SFSpeechRecognizer 属于 Speech 框架,在 iOS 10 首次出现,并在 iOS13 中进行了比较重大的更新,在 iOS 13 上支持离线语音识别以及语音分析。WWDC2019 展示了其在 AI 领域的进步,其中 iOS 13 设备内置语音识别就是一项比较不错功能。

1. 都做了哪些升级
移动端上的离线语音识别模型,减少用户泄露风险,增加了用户隐私。新 API 支持了很多新功能,例如使用语音分析指标跟踪语音质量和语音模式。
同时设备上的离线模型,可以支持无限期地语音识别。与iOS 10 的早期版本只能识别一分钟相比,这是一个很巨大的提升。当然也存在一丢丢的弊端,它并不会像云端模型一样可以在线学习。会导致设备的准确性有些降低。
iOS 13 SFSpeechRecognizer 相比也智能了很多,可以识别语音中的标点符号。比如说句号,它会识别一个句号,同样其他符号也可以支持识别,比如逗号、破折号等等。但是还存在不足的一点就是目前它还不能自己帮助识别的文字添加标点符号,不过这一点已经在 iOS 16 上得到了处理,准确率也做了相应提升,已经可以替换很多付费的语音识别框架了。
2. 实现效果
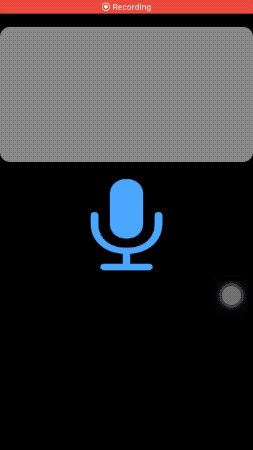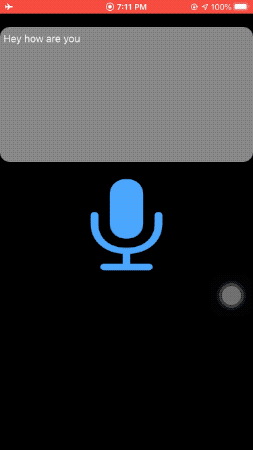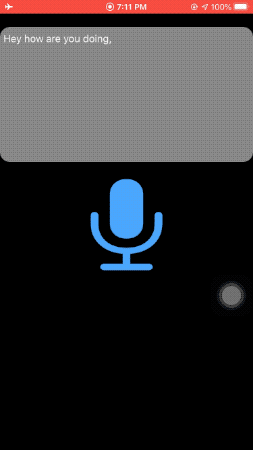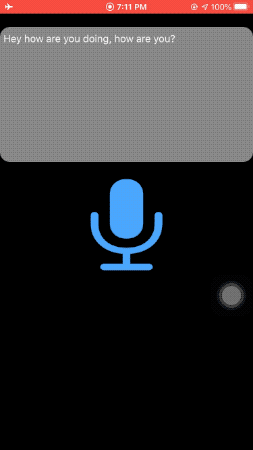
可以先看效果,可以注意一下,屏幕截图是在飞行模式下拍摄的,完全离线。
这次是通过麦克风进行语音识别的,SFSpeechRecognizer 也可以支持语音文件来识别,有兴趣可以自己了解一下。
3. 工作原理

上图是实时语音识别的内部实现,语音识别依赖于以下四个:
- AVAudioEngine
- SFSpeechRecognizer
- SFRecognitionTask
- SFSpeechAudioBufferRecognitionRequest
接下来,我们看看这些是如何工作的。
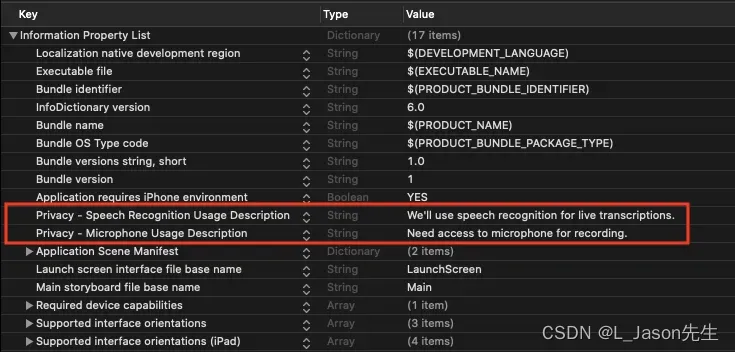
对于新手而言,我先介绍一下用户隐私权限相关的内容:
添加隐私使用说明
这里需要增加麦克风和语音识别的隐私使用说明, 如下所示。
请求权限
SFSpeechRecognizer.requestAuthorization { authStatus in
switch authStatus {
case .authorized:
case .restricted:
case .notDetermined:
case .denied:
}
}
初始化
var speechRecognizer = SFSpeechRecognizer(locale: Locale(identifier: “zh-CN”))
4. 实现
4.1 配置 AVAudioEngine
AVAudioEngine 负责采集来自麦克风的音频信号,然后将音频信号传入 SFSpeechAudioBufferRecognitionRequest。
let audioEngine = AVAudioEngine()
let audioSession = AVAudioSession.sharedInstance()
try audioSession.setCategory(.record, mode: .measurement, options: .duckOthers)
try audioSession.setActive(true, options: .notifyOthersOnDeactivation)
let inputNode = audioEngine.inputNode
// 在安装 tap 之前先移除上一个 否则可能报
// "*** Terminating app due to uncaught exception 'com.apple.coreaudio.avfaudio', reason: 'required condition is false: nullptr == Tap()"之类的错误
inputNode.removeTap(onBus: 0)
let recordingFormat = inputNode.outputFormat(forBus: 0)
// bufferSize:传入缓冲区的请求大小
