【计算机网络:自顶向下方法】
3.1 概述

- 传输层协议是在端系统中实现的
- 传输层将发送的应用程序进程接受到的报文转换成传输层分组 (运输层报文段)
- 实现的方法/过程 : 将应用报文划分为较小的块,并为每块加上传输层首部以生成传输层报文段
ff。 IP服务模型 :best-effort delivery serice;- 它确保文段的交付,不保证报文段的按序交付,不保证报文段中数据的完整性,故
ip被称为不可靠服务

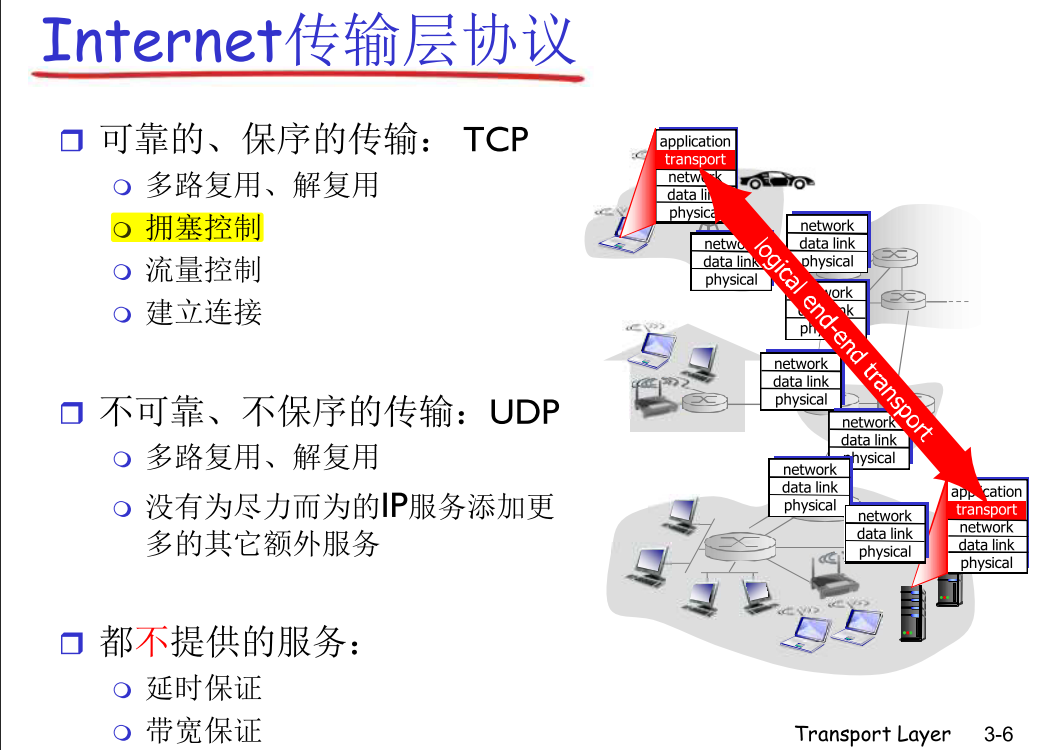
3.2 多路复用和多路分解
视 频 链 接
-
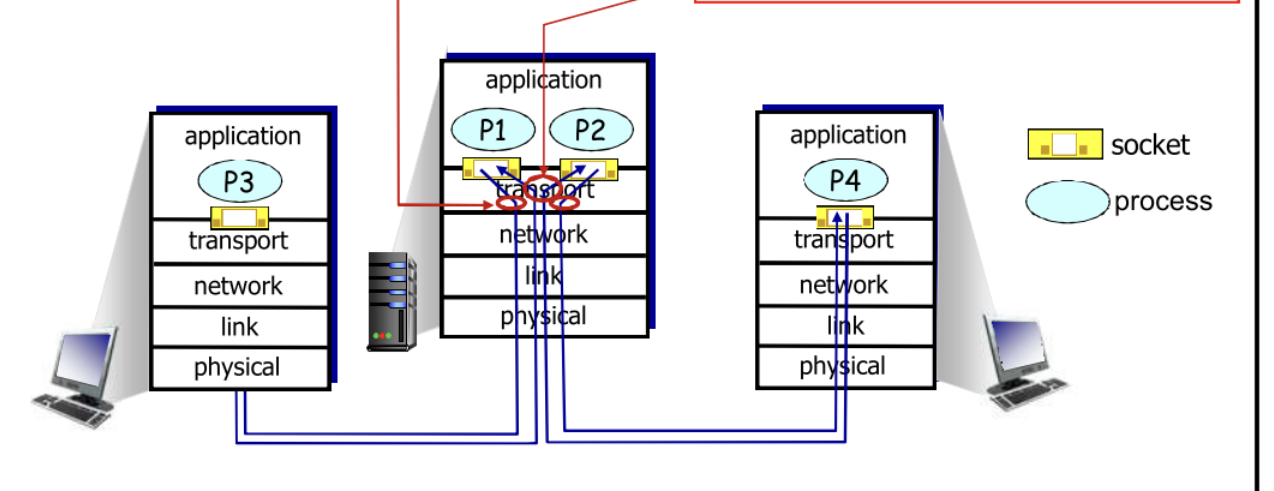
这里的复用是指多个应用层协议使用一个传输层传数据 [应用层 - 》 传输层 (在传输层复用)]
-
多路分解 (解复用 )是指一个传输层把不同的数据正确交付给不同应用 [传输层 - 》 其他层 (在其他层解复用)]
-
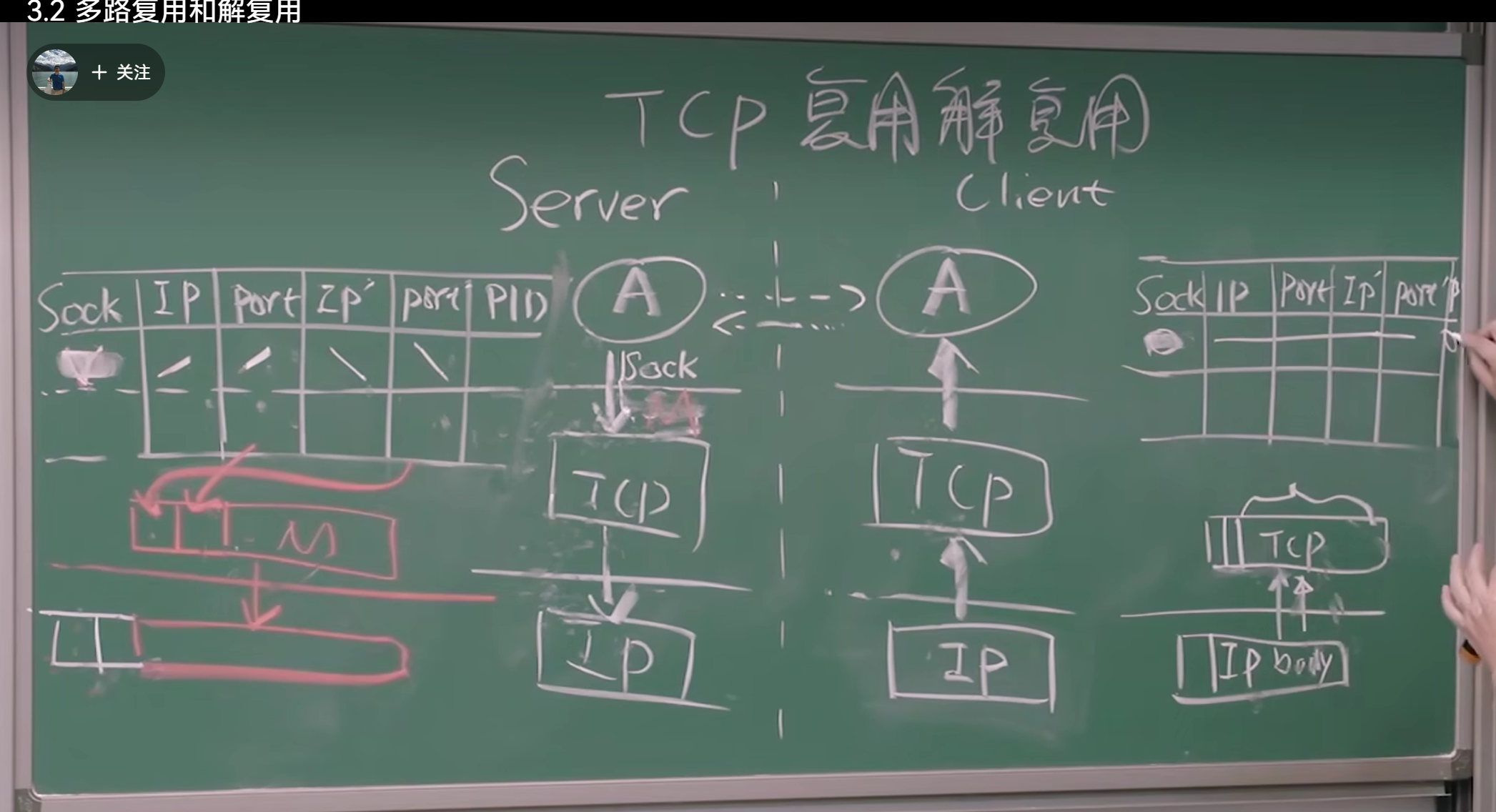
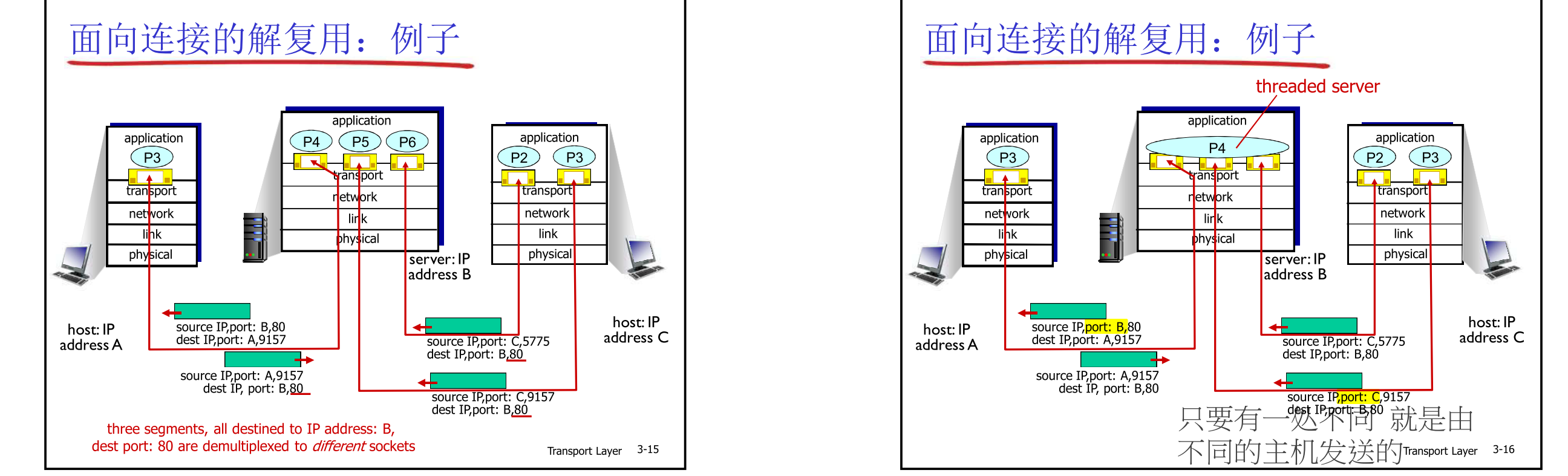
将运输层报文段中的数据交付到正确的套接字的工作称为多路分解 ( demultiplexing)。在源主机从不同套接字中收集数据块,并为每个数据块封装上首部信息(这将在以后用于分解)从而生成报文段,然后将报文段传递到网络层,所有这些工作称为多路复用 ( nmhiplexing) 。

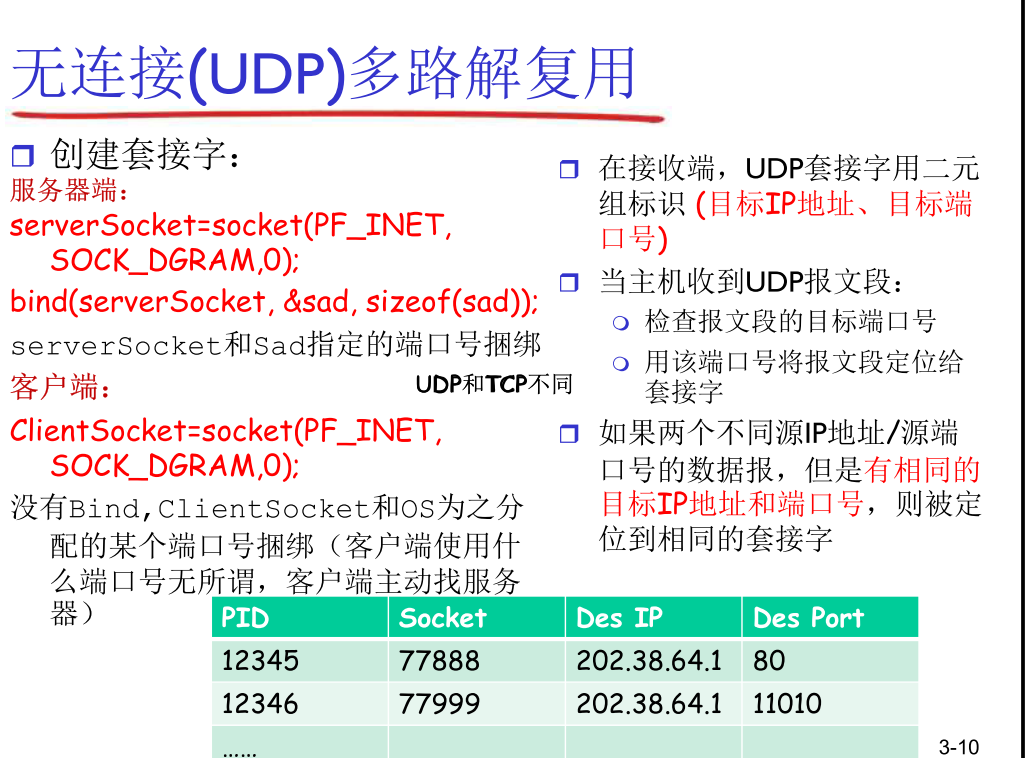
无连接(UDP) 多路复用 & 解复用
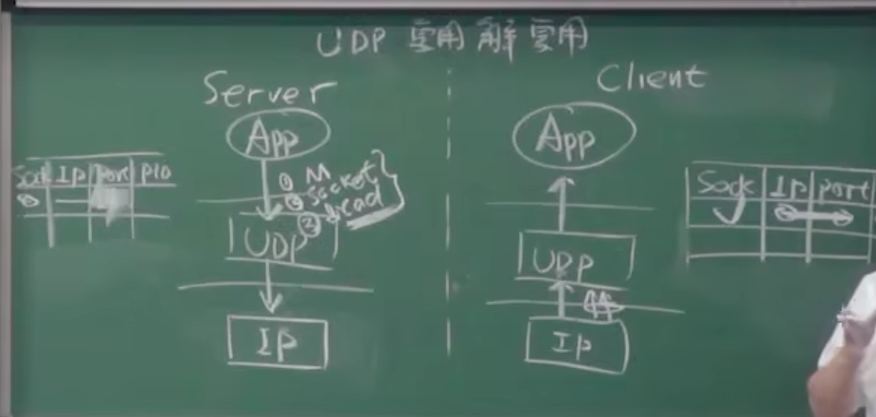
- 注意 : 绑定关系

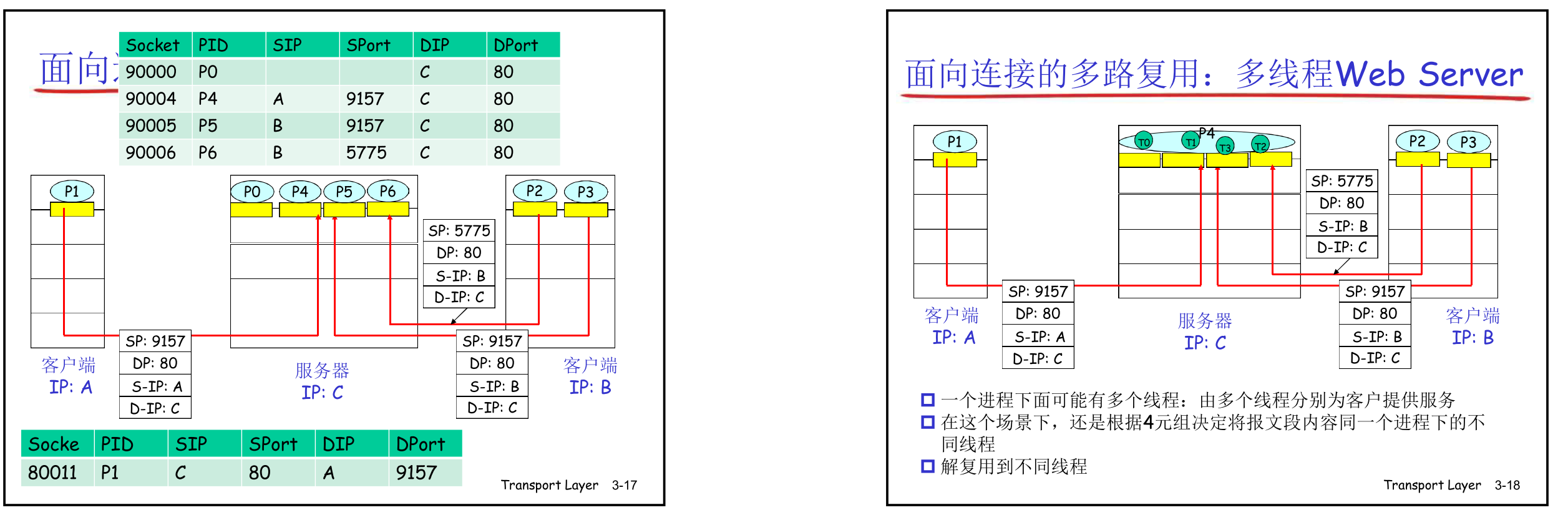
TCP 复用 & 解复用

3.3无连接服务 : UDP
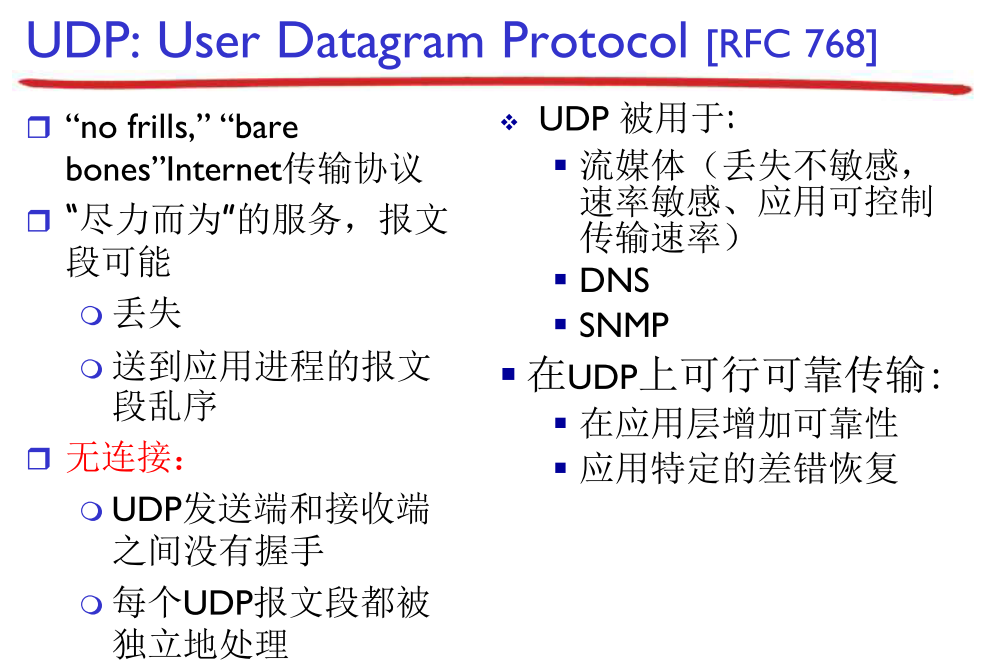
UDP除了实现了复用/分用功能和简单的错误校验外,几乎没有对 IP 增加别的东西;UDP 提供尽力而为交付服务服务,UDP段可能丢失、非按序到达;UDP是无连接的,发送方和接收方之间不需要握手,每个UDP段的处理独立于其他段。
TCP提供可靠数据传输和拥塞控制,为什么还需要UDP呢?UDP有以下好处:
- 应用可更好地控制发送时间和速率
- 无需建立连接 (减少延迟减少延迟)。这也可能是DNS使用UDP而不是TCP的主要原因,如果使用TCP的话,DNS服务将会慢很多。
- 无需维护连接状态:
TCP为了实现可靠数据传输和拥塞控制需要在端系统中维护一些参数,这些参数包括:接收和发送的缓存、拥塞控制参数、确认号和序号;这些参数信息都是必须的;而UDP因为不建立连接,所以自然也就不需要维护这些状态,这就减少了时空开销; - 分组首部更小:
TCP有20字节的首部开销,而UDP只有8字节;
udp报文结构

UDP首部只有4个字段,每个字段占用两个字节,分别是:源端口号、目的端口号、长度和校验和;长度字段指示了在 UDP 报文段中的字节数(首部加数据)。接收方使用检验和来检查在该报文段中是否出现了差错。
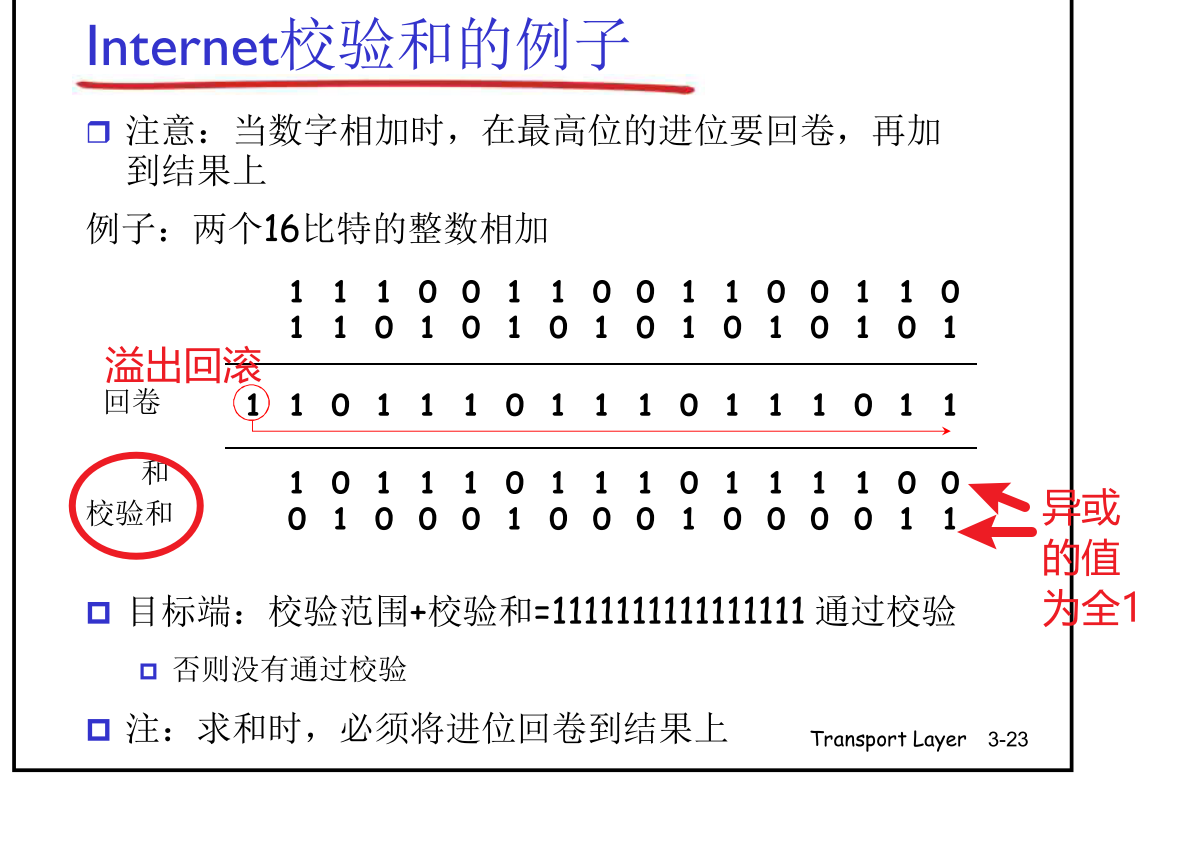
UDP校验和

出错就丢弃
3.4 可靠数据传输原理 (Principles of reliable data transfer, rdt)
- 对应用层、传输层、链路层都很重要
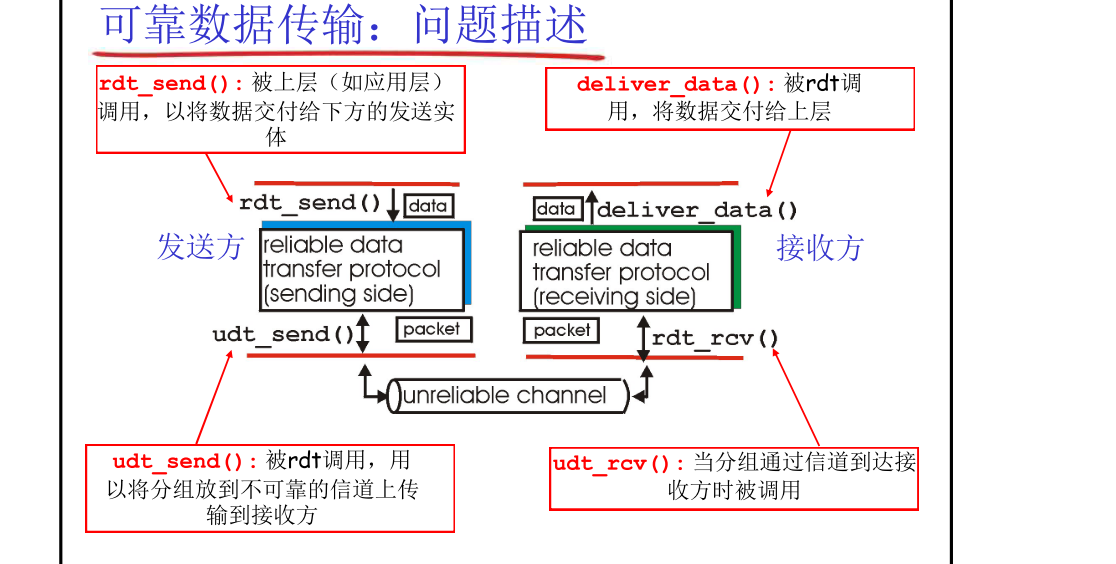
- 不可靠信道的特点决定了不可靠传输协议的复杂度
- 与不可靠信道之间的函数调用都是双向的,由于其不可靠性,需要进行确认的控制信号(ACK,NAK)。
