProperties注解,并标注要使用@ConfigurationProperties注解绑定属性的类
@SpringBootApplication
@EnableConfigurationProperties(ServerConfig.class)
public class Springboot13ConfigurationApplication {
}
步骤②:在对应的类上直接使用@ConfigurationProperties进行属性绑定
@Data
@ConfigurationProperties(prefix = "servers")
public class ServerConfig {
private String ipAddress;
private int port;
private long timeout;
}
使用**@EnableConfigurationProperties注解时,spring会默认将其标注的类定义为bean,因此无需再次声明@Component注解**了。

出现这个提示后只需要添加一个坐标此提醒就消失了
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</dependency>
总结
- 使用@ConfigurationProperties可以为使用@Bean声明的第三方bean绑定属性
- 当使用@EnableConfigurationProperties声明进行属性绑定的bean后,无需使用@Component注解再次进行bean声明
KF-2-2.宽松绑定/松散绑定(yml注入属性名与bean属性名匹配问题)
- 配置文件属性命名支持各种模式,推荐中划线模式
- ConfigurationProperties进行属性绑定时,prefix引用yml的scope时,只支持中划线模式
- @value注解只适用于单个类中属性的注入,并且不支持中划线模式,如只能使用@value(“servers.ipAddress”)且配置文件中必须用ipAddress
什么是宽松绑定?即配置文件中的命名格式与变量名的命名格式可以进行格式上的最大化兼容。兼容到什么程度呢?几乎主流的命名格式都支持,例如:
可以与下面的配置属性名规则全兼容
servers:
ipAddress: 192.168.0.2 # 驼峰模式
ip_address: 192.168.0.2 # 下划线模式
ip-address: 192.168.0.2 # 烤肉串模式
IP_ADDRESS: 192.168.0.2 # 常量模式
以上4种命名去掉下划线中划线忽略大小写后都是一个词ipaddress,java代码中的属性名忽略大小写后也是ipaddress,这样就可以进行等值匹配了。不过springboot官方推荐使用烤肉串模式,也就是中划线模式。
最后说一句,以上规则仅针对springboot中@ConfigurationProperties注解进行属性绑定时有效,对@Value注解进行属性映射无效。有人就说,那我不用你不就行了?
总结
- @ConfigurationProperties绑定属性时支持属性名宽松绑定,这个宽松体现在属性名的命名规则上
- @Value注解不支持松散绑定规则
- 绑定前缀名推荐采用烤肉串命名规则,即使用中划线做分隔符
KF-2-3.常用计量单位绑定
在前面的配置中,我们书写了如下配置值,其中第三项超时时间timeout描述了服务器操作超时时间,当前值是-1表示永不超时。
servers:
ip-address: 192.168.0.1
port: 2345
timeout -1
除了加强约定之外,springboot充分利用了JDK8中提供的全新的用来表示计量单位的新数据类型,从根本上解决这个问题。以下模型类中添加了两个JDK8中新增的类,分别是Duration和DataSize
@Component
@Data
@ConfigurationProperties(prefix = "servers")
public class ServerConfig {
@DurationUnit(ChronoUnit.HOURS)
private Duration serverTimeOut;
@DataSizeUnit(DataUnit.MEGABYTES)
private DataSize dataSize;
}
Duration:表示时间间隔,可以通过@DurationUnit注解描述时间单位,例如上例中描述的单位为小时(ChronoUnit.HOURS)
DataSize:表示存储空间,可以通过@DataSizeUnit注解描述存储空间单位,例如上例中描述的单位为MB(DataUnit.MEGABYTES)
使用上述两个单位就可以有效避免因沟通不同步或文档不健全导致的信息不对称问题,从根本上解决了问题,避免产生误读。
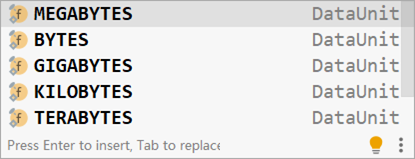
Druation常用单位如下:
DataSize常用单位如下:
KF-2-4.校验:校验配置注入属性文件与注入属性间的校验
SpringBoot给出了强大的数据校验功能,可以有效的避免此类问题的发生。在JAVAEE的JSR303规范中给出了具体的数据校验标准,开发者可以根据自己的需要选择对应的校验框架,此处使用Hibernate提供的校验框架来作为实现进行数据校验。书写应用格式非常固定,话不多说,直接上步骤
步骤①:开启校验框架
javax.validation ====> 相当于Java提供的一套接口 如jdbc
hibernate-validator ====> 相当于对接口的实现类 如数据库驱动
<!--1.导入JSR303规范-->
<dependency>
<groupId>javax.validation</groupId>
<artifactId>validation-api</artifactId>
</dependency>
<!--使用hibernate框架提供的校验器做实现-->
<dependency>
<groupId>org.hibernate.validator</groupId>
<artifactId>hibernate-validator</artifactId>
</dependency>
步骤②:在需要开启校验功能的类上使用注解@Validated开启校验功能
@Component
@Data
@ConfigurationProperties(prefix = "servers")
//开启对当前bean的属性注入校验
@Validated
public class ServerConfig {
}
步骤③:对具体的字段设置校验规则
先加@Validated 让spring识别到
在加Max,Min注解
@Component
@Data
@ConfigurationProperties(prefix = "servers")
//开启对当前bean的属性注入校验
@Validated =========================================> spring中标示的注解
public class ServerConfig {
//设置具体的规则
@Max(value = 8888,message = "最大值不能超过8888")===================> javax规范,hibernate实现
@Min(value = 202,message = "最小值不能低于202")
private int port;
}
通过设置数据格式校验,就可以有效避免非法数据加载,其实使用起来还是挺轻松的,基本上就是一个格式。
总结
- 开启Bean属性校验功能一共3步:导入JSR303与Hibernate校验框架坐标、使用@Validated注解启用校验功能、使用具体校验规则规范数据校验格式
KF-2-5.数据类型转换⭐️