// 创建一个“tap”来记录/监视/观察节点的输出
// bus:连接tap的节点输出总线
inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) { (buffer: AVAudioPCMBuffer, when: AVAudioTime) in
self.recognitionRequest?.append(buffer)
}
audioEngine.prepare()
try audioEngine.start()
上面的代码在 上安装了一个 tap ,并设置了输出的缓冲区大小,这个缓冲区用来缓存说话或录音时的音频信号。
一旦该缓冲区大小被填满,就会被发送到 SFSpeechAudioBufferRecognitionRequest。
现在我们看看 SFSpeechAudioBufferRecognitionRequest 是如何使用 SFSpeechRecognizer 和 SFSpeechRecognitionTask 将语音转录为文本。
4.2 启用设备语音识别
recognitionRequest.requiresOnDeviceRecognition = true
设置为 false 将使用 Apple Cloud 进行语音识别。需要注意一下,requiresOnDeviceRecognition 仅适用于 iOS 13、macOS Catalina 及更高版本的设备。它需要 Apple 的 A9 或新的处理器,在 iOS 中 iPhone6s 及以上设备支持。
4.3 创建 SFSpeechRecognitionTask
SFSpeechRecognitionTask 是用来运行 SFSpeechAudioBufferRecognitionRequest 和 SFSpeechRecognizer. 这里有 block 和 delegate 两种方式,下面这个例子是使用了 block 方式,它回调了一个 result,我们通过 result 访问不同的语音属性。bestTranscription 标识置信度最高的一个选项
recognitionTask = speechRecognizer?.recognitionTask(with: recognitionRequest) { result, error in
// 处理识别结果
if let result = result {
DispatchQueue.main.async {
let transcribedString = result.bestTranscription.formattedString
self.transcribedText.text = (transcribedString)
}
}
// 异常处理
if error != nil {
self.audioEngine.stop()
inputNode.removeTap(onBus: 0)
self.recognitionRequest = nil
self.recognitionTask = nil
}
}
4.4 SFVoiceAnalytics
SFVoiceAnalytics 是新引入的类,它包含一组语音指标,用于跟踪语音结果中的音高、闪烁和抖动等特征。 可以从 transcription 的 segments 属性访问它们:
for segment in result.bestTranscription.segments {
guard let voiceAnalytics = segment.voiceAnalytics else { continue }
let pitch = voiceAnalytics.pitch
let voicing = voiceAnalytics.voicing.acousticFeatureValuePerFrame
let jitter = voiceAnalytics.jitter.acousticFeatureValuePerFrame
let shimmer = voiceAnalytics.shimmer.acousticFeatureValuePerFrame
}
4.5 语音识别
在上面我们提到了四个组件,下面代码看看他整体是如何工作的
private let audioEngine = AVAudioEngine()
private var recognitionRequest: SFSpeechAudioBufferRecognitionRequest?