rdt1.0:经可靠信道的可靠数据传输
rdt1.0有限状态机
-
下层信道完全可靠:rdt1.0中假设下层的信道是一个完全可靠的信道(理想情况)
- 没有bit的错误
- 没有分组(packet)丢失
-
发送方和接收方的 有限状态机(FSM) (存在状态和操作)
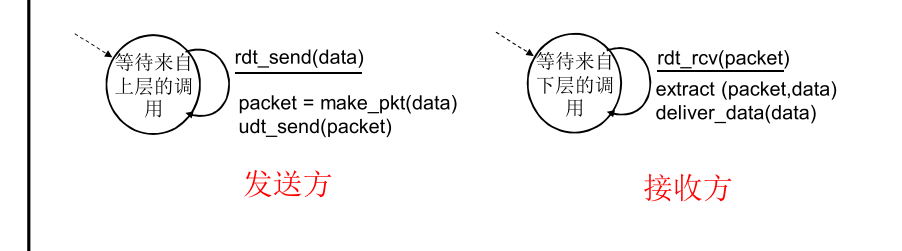
- 发送方发送数据给下层信道 , 接收方接收下层信道传来的数据
发送方首先在“等待上级调用”的状态,rdt_send(data)上级调用rdt,从上级接收到data,make_pkt(data)将data装到packet里,再用udt_send(packet)将packet发送出去,完成后发送方再回到“等待上级调用”的状态。(发送方只有一个状态)
- 发送方发送数据给下层信道 , 接收方接收下层信道传来的数据
接收方首先在“等待下级调用”的状态,rdt_rcv(packet)下级调用rdt,从下级接收到packet,用extract(packet, data)将packet重新恢复成data,提取出来的data再通过deliver_data(data)传送给上级。完成后接收方再回到“等待下级调用”的状态。
- 下层信道不可能完全可靠 => 引入rdt2.0
rdt2.0:经具有比特差错信道的数据传输
引入差错检测、控制信号和重传机制,解决下层信道不可靠问题。
rdt2.0概述
- packet在下层信道传输中会出现比特翻转:可以引入**校验和(checksum)**来检测比特错误。
- 错误恢复——如果检验到错误如何恢复?
- ACKs(acknowledgements):接收方告诉发送方收到的pkt是正确的
- NAKs(negative acknowledgements):接收方告诉发送方收到的pkt是错误的
- 发送方收到NAK则重传那个pkt
- rdt2.0引入的新机制
- 差错检测:checksum
- 接收方反馈:控制信号(control msg),即ACK和NAK
- 重传
rdt2.0无限状态机
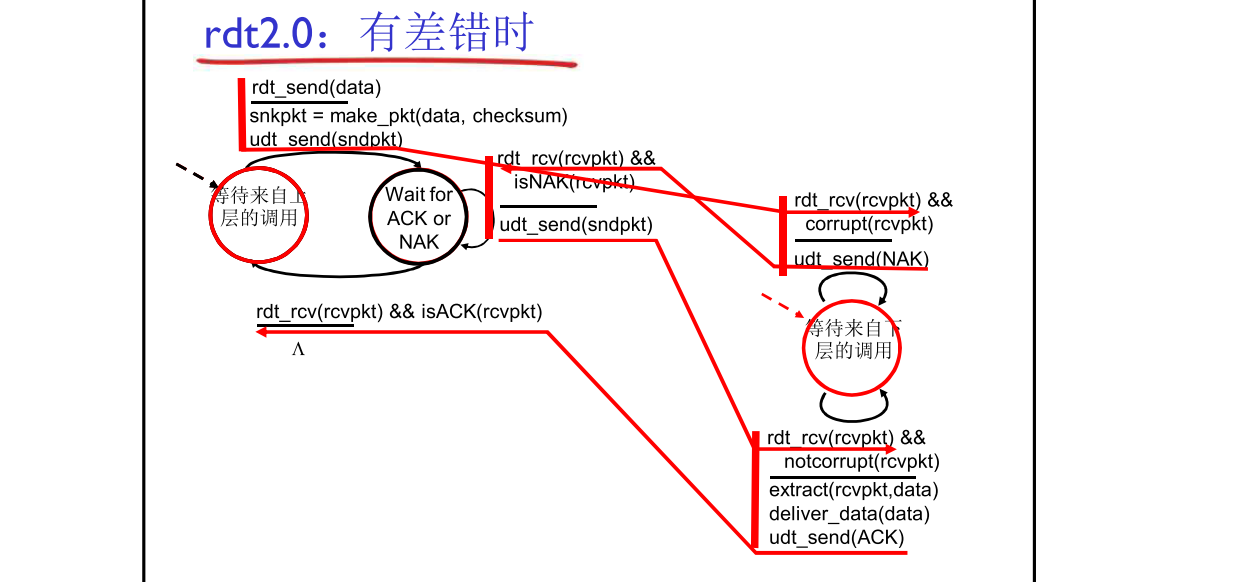
发送方
rdt2.0的发送方有2个状态——等待上级调用、等待ACK或NAK。发送方最初处于“等待上级调用”的状态,rdt_send(data)上级调用rdt,从上级接收到data,sndpkt = make_pkt(data, checksum)将data装到packet里,再用udt_send(sndpkt)将packet发送出去。此时,发送方变为“等待ACK或NAK”的状态。rdt_rcv(rcvpkt)接收反馈,如果isNAK(rcvpkt)即接收到NAK,则重传udt_send(sndpkt),并保持“等待ACK或NAK”的状态;如果isACK(rcvpkt)即接收到ACK,则回到“等待上级调用”的状态。
- 停等机制(
stop and wait) - 发送方发送一个
packet,然后等待接收方的响应。
接收方
接收方还是只有一个状态——等待下级调用。接收方首先在“等待下级调用”的状态,rdt_rcv(rcvpkt)接收方接收packet,如果corrupt(rcvpkt),即检测到错误,则udt_send(NAK)反馈NAK;如果notcorrupt(rcvpkt),即未检测到错误,则extract(packet, data)将packet重新恢复成data,deliver_data(data)将data传送给上级,最后udt_send(ACK)反馈ACK。完成后接收方再回到“等待下级调用”的状态。
问题
接收方可能判断ACK/NAK信号出错,导致发送分组冗余
- 缺乏技术 : 差错检测 、 接收方反馈、重传 .