有关spring属性注入的问题到这里基本上就讲完了,但是最近一名开发者向我咨询了一个问题,我觉得需要给各位学习者分享一下。在学习阶段其实我们遇到的问题往往复杂度比较低,单一性比较强,但是到了线上开发时,都是综合性的问题,而这个开发者遇到的问题就是由于bean的属性注入引发的灾难。
先把问题描述一下,这位开发者连接数据库正常操作,但是运行程序后显示的信息是密码错误。
java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: YES)
如果是初学者,估计这会心态就崩了,我密码没错啊,你怎么能说我有错误呢?来看看用户名密码的配置是如何写的:
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
username: root
password: 0127
之前在基础篇讲属性注入时,提到过类型相关的知识,在整数相关知识中有这么一句话,支持二进制,八进制,十六进制

这个问题就处在这里了,因为0127在开发者眼中是一个字符串“0127”,但是在springboot看来,这就是一个数字,而且是一个八进制的数字。当后台使用String类型接收数据时,如果配置文件中配置了一个整数值,他是先安装整数进行处理,读取后再转换成字符串。巧了,0127撞上了八进制的格式,所以最终以十进制数字87的结果存在了。
这里提两个注意点,第一,字符串标准书写加上引号包裹,养成习惯,第二,遇到0开头的数据多注意吧。
总结
- yaml文件中对于数字的定义支持进制书写格式,如需使用字符串请使用引号明确标注
- 对于数值型 0 开头表示八进制,0x开头表示16进制。字符串和数字相互转换,变量用数字去接,然后用注入到字符串里,先解析数字然后再注入
KF-3.测试
说完bean配置相关的内容,下面要对前面讲过的一个知识做加强了,测试。测试是保障程序正确性的唯一屏障,在企业级开发中更是不可缺少,但是由于测试代码往往不产生实际效益,所以一些小型公司并不是很关注,导致一些开发者从小型公司进入中大型公司后,往往这一块比较短板,所以还是要拿出来把这一块知识好好说说,做一名专业的开发人员。
KF-3-1.加载测试专用属性
测试过程本身并不是一个复杂的过程,但是很多情况下测试时需要模拟一些线上情况,或者模拟一些特殊情况。如果当前环境按照线上环境已经设定好了,例如是下面的配置
env:
maxMemory: 32GB
minMemory: 16GB
但是你现在想测试对应的兼容性,需要测试如下配置
env:
maxMemory: 16GB
minMemory: 8GB
这个时候我们能不能每次测试的时候都去修改源码application.yml中的配置进行测试呢?显然是不行的。每次测试前改过来,每次测试后改回去,这太麻烦了。于是我们就想,需要在测试环境中创建一组临时属性,去覆盖我们源码中设定的属性,这样测试用例就相当于是一个独立的环境,能够独立测试,这样就方便多了。
临时属性
springboot已经为我们开发者早就想好了这种问题该如何解决,并且提供了对应的功能入口。在测试用例程序中,可以通过对注解@SpringBootTest添加属性来模拟临时属性,具体如下:
//properties属性可以为当前测试用例添加临时的属性配置
@SpringBootTest(properties = {"test.prop=testValue1"})
public class PropertiesAndArgsTest {
@Value("${test.prop}")
private String msg;
@Test
void testProperties(){
System.out.println(msg);
}
}
使用注解@SpringBootTest的properties属性就可以为当前测试用例添加临时的属性,覆盖源码配置文件中对应的属性值进行测试。
临时参数
通过命令行参数也可以设置属性值(启动的时候)。而且线上启动程序时,通常都会添加一些专用的配置信息。而在测试中这些配置信息通过注解@SpringBootTest的另一个属性来进行设定。
//args属性可以为当前测试用例添加临时的命令行参数
@SpringBootTest(args={"--test.prop=testValue2"})
public class PropertiesAndArgsTest {
@Value("${test.prop}")
private String msg;
@Test
void testProperties(){
System.out.println(msg);
}
}
使用注解@SpringBootTest的args属性就可以为当前测试用例模拟命令行参数并进行测试。
args属性配置优先于properties属性配置加载。
总结
- 加载测试临时属性可以通过注解@SpringBootTest的properties和args属性进行设定,此设定应用范围仅适用于当前测试用例
思考
应用于测试环境的临时属性解决了,如果想在测试的时候临时加载一些bean能不做呢?也就是说我测试时,想搞一些独立的bean出来,专门应用于测试环境,能否实现呢?咱们下一节再讲。
KF-3-2.加载测试专用配置
上一节提出了临时配置一些专用于测试环境的bean的需求,这一节我们就来解决这个问题。
现在我们的需求就是在测试环境中再添加一个配置类,然后启动测试环境时,生效此配置就行了。其实做法和spring环境中加载多个配置信息的方式完全一样。具体操作步骤如下:
步骤①:在测试包test中创建专用的测试环境配置类
@Configuration
public class MsgConfig {
@Bean
public String msg(){
return "bean msg";
}
}
上述配置仅用于演示当前实验效果,实际开发可不能这么注入String类型的数据
步骤②:在启动测试环境时,导入测试环境专用的配置类,使用@Import注解即可实现
@SpringBootTest
@Import({MsgConfig.class})
public class ConfigurationTest {
@Autowired
private String msg;
@Test
void testConfiguration(){
System.out.println(msg);
}
}
到这里就通过@Import属性实现了基于开发环境的配置基础上,对配置进行测试环境的追加操作,实现了1+1的配置环境效果。这样我们就可以实现每一个不同的测试用例加载不同的bean的效果,丰富测试用例的编写,同时不影响开发环境的配置。
总结
- 定义测试环境专用的配置类,然后通过@Import注解在具体的测试中导入临时的配置,例如测试用例,方便测试过程,且上述配置不影响其他的测试类环境
思考
当前我们已经可以实现业务层和数据层的测试,并且通过临时配置,控制每个测试用例加载不同的测试数据。但是实际企业开发不仅要保障业务层与数据层的功能安全有效,也要保障表现层的功能正常。但是我们目的对表现层的测试都是通过postman手工测试的,**并没有在打包过程中体现表现层功能被测试通过。**能否在测试用例中对表现层进行功能测试呢?还真可以,咱们下一节再讲。
KF-3-3.Web环境模拟测试⭐️
在测试中对表现层功能进行测试需要一个基础和一个功能。所谓的一个基础是运行测试程序时,必须启动web环境,不然没法测试web功能。一个功能是必须在测试程序中具备发送web请求的能力,不然无法实现web功能的测试。所以在测试用例中测试表现层接口这项工作就转换成了两件事,一,如何在测试类中启动web测试,二,如何在测试类中发送web请求。下面一件事一件事进行,先说第一个
测试类中启动web环境
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class WebTest {
}