private var speechRecognizer = SFSpeechRecognizer(locale: Locale(identifier: "zh-CN"))
private var recognitionTask: SFSpeechRecognitionTask?
func startRecording() throws {
recognitionTask?.cancel()
self.recognitionTask = nil
let audioSession = AVAudioSession.sharedInstance()
try audioSession.setCategory(.record, mode: .measurement, options: .duckOthers)
try audioSession.setActive(true, options: .notifyOthersOnDeactivation)
let inputNode = audioEngine.inputNode
inputNode.removeTap(onBus: 0)
let recordingFormat = inputNode.outputFormat(forBus: 0)
inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) { (buffer: AVAudioPCMBuffer, when: AVAudioTime) in
self.recognitionRequest?.append(buffer)
}
audioEngine.prepare()
try audioEngine.start()
recognitionRequest = SFSpeechAudioBufferRecognitionRequest()
guard let recognitionRequest = recognitionRequest else { fatalError("Unable to create a SFSpeechAudioBufferRecognitionRequest object") }
// 分部返回结果,每次识别完成就会回调部分结果
recognitionRequest.shouldReportPartialResults = true
if #available(iOS 16, *) {
// iOS 16 已经支持自动添加标点符号,不需要再喊标点符号了
recognitionRequest.addsPunctuation = true
}
if #available(iOS 13, *) {
if speechRecognizer?.supportsOnDeviceRecognition ?? false{
recognitionRequest.requiresOnDeviceRecognition = true
}
}
recognitionTask = speechRecognizer?.recognitionTask(with: recognitionRequest) { result, error in
if let result = result {
DispatchQueue.main.async {
// 获取置信度最高的 transcription,并格式化为字符串
let transcribedString = result.bestTranscription.formattedString
self.transcribedText.text = (transcribedString)
}
}
if error != nil {
self.audioEngine.stop()
inputNode.removeTap(onBus: 0)
self.recognitionRequest = nil
self.recognitionTask = nil
}
}
}
上面的代码比较长,我们讲解一下上面的代码中:
-
在按开始录音识别的时,先取消任何先前的识别任务。
-
使用 SFSpeechRecognizer 和 SFSpeechAudioBufferRecognitionRequest 创建识别任务 SFSpeechRecognitionTask。
-
设置 shouldReportPartialResults 为 true 可以允许在识别期间访问中间结果。
-
result.bestTranscription 会返回具有最高置信度的识别转录,formattedString 属性会给出转录文本。
-
还可以访问其他属性,例如 speakingRate、averagePauseDuration或 segments 等等。
5. 总结
这基本上就是通过麦克风将语音识别为文本的整个过程了,所使用的 SFSpeechAudioBufferRecognitionRequest是 SFSpeechRecognitionRequest 的子类,它还有另外一个子类 SFSpeechURLRecognitionRequest,它可以通过本地录音文件路径进行识别,有兴趣的自己可以再看一下。
由于再实际应用场景中,还有可能使用第三方 SDK 来提供 AudioBuffer 音频信息的,而我们的示例是使用 AVAudioEngine 来提供 AudioBuffer ,其实也可以通过 recognitionRequest 自己添加 buffer,如果有遇到的可以试一试。