rdt2.1:接收方判断ACK/NAK信号出错
引入0/1序号和丢弃分组,解决接收方判断ACK/NAK信号出错,导致发送分组重复问题。但这也让发送方和接收方有限状态机的状态翻倍。
rdt2.1有限状态机
发送方
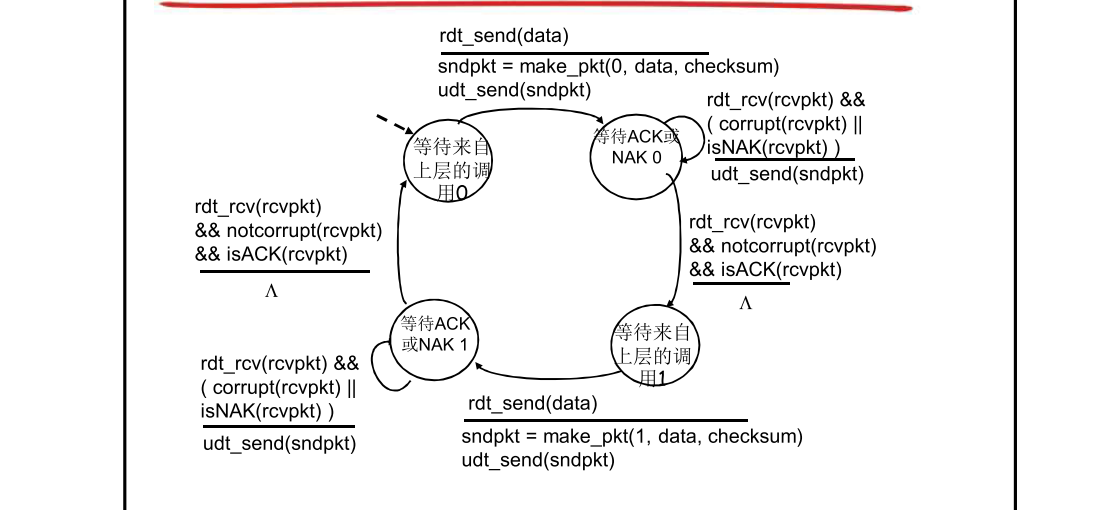
相较于rdt2.0,rdt2.1在发送的packet里包含了0/1序号(sequence number),所以发送方有4种状态——等待上级调用 0、等待ACK或NAK 0、等待上级调用 1、等待ACK或NAK 1。
接收方
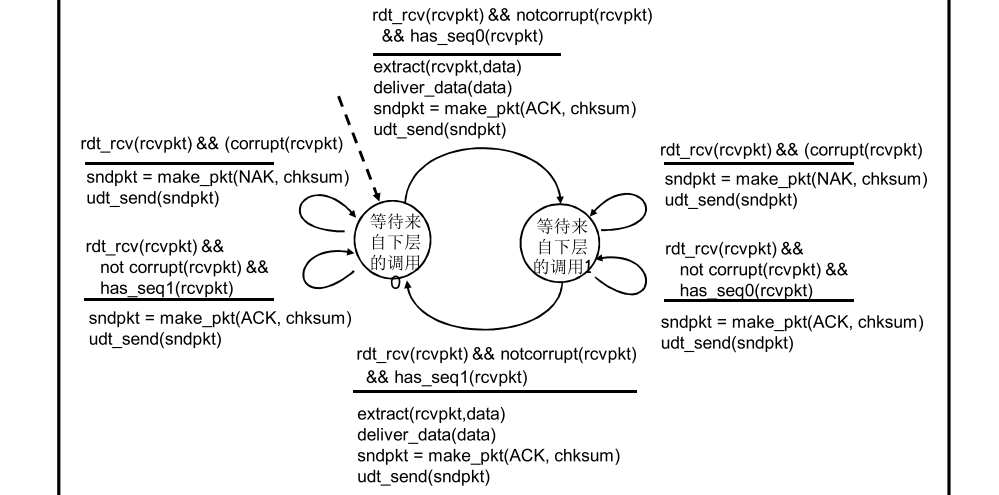
接收方有2种状态——等待下级调用 0、等待下级调用 1。只有在数据包ACK且收到的packet序号与目前状态等待的序号相同时,才能向上传输。
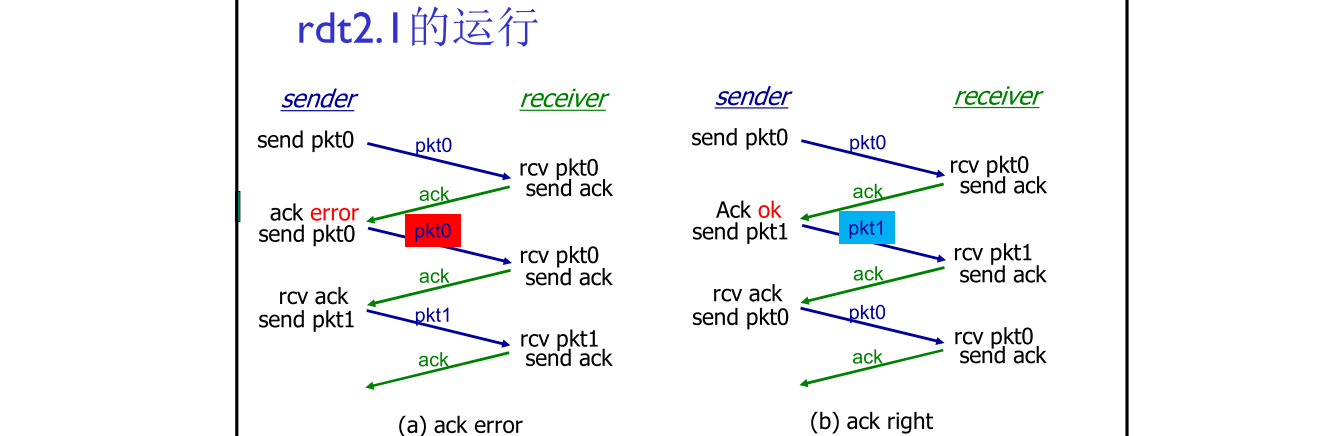
为什么接收方等待1状态接收到0的packet时,为什么要反馈ACK?
发送方不对收到的ack/nak给确认,没有所谓的确认的确认
rdt2.2:不发送(free) NAK的协议
- 用重复的ACK替代NAK,解决信号冗余问题。
rdt2.2概述
- 只用ACK,不用NAK,实现和rdt2.1一样的功能。
- 在检测到错误时,不发送NAK,但是接收方要发送判断上一次序号的ACK(同时包括序号)
- 用重复的ACK代替NAK
rdt2.2有限状态机
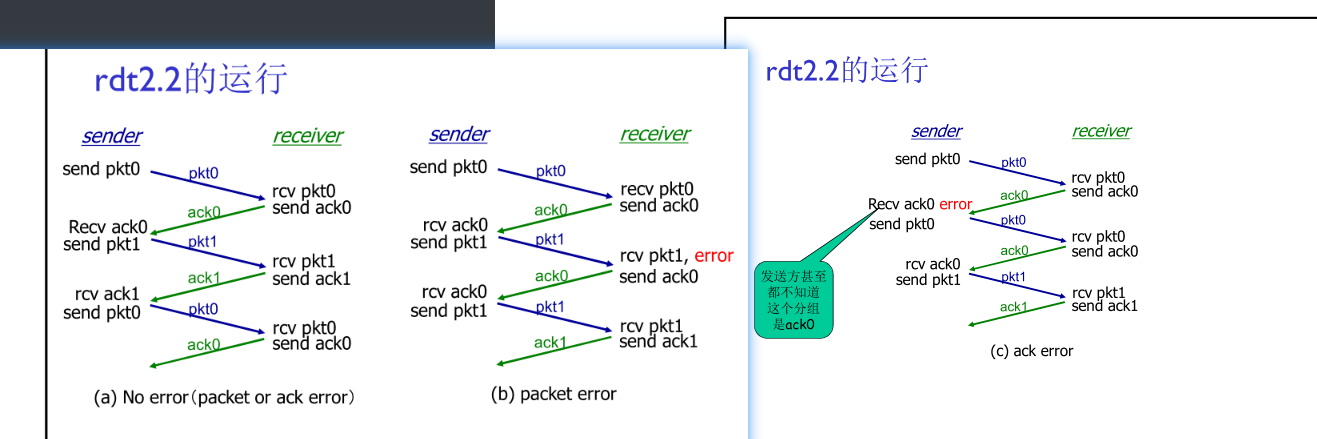
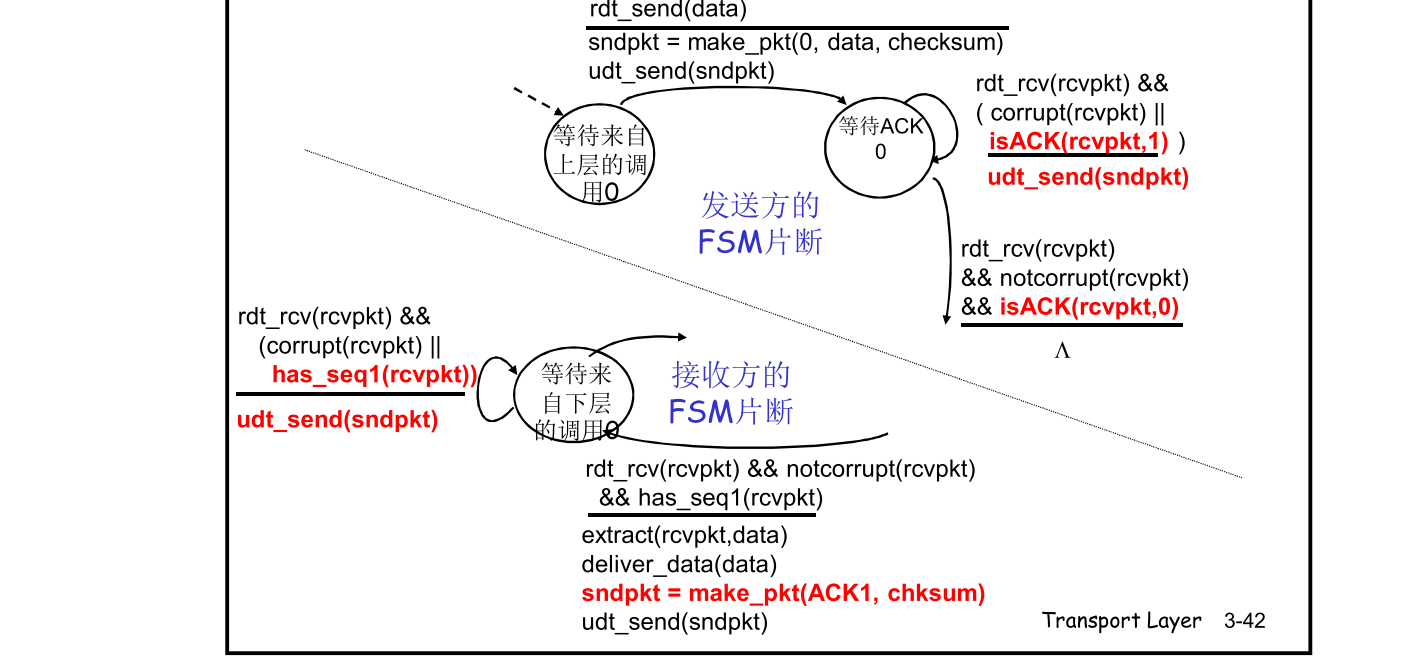
- 发送方 将rdt2.1中的
isNAK(rcvpkt)判断本次反馈是NAK,替代成判断上次序号的反馈是ACK,比如rdt2.2在“等待ACK 0”时,如果isACK(rcvpkt, 1),则相当于收到来rdt2.1中的isNAK(rcvpkt)。其余不变。 - 接收方如果校验和检测出错,则发送上一次序号的ACK;在校验和检测正确时,发送ACK也需要带上本次的序号。
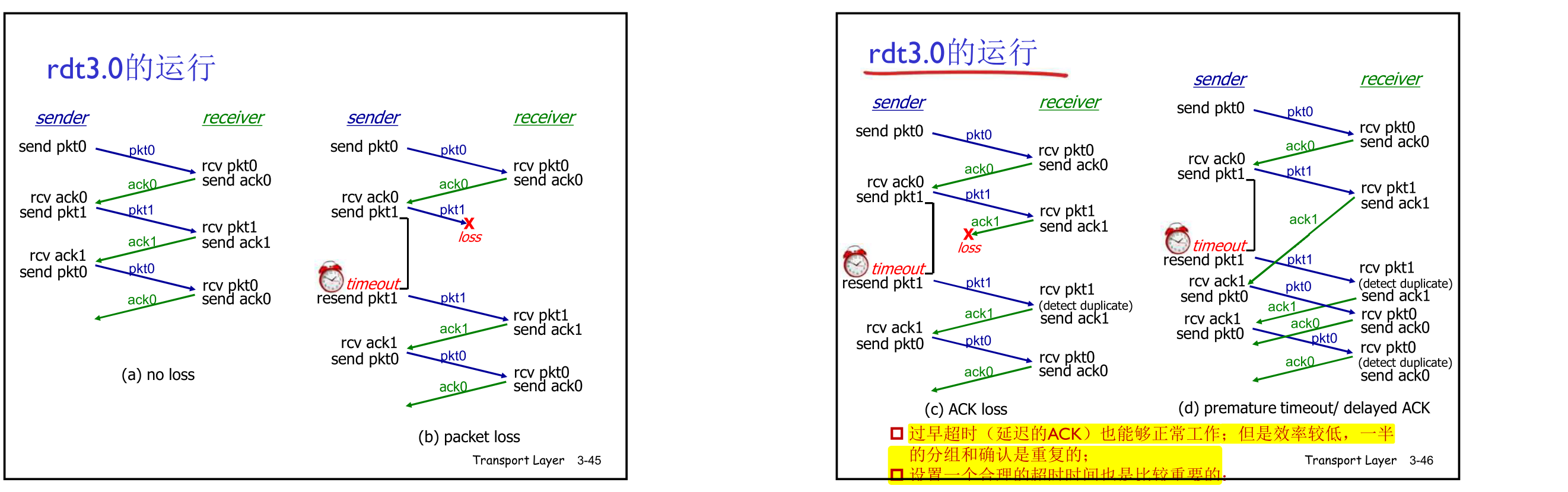
rdt3.0:信道存在错误和丢包
方法:发送方等待ACK一段 合理的时间 (链路层的timeout时间确定的 传输层timeout时间是适应式的)
- 发送端超时重传:如果到时没有 收到ACK->重传 (防止死锁产生)
- 问题:如果分组(
或ACK)只 是被延迟了:- 重传将会导致数据重复,但 利用序列号已经可以处理这 个问题
- 接收方必须指明被正确接收 的序列号
- 需要一个倒计数定时器
rdt3.0有限状态机
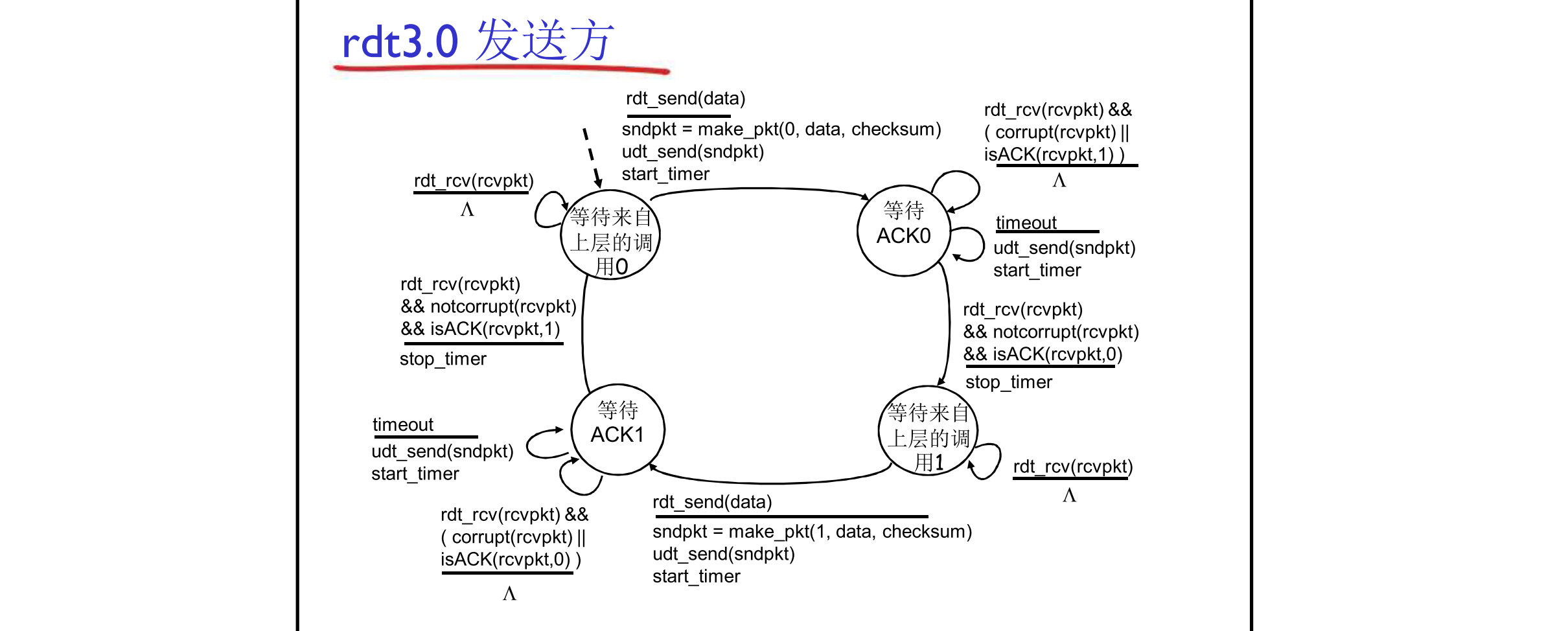
发送方传输开始时,start_timer启动计时器。如果timeout传输超时,则重新启动计时器;如果在规定时间内接收到反馈,则stop_timer结束计时。
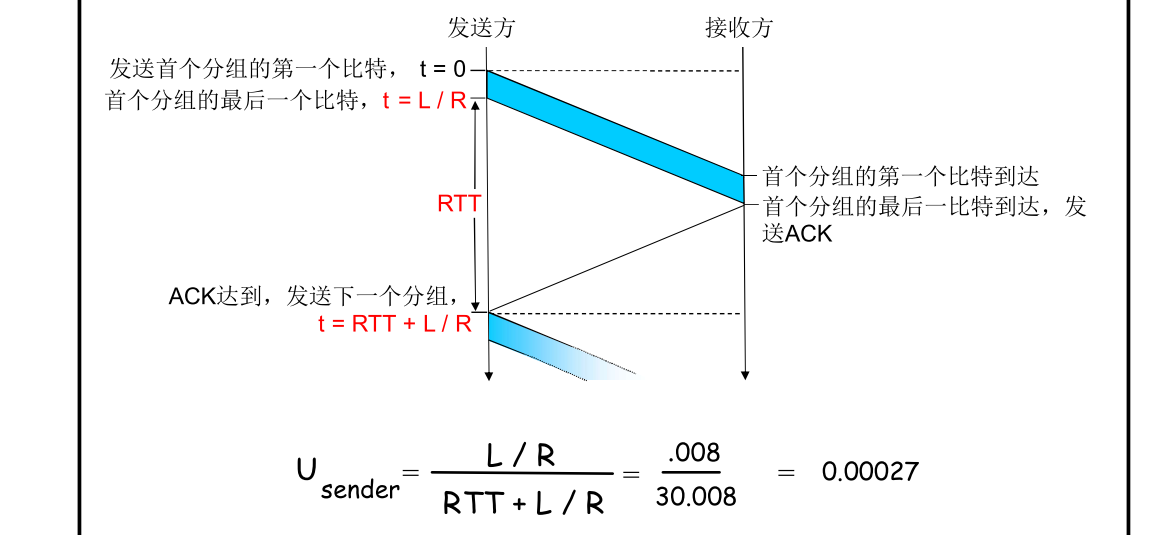
rdt3.0性能

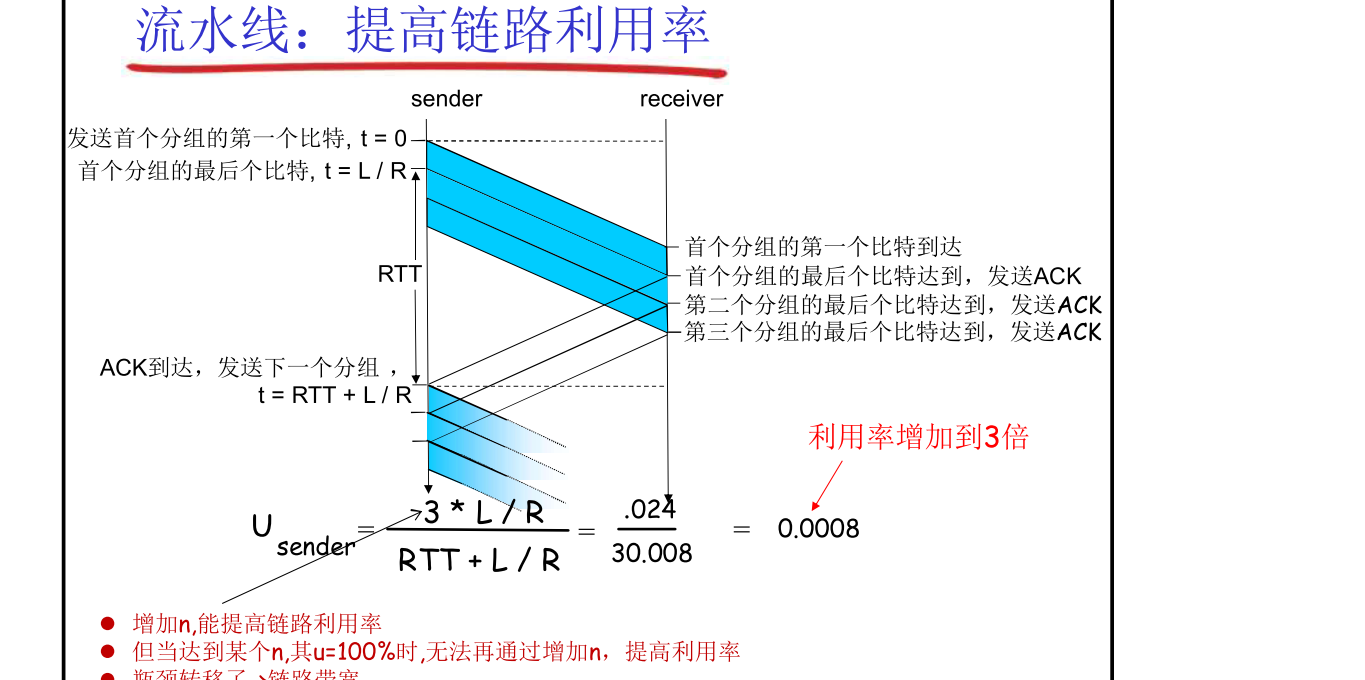
流水线协议
采用流水线的机制,不要等一个RTT发送回来再发下一个(即不再采用停等机制),来提高物理资源的使用率。
-
停等机制(Stop-and-wait)
-
流水线机制(Pipelined Operation)
滑动窗口协议:
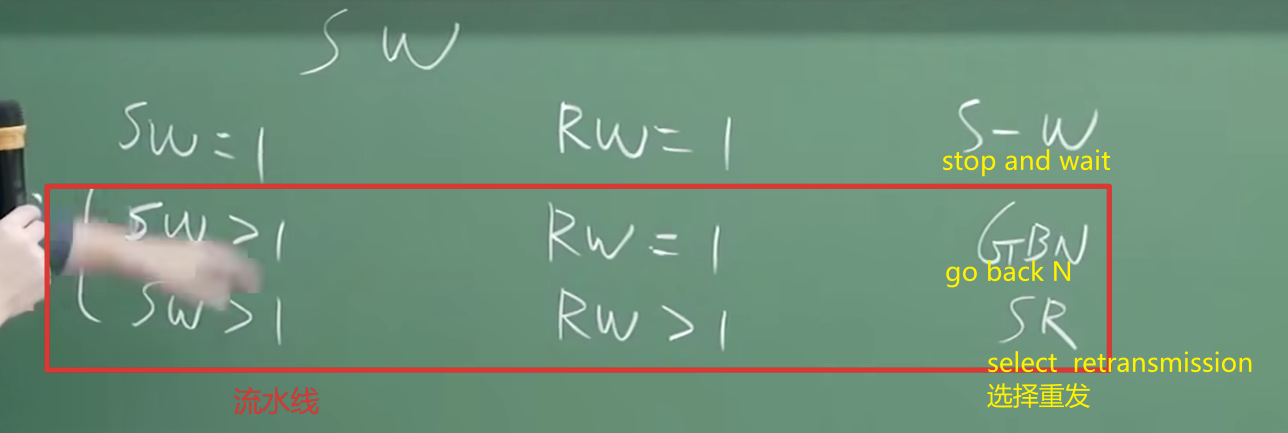