测试类中启动web环境时,可以指定启动的Web环境对应的端口,springboot提供了4种设置值,分别如下:
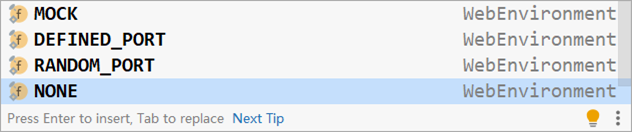
- MOCK:根据当前设置确认是否启动web环境,例如使用了Servlet的API就启动web环境,属于适配性的配置
- DEFINED_PORT:使用自定义的端口作为web服务器端口
- RANDOM_PORT:使用随机端口作为web服务器端口
- NONE:不启动web环境
通过上述配置,现在启动测试程序时就可以正常启用web环境了,建议大家测试时使用RANDOM_PORT。
测试环境中的web环境已经搭建好了,下面就可以来解决第二个问题了,如何在程序代码中发送web请求。
1.测试类中发送请求
对于测试类中发送请求,其实java的API就提供对应的功能,只不过平时各位小伙伴接触的比较少,所以较为陌生。springboot为了便于开发者进行对应的功能开发,对其又进行了包装,简化了开发步骤,具体操作如下:
步骤①:在测试类中开启web虚拟调用功能,通过注解**@AutoConfigureMockMvc**实现此功能的开启
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
//开启虚拟MVC调用
@AutoConfigureMockMvc
public class WebTest {
}
步骤②:定义发起虚拟调用的对象MockMVC,通过自动装配的形式初始化对象
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
//开启虚拟MVC调用
@AutoConfigureMockMvc
public class WebTest {
@Test
void testWeb(@Autowired MockMvc mvc) {
}
}
步骤③:创建一个虚拟请求对象,封装请求的路径,并使用MockMVC对象发送对应请求
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
//开启虚拟MVC调用
@AutoConfigureMockMvc
public class WebTest {
@Test
void testWeb(@Autowired MockMvc mvc) throws Exception {
//http://localhost:8080/books
//创建虚拟请求,当前访问/books
MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books");
//执行对应的请求
mvc.perform(builder);
}
}
执行测试程序,现在就可以正常的发送/books对应的请求了,注意访问路径不要写http://localhost:8080/books,因为前面的服务器IP地址和端口使用的是当前虚拟的web环境,无需指定,仅指定请求的具体路径即可。
总结
- 在测试类中测试web层接口要保障测试类启动时启动web容器,使用@SpringBootTest注解的webEnvironment属性可以虚拟web环境用于测试
- 为测试方法注入MockMvc对象,通过MockMvc对象可以发送虚拟请求,模拟web请求调用过程
思考
目前已经成功的发送了请求,但是还没有起到测试的效果,测试过程必须出现预计值与真实值的比对结果才能确认测试结果是否通过,虚拟请求中能对哪些请求结果进行比对呢?咱们下一节再讲。
2.web环境请求结果比对
上一节已经在测试用例中成功的模拟出了web环境,并成功的发送了web请求,本节就来解决发送请求后如何比对发送结果的问题。其实发完请求得到的信息只有一种,就是响应对象。至于响应对象中包含什么,就可以比对什么。常见的比对内容如下:
-
响应状态匹配
@Test void testStatus(@Autowired MockMvc mvc) throws Exception { MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books"); ResultActions action = mvc.perform(builder); //设定预期值 与真实值进行比较,成功测试通过,失败测试失败 //定义本次调用的预期值 StatusResultMatchers status = MockMvcResultMatchers.status(); //预计本次调用时成功的:状态200 ResultMatcher ok = status.isOk(); //添加预计值到本次调用过程中进行匹配 action.andExpect(ok); } -
响应体匹配(非json数据格式)
@Test void testBody(@Autowired MockMvc mvc) throws Exception { MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books"); ResultActions action = mvc.perform(builder); //设定预期值 与真实值进行比较,成功测试通过,失败测试失败 //定义本次调用的预期值 ContentResultMatchers content = MockMvcResultMatchers.content(); ResultMatcher result = content.string("springboot2"); //添加预计值到本次调用过程中进行匹配 action.andExpect(result); } -
响应体匹配(json数据格式,开发中的主流使用方式)
@Test void testJson(@Autowired MockMvc mvc) throws Exception { MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books"); ResultActions action = mvc.perform(builder); //设定预期值 与真实值进行比较,成功测试通过,失败测试失败 //定义本次调用的预期值 ContentResultMatchers content = MockMvcResultMatchers.content(); ResultMatcher result = content.json("{\"id\":1,\"name\":\"springboot2\",\"type\":\"springboot\"}"); //添加预计值到本次调用过程中进行匹配 action.andExpect(result); } -
响应头信息匹配
@Test void testContentType(@Autowired MockMvc mvc) throws Exception { MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books"); ResultActions action = mvc.perform(builder); //设定预期值 与真实值进行比较,成功测试通过,失败测试失败 //定义本次调用的预期值 HeaderResultMatchers header = MockMvcResultMatchers.header(); ResultMatcher contentType = header.string("Content-Type", "application/json"); //添加预计值到本次调用过程中进行匹配 action.andExpect(contentType); }
基本上齐了,头信息,正文信息,状态信息都有了,就可以组合出一个完美的响应结果比对结果了。以下范例就是三种信息同时进行匹配校验,也是一个完整的信息匹配过程。
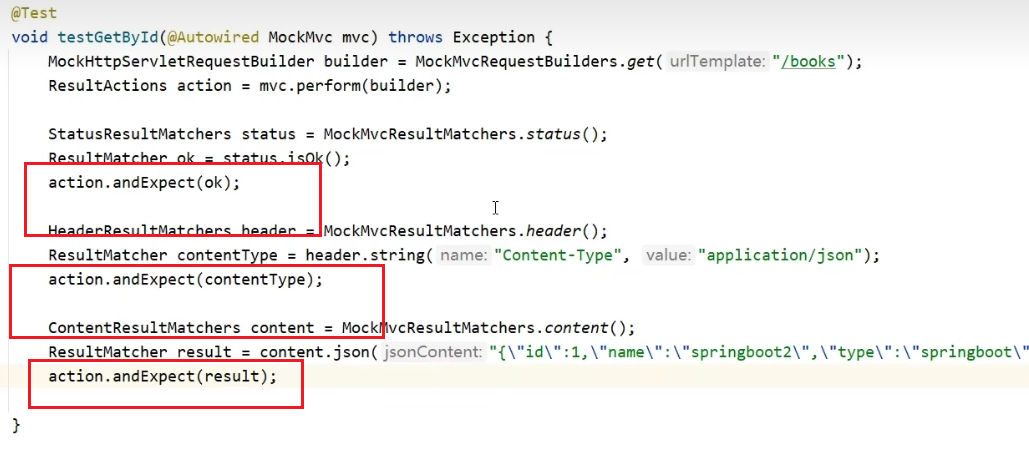
@Test
void testGetById(@Autowired MockMvc mvc) throws Exception {
MockHttpServletRequestBuilder builder = MockMvcRequestBuilders.get("/books");
ResultActions action = mvc.perform(builder);
StatusResultMatchers status = MockMvcResultMatchers.status();
ResultMatcher ok = status.isOk();
action.andExpect(ok);
HeaderResultMatchers header = MockMvcResultMatchers.header();
ResultMatcher contentType = header.string("Content-Type", "application/json");
action.andExpect(contentType);
ContentResultMatchers content = MockMvcResultMatchers.content();
ResultMatcher result = content.json("{\"id\":1,\"name\":\"springboot\",\"type\":\"springboot\"}");
action.andExpect(result);
}
- 一般只匹配context即可
总结
- web虚拟调用可以对本地虚拟请求的返回响应信息进行比对,分为响应头信息比对、响应体信息比对、响应状态信息比对
KF-3-4.数据层测试回滚
-
数据库表结构要用innodb存储引擎,myIsam不支持事务
-
这里要注意,即使回滚数据,id也被占用,id被数据库管理
-
设置数据回滚的原因
当前我们的测试程序可以完美的进行表现层、业务层、数据层接口对应的功能测试了,但是测试用例开发完成后,在打包的阶段由于test生命周期属于必须被运行的生命周期,如果跳过会给系统带来极高的安全隐患,所以测试用例必须执行。但是新的问题就呈现了,测试用例如果测试时产生了事务提交就会在测试过程中对数据库数据产生影响,进而产生垃圾数据。这个过程不是我们希望发生的,作为开发者测试用例该运行运行,但是过程中产生的数据不要在我的系统中留痕,这样该如何处理呢?
当程序运行后,只要注解@Transactional出现的位置存在注解@SpringBootTest,springboot就会认为这是一个测试程序,无需提交事务,所以也就可以避免事务的提交。
@SpringBootTest
@Transactional
@Rollback(true)
public class DaoTest {
@Autowired
private BookService bookService;
@Test
void testSave(){
Book book = new Book();
book.setName("springboot3");
book.setType("springboot3");
book.setDescription("springboot3");
bookService.save(book);
}
}
如果开发者想提交事务,也可以,再添加一个**@RollBack的注解**,设置回滚状态为false即可正常提交事务,是不是很方便?springboot在辅助开发者日常工作这一块展现出了惊人的能力,实在太贴心了。
总结
- 在springboot的测试类中通过添加注解@Transactional来阻止测试用例提交事务
- 通过注解@Rollback控制springboot测试类执行结果是否提交事务,需要配合注解@Transactional使用
思考
当前测试程序已经近乎完美了,但是由于测试用例中书写的测试数据属于固定数据,往往失去了测试的意义,开发者可以针对测试用例进行针对性开发,这样就有可能出现测试用例不能完美呈现业务逻辑代码是否真实有效的达成业务目标的现象,解决方案其实很容易想,测试用例的数据只要随机产生就可以了,能实现吗?咱们下一节再讲。
KF-3-5.测试用例数据设定:随机值
对于测试用例的数据固定书写肯定是不合理的,springboot提供了在配置中使用随机值的机制,确保每次运行程序加载的数据都是随机的。具体如下:
testcase:
book:
id: ${random.int}
id2: ${random.int(10)}
type: ${random.int!5,10!}
name: ${random.value}
uuid: ${random.uuid}
publishTime: ${random.long}
当前配置就可以在每次运行程序时创建一组随机数据,避免每次运行时数据都是固定值的尴尬现象发生,有助于测试功能的进行。数据的加载按照之前加载数据的形式,使用@ConfigurationProperties注解即可
@Component
@Data
@ConfigurationProperties(prefix = "testcase.book")
public class BookCase {
private int id;
private int id2;
private int type;
private String name;
private String uuid;
private long publishTime;
}
对于随机值的产生,还有一些小的限定规则,比如产生的数值性数据可以设置范围等,具体如下:

- ${random.int}表示随机整数
- ${random.int(10)}表示10以内的随机数
- ${random.int(10,20)}表示10到20的随机数
- 其中()可以是任意字符,例如[],!!均可
总结
- 使用随机数据可以替换测试用例中书写的固定数据,提高测试用例中的测试数据有效性
KF-4.数据层解决方案⭐️
开发实用篇前三章基本上是开胃菜,从第四章开始,开发实用篇进入到了噩梦难度了,从这里开始,不再是单纯的在springboot内部搞事情了,要涉及到很多相关知识。本章节主要内容都是和数据存储与读取相关,前期学习的知识与数据层有关的技术基本上都围绕在数据库这个层面上,所以本章要讲的第一个大的分支就是SQL解决方案相关的内容,除此之外,数据的来源还可以是非SQL技术相关的数据操作,因此第二部分围绕着NOSQL解决方案讲解。至于什么是NOSQL解决方案,讲到了再说吧。下面就从SQL解决方案说起。
KF-4-1.SQL
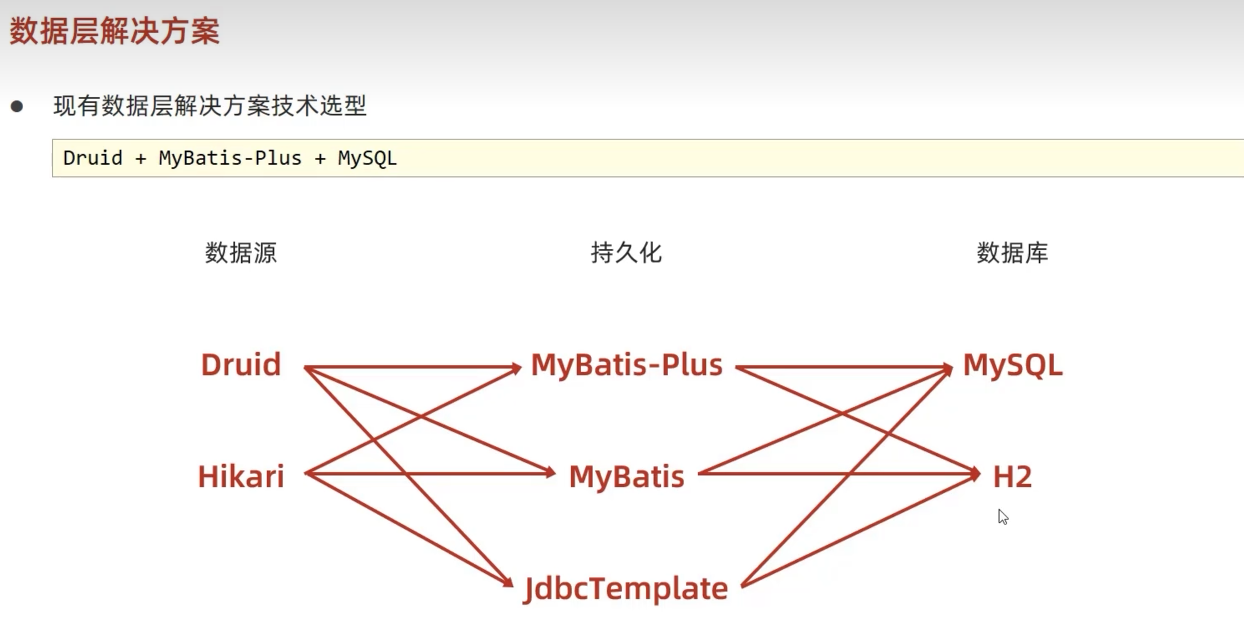
回忆一下之前做SSMP整合的时候数据层解决方案涉及到了哪些技术?MySQL数据库与MyBatisPlus框架,后面又学了Druid数据源的配置,所以现在数据层解决方案可以说是Mysql+Druid+MyBatisPlus。而三个技术分别对应了数据层操作的三个层面:
- 数据源技术:Druid
- 持久化技术:MyBatisPlus
- 数据库技术:MySQL
下面的研究就分为三个层面进行研究,对应上面列出的三个方面,咱们就从第一个数据源技术开始说起。
数据源技术
- 作用:数据库连接的管理
- 概述:①常用数据源的配置和替换②三种内嵌数据源
目前我们使用的数据源技术是Druid,运行时可以在日志中看到对应的数据源初始化信息,具体如下:
INFO 28600 --- [ main] c.a.d.s.b.a.DruidDataSourceAutoConfigure : Init DruidDataSource
INFO 28600 --- [ main] com.alibaba.druid.pool.DruidDataSource : {dataSource-1} inited