更正 : selective repeat SR SW size windows
sw > 1 流水线协议 sw = 1停止流水线协议sw发送窗口rw接受窗口
回退N步(Go-back-N,GBN)
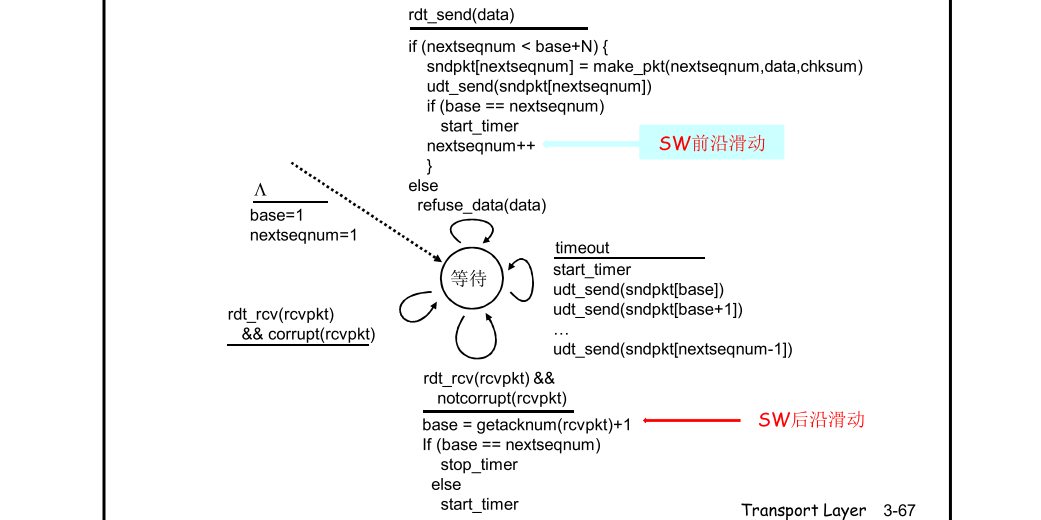
Go-back-N: 发送端最多在流水线 中有N个未确认的分 组
接收端只是发送累计 型确认cumulative ack 接收端如果发现gap, 不确认新到来的分组
发送端拥有对最老的 未确认分组的定时器 只需设置一个定时器 当定时器到时时,重 传所有未确认分组
GBN发送方
-
packet头部有
k bit的序号,则可以表示 2k2� 个序号。 -
“窗口”大小为
N,这一段是允许的未ACK的packet -
ACK(n)累计确认:ACK在发送的时候要带上序号#n,即#n及之前的packet都收到了。接收方发送ACK n,则证明#n及之前的packet都收到了。否则接收方还是发送之前的ACK(重复)。
-
计时器只给最早的未ACK的packet保留
-
如果timeout(n),重传#n以及比#n更大的未ACK的packet
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4RYdcgcM-1682166861126)(https://raw.githubusercontent.com/GY23333/imgs/master/Network_GBN-sender(1)].png)
GBN接收方
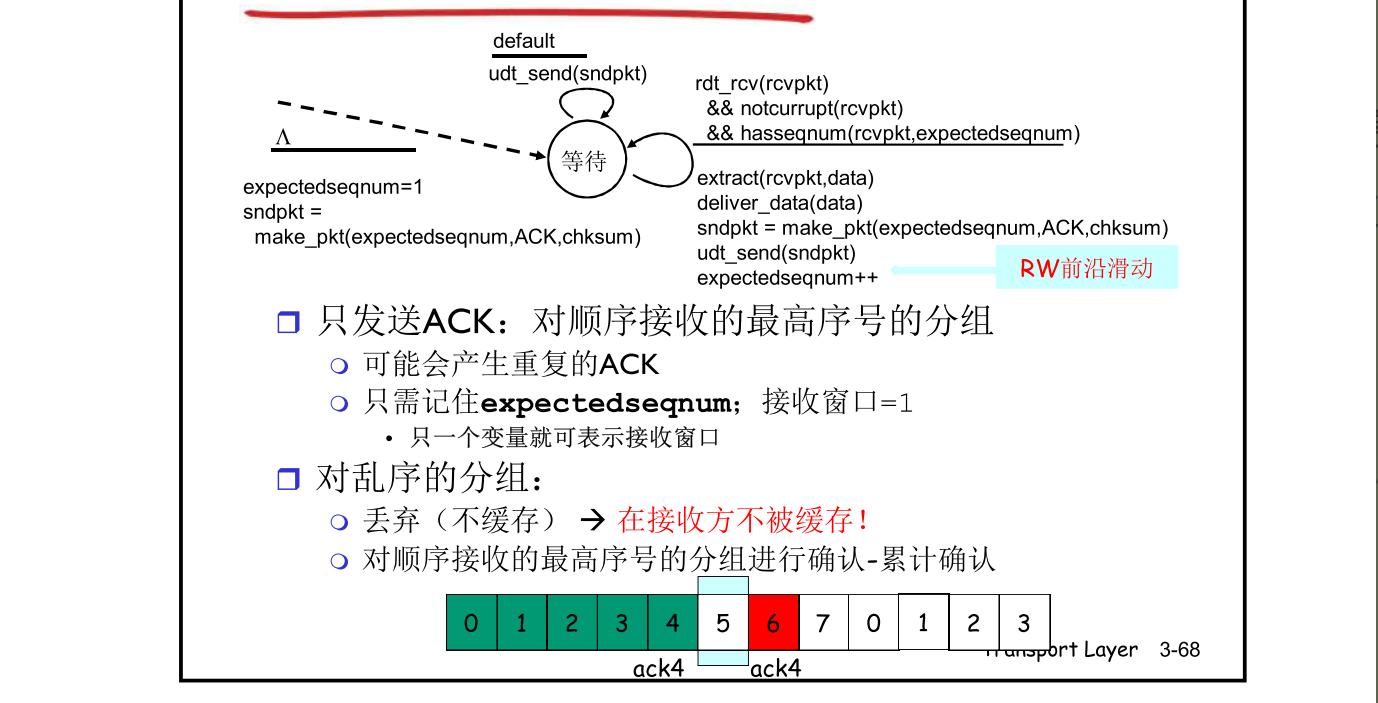
- 发送的ACK是顺序接收到的packet里面最大的序列号#
- 可能会产生重复的ACK
- 只需要记住期望的序列号(expextedseqnum)
- 乱序到达的packet
- 直接丢弃,不缓存(缓存会造成数据重复)
- 重新发送顺序最大序列号#
GBN运行
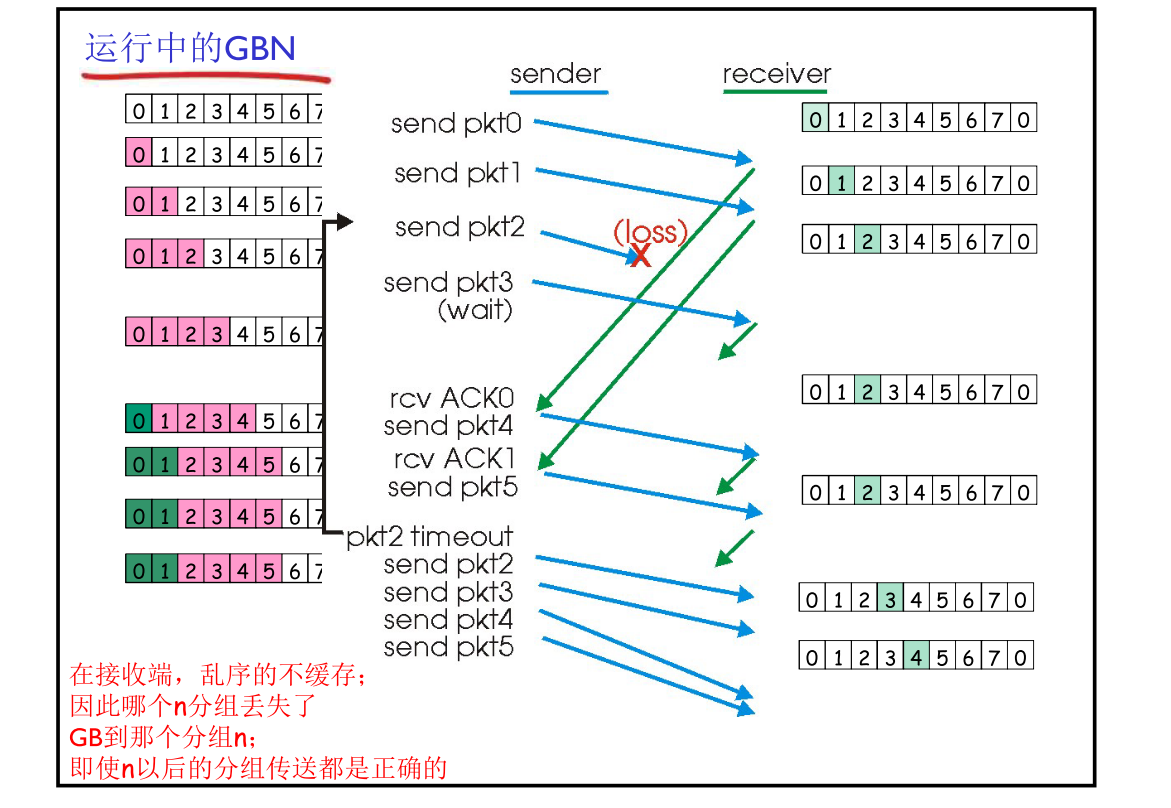
重发#2 ~ #5 的 packet。
选择重传(Selective Repeat,SR)
Selective Repeat:
发送端最多在流水线中 有N个未确认的分组
接收方对每个到来的分 组单独确认individual ack (非累计确认)
发送方为每个未确认的 分组保持一个定时器 当超时定时器到时,只是 重发到时的未确认分组
v
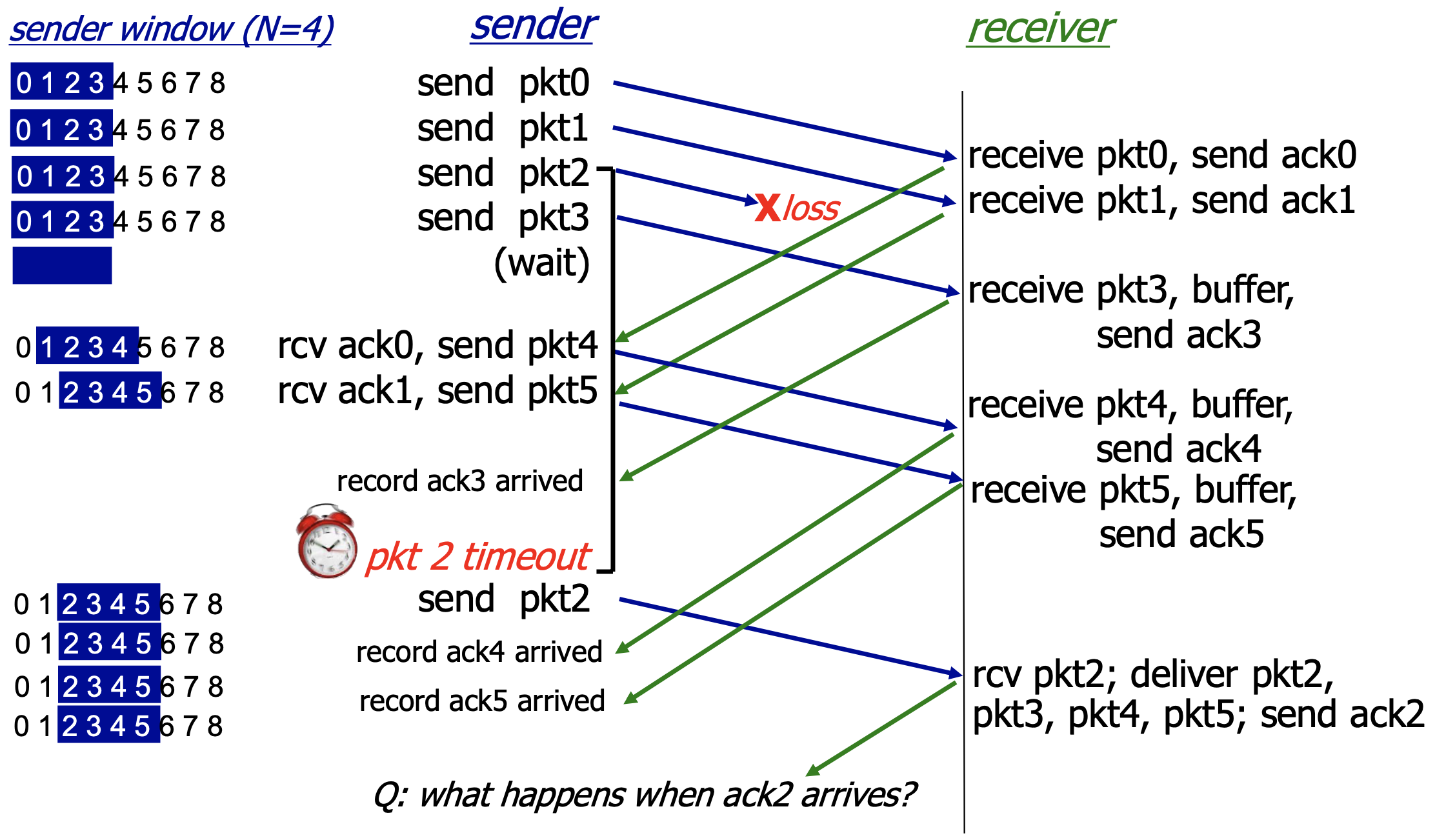
SR困境
比如下面序列号有:#0, #1, #2, #3,window大小为3的情况。SR会无法分清a、b两种情况,导致在b中误判重发的第一轮的pkt0,被当作后一轮的pkt0填入。
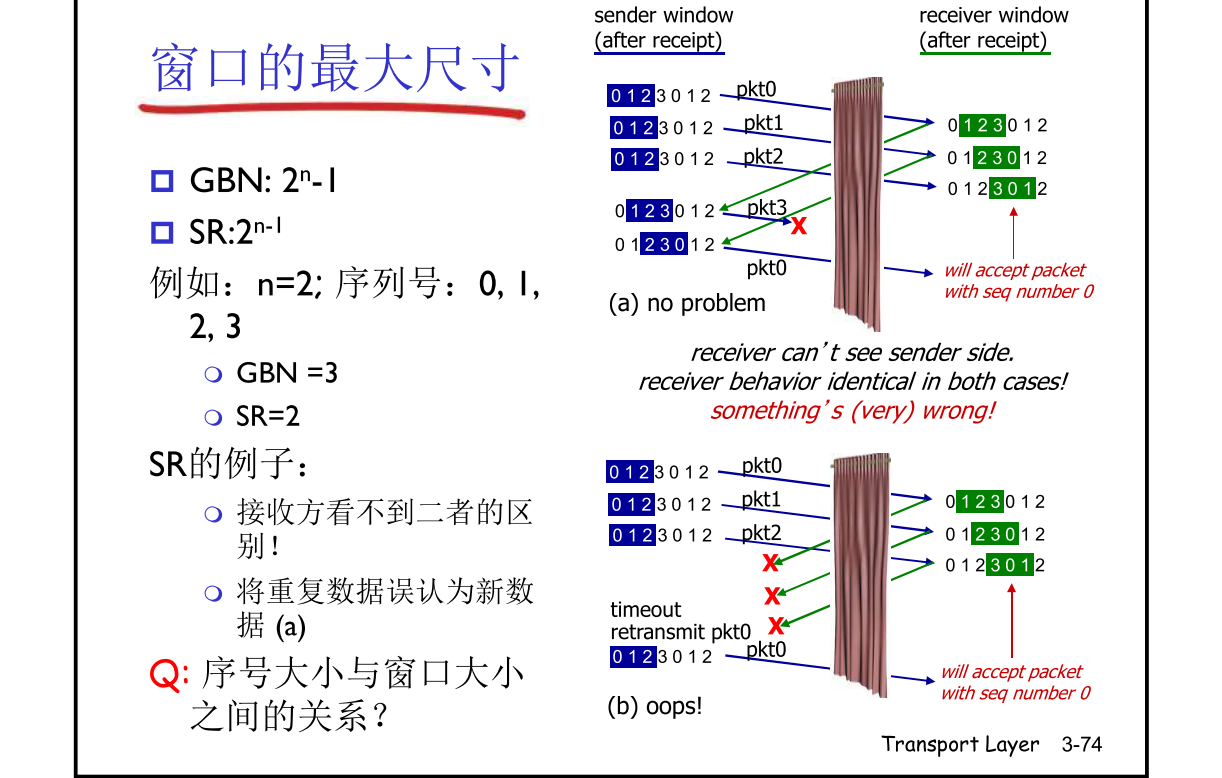
对比 GBN & SR

3.5 面向连接的传输: TCP
- 点对点(point-to-point):一个发送方、一个接收方
- 可靠的、有序的字节流
- 没有消息的边界
- 流水线机制
- 窗口大小由拥塞和流量控制
- 全双工
- 同时双向数据流
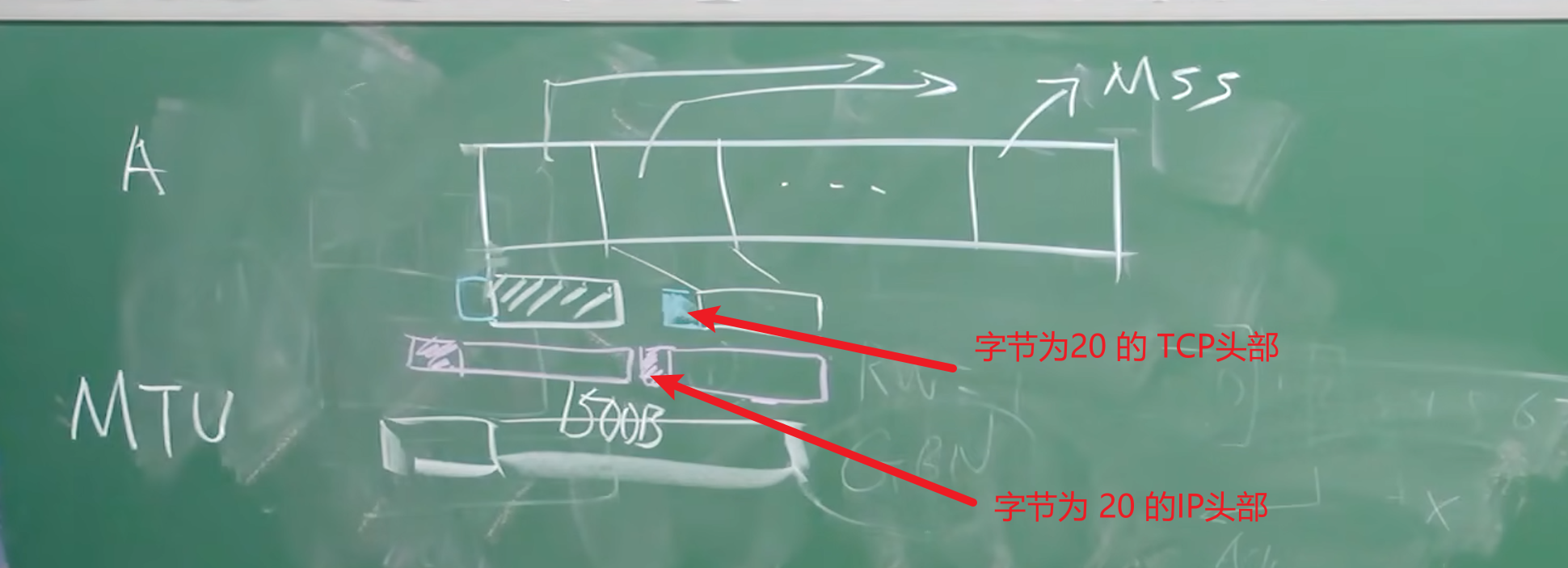
- MSS(maximum segment size):最大报文段长度
- 面向连接
- 握手:交换控制信息,初始化发送方和接收方的状态
- 流量控制
TCP报文段结构
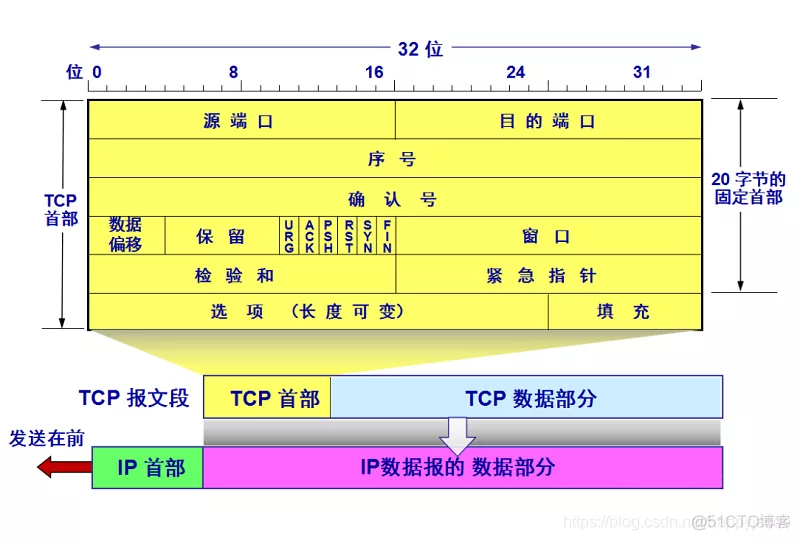
1、端口号:用来标识同一台计算机的不同的应用进程。