如果不使用Druid数据源,程序运行后是什么样子呢?是独立的数据库连接对象还是有其他的连接池技术支持呢?将Druid技术对应的starter去掉再次运行程序可以在日志中找到如下初始化信息:
INFO 31820 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
INFO 31820 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
数据层技术是每一个企业级应用程序都会用到的,而其中必定会进行数据库连接的管理。springboot根据开发者的习惯出发,开发者提供了数据源技术,就用你提供的,开发者没有提供,那总不能手工管理一个一个的数据库连接对象啊,怎么办?我给你一个默认的就好了,这样省心又省事,大家都方便。
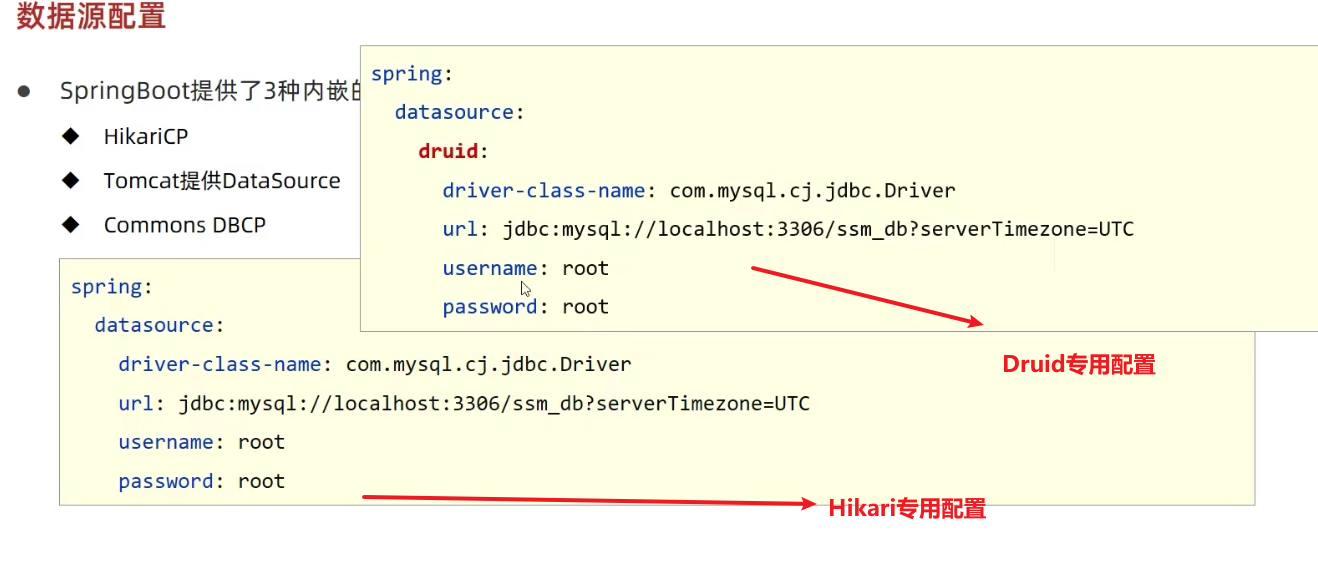
springboot提供了3款内嵌数据源技术,分别如下:
- HikariCP
- Tomcat提供DataSource
- Commons DBCP
第一种,HikartCP,这是springboot官方推荐的数据源技术,作为默认内置数据源使用。啥意思?你不配置数据源,那就用这个。
第二种,Tomcat提供的DataSource,如果不想用HikartCP,并且使用tomcat作为web服务器进行web程序的开发,使用这个。为什么是Tomcat,不是其他web服务器呢?因为web技术导入starter后,默认使用内嵌tomcat,既然都是默认使用的技术了,那就一用到底,数据源也用它的。有人就提出怎么才能不使用HikartCP用tomcat提供的默认数据源对象呢?把HikartCP技术的坐标排除掉就OK了。
第三种,DBCP,这个使用的条件就更苛刻了,既不使用HikartCP也不使用tomcat的DataSource时,默认给你用这个。
之前我们配置druid时使用druid的starter对应的配置如下:
spring:
datasource:
druid:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
这就是配置hikari数据源的方式。如果想对hikari做进一步的配置,可以继续配置其独立的属性。例如:
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
hikari:
maximum-pool-size: 50
如果不想使用hikari数据源,使用tomcat的数据源或者DBCP配置格式也是一样的。学习到这里,以后我们做数据层时,数据源对象的选择就不再是单一的使用druid数据源技术了,可以根据需要自行选择。
总结
- springboot技术提供了3种内置的数据源技术,分别是Hikari、tomcat内置数据源、DBCP
持久化技术:主要讲JdbcTemplate
-
**依赖联系:**mybatis-plus-boot-starter集成了spring-boot-starter-jdbc,而spring-boot-starter-jdbc内置了默认数据库连接池
-
JdbcTemplate加入boot工程后,交给spring容器管理,spring容器为其注入数据库配置和连接池,jdbcTemplate相当于原生jdbc上进行数据层的开发
-
使用过程:一定要先导入spring-boot-starter-jdbc,这样会提供默认持久化技术spring-boot-starter-jdbc
其实这个技术不能说是springboot提供的,因为不使用springboot技术,一样能使用它,谁提供的呢?spring技术提供的,所以在springboot技术范畴中,这个技术也是存在的,毕竟springboot技术是加速spring程序开发而创建的。
这个技术其实就是回归到jdbc最原始的编程形式来进行数据层的开发,下面直接上操作步骤:
步骤①:导入jdbc对应的坐标,记得是starter
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency
步骤②:自动装配JdbcTemplate对象
@SpringBootTest
class Springboot15SqlApplicationTests {
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
}
}
步骤③:使用JdbcTemplate实现查询操作(非实体类封装数据的查询操作)
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
String sql = "select * from tbl_book";
List<Map<String, Object>> maps = jdbcTemplate.queryForList(sql);
System.out.println(maps);
}
步骤④:使用JdbcTemplate实现查询操作(实体类封装数据的查询操作)
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
String sql = "select * from tbl_book";
RowMapper<Book> rm = new RowMapper<Book>() {
@Override
public Book mapRow(ResultSet rs, int rowNum) throws SQLException {
Book temp = new Book();
temp.setId(rs.getInt("id"));
temp.setName(rs.getString("name"));
temp.setType(rs.getString("type"));
temp.setDescription(rs.getString("description"));
return temp;
}
};
List<Book> list = jdbcTemplate.query(sql, rm);
System.out.println(list);
}
步骤⑤:使用JdbcTemplate实现增删改操作
@Test
void testJdbcTemplateSave(@Autowired JdbcTemplate jdbcTemplate){
String sql = "insert into tbl_book values(3,'springboot1','springboot2','springboot3')";
jdbcTemplate.update(sql);
}
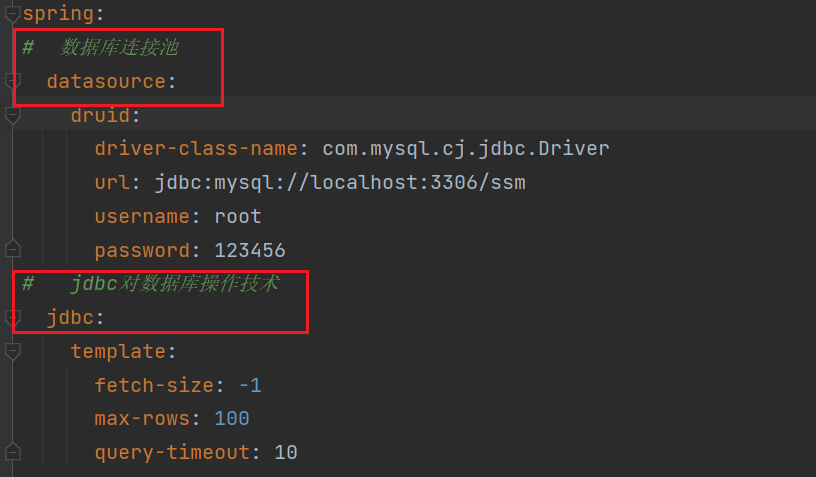
如果想对JdbcTemplate对象进行相关配置,可以在yml文件中进行设定,具体如下:
spring:
jdbc:
template:
query-timeout: -1 # 查询超时时间
max-rows: 500 # 最大行数
fetch-size: -1 # 缓存行数
总结
- SpringBoot内置JdbcTemplate持久化解决方案
- 使用JdbcTemplate需要导入spring-boot-starter-jdbc的坐标
数据库技术
- 内嵌数据库特点:内存运行,速度快
- 内嵌数据库优点:方便进行功能测试
- H2数据库连接的时候:只能有一个程序来访问,如果springboot启动的时候,插入操作就不能进行
- H2数据库可以有jdbcTmplate操作,mybatis-plus也能无缝操作
截止到目前,springboot给开发者提供了内置的数据源解决方案和持久化解决方案,在数据层解决方案三件套中还剩下一个数据库,莫非springboot也提供有内置的解决方案?还真有,还不是一个,三个,这一节就来说说内置的数据库解决方案。
springboot提供了3款内置的数据库,分别是
- H2
- HSQL
- Derby
以上三款数据库除了可以独立安装之外,还可以像是tomcat服务器一样,采用内嵌的形式运行在spirngboot容器中。内嵌在容器中运行,那必须是java对象啊,对,这三款数据库底层都是使用java语言开发的。
在应用程序运行后,如果我们进行测试工作,此时测试的数据无需存储在磁盘上,但是又要测试使用,内嵌数据库就方便了,运行在内存中,该测试测试,该运行运行,等服务器关闭后,一切烟消云散,多好,省得你维护外部数据库了。这也是内嵌数据库的最大优点,方便进行功能测试。
下面以H2数据库为例讲解如何使用这些内嵌数据库,操作步骤也非常简单,简单才好用嘛
步骤①:导入H2数据库对应的坐标,一共2个
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
步骤②:将工程设置为web工程,启动工程时启动H2数据库
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
步骤③:通过配置开启H2数据库控制台访问程序,也可以使用其他的数据库连接软件操作
spring:
h2:
console:
enabled: true
path: /h2
web端访问路径/h2,访问密码123456,如果访问失败,先配置下列数据源,启动程序运行后再次访问/h2路径就可以正常访问了
datasource:
url: jdbc:h2:~/test
hikari:
driver-class-name: org.h2.Driver
username: sa
password: 123456
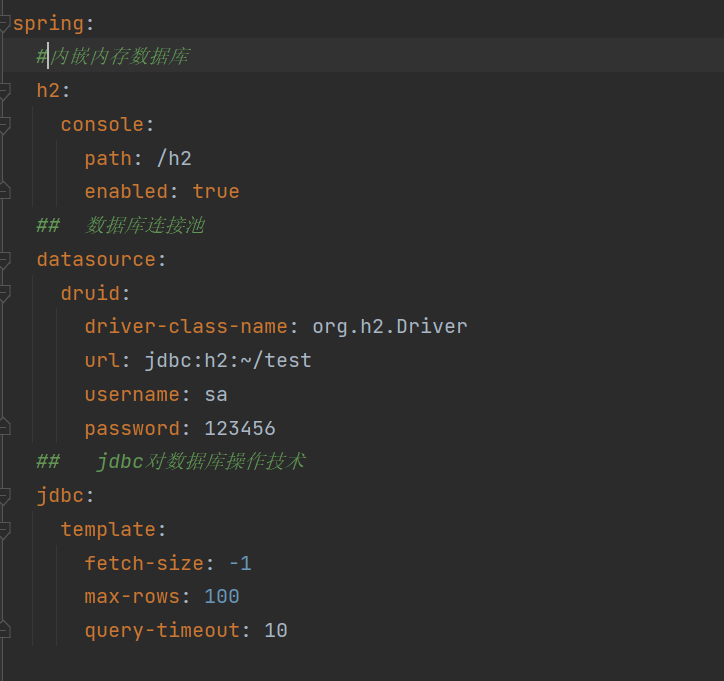
步骤④:使用JdbcTemplate或MyBatisPlus技术操作数据库
(略)
其实我们只是换了一个数据库而已,其他的东西都不受影响。一个重要提醒,别忘了,上线时,把内存级数据库关闭,采用MySQL数据库作为数据持久化方案,关闭方式就是设置enabled属性为false即可。
总结
- H2内嵌式数据库启动方式,添加坐标,添加配置
- H2数据库线上运行时请务必关闭
到这里SQL相关的数据层解决方案就讲完了,现在的可选技术就丰富的多了。
- 数据源技术:Druid、Hikari、tomcat DataSource、DBCP
- 持久化技术:MyBatisPlus、MyBatis、JdbcTemplate
- 数据库技术:MySQL、H2、HSQL、Derby
现在开发程序时就可以在以上技术中任选一种组织成一套数据库解决方案了。
KF-4-2.NoSQL
SQL数据层解决方案说完了,下面来说收NoSQL数据层解决方案。这个NoSQL是什么意思呢?从字面来看,No表示否定,NoSQL就是非关系型数据库解决方案,意思就是数据该存存该取取,只是这些数据不放在关系型数据库中了,那放在哪里?自然是一些能够存储数据的其他相关技术中了,比如Redis等。
如果想看Linux版软件安装,可以再找到对应技术的学习文档查阅学习。
SpringBoot整合Redis
- 内存级数据库
Redis是一款采用key-value数据存储格式的内存级NoSQL数据库,重点关注数据存储格式,是key-value格式,也就是键值对的存储形式。与MySQL数据库不同,MySQL数据库有表、有字段、有记录,Redis没有这些东西,就是一个名称对应一个值,并且数据以存储在内存中使用为主。什么叫以存储在内存中为主?其实Redis有它的数据持久化方案,分别是RDB和AOF,但是Redis自身并不是为了数据持久化而生的,主要是在内存中保存数据,加速数据访问的,所以说是一款内存级数据库。
Redis支持多种数据存储格式,比如可以直接存字符串,也可以存一个map集合,list集合,后面会涉及到一些不同格式的数据操作,这个需要先学习一下才能进行整合,所以在基本操作中会介绍一些相关操作。下面就先安装,再操作,最后说整合
安装
啥是msi,其实就是一个文件安装包,不仅安装软件,还帮你把安装软件时需要的功能关联在一起,打包操作。比如如安装序列、创建和设置安装路径、设置系统依赖项、默认设定安装选项和控制安装过程的属性。说简单点就是一站式服务,安装过程一条龙操作一气呵成,就是为小白用户提供的软件安装程序。
安装完毕后会得到如下文件,其中有两个文件对应两个命令,是启动Redis的核心命令,需要再CMD命令行模式执行。
启动服务器
redis-server.exe redis.windows.conf
初学者无需调整服务器对外服务端口,默认6379。
启动客户端
redis-cli.exe
如果启动redis服务器失败,可以先启动客户端,然后执行shutdown操作后退出,此时redis服务器就可以正常执行了。
基本操作
服务器启动后,使用客户端就可以连接服务器,类似于启动完MySQL数据库,然后启动SQL命令行操作数据库。
放置一个字符串数据到redis中,先为数据定义一个名称,比如name,age等,然后使用命令set设置数据到redis服务器中即可
set name itheima
set age 12
从redis中取出已经放入的数据,根据名称取,就可以得到对应数据。如果没有对应数据就会得到(nil)
get name
get age
以上使用的数据存储是一个名称对应一个值,如果要维护的数据过多,可以使用别的数据存储结构。例如hash,它是一种一个名称下可以存储多个数据的存储模型,并且每个数据也可以有自己的二级存储名称。向hash结构中存储数据格式如下:
hset a a1 aa1 #对外key名称是a,在名称为a的存储模型中,a1这个key中保存了数据aa1
hset a a2 aa2
获取hash结构中的数据命令如下
hget a a1 #得到aa1
hget a a2 #得到aa2
整合
在进行整合之前先梳理一下整合的思想,springboot整合任何技术其实就是在springboot中使用对应技术的API。如果两个技术没有交集,就不存在整合的概念了。所谓整合其实就是使用springboot技术去管理其他技术,几个问题是躲不掉的。
第一,需要先导入对应技术的坐标,而整合之后,这些坐标都有了一些变化
第二,任何技术通常都会有一些相关的设置信息,整合之后,这些信息如何写,写在哪是一个问题
第三,没有整合之前操作如果是模式A的话,整合之后如果没有给开发者带来一些便捷操作,那整合将毫无意义,所以整合后操作肯定要简化一些,那对应的操作方式自然也有所不同
按照上面的三个问题去思考springboot整合所有技术是一种通用思想,在整合的过程中会逐步摸索出整合的套路,而且适用性非常强,经过若干种技术的整合后基本上可以总结出一套固定思维。
下面就开始springboot整合redis,操作步骤如下:
步骤①:导入springboot整合redis的starter坐标
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
上述坐标可以在创建模块的时候通过勾选的形式进行选择,归属NoSQL分类中
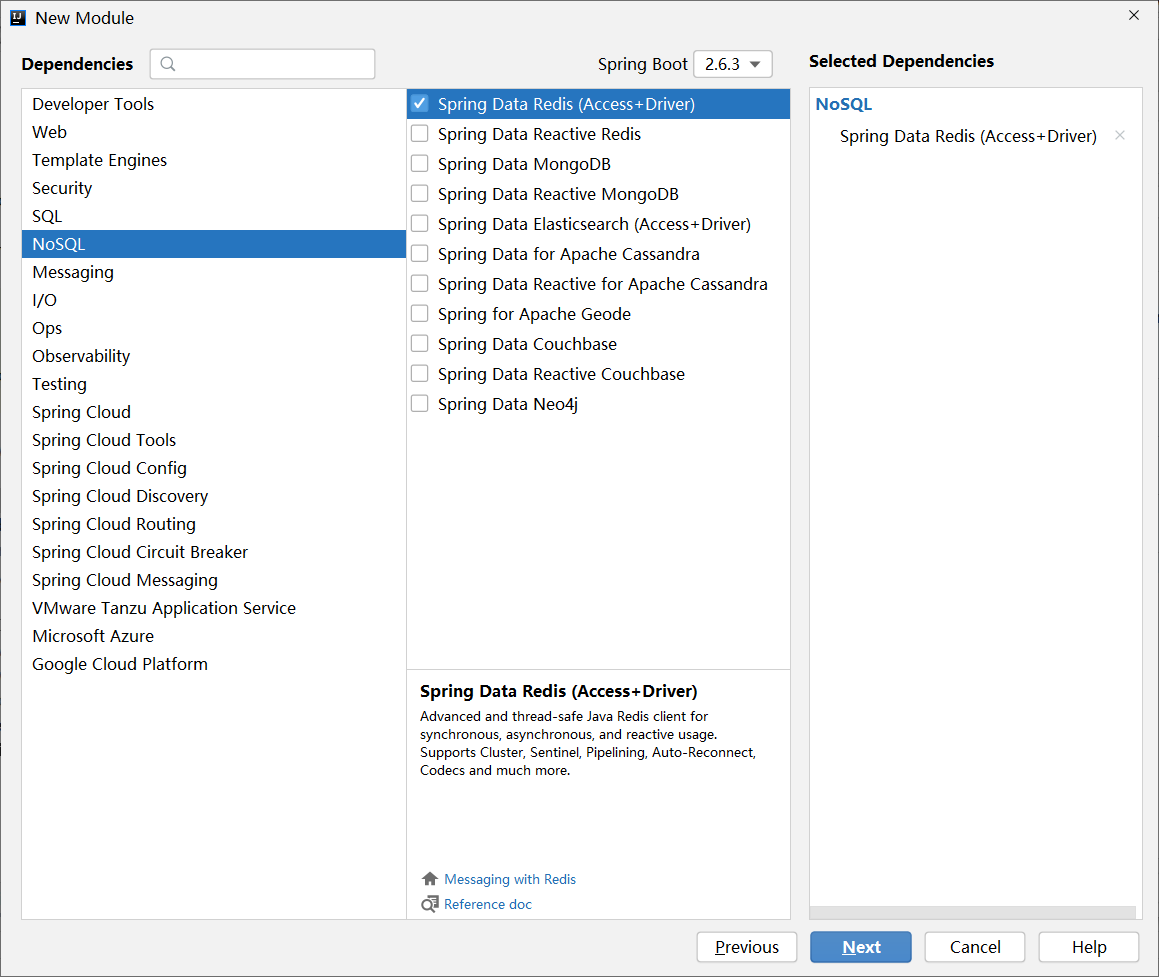
步骤②:进行基础配置
spring:
redis:
host: localhost
port: 6379
操作redis,最基本的信息就是操作哪一台redis服务器,所以服务器地址属于基础配置信息,不可缺少。但是即便你不配置,目前也是可以用的。因为以上两组信息都有默认配置,刚好就是上述配置值。
步骤③:使用springboot整合redis的专用客户端接口操作,此处使用的是RedisTemplate
@SpringBootTest
class Springboot16RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void set() {