- 源端口:源端口和IP地址的作用是标识报文的返回地址。
- 目的端口:端口指明接收方计算机上的应用程序接口。
TCP报头中的源端口号和目的端口号同IP数据报中的源IP与目的IP唯一确定一条TCP连接。
2、序号和确认号:是TCP可靠传输的关键部分。序号是本报文段发送的数据组的第一个字节的序号。在TCP传送的流中,每一个字节一个序号。e.g.一个报文段的序号为300,此报文段数据部分共有100字节,则下一个报文段的序号为400。所以序号确保了TCP传输的有序性。确认号,即ACK,指明下一个期待收到的字节序号,表明该序号之前的所有数据已经正确无误的收到。确认号只有当ACK标志为1时才有效。比如建立连接时,SYN报文的ACK标志位为0。
3、数据偏移/首部长度:4bits。由于首部可能含有可选项内容,因此TCP报头的长度是不确定的,报头不包含任何任选字段则长度为20字节,4位首部长度字段所能表示的最大值为1111,转化为10进制为15,15*32/8 = 60,故报头最大长度为60字节。首部长度也叫数据偏移,是因为首部长度实际上指示了数据区在报文段中的起始偏移值。
4、保留:为将来定义新的用途保留,现在一般置0。
5、控制位:URG ACK PSH RST SYN FIN,共6个,每一个标志位表示一个控制功能。
- URG:紧急指针标志,为1时表示紧急指针有效,为0则忽略紧急指针。
- ACK:确认序号标志,为1时表示确认号有效,为0表示报文中不含确认信息,忽略确认号字段。
- PSH:push标志,为1表示是带有push标志的数据,指示接收方在接收到该报文段以后,应尽快将这个报文段交给应用程序,而不是在缓冲区排队。
- RST:重置连接标志,用于重置由于主机崩溃或其他原因而出现错误的连接。或者用于拒绝非法的报文段和拒绝连接请求。
- SYN:同步序号,用于建立连接过程,在连接请求中,SYN=1和ACK=0表示该数据段没有使用捎带的确认域,而连接应答捎带一个确认,即SYN=1和ACK=1。
- FIN:finish标志,用于释放连接,为1时表示发送方已经没有数据发送了,即关闭本方数据流。
6、窗口:滑动窗口大小,用来告知发送端接受端的缓存大小,以此控制发送端发送数据的速率,从而达到流量控制。窗口大小时一个16bit字段,因而窗口大小最大为65535。
7、校验和:奇偶校验,此校验和是对整个的 TCP 报文段,包括 TCP 头部和 TCP 数据,以 16 位字进行计算所得。由发送端计算和存储,并由接收端进行验证。
8、紧急指针:只有当 URG 标志置 1 时紧急指针才有效。紧急指针是一个正的偏移量,和顺序号字段中的值相加表示紧急数据最后一个字节的序号。 TCP 的紧急方式是发送端向另一端发送紧急数据的一种方式。
9、选项和填充:最常见的可选字段是最长报文大小,又称为MSS(Maximum Segment Size),每个连接方通常都在通信的第一个报文段(为建立连接而设置SYN标志为1的那个段)中指明这个选项,它表示本端所能接受的最大报文段的长度。选项长度不一定是32位的整数倍,所以要加填充位,即在这个字段中加入额外的零,以保证TCP头是32的整数倍。
10、数据部分: TCP 报文段中的数据部分是可选的。在一个连接建立和一个连接终止时,双方交换的报文段仅有 TCP 首部。如果一方没有数据要发送,也使用没有任何数据的首部来确认收到的数据。在处理超时的许多情况中,也会发送不带任何数据的报文段。
TCP序号
报文段(segment)的序号:字节流第一个字节的序号
例题:下面文件的前3个报文段的序号分别是?