ValueOperations ops = redisTemplate.opsForValue();
ops.set("age",41);
}
@Test
void get() {
ValueOperations ops = redisTemplate.opsForValue();
Object age = ops.get("name");
System.out.println(age);
}
@Test
void hset() {
HashOperations ops = redisTemplate.opsForHash();
ops.put("info","b","bb");
}
@Test
void hget() {
HashOperations ops = redisTemplate.opsForHash();
Object val = ops.get("info", "b");
System.out.println(val);
}
}
在操作redis时,需要先确认操作何种数据,根据数据种类得到操作接口。例如使用opsForValue()获取string类型的数据操作接口,使用opsForHash()获取hash类型的数据操作接口,剩下的就是调用对应api操作了。各种类型的数据操作接口如下:
总结
- springboot整合redis步骤
- 导入springboot整合redis的starter坐标
- 进行基础配置
- 使用springboot整合redis的专用客户端接口RedisTemplate操作
StringRedisTemplate
由于redis内部不提供java对象的存储格式,因此当操作的数据以对象的形式存在时,会进行转码,转换成字符串格式后进行操作。为了方便开发者使用基于字符串为数据的操作,springboot整合redis时提供了专用的API接口StringRedisTemplate,你可以理解为这是RedisTemplate的一种指定数据泛型的操作API。
@SpringBootTest
public class StringRedisTemplateTest {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
void get(){
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
String name = ops.get("name");
System.out.println(name);
}
}
redis客户端选择
springboot整合redis技术提供了多种客户端兼容模式,默认提供的是lettucs客户端技术,也可以根据需要切换成指定客户端技术,例如jedis客户端技术,切换成jedis客户端技术操作步骤如下:
步骤①:导入jedis坐标
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
jedis坐标受springboot管理,无需提供版本号
步骤②:配置客户端技术类型,设置为jedis
spring:
redis:
host: localhost
port: 6379
client-type: jedis
步骤③:根据需要设置对应的配置
spring:
redis:
host: localhost
port: 6379
client-type: jedis
lettuce:
pool:
max-active: 16
jedis:
pool:
max-active: 16
lettcus与jedis区别
- jedis连接Redis服务器是直连模式,当多线程模式下使用jedis会存在线程安全问题,解决方案可以通过配置连接池使每个连接专用,这样整体性能就大受影响
- lettcus基于Netty框架进行与Redis服务器连接,底层设计中采用StatefulRedisConnection。 StatefulRedisConnection自身是线程安全的,可以保障并发访问安全问题,所以一个连接可以被多线程复用。当然lettcus也支持多连接实例一起工作
总结
- springboot整合redis提供了StringRedisTemplate对象,以字符串的数据格式操作redis
- 如果需要切换redis客户端实现技术,可以通过配置的形式进行
SpringBoot整合MongoDB
- MongoDB能存储结构化数据,而且访问速度较快
使用Redis技术可以有效的提高数据访问速度,但是由于Redis的数据格式单一性,无法操作结构化数据,当操作对象型的数据时,Redis就显得捉襟见肘。在保障访问速度的情况下,如果想操作结构化数据,看来Redis无法满足要求了,此时需要使用全新的数据存储结束来解决此问题,本节讲解springboot如何整合MongoDB技术。
MongoDB是一个开源、高性能、无模式的文档型数据库,它是NoSQL数据库产品中的一种,是最像关系型数据库的非关系型数据库。
上述描述中几个词,其中对于我们最陌生的词是无模式的。什么叫无模式呢?简单说就是作为一款数据库,没有固定的数据存储结构,第一条数据可能有A、B、C一共3个字段,第二条数据可能有D、E、F也是3个字段,第三条数据可能是A、C、E3个字段,也就是说数据的结构不固定,这就是无模式。有人会说这有什么用啊?灵活,随时变更,不受约束。基于上述特点,MongoDB的应用面也会产生一些变化。以下列出了一些可以使用MongoDB作为数据存储的场景,但是并不是必须使用MongoDB的场景:
- 淘宝用户数据
- 存储位置:数据库
- 特征:永久性存储,修改频度极低
- 游戏装备数据、游戏道具数据
- 存储位置:数据库、Mongodb
- 特征:永久性存储与临时存储相结合、修改频度较高
- 直播数据、打赏数据、粉丝数据
- 存储位置:数据库、Mongodb
- 特征:永久性存储与临时存储相结合,修改频度极高
- 物联网数据
- 存储位置:Mongodb
- 特征:临时存储,修改频度飞速
快速了解一下MongoDB,下面直接开始我们的学习,老规矩,先安装,再操作,最后说整合
安装
windows版安装包下载地址:https://www.mongodb.com/try/download
下载的安装包也有两种形式,一种是一键安装的msi文件,还有一种是解压缩就能使用的zip文件,哪种形式都行,本课程采用解压缩zip文件进行安装。
解压缩完毕后会得到如下文件,其中bin目录包含了所有mongodb的可执行命令
mongodb在运行时需要指定一个数据存储的目录,所以创建一个数据存储目录,通常放置在安装目录中,此处创建data的目录用来存储数据,具体如下
如果在安装的过程中出现了如下警告信息,就是告诉你,你当前的操作系统缺少了一些系统文件,这个不用担心。
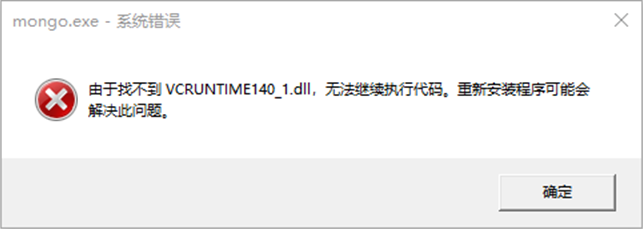
根据下列方案即可解决,在浏览器中搜索提示缺少的名称对应的文件,并下载,将下载的文件拷贝到windows安装目录的system32目录下,然后在命令行中执行regsvr32命令注册此文件。根据下载的文件名不同,执行命令前更改对应名称。
regsvr32 vcruntime140_1.dll
启动服务器
mongod --dbpath=..\data\db
启动服务器时需要指定数据存储位置,通过参数–dbpath进行设置,可以根据需要自行设置数据存储路径。默认服务端口27017。
启动客户端
mongo --host=127.0.0.1 --port=27017
基本操作
MongoDB虽然是一款数据库,但是它的操作并不是使用SQL语句进行的,因此操作方式各位小伙伴可能比较陌生,好在有一些类似于Navicat的数据库客户端软件,能够便捷的操作MongoDB,先安装一个客户端,再来操作MongoDB。