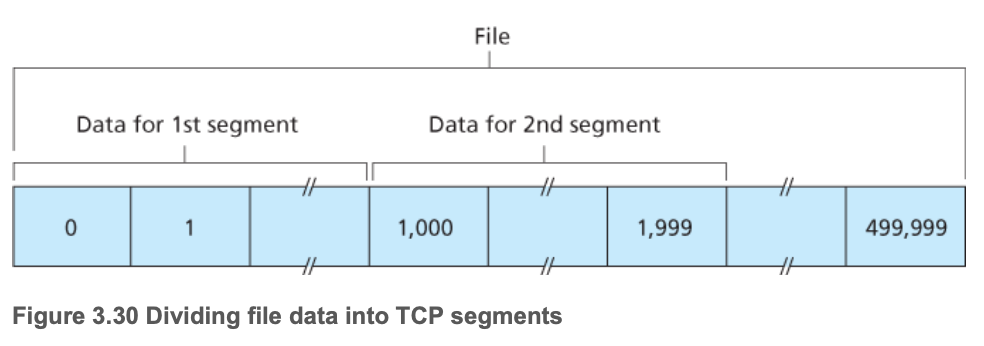
第一个报文段:0;第二个报文段:1000;第三个报文段:2000
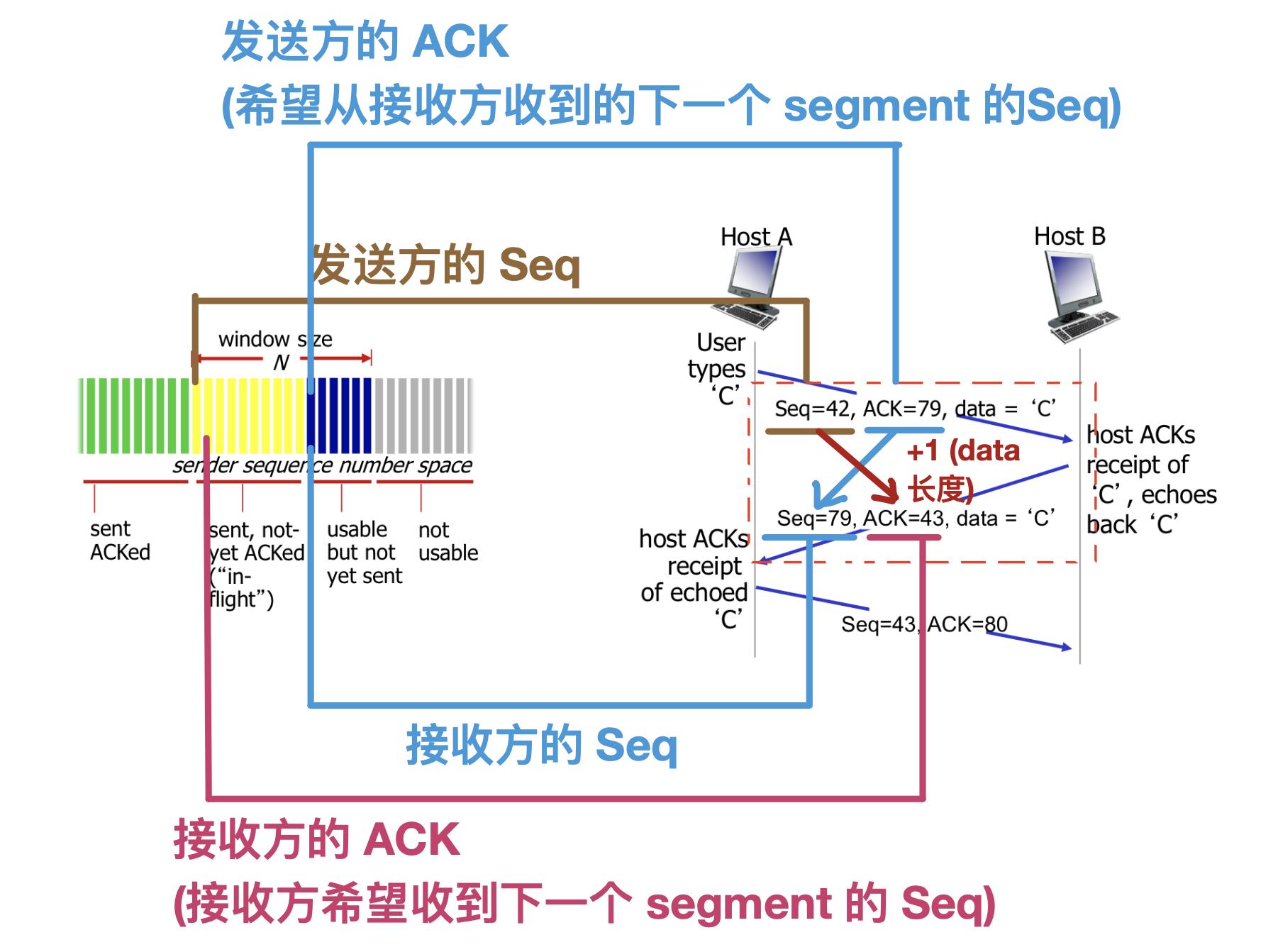
TCP ACK
- TCP报文的ACK填写:期望从另一方收到的下一个字节序号 (确认号)
- 主机A接收到从主机B传来的字节0~535,A下一个期望接到的字节为536,所以主机A发送的报文段的ACK中填536。
- 累计ACK(cumulative ACK):与GBN相似
- 主机A接收到从主机B传来的字节 0~535 和 900~1000,A下一个期望接到的字节依旧为536,所以主机A下一个发送的报文段的ACK中填536。
TCP 序号和ACK传输
TCP计时
Q: 怎样设置TCP 超时?
比RTT要长 :但RTT是变化的
太短:太早超时 : 不必要的重传
太长:对报文段丢失 反应太慢,消极
如何EstimateRTT(估计RTT)?
SampleRTT:测量从报文段发出到 收到确认的时间 : 如果有重传,忽略此次测量
SampleRTT会变化,因此估计的 RTT应该比较平滑 : 对几个最近的测量值求平均,而不是仅用当前的SampleRTT
设置的时间间隔 (数学 看不懂 就是套公式) : 推荐值: & = 0.25 概率问题

TCP可靠数据传输
- TCP在IP不可靠服务的基础上 建立了rdt
- 管道化的报文段 • GBN or SR
- 累积确认(像GBN)
- 单个重传定时器(像GBN)
- 是否可以接受乱序的,没有规范
通过以下事件触发重传
超时(只重发那个最早的未确认段:SR)
重复的确认
例子:收到了ACK50,之后又收到3 个ACK50 - 首先考虑简化的
TCP发送方: 忽略重复的确认 , 忽略流量控制和拥塞控 制
TCP简化
TCP简化版:无重复ACK、拥塞控制和流量控制。
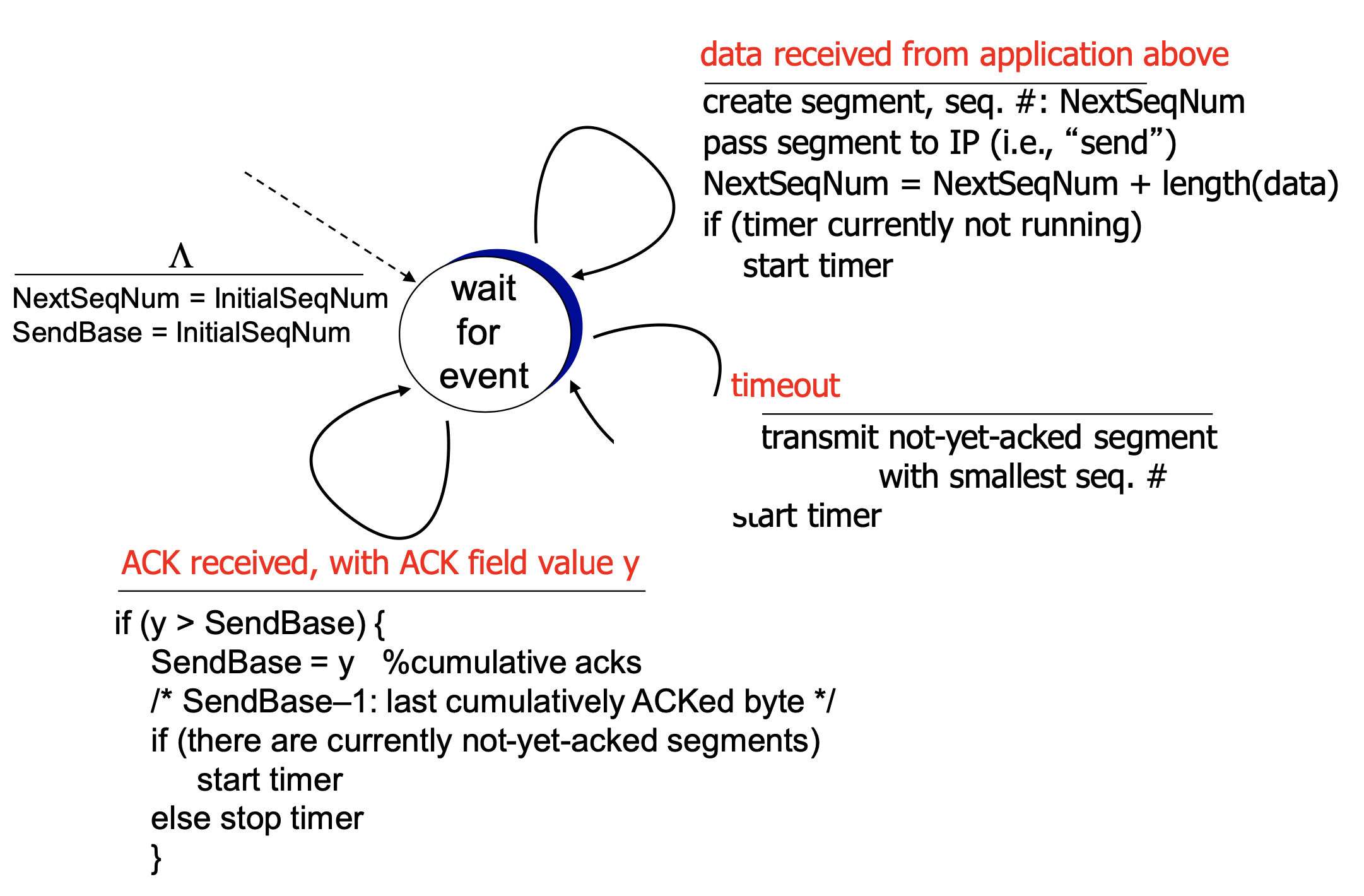
TCP sender
TCP sender 的3种事件
- 从上一层收到数据
- 分段,创建seq#(报文中字节流第一个字节的序号)
- 开始timer
- 只给最早一个未ACK的segment timer
- 用 TimeoutInterval 作为timeout时间
- 超时
- 重传segment
- 重启timer
- 收到ACK
- 如果收到未ACK的segment的ACK
- 更新被ACK的segment标记
- 从最近的一个未ACK的segment开新的timer
- 如果收到未ACK的segment的ACK
TCP sender简化版 :
TCP重传情况
图 ACK丢包
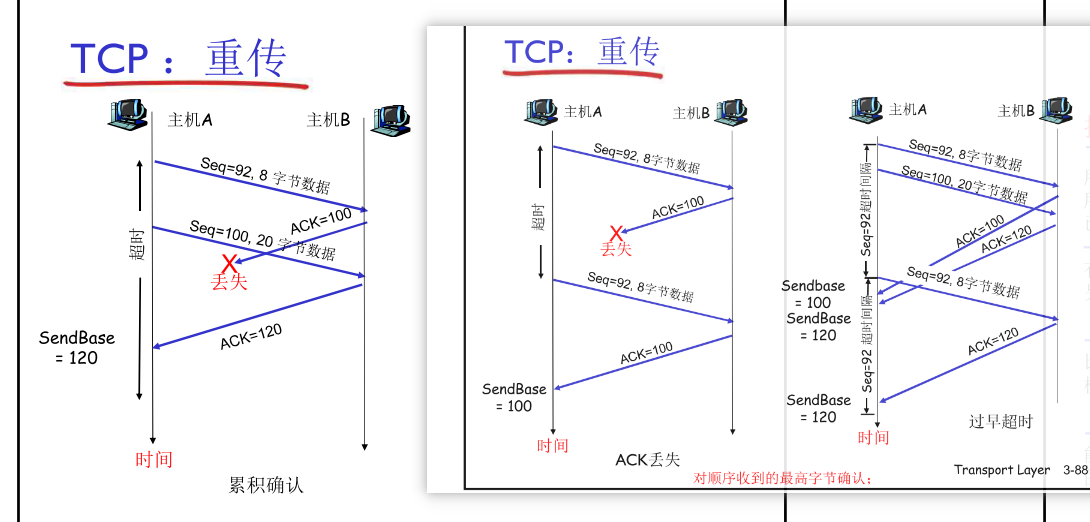
TCP快速重传
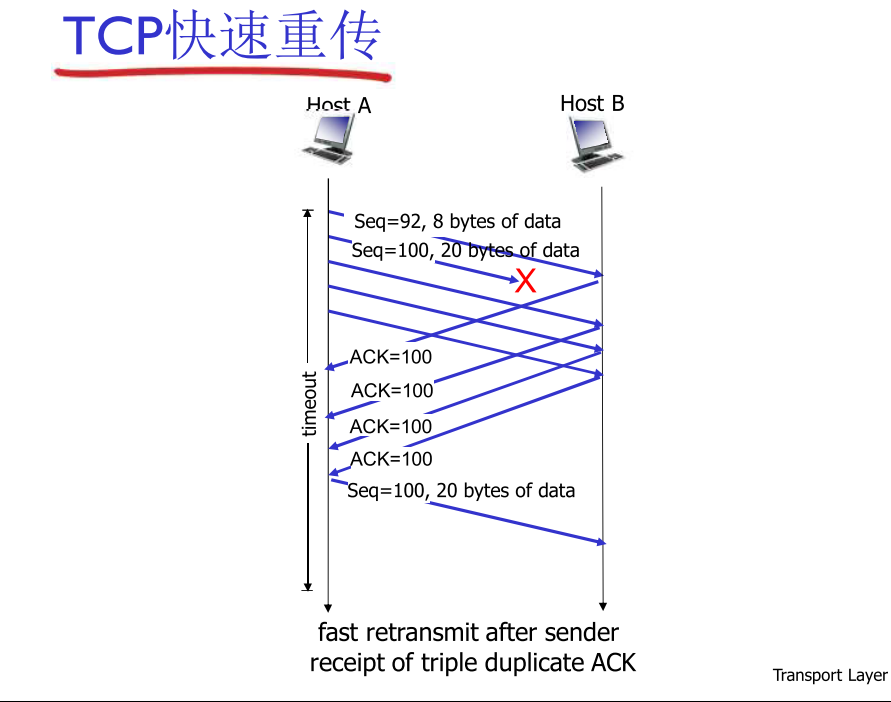
- timeout时间长,造成长时延
- 通过重复的ACK检测丢包
- 发送方会发送很多个segment
- 如果有segment丢失,则可能会收到很多个重复的ACK
TCP快速重传机制:
- 如果发送方收到对同一数据收到3个重复的ACK(实际收到4次该ACK),则认为此时未ACK的segment丢失,不需再等待timeout,重发未ACK的最小seq#
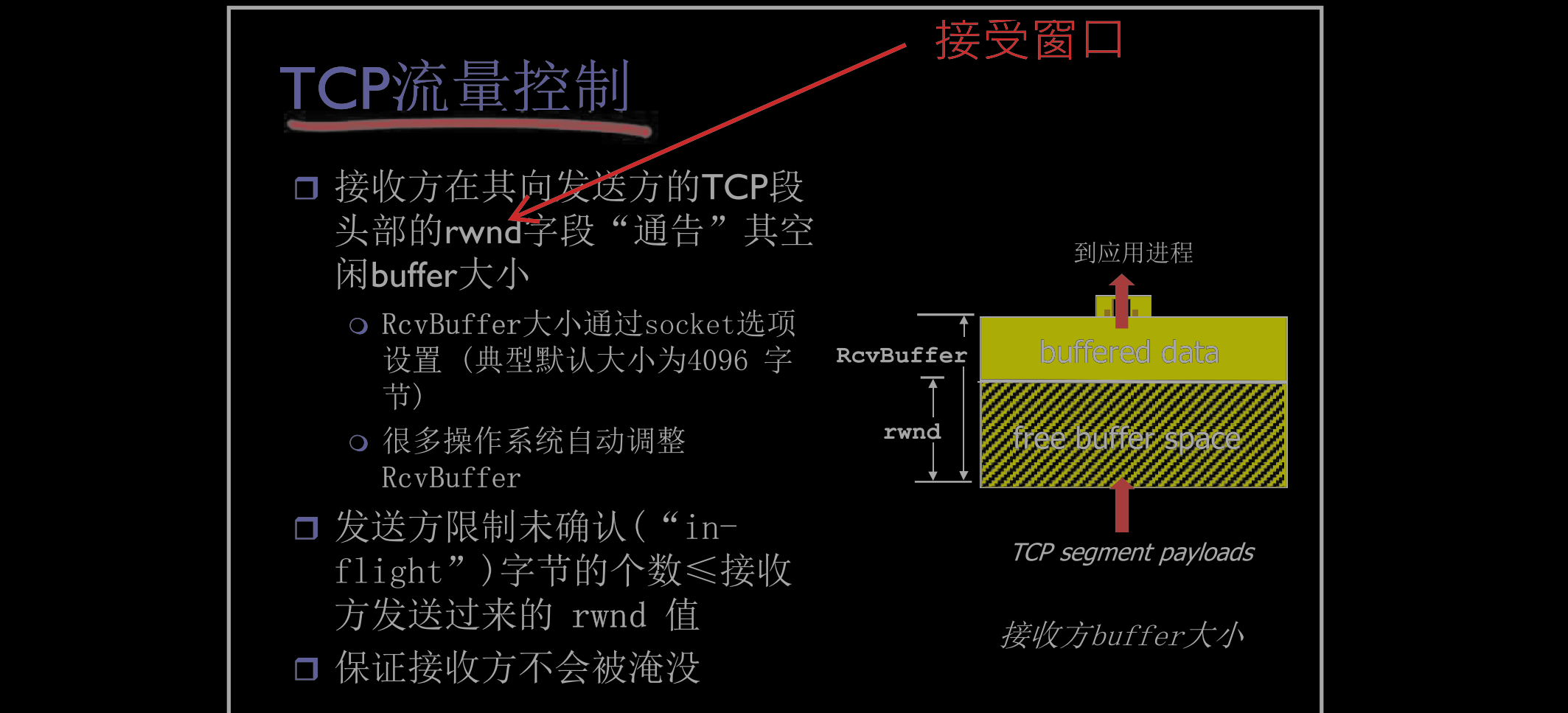
流量控制 rwnd
接收方要控制发送方,使发送方不会发送得太快导致接收方的缓存(buffer)溢出。
- 接收方告诉发送方
free buffer大小,包含在TCP报文的 ```rwnd(receive window`中)- RcvBuffer socket设定大小(一般,4096)
- 一些操作系统也可以自动调节RcvBuffer
接收方缓存 :

sender通过rwnd来限制unacked segment的数量- 保障
receive的buffer不会溢出
如果sender接收到rwnd=0,则说明此时没有剩余buffer,再发送数据会造成receiver buffer溢出,但是有要防止锁住。
所以sender向receiver发送一个1 byte data的报文,以更新rwnd。
连接管理
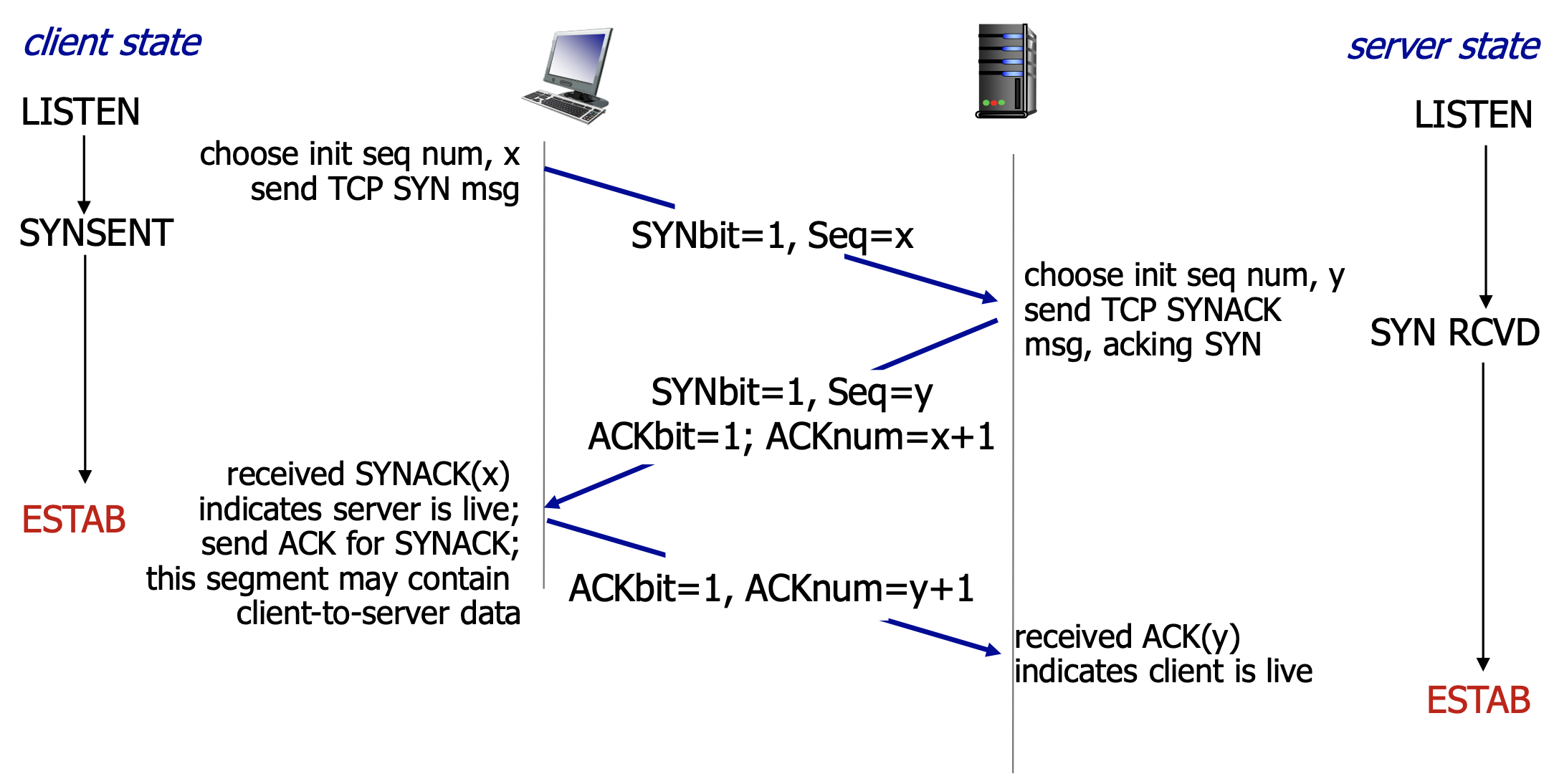
TCP建立连接:3次握手
建立连接之前,先握手
- 双方同意建立连接
- 同意连接的参数
为什么两次握手行不通?
- 各种delay
- 消息丢失导致重传
- 消息乱序
- 相互看不到对方
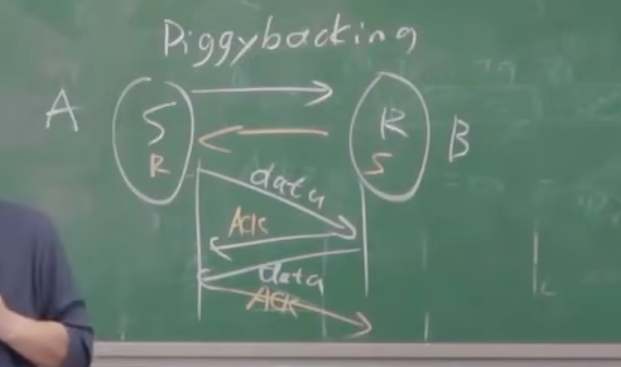
捎带技术 (AYN = 1 & ACK = 1 的时候使用 将俩个合并 ) - 文章
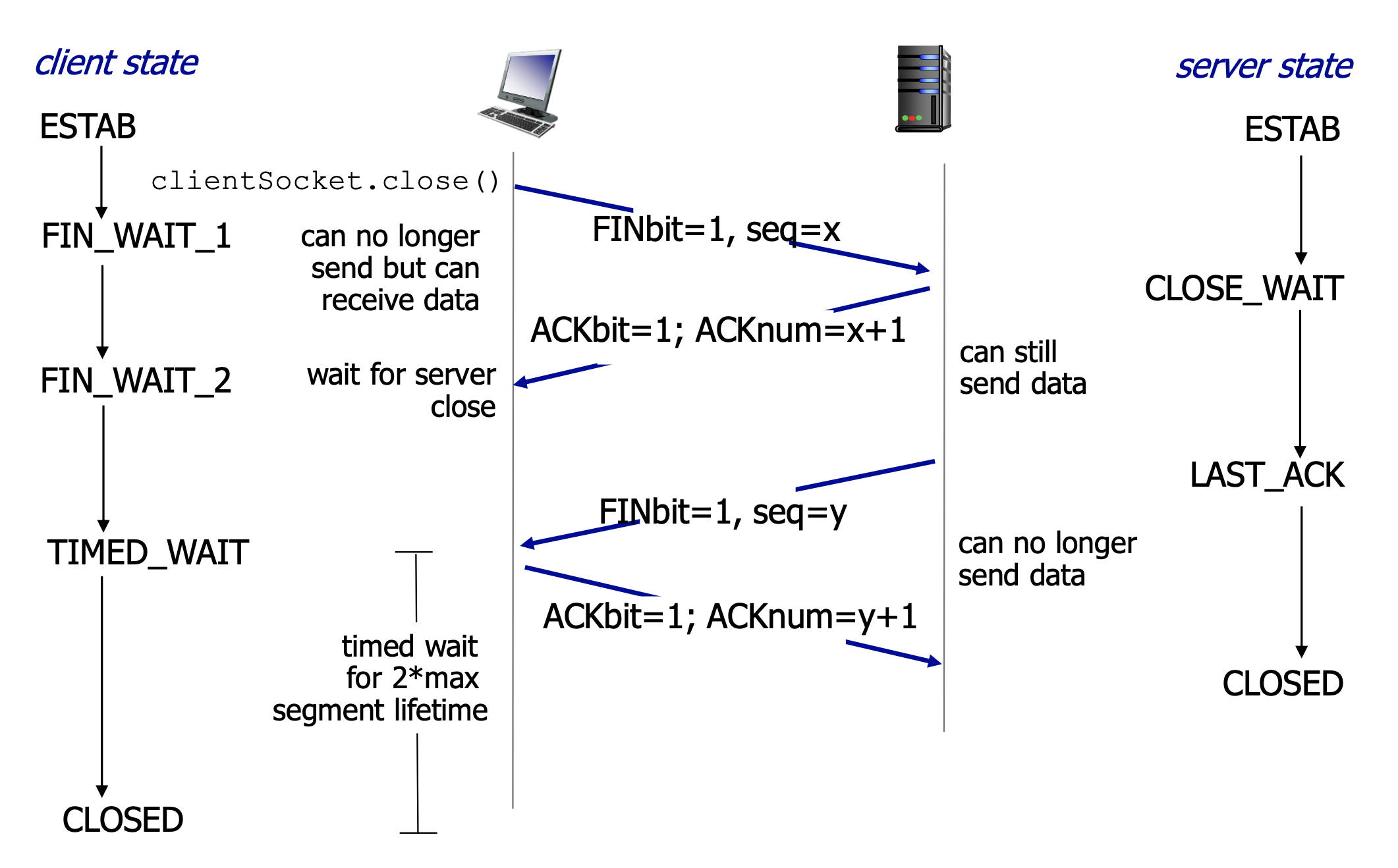
TCP关闭连接:4次挥手
- client、server两边都可关闭连接
- 发送TCP segment的 FIN bit = 1
- 用ACK回应FIN(ACK可以和FIN一起发)
- 同时收到FIN也可以处理(双工)
图 TCP关闭连接
拥塞控制(cwnd)原理
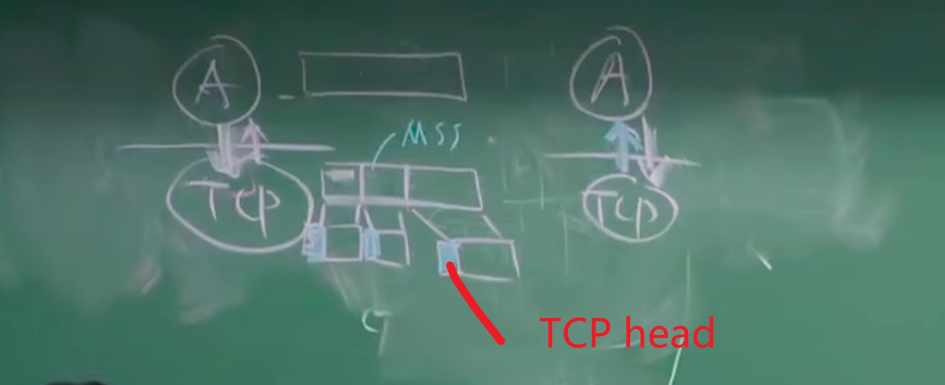
-
MTU - >
- 初次的序号不可能为
0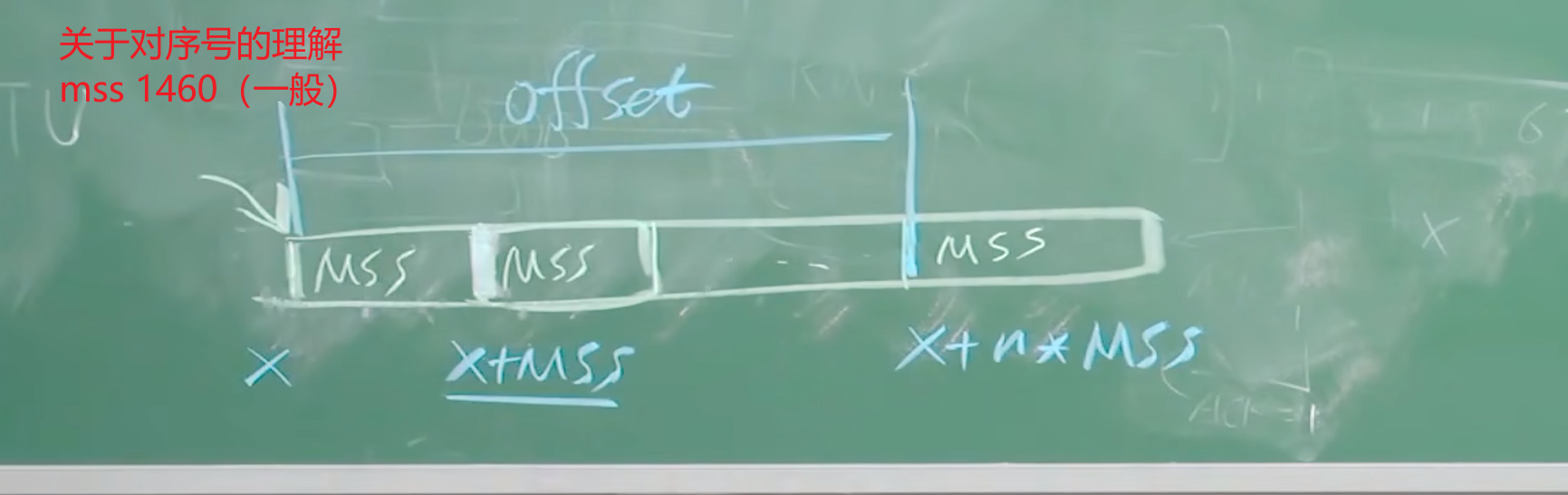
- 初次的序号不可能为
-
虽然网卡的传输时间可以设置为固定的, 但是应用进程建立TCP的时间是不固定的,动态的 ,其分布非常大,所以需要定期测量 !
TCP拥塞控制
概述
拥塞:
- 非正式的定义: “太多的数据需要网络传输,超过了网络的处理能力”
- 与流量控制不同
- 拥塞的表现:
-
分组丢失 (路由器缓冲区溢出) - 分组经历比较长的延迟(在路由器的队列中排队)
网络中前10位的问题!