同类型的软件较多,本次安装的软件时Robo3t,Robot3t是一款绿色软件,无需安装,解压缩即可。解压缩完毕后进入安装目录双击robot3t.exe即可使用。
打开软件首先要连接MongoDB服务器,选择【File】菜单,选择【Connect…】
进入连接管理界面后,选择左上角的【Create】链接,创建新的连接设置
如果输入设置值即可连接(默认不修改即可连接本机27017端口)
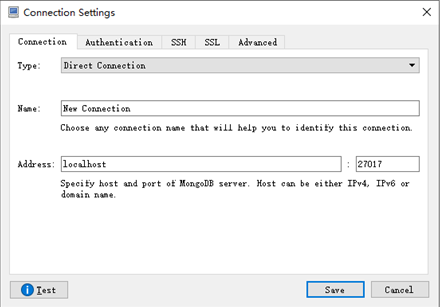
连接成功后在命令输入区域输入命令即可操作MongoDB。
创建数据库:在左侧菜单中使用右键创建,输入数据库名称即可
创建集合:在Collections上使用右键创建,输入集合名称即可,集合等同于数据库中的表的作用
新增文档:(文档是一种类似json格式的数据,初学者可以先把数据理解为就是json数据)
db.集合名称.insert/save/insertOne(文档)
删除文档:
db.集合名称.remove(条件)
修改文档:
db.集合名称.update(条件,{操作种类:{文档}})
查询文档:
基础查询
查询全部: db.集合.find();
查第一条: db.集合.findOne()
查询指定数量文档: db.集合.find().limit(10) //查10条文档
跳过指定数量文档: db.集合.find().skip(20) //跳过20条文档
统计: db.集合.count()
排序: db.集合.sort({age:1}) //按age升序排序
投影: db.集合名称.find(条件,{name:1,age:1}) //仅保留name与age域
条件查询
基本格式: db.集合.find({条件})
模糊查询: db.集合.find({域名:/正则表达式/}) //等同SQL中的like,比like强大,可以执行正则所有规则
条件比较运算: db.集合.find({域名:{$gt:值}}) //等同SQL中的数值比较操作,例如:name>18
包含查询: db.集合.find({域名:{$in:[值1,值2]}}) //等同于SQL中的in
条件连接查询: db.集合.find({$and:[{条件1},{条件2}]}) //等同于SQL中的and、or
有关MongoDB的基础操作就普及到这里,需要全面掌握MongoDB技术,请参看相关教程学习。
整合
使用springboot整合MongDB该如何进行呢?其实springboot为什么使用的开发者这么多,就是因为他的套路几乎完全一样。导入坐标,做配置,使用API接口操作。整合Redis如此,整合MongoDB同样如此。
第一,先导入对应技术的整合starter坐标
第二,配置必要信息
第三,使用提供的API操作即可
下面就开始springboot整合MongoDB,操作步骤如下:
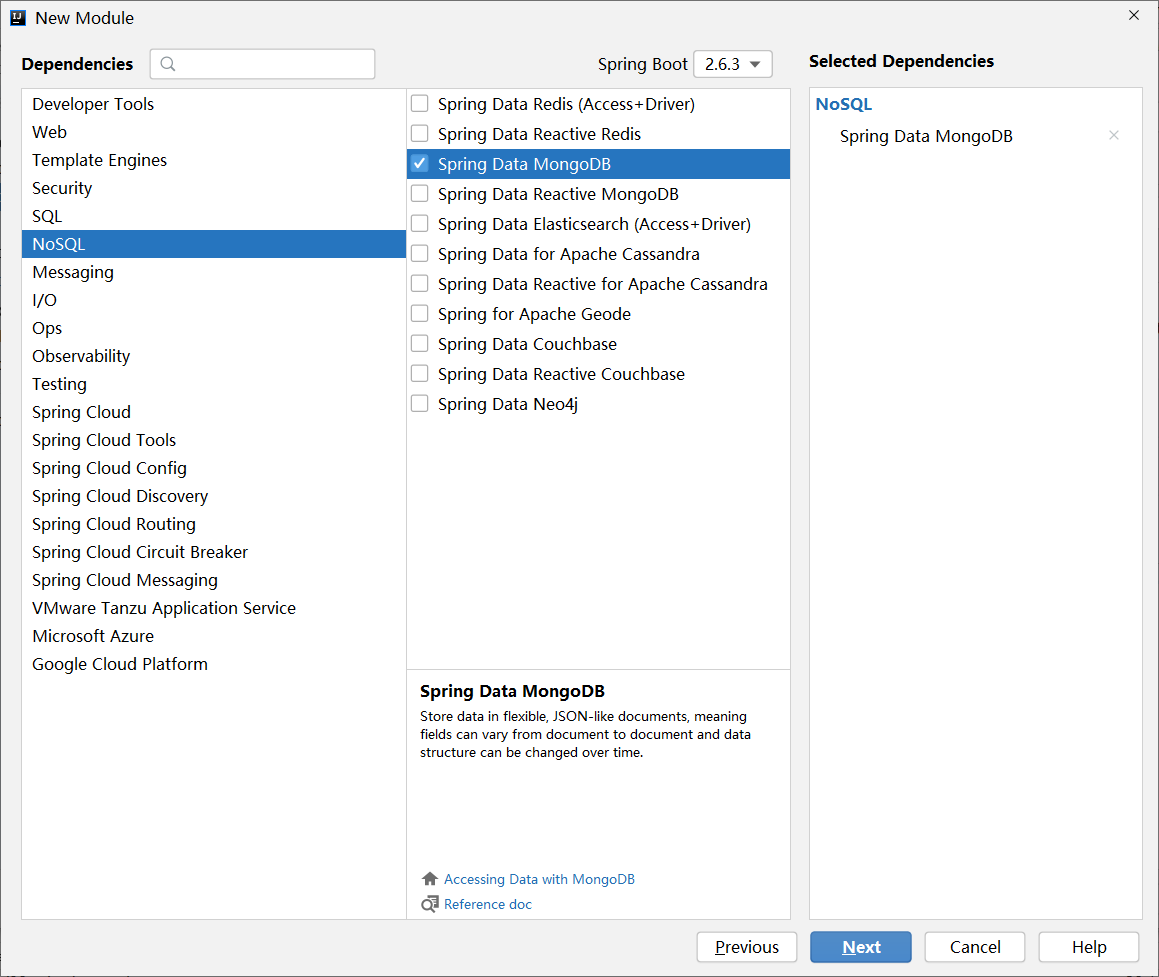
步骤①:导入springboot整合MongoDB的starter坐标
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
上述坐标也可以在创建模块的时候通过勾选的形式进行选择,同样归属NoSQL分类中
步骤②:进行基础配置
spring:
data:
mongodb:
uri: mongodb://localhost/itheima
操作MongoDB需要的配置与操作redis一样,最基本的信息都是操作哪一台服务器,区别就是连接的服务器IP地址和端口不同,书写格式不同而已。
步骤③:使用springboot整合MongoDB的专用客户端接口MongoTemplate来进行操作
@SpringBootTest
class Springboot17MongodbApplicationTests {
@Autowired
private MongoTemplate mongoTemplate;
@Test
void contextLoads() {
Book book = new Book();
book.setId(2);
book.setName("springboot2");
book.setType("springboot2");
book.setDescription("springboot2");
mongoTemplate.save(book);
}
@Test
void find(){
List<Book> all = mongoTemplate.findAll(Book.class);
System.out.println(all);
}
}
整合工作到这里就做完了,感觉既熟悉也陌生。熟悉的是这个套路,三板斧,就这三招,导坐标做配置用API操作,陌生的是这个技术,里面具体的操作API可能会不熟悉,有关springboot整合MongoDB我们就讲到这里。有兴趣可以继续学习MongoDB的操作,然后再来这里通过编程的形式操作MongoDB。
总结
- springboot整合MongoDB步骤
- 导入springboot整合MongoDB的starter坐标
- 进行基础配置
- 使用springboot整合MongoDB的专用客户端接口MongoTemplate操作
,先导入对应技术的整合starter坐标
第二,配置必要信息
第三,使用提供的API操作即可
下面就开始springboot整合MongoDB,操作步骤如下:
步骤①:导入springboot整合MongoDB的starter坐标
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
上述坐标也可以在创建模块的时候通过勾选的形式进行选择,同样归属NoSQL分类中
步骤②:进行基础配置
spring:
data:
mongodb:
uri: mongodb://localhost/itheima
操作MongoDB需要的配置与操作redis一样,最基本的信息都是操作哪一台服务器,区别就是连接的服务器IP地址和端口不同,书写格式不同而已。
步骤③:使用springboot整合MongoDB的专用客户端接口MongoTemplate来进行操作
@SpringBootTest
class Springboot17MongodbApplicationTests {
@Autowired
private MongoTemplate mongoTemplate;
@Test
void contextLoads() {
Book book = new Book();
book.setId(2);
book.setName("springboot2");
book.setType("springboot2");
book.setDescription("springboot2");
mongoTemplate.save(book);
}
@Test
void find(){
List<Book> all = mongoTemplate.findAll(Book.class);
System.out.println(all);
}
}
整合工作到这里就做完了,感觉既熟悉也陌生。熟悉的是这个套路,三板斧,就这三招,导坐标做配置用API操作,陌生的是这个技术,里面具体的操作API可能会不熟悉,有关springboot整合MongoDB我们就讲到这里。有兴趣可以继续学习MongoDB的操作,然后再来这里通过编程的形式操作MongoDB。
总结
- springboot整合MongoDB步骤
- 导入springboot整合MongoDB的starter坐标
- 进行基础配置
- 使用springboot整合MongoDB的专用客户端接口MongoTemplate操作
![[渗透教程]-017-入侵检测与社交网络安全](https://img-blog.csdnimg.cn/img_convert/96da06135b71c16fa9988e6b5a047997.png)