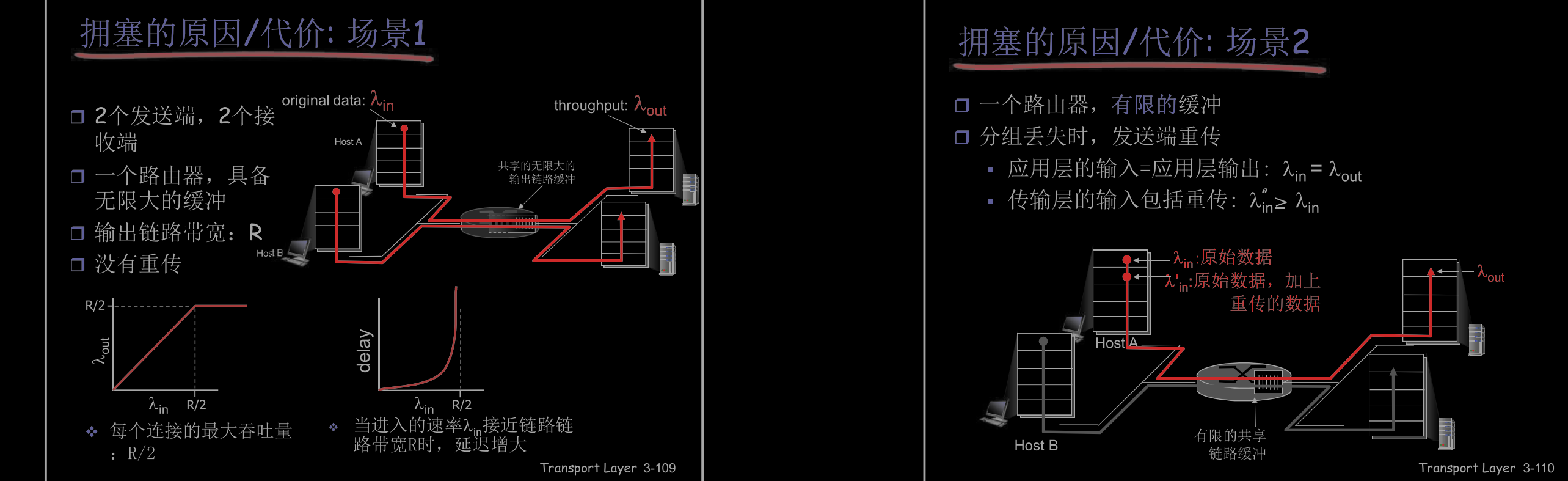
-

拥塞控制策略:
慢启动 AIMD:线性增、乘性减少 超时事件后的保守策略
TCP 拥塞控制:AIMD
sender逐渐增加发送速率(window size),从而探查可用bandwidth,直到丢包
- 加性增(additive increase):cwnd每次每个RTT增加 1 MSS 直到检测到丢包(MSS 最大报文段长度)
- 乘性减(multiplicative decrease):如果发生丢包,cwnd减半
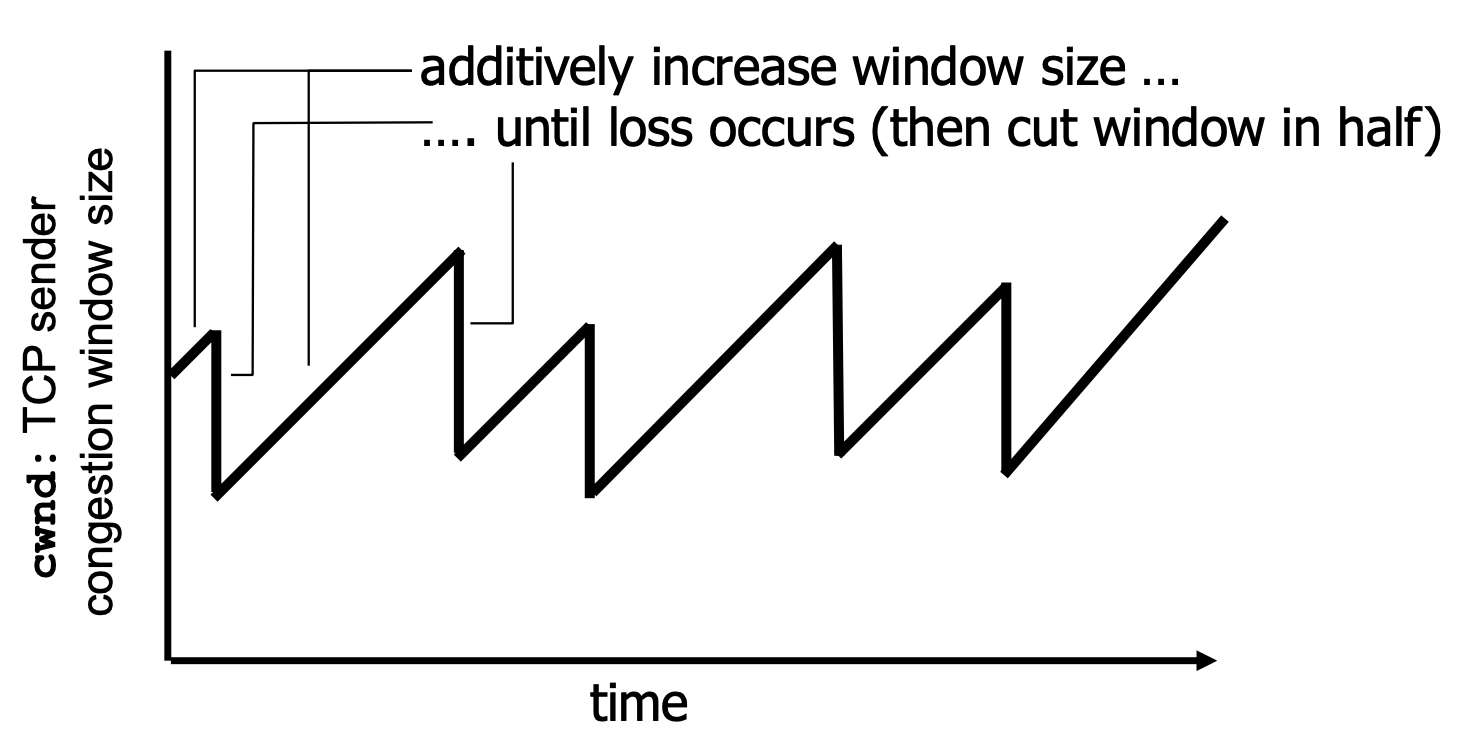
-
sender传输限制
-
cwnd是动态的随着网络拥塞程度变化的函数
-
结合之前的rwnd,实际的窗口大小为 minrwnd,cwnd
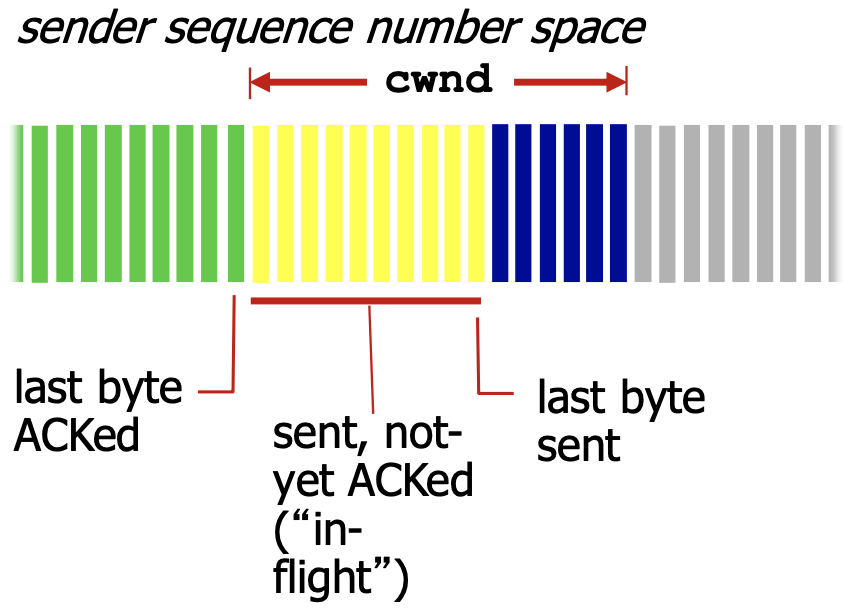
TCP发送速率(TCP sending rate)
发送cwnd bytes,等待1个RTT接收ACK,然后再发送后续的bytes。
rate≈cwndRTT bytes/sec����≈������� �����/���
TCP慢启动(TCP slow start)
-
连接开始时,先指数级增长发送速率,直到出现
丢包
- 初始,cwnd=1 MSS����=1 ���
- 每经过一个RTT,翻倍cwnd(实际上,每收到一个ACK,cwnd+1)
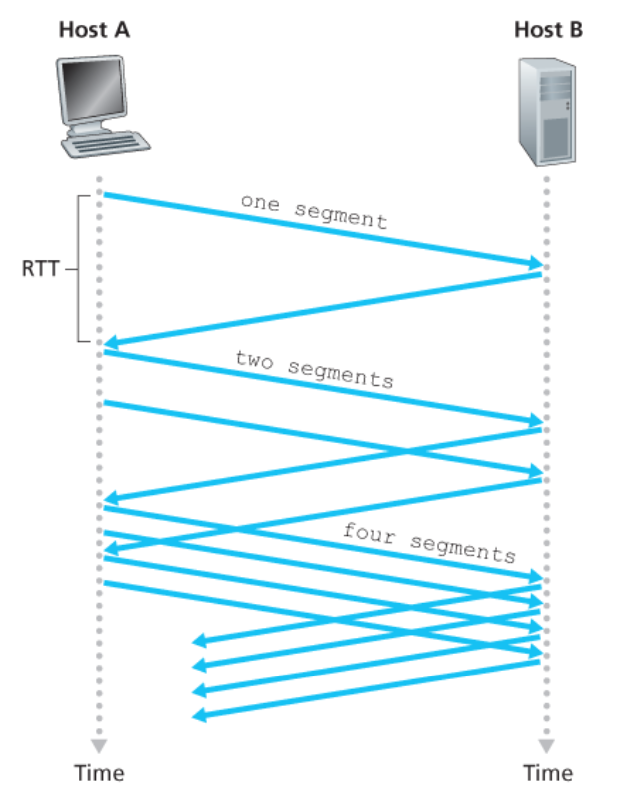
当出现丢包时,
- timeout情况
- cwnd重新设为 1MSS
- 重新开始慢启动,直到到达一个threshold
- 3个重复的ACK情况(TCP RENO版本)
- 重复的ACK既然能收到,那么网络还是有一定的传输能力,不需要像timeout一样重开。
- cwnd减半(乘性减)
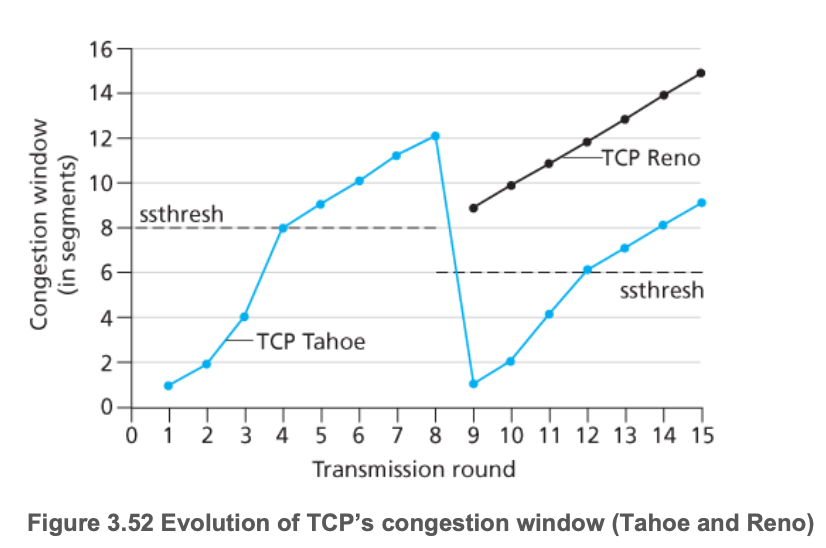
- TCP Tahoe版本中,timeout和3个重复的ACK都将cwnd设为 1MSS
从 slow start 到 CA (快速恢复)的转换
当cwnd达到上次timeout时的1/2(即sstresh)时,从指数级增长变成线形增长。
sstresh —— 出现丢包时,将sstresh设置为此时cwnd的1/2
图 TCP Tahoe/Reno下cwnd的变化图【注:中间有一次3次ACK的丢包】
TCP吞吐量


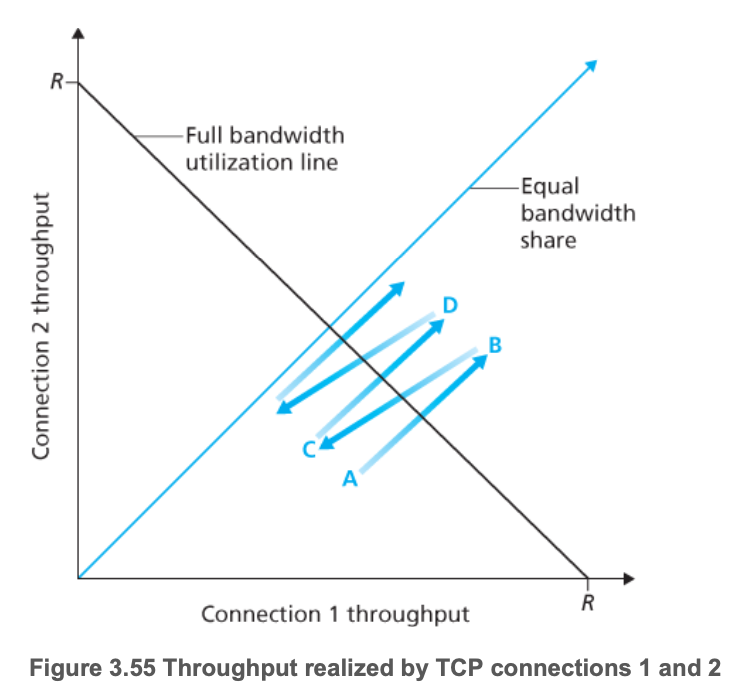
TCP公平性
-
目标:K条TCP连接,经过R bps的瓶颈,每条TCP连接分 R/Kbps,则公平。
-
以两条TCP连接为例,从A出发,经过加性增、乘性减,会逐渐趋向公平线。所以TCP可以实现公平性。

-
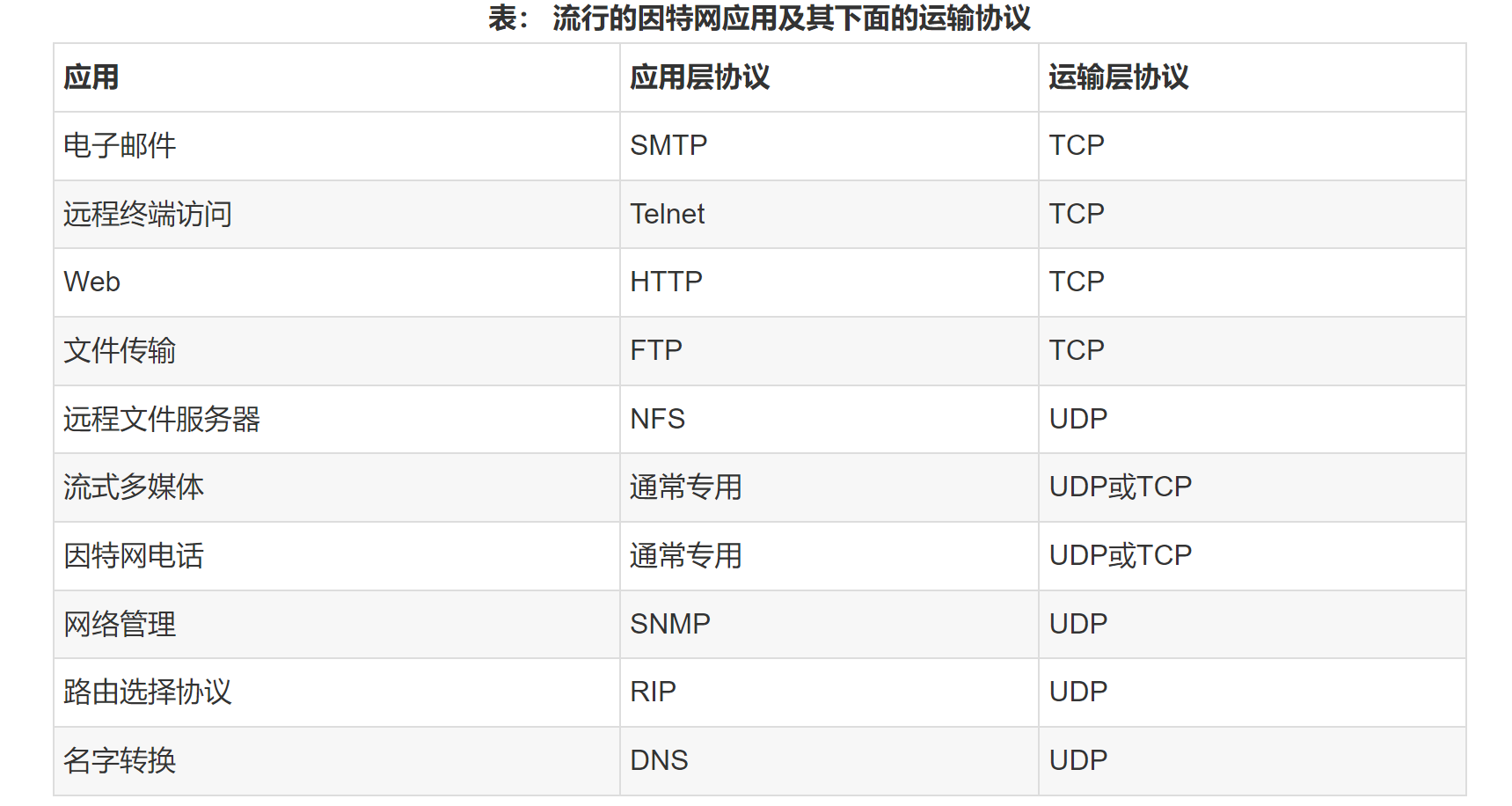
不同应用分别使用的协